






论文来源
这篇论这篇论文由 北京大学 和 北京航空航天大学 的研究人员合作撰写,具体发表在 ACL 2024(国际计算语言学协会大会 2024)的会议论文集中文由 北京大学 和 北京航空航天大学 的研究人员合作撰写,具体发表在 ACL 2024(国际计算语言学协会大会 2024)的会议论文集中。
该论文的贡献如下:
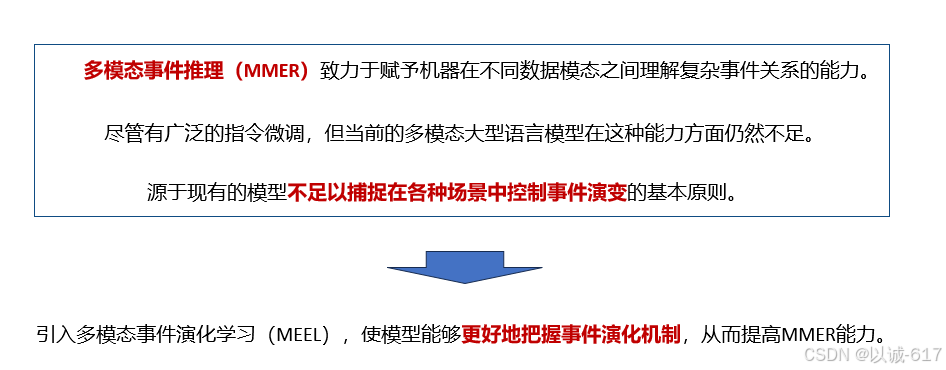
- 论文提出了多模态事件进化学习(MEEL)。旨在训练模型来理解各种场景的复杂事件演变。该方法对MM事件推理的其他研究具有一定的借鉴意义。
- 进一步设计了引导辨别来引导MMER的进化并减轻其幻觉。
- 为MMER收集和策划了
基准测试。
目录
Multi-Modal Event Evolution Learning
摘要图解,针对为何要提出此问题,解决此问题
引言部分
注重多模态图文数据,针对图片信息提取和解答,目前虽然多模态已经深入研究,但是针对输入的动态性质,任务训练模型无法感知事件演变。

对于此更好的理解如下图:
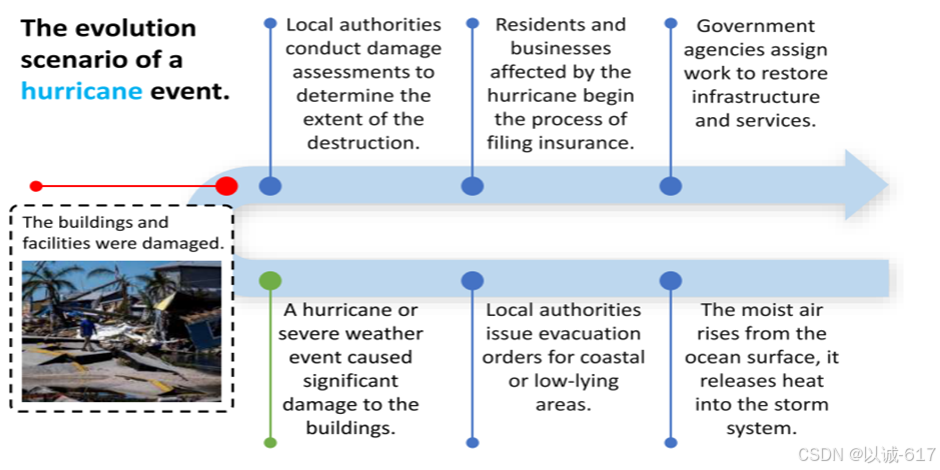
上图是飓风情景的事件演变的一部分。查询的事件为红色。MEEL赋予了模型关于场景演化中所有事件的知识。目前现有的方法只训练了绿色事件推理的少量片段模型。
针对事件发生的前导,造成的影响演化,结果处理等均没有考虑到。
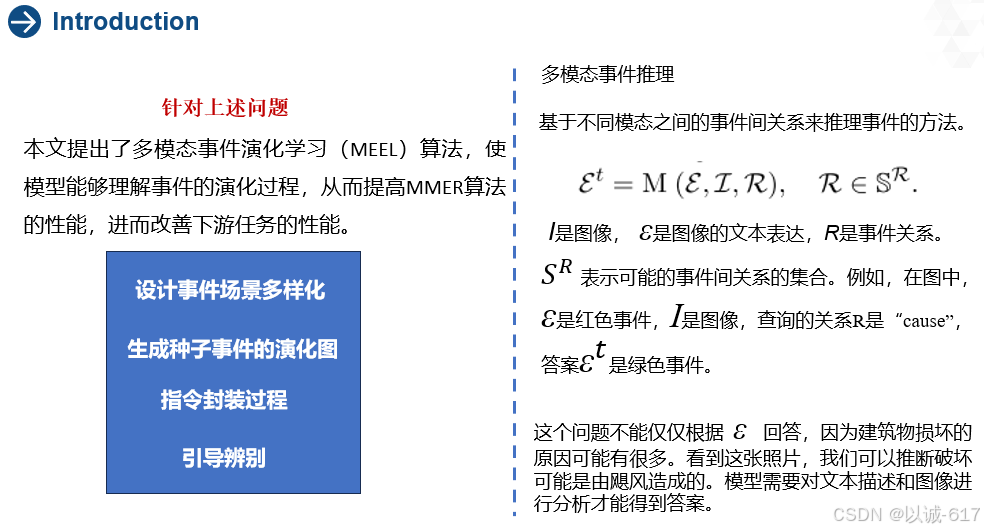
- 首先设计事件场景多样化,从丰富的场景中获取各种事件。
- 然后,我们使用ChatGPT生成这些种子事件的演化图。其目的是使用这些图来训练模型,以理解事件演变的丰富知识。为了实现这一目标,改论文提出了指令封装过程,将演化图适配为指令调优数据来训练模型。这样,训练允许模型理解场景的更多事件演化知识,从而导致MMER的更好性能。
- 然而,仅允许模型学习演化图是不够的。如果不承认错误的演化事件,模型将错误地推进过程,导致事件推理的幻觉。为了缓解这种情况,作者进行了引导辨别。该模型需要判断错误的进化。
- 作者设计了各种负面挖掘策略来收集不正确的事件。最后,对模型进行训练,对正确的事件进行分类。我们还将引导性辨别引入到教学调整中。在获得所有数据后,对LLaVA进行微调模型(来获得论文的模型。
Multi-Modal Event Evolution Learning
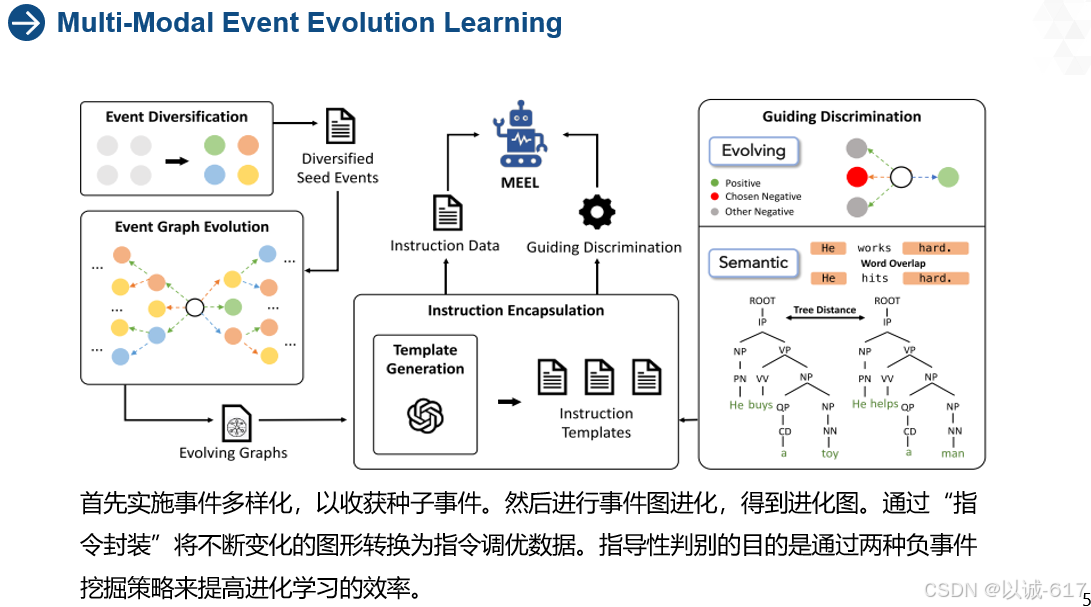
整体的流程框架图
Event Diversification

Event Diversification 事件演化
上图目的是展示MEEL系统中不同步骤的事件演变和指令生成过程。它描述了如何从种子事件开始,逐步构建事件演变图,并将这些演变图转化为模型训练所需的指令数据。具体来说,图3分为三个部分,分别展示了关键步骤。下面是详细解释:
1. 图3(a) - 事件演变提示生成 (Evolving Prompt):
解释:种子事件给出后,ChatGPT会生成一系列与该事件有关的后续事件(比如种子事件的原因或结果)。这个提示通过结合图像和文本来创建新的事件,最终形成一个事件链。
2. 图3(b) - 指令生成与模板 (Instruction Generation & Template):
解释:这一步是为了把复杂的事件关系(比如“事件A会导致事件B”)转化为模型能理解的训练任务格式,比如“根据图片描述事件A,模型需要推测出事件B是什么”。
3. 图3(c) - 多选指令生成与模板 (Multiple-choice Instruction Generation & Template):
解释:通过多选题,训练模型在面对多种可能结果时,学会判断哪个结果最符合事件演变的逻辑。这个过程有助于提高模型在复杂事件推理中的辨别能力。
Event Graph Evolution

输入:
步骤16-17:循环结束后,Ẽ被更新为新生成的事件集合,继续下一轮演变。
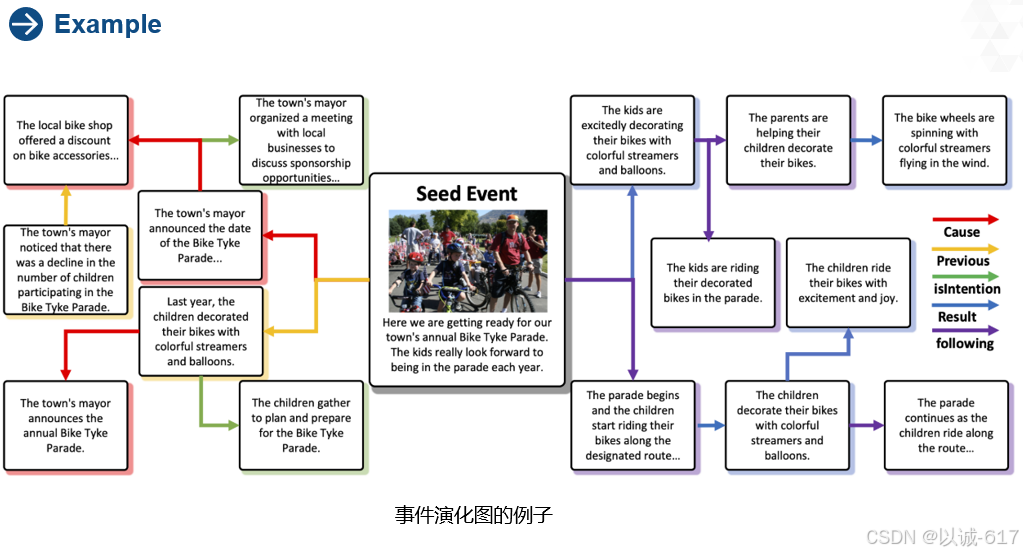
上述为演化进程,下图为一个种子事件的演化进程:
Instruction Encapsulation
指令封装部分的详细解释:

指令封装具体步骤
通过这种方式,模型能够推测出更复杂的事件间关系。
b. 指令生成模板
具体的指令参考Event Diversification 部分的图3(b)
Guiding Discrimination
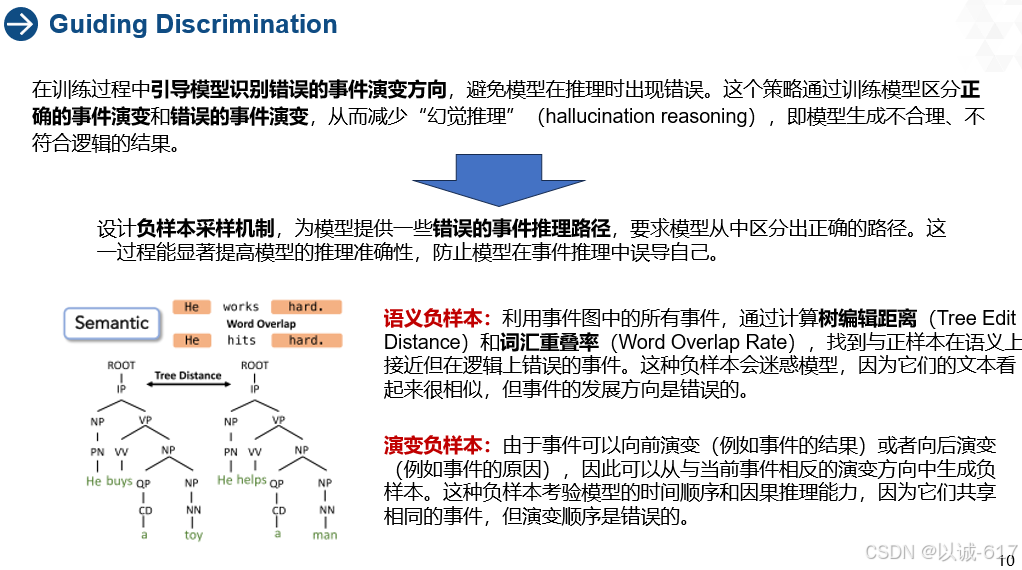
指导性歧视
在一个复杂的事件演变过程中,模型需要基于给定的事件(如文本或图像)推测出正确的后续事件。然而,如果模型只学习正向的事件演变路径,而没有学会区分错误的演变,可能会导致模型生成错误的推理结果。比如,模型可能会推测出与逻辑不符的事件发展。
定义:语义负样本是那些与正样本在语义上非常相似,但在逻辑上不正确的事件。模型要学会区分这些在语义上很接近的错误事件。
定义:演变负样本是那些演变方向上出错的事件。模型要学会识别哪些事件演变方向是错误的。例子:如果模型需要推测“某人购买了一本书”之后的事件,而一个可能的负样本是“他把书还回去了”,这在时间顺序上不符合逻辑(除非已经发生了一系列中间事件),因此模型需要识别这是错误的结果。
在 Guiding Discrimination 的训练过程中,模型的损失函数被定义为两部分:
综合的总损失函数为: L=LR+LDL = LR + LDL=LR+LD
模型通过最小化这个损失函数,学习既能正确推理事件的演变,又能有效避免推理出错误的事件。
具体的指令参考Event Diversification 部分的图3(c)
Experiments
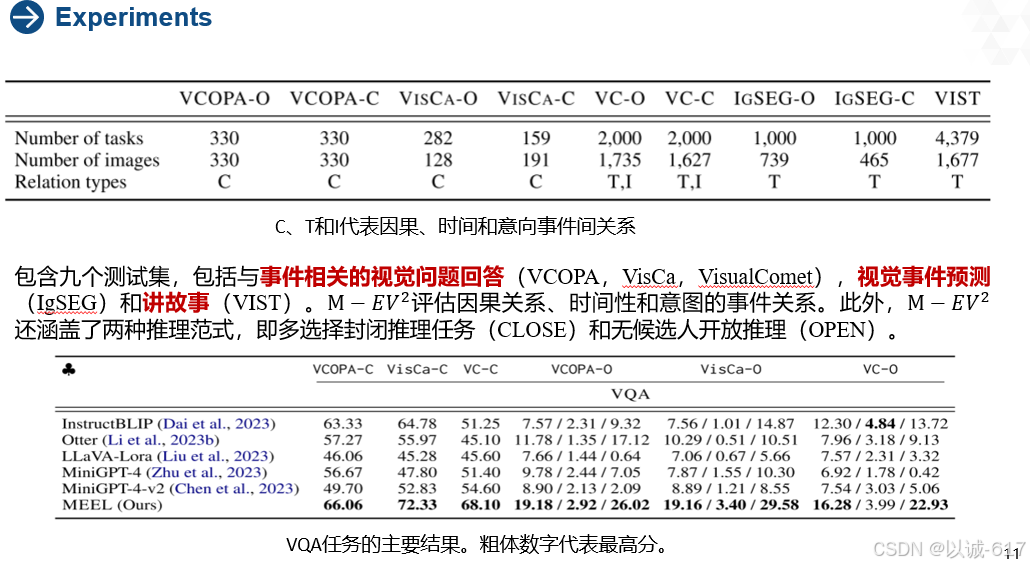
为了全面评估MMER模型对多元化事件间关系的能力,该团队收集并策划了基准M−𝐸𝑉2M-EV^2
1、VCOPA这是常识性VQA的任务。给定图像I和两个候选选项,任务是选择更合理的原因或结果选项。
将该数据集转化为一个开放式推理任务。我们将原始的多项选择任务表示为VCOPA-C,将转换后的任务表示为VCOPA-O。
2、VisCa这是从视觉和文本信号中学习上下文因果关系的数据集
在给定两个图像作为上下文和两个文本句子描述的情况下,模型需要确定前一个句子是否导致后一个句子。VisCa-C和VisCa-O。
我们将其转换为我们的VQA任务。我们保留了图像和第一句话,并将第二句话作为标签生成。我们根据真实情况提取一个否定句,并将其形成一个多项选择题。我们还将多项选择任务改编成类似于VCOPA-O的开放式推理。
3. VisualComet这是一个开放的常识性VQA任务。我们还检索了一个否定的答案,并将其公式化为一个多项选择任务。我们将这两个任务分别表示为VC-O和VC-C。
4. IgSEG该数据集的目的是基于已经发生的事情来预测未来的事件。具体地说,给定一个按顺序排列的句子序列和接下来将要发生的事情的图像,模型需要为这个图像生成一个句子。此外,我们还提取了一个否定事件,并将其形成为一个多项选择任务。我们将这两个任务表示为IgSEG-O和IgSEG-C。
5. VIST这是讲故事的任务,即在句子和图像中给出前一个故事的情况下产生下一个故事
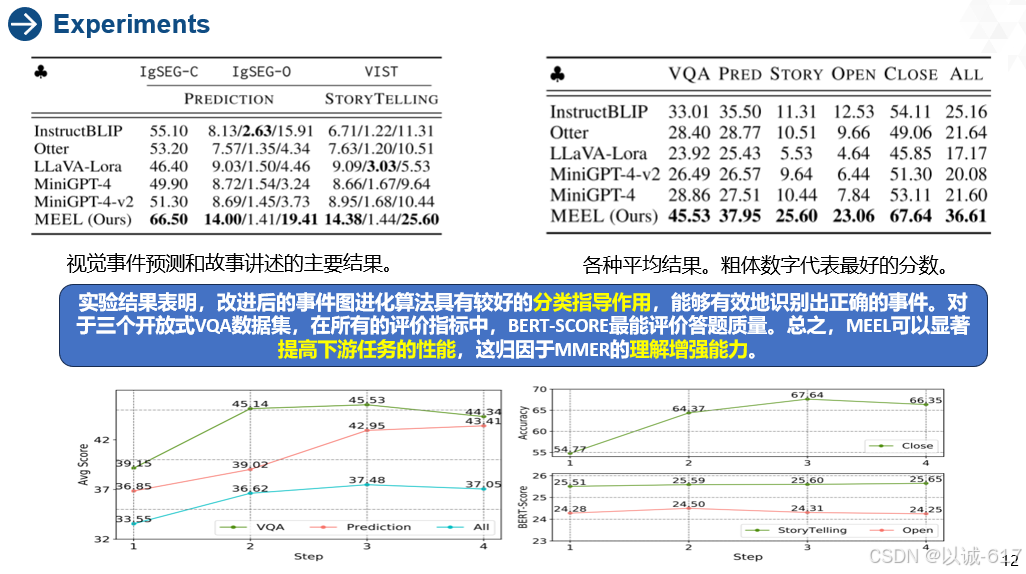
MEEL在视觉事件预测方面优于基线。MEEL在表中的所有基线中表现最好。结果表明,训练方法使模型能够捕获正确的时间关系,从而对未来进行更精确的预测。与VQA任务相比,所有模型在视觉事件预测方面的表现都较差,这表明完成这个任务需要更多的知识和推理能力。在OPEN视觉预测中,MEEL在BERT-SCORE中也获得了最高分。这表明模型可以预测语义相似的事件。
MEEL可以生成高级故事。右图中,发现MEEL可以优于VIST中的所有基线。实验结果表明,MEEL能捕捉更多的情景知识,理解事件间的关系,从而更好地讲述故事。事件图演化影响模型的训练,以确认丰富的事件信息,而不仅仅是浅步推理。
事件图进化过程刺激了对事件的上下文理解。引导辨别进一步减轻了事件推理的幻觉,从而产生更好的性能。
最下面的图
发现当步长太大,即大于4时,性能下降。这可能归因于事件图演化的语义漂移。如果ChatGPT进一步发展,它将生成比种子事件更少的相关内容。
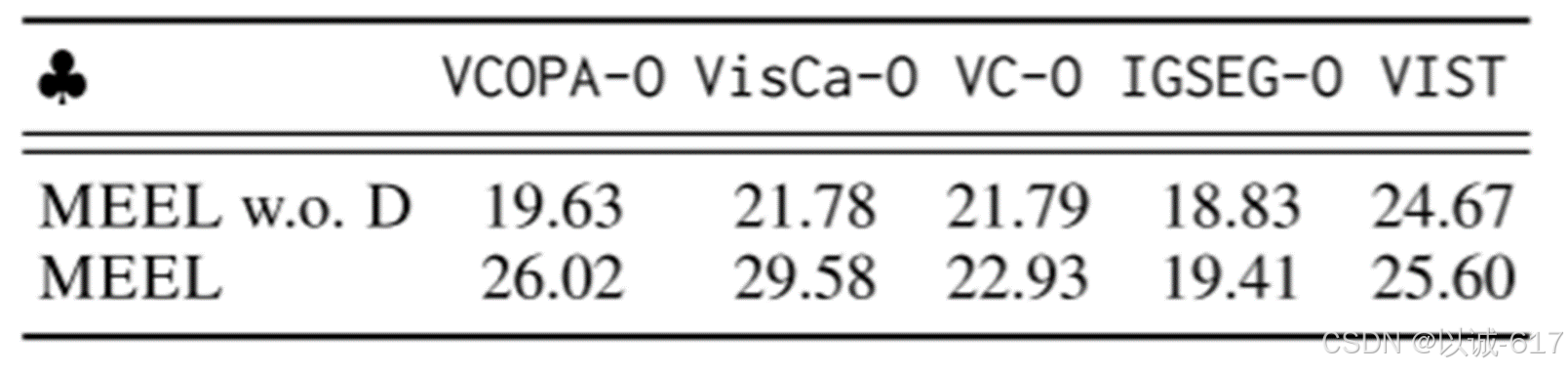
上图进行了消融实验,分别对比MEEL是否含有指导性歧视操作,可以发现没有指导性歧视的实验得分有所下降,验证了指导性歧视的必要性。
Conclusion


















 1348
1348

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









