






写在前面
学习了相关文章,发现大部分内容不够详细,提供的代码虽然可用,但比较繁杂,并不方便。当然也有优秀作者写出了很好的文章。本文站在巨人肩膀,融入自己的理解,希望对各位看官有所帮助。本文默认各位看官对环境搭建已经掌握,本文对此比在赘述
数据集划分
最终数据文件如下所示。首先在datasets文件夹下放置images、xmls文件。这两个文件夹分别存放所有的jpg文件和所有的xml文件。
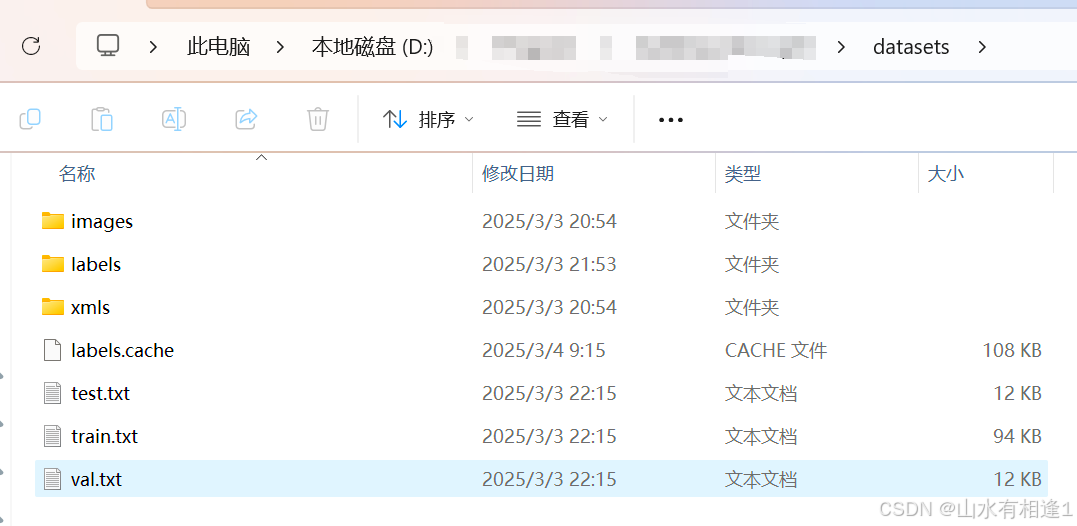
利用下列所给代码,生成labels文件夹和train.txt、val.txt、test.txt四个文件。修改**parse_option()**函数,配置自己的文件路径和数据划分比例。
import os
import random
import argparse
from ultils import *
import warnings
def parse_option():
parser = argparse.ArgumentParser()
# xml文件的地址,根据自己的数据进行修改 xml一般存放在Annotations下
parser.add_argument('--dataset', default='datasets', type=str, help='input dataset path')
# xml文件的地址,根据自己的数据进行修改 xml一般存放在Annotations下
parser.add_argument('--xml_path', default='datasets/xmls', type=str, help='input xml label path')
# 数据集的划分,地址选择自己数据下的ImageSets/Main
parser.add_argument('--jpg_path', default='datasets/images', type=str, help='output jpg label path')
# 数据集的划分,地址选择自己数据下的ImageSets/Main
parser.add_argument('--label_path', default='datasets/labels', type=str, help='output txt label path')
# 数据集的划分,比例
parser.add_argument('--ratio', default=[0.8, 0.1, 0.1], type=list, help='the ratio of [train val test]')
# 随机数种子,保证每次产生的分组相同,实现具有复现性
parser.add_argument('--seed', default=42, type=int, help='seed for initializing training. ')
opt = parser.parse_args()
if opt.seed is not None:
random.seed(opt.seed)
warnings.warn('You have chosen to seed training.')
if not os.path.exists(opt.label_path):
os.makedirs(opt.label_path)
return opt
if __name__ == '__main__':
opt = parse_option()
# 将xml文件转化为voc格式文件
total_files = os.listdir(opt.jpg_path)
for file in total_files:
xml_file = opt.xml_path + '/' + file[:-4] + '.xml'
txt_file = opt.label_path + '/' + file[:-4] + '.txt'
convert_annotation(xml_file, txt_file)
# 对数据进行划分
train_txt = open(os.path.join(opt.dataset, 'train.txt'), 'w')
val_txt = open(os.path.join(opt.dataset, 'val.txt'), 'w')
test_txt = open(os.path.join(opt.dataset, 'test.txt'), 'w')
abs_path = os.getcwd()
trainval = random.sample(total_files, int(len(total_files) * (opt.ratio[0]+opt.ratio[1])))
train = random.sample(trainval, int(len(total_files) * opt.ratio[0]))
for file in total_files:
if file in trainval:
if file in train: # train_data
train_txt.write(opt.jpg_path + '/' + file + '\n')
else: # val_data
val_txt.write(opt.jpg_path + '/' + file + '\n')
else: # test_data
test_txt.write(opt.jpg_path + '/' + file + '\n')
代码首先实现对数据转成txt格式并保存在labels文件夹下,然后train.txt、val.txt、test.txt三个文件夹分别保存训练、验证、测试的数据。
训练数据
复制ultralytics/cfg/datasets/coco.yaml文件修改其中内容并重命名为自己的文件。其中左图为原始coco.yaml文件内容,右图为修改后的文件内容。


下载相应模型文件,放置在同一目录下,采用终端命令即可实现模型训练。
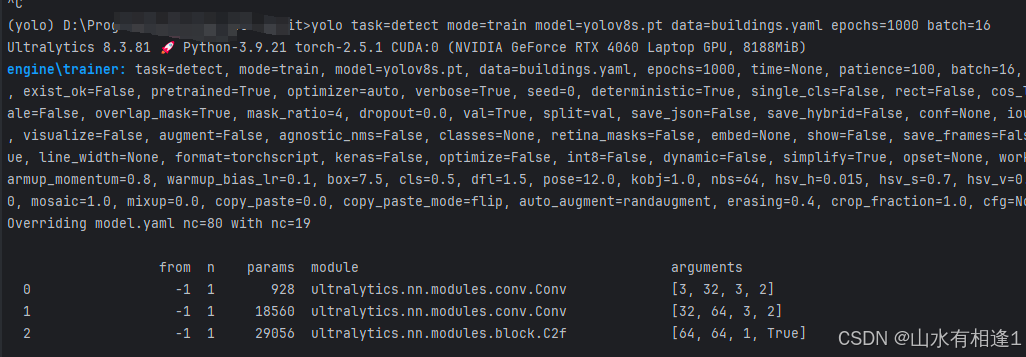
yolo task=detect mode=train model=yolov8s.pt data=buildings.yaml epochs=1000 batch=16
正确运行


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









