






 本文详细解释了二叉搜索树的查找、插入和删除操作,以及Map和Set在Java中如何通过HashMap、TreeMap、HashSet和TreeSet实现,特别强调了哈希表的原理、冲突处理和equals与hashCode的关联。
本文详细解释了二叉搜索树的查找、插入和删除操作,以及Map和Set在Java中如何通过HashMap、TreeMap、HashSet和TreeSet实现,特别强调了哈希表的原理、冲突处理和equals与hashCode的关联。
Map和Set主要是通过HashMap/TreeMap/HashSet/TreeSet来实现的,所以具体了解这4种情况即可。
二叉搜索树
特点是:左子结点都小于根结点,右子结点都大于根结点。
查找方法:递归查找。
若根节点不为空:
如果根结点key==查找key,return true;
如果根结点key>查找key,在其右子树找;
如果根结点key<查找key,在其左子树找;
否则,返回false;插入:通过对比插入结点和树中根结点的值,然后修改指向,来达到插入的方法。
删除:
1.
cur.left == null
1. cur 是
root
,则
root = cur.right
2. cur 不是
root
,
cur
是
parent.left
,则
parent.left = cur.right
3. cur 不是
root
,
cur
是
parent.right
,则
parent.right = cur.right
2.
cur.right == null
1. cur 是
root
,则
root = cur.left
2. cur 不是
root
,
cur
是
parent.left
,则
parent.left = cur.left
3. cur
不是
root
,
cur
是
parent.right
,则
parent.right = cur.left
3.
cur.left != null && cur.right != null
1. 需要使用
替换法
进行删除,即在它的右子树中寻找中序下的第一个结点
(
关键码最小
)
,用它的值填补到被删除节点中,再来处理该结点的删除问题
public class BinarySearchTree {
public static class Node {
int key;
Node left;
Node right;
public Node(int key) {
this.key = key;
}
}
private Node root = null;
/**
* 在搜索树中查找 key,如果找到,返回 key 所在的结点,否则返回 null
* @param key
* @return
*/
public Node search(int key) {
Node cur = root;
while (cur != null) {
if (key == cur.key) {
return cur;
} else if (key < cur.key) {
cur = cur.left;
} else {
cur = cur.right;
}
}
return null;
}
/**
* 插入
* @param key
* @return true 表示插入成功, false 表示插入失败
*/
public boolean insert(int key) {
if (root == null) {
root = new Node(key);
return true;
}
Node cur = root;
Node parent = null;
while (cur != null) {
if (key == cur.key) {
return false;
} else if (key < cur.key) {
parent = cur;
cur = cur.left;
} else {
parent = cur;
cur = cur.right;
}
}
Node node = new Node(key);
if (key < parent.key) {
parent.left = node;
} else {
parent.right = node;
}
return true;
}
/**
* 删除成功返回 true,失败返回 false
* @param key
* @return
*/
public boolean remove(int key) {
Node cur = root;
Node parent = null;
while (cur != null) {
if (key == cur.key) {
break;
} else if (key < cur.key) {
parent = cur;
cur = cur.left;
} else {
parent = cur;
cur = cur.right;
}
}
// 该元素不在二叉搜索树中
if(null == cur){
return false;
}
/*
根据cur的孩子是否存在分四种情况
1. cur左右孩子均不存在
2. cur只有左孩子
3. cur只有右孩子
4. cur左右孩子均存在
看起来有四种情况,实际情况1可以与情况2或者3进行合并,只需要处理是那种情况即可
除了情况4之外,其他情况可以直接删除
情况4不能直接删除,需要在其子树中找一个替代节点进行删除
*/
return true;
}
}
最优情况下,二叉搜索树为完全二叉树,其平均比较次数为:log2N
最差情况下,二叉搜索树退化为单支树,其平均比较次数为:N/2
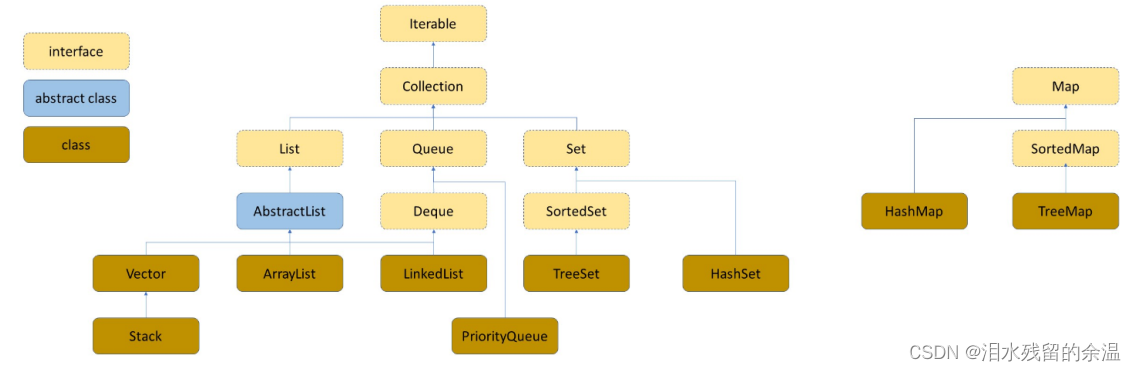

Map
特点:key-value,键值对存储
map其实就是python中的字典,注意以下几个方法的使用。
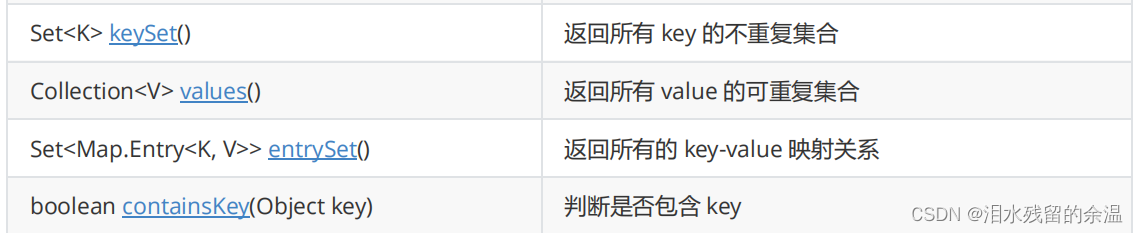
注意:
1.
Map
是一个接口,不能直接实例化对象
,如果
要实例化对象只能实例化其实现类
TreeMap
或者
HashMap
2.
Map
中存放键值对的
Key
是唯一的,
value
是可以重复的
3.
在
TreeMap
中插入键值对时,
key
不能为空,否则就会抛
NullPointerException
异常
,
value
可以为空。但
是
HashMap
的
key
和
value
都可以为空。
4.
Map
中的
Key
可以全部分离出来,存储到
Set
中
来进行访问
(
因为
Key
不能重复
)
。
5.
Map
中的
value
可以全部分离出来,存储在
Collection
的任何一个子集合中
(value
可能有重复
)
。
6. Map
中键值对的
Key
不能直接修改,
value
可以修改,如果要修改
key
,只能先将该
key
删除掉,然后再来进行重新插入。
Set
特点:去重
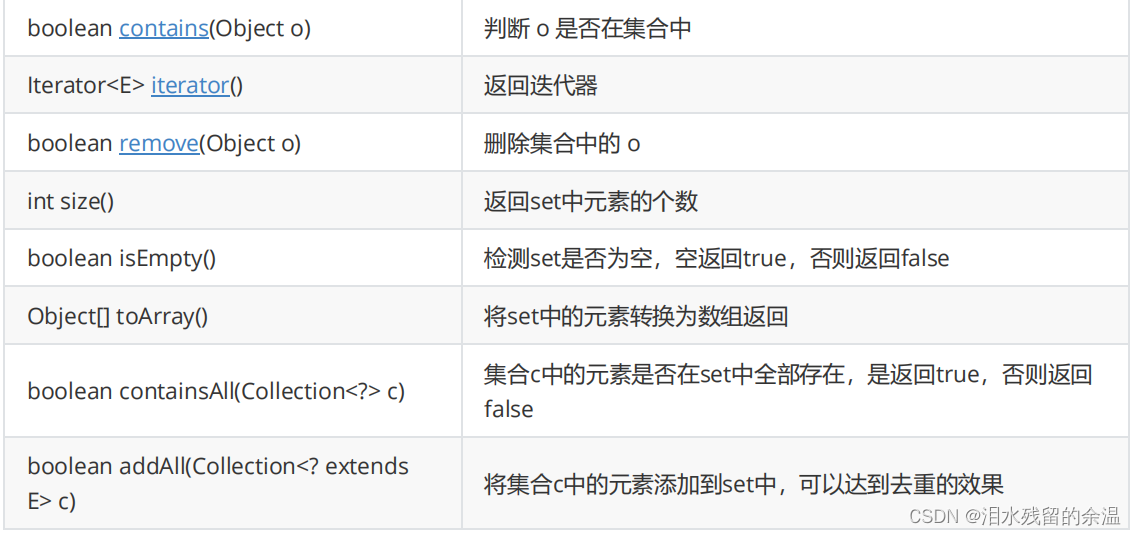
注意:
1. Set
是继承自
Collection
的一个接口类
2. Set
中只存储了
key
,并且要求
key
一定要唯一
3. TreeSet
的底层是使用
Map
来实现的,其使用
key
与
Object
的一个默认对象作为键值对插入到
Map
中的
4. Set
最大的功能就是对集合中的元素进行去重
5.
实现
Set
接口的常用类有
TreeSet
和
HashSet
,还有一个
LinkedHashSet
,
LinkedHashSet
是在
HashSet
的基础
上维护了一个双向链表来记录元素的插入次序。
6. Set
中的
Key
不能修改,如果要修改,先将原来的删除掉,然后再重新插入
7. TreeSet
中不能插入
null
的
key
,
HashSet
可以。
哈希表
哈希方法中使用的转换函数称为哈希
(
散列
)
函数,构造出来的结构称为哈希表
(Hash
Table)(
或者称散列表
)
哈希函数设置为:
hash(key) = key % capacity
; capacity
为存储元素底层空间总的大小。
哈希冲突
不可避免
负载因子=填入表中的元素/表长。
当负载因子达到一定量的时候,需要通过扩容,来降低负载因子。
处理哈希冲突的两个方法
闭散列和开散列
闭散列(开放定址法)
1.线性探测-向后找空位
2.二次探测-通过(H+i^2)% m的方式找空位,优化了顺序查找
开散列(链地址法)(开链法)
通过让数组的每个位置,挂上一个链表(桶)来解决冲突,链表采用尾插法。当链表的长度任然过大时,难以搜索时,将其优化为哈希表或者搜索树。
哈希表的时间复杂度认为是O(1)
1. HashMap
和
HashSet
即
java
中利用哈希表实现的
Map
和
Set
2. java
中使用的是哈希桶方式解决冲突的
3. java
会在冲突链表长度大于一定阈值后,将链表转变为搜索树(红黑树)
4. java
中计算哈希值实际上是调用的类的
hashCode
方法,进行
key
的相等性比较是调用
key
的
equals
方
法。所以如果要用自定义类作为
HashMap
的
key
或者
HashSet
的值,
必须覆写
hashCode
和
equals
方
法
,而且要做到
equals
相等的对象,
hashCode
一定是一致的。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









