







Weakly Supervised Video Salient Object Detection
摘要
本文首次提出了基于重标注的“眼动点模糊标注”的弱监督视频显著性目标检测模型。本文提出了“Appearance-motion fusion module”和双向的LSTM;另外还设计了前背景similarity loss;另外还提出了一个weak annotation boosting strategy。
1. Introduction
视频显著性检测(VSOD)是在空间域和时间域分割显著性目标的任务。现有的VSOD方法有两个不同的解决思路:1.用循环网络encoding时间信息;2.用光流约束encoding几何信息。VSOD的困难在于pixel-wise标注工作量很大。
训练深度视频显著性检测模型的标准pipeline包括两个主要步骤。首先,网络在现有的静止RGBimage-based显著性检测训练集,如DUTS或MSRA 10K上面做预训练。然后,在视频显著性检测数据集,如DAVSOD和DAVIS上微调。这样做的主要原因是视频显著性检测数据集通常场景密度有限。即使最大的DAVSOD数据集有超过10K帧的训练数据,其中还是有很多冗余帧,使得其无法有效,充分地训练深度视频显著性模型。DAVSOD有107个用于训练和验证的片段,即只有107个不同的场景。因此,直接用VSOD数据集训练可能还不够,且含有大量冗余的数据可能会导致模型过拟合。
为了得到一个高效的视频显著性检测模型,现有的全监督VSOD方法依赖于RGB图像显著性数据集和VSOD训练数据集。以上pipeline背后的问题是pixel-wise标注的巨大限制,其时间和成本代价昂贵。例如,RGB图像显著性检测训练数据集有超过10K的标注样本。此外广泛应用的VSOD训练数据集(DAVSOD和DAVIS)包含了超过14K的pixel-wise标注帧。两者的标注都意味着巨大的标注负担。
为了缓解这种pixel-wise标注负担,一个可以采取的方式就是用弱监督学习技术从图像的scribble或image-level标注中学习显著性。在本文中,考虑到scribble标注的高效性,我们旨在通过scribble学习一个弱监督视频显著性检测网络。然而,最主要的问题是每张scribble标注没有时间信息。为了把时间信息包含入我们的弱监督标注,本文在现有的VSOD训练集中采用了眼动点标注作为监督。另外,文本首先将眼动点的峰值反应区域定义为前景,那些没有眼动点的区域作为背景。然后本文用《Weakly-supervised salient object detection via scribble annotations》同时标注了前景scribble和背景scribble。
问题:《Weakly-supervised salient object detection via scribble annotations》是如何进行标注的?
回答:眼动点涂鸦标注,涂鸦两笔,一笔是眼动点关注到的显著区域,一笔是随机在背景上画一笔,这样的标注最后有三个标签,1代表前景,2代表背景,0表示未知。
基于眼动点的scribble标注,本文设计了一个appearance-motion融合模型去融合RGB图像的外观信息和光流中的运动信息。另外展示了一个基于时间信息加强模型的双向LSTM去加强提取长期时间信息。需要注意的是,本文使用来自S-DUTS的scribble标注通过传统方式去对我们的视频显著性检测网络做预训练。通过建立RGB图像显著性检测数据集和视频显著性检测数据集的scribble标注,和现有的深度视频显著性检测模型相比,我们的弱监督视频显著性检测网络只要求非常低廉的配置。考虑到数据集中cross-frame的冗余,本文介绍了foreground-background similarity loss去完全开发我们的弱监督标注。本文另外还介绍了一种弱监督加强策略,这种策略利用了我们的scribble标注和产生于现有的全监督SOD模型生成的saliency map。得益于此,我们的模型表现很好(见图1的f, e)。

本文主要的contribution是:1.介绍了首个基于眼动点scribble标注的弱监督视频显著性检测网络;2.提出了一种appearance-motion融合模型和一个时间信息加强模型去有效地融合外观和动作特征;3.提出foreground-background similarity loss在邻近帧中去探索我们的弱监督标注;4.结合现有saliency模型生成的saliency maps和我们的scribble标注去加强模型效果。
2. Related Work
Fully supervised video salient object detection: 作为VSOD任务的主流,全监督模型关注探索训练集的空间和时间信息。
然而这中算法要求的标注很麻烦。
Weakly/semi/un-supervised video salient object detection: 弱监督/半监督/无监督任务
Video object segmentation: VOS任务
3. Our Method
3.1. Overview
重新标注了DAVSOD和DAVIS数据集,做了scribble标注。scribble标注缺少时间信息,因此本文做了眼动点scribble标注。这样数据集分成三部分,RGB图像X,光流图F和眼动点模糊标注Y。本文设计了一个显著特征提取器 f α f_{\alpha} fα来提取X和F的显著性特征。然后用Appearance-Motion Fusion Module (AMFM)把这两个特征融合到一起,这样就同时学习到了外观和运动信息。用LSTM对融合的结果使用Temporal Information Enhanced Module (TIEM)得到了长期的时间信息。Foreground-background similarity loss利用到了眼动点模糊标注信息,这提升了对时间信息的提取。最后Saliency boosting strategy改善了方法的效果。
3.2. Fixation guided scribble annotation
最大的视频显著性检测数据集DAVSOD的标注分为两步:1.使用视觉追踪器记录眼动点,输出经过高斯模糊处理,得到稠密fixation map;2.标注者分割基于峰值关注区域(peak response region,即眼动点最密集的部分)的全范围作为显著性前景。根据《Shifting more attention to video salient object detection》,额外的眼动点标注提供了视频显著性数据集有用的时间信息。按照惯例,DAVSOD和DAVIS结合到一起去训练全监督VSOD模型。起初,DAVIS没有眼动点标注,然而Wang et al.为其添加了标注。作为一个弱监督显著性检测网络,本文趋于使用眼动点数据作为监督信息去火的时间信息,然后用scribble标注训练学习代替pixel-wise clean annotation。给定数据集中的每一帧(图a)和相关的fixation map(图b),我们通过peak response regions标注目标前景scribble和其他区域的背景scribble(图d)。这样,产生的scribble标注encode了时间信息(相比之下《Weakly-supervised salient object detection via scribble annotations》中的scribble没有包含时间信息)。

问题:《Weakly-supervised salient object detection via scribble annotations》中的scribble和本文的scribble有什么区别?
回答:根据本文的描述推测是这样的区别。直接做scribble标注是单张图片随便标注,但是本文添加了fixation的跟踪后就相当于显著性区域是根据视频的内容不断变化的,这样就包含了时间信息。
3.3. Saliency feature extraction
根据图2结构所示,使用显著性特征提取模块在RGB图像 X X X中提取外观显著性特征 f α ( X ) f_{\alpha}(X) fα(X),在光流图 F F F中提取运动显著性特征 f α ( F ) f_{\alpha}(F) fα(F)。本文结构基于ResNet-50并移除了第四阶段(output的size相同的为一个阶段)下采样来保留空间信息,用空洞卷积代替了最后一层卷积层,第四阶段添加了ASPP模块,这个模块用多尺度的空洞卷积获得多尺度空间信息。基于这个显著特征提取模块,我们得到了外观特征 f α ( X ) = { f r 1 , f r 2 , f r 3 , f r 4 } f_{\alpha}(X)=\{f_r^1, f_r^2, f_r^3, f_r^4\} fα(X)={fr1,fr2,fr3,fr4}和运动特征 f α ( F ) = { f m 1 , f m 2 , f m 3 , f m 4 } f_{\alpha}(F)=\{f_m^1, f_m^2, f_m^3, f_m^4\} fα(F)={fm1,fm2,fm3,fm4}。我们还添加了额外的edge detection branch去恢复最终输出的结构信息,这个细节可以阅读《Weakly-supervised salient object detection via scribble annotations》。
问题:什么是edge detection branch?
回答:就是一个边缘检测分支,更好地定位目标轮廓。
3.4. Appearance-motion fusion module
AMFM模块的作用是融合 f α ( X ) f_{\alpha}(X) fα(X)和 f α ( F ) f_{\alpha}(F) fα(F)。AMFM的输入是外观特征 f r k f_r^k frk和运动特征 f m k f_m^k fmk,大小为 C × W × H C×W×H C×W×H。我们使用两个ReLU激活函数的卷积层去将 f r k f_r^k frk和 f m k f_m^k fmk的channels的数量分别减少到32。然后用级联操作和 1 × 1 1×1 1×1的卷积层得到fused feature g r m k g_{rm}^k grmk,大小为 C × W × H C×W×H C×W×H,包含了外观和运动信息。
问题:什么是级联操作(concatenation operation)?
回答:将新向量拼接到原来的向量之后,对应着维数增加,具体请见这里。但是这里的级联操作应该就是concat,要不然size那里说不通。
AMFM中有3个子模块,分别叫做gate module(GM),channel attention module(CAM)和spatial attention module(SAM)。GM用来控制外观信息和运动信息的重要性,另外两个注意力机制模块用来选择具有辨别性的channels和locations。在GM中,两个不同的门可以从被融合的信息
g
r
m
g_{rm}
grm中生成,分别叫做外观门
G
r
(
g
r
m
)
G_r(g_{rm})
Gr(grm)和运动门
G
m
(
g
r
m
)
G_m(g_{rm})
Gm(grm)。这个模块可以控制
f
r
f_r
fr和
f
m
f_m
fm的重要性,公式如下:
G
=
G
A
P
(
σ
(
C
o
n
v
(
g
r
m
;
β
)
)
)
G=GAP(\sigma(Conv(g_{rm};\beta)))
G=GAP(σ(Conv(grm;β)))
其中,
G
=
[
G
r
,
G
m
]
,
G
r
,
G
m
G=[G_r, G_m],G_r, G_m
G=[Gr,Gm],Gr,Gm是两个[0,1]范围内的标量。
C
o
n
v
(
g
r
m
;
β
)
Conv(g_{rm};\beta)
Conv(grm;β)是一个
1
×
1
1×1
1×1的卷积层,可以将特征
g
r
m
g_{rm}
grm的channels数从
C
C
C减少到2。
G
A
P
(
∗
)
GAP(*)
GAP(∗)是空间维度中的global average pooling层,
β
\beta
β是网络参数集合,
σ
(
∗
)
\sigma(*)
σ(∗)是sigmoid函数。
门模块产生了两个不同的标量,代表了外观和运动信息的重要性。然而,它无法强调哪些channels和空间位置是重要的。基于此,我们提出了两个注意力机制模块,叫做CAM和SAM,如下:
C
A
=
S
o
f
t
m
a
x
(
F
C
(
M
a
x
P
o
o
l
i
n
g
(
g
r
m
)
;
β
)
)
CA=Softmax(FC(MaxPooling(g_{rm});\beta))
CA=Softmax(FC(MaxPooling(grm);β))
S
A
=
σ
(
C
o
n
v
(
g
r
m
)
;
β
)
SA=\sigma(Conv(g_{rm});\beta)
SA=σ(Conv(grm);β)
其中
C
A
=
[
c
r
,
c
m
]
CA=[c_r, c_m]
CA=[cr,cm]是两个外观和运动信息的channel attention maps,大小为
C
×
1
×
1
C×1×1
C×1×1。
M
a
x
P
o
o
l
i
n
g
(
∗
)
MaxPooling(*)
MaxPooling(∗)在空间维度内。
F
C
FC
FC是输出为2Cchannels的全连接层。
S
o
f
t
m
a
x
Softmax
Softmax函数应用在每C个channels中。
S
A
=
[
s
r
,
s
m
]
SA=[s_r, s_m]
SA=[sr,sm],
s
r
,
s
m
s_r, s_m
sr,sm是两个spatial attention maps,大小为
1
×
W
×
H
1×W×H
1×W×H。接着,门
[
G
r
,
G
m
]
[G_r, G_m]
[Gr,Gm],channel attention tensors
[
c
r
,
c
m
]
[c_r, c_m]
[cr,cm],spatial attention tensors
[
s
r
,
s
m
]
[s_r, s_m]
[sr,sm]分别和
f
r
,
f
m
f_r, f_m
fr,fm相乘实现importance reweighting(门模块)和attention reweighting(注意力机制模块)。然而,这样的乘积操作可能会丢失一些有用的信息。因此使用以下形式来利用门控特征:
g
r
=
(
G
r
⨂
f
r
)
(
1
+
s
r
⨂
c
r
)
g_r=(G_r\bigotimes f_r)(1+s_r\bigotimes c_r)
gr=(Gr⨂fr)(1+sr⨂cr)
g
m
=
(
G
m
⨂
f
m
)
(
1
+
s
m
⨂
c
m
)
g_m=(G_m\bigotimes f_m)(1+s_m\bigotimes c_m)
gm=(Gm⨂fm)(1+sm⨂cm)
其中
⨂
\bigotimes
⨂表示element-wise multiplication with broadcast(对应元素点乘)。最后输出相加得到融合特征
g
A
M
F
M
=
g
r
+
g
m
g^{AMFM}=g_r+g_m
gAMFM=gr+gm。
问题:什么是MaxPooling在空间维度内?
回答:每个通道都是一个空间维度,这个意思就是说在每个通道里分别做MaxPooling。
问题:如何理解element-wise multiplication with broadcast中的broadcast?
回答:比如说你用一个1通道的和C通道的进行element-wise的相乘或者相加 broadcast意思就是相当于把这个1通道的复制成C通道 这样就能element-wise对应起来了。
3.5. Temporal information enhanced module
虽然外观-运动模块可以有效地融合外观信息和运动信息,但我们仍然观察了不太好的预测当我们单独使用外观-运动模块时。我们认为出现这种情况的原因有两个:1.光流图只能提供两个临近帧的时间信息,无法保留长期的时间信息。2.作为带有外观特征的流特征,一些低质量的流可能为网络带来噪音,导致预测恶化。
为了解决这个问题,我们通过采用双向的ConvLSTM建立了长期时间信息模型来加强约束cross-frames的空间和时间信息,模型称为r “Temporal information enhanced module” (TIEM) 。传统方法只在最高的level上添加temporal model,而我们在在每个AMFM后面都添加TIEM以提升视频帧之间的每个feature level的信息流。
通过双向的ConvLSTM,我们从前传和后传ConvLSTM单元得到了隐层
H
t
f
,
H
t
b
H_t^f, H_t^b
Htf,Htb,如下所示:
H
t
f
=
C
o
n
v
L
S
T
M
(
H
t
−
1
f
,
g
t
A
M
F
M
;
γ
)
H_t^f=ConvLSTM(H_{t-1}^f, g_t^{AMFM}; \gamma)
Htf=ConvLSTM(Ht−1f,gtAMFM;γ)
H
t
b
=
C
o
n
v
L
S
T
M
(
H
t
+
1
b
,
H
t
f
;
γ
)
H_t^b=ConvLSTM(H_{t+1}^b, H_t^f; \gamma)
Htb=ConvLSTM(Ht+1b,Htf;γ)
s
t
T
I
E
M
=
C
o
n
v
(
C
a
t
(
H
t
f
,
H
t
b
)
;
γ
)
s_t^{TIEM}=Conv(Cat(H_t^f, H_t^b); \gamma)
stTIEM=Conv(Cat(Htf,Htb);γ)
其中
g
t
A
M
F
M
,
s
t
T
I
E
M
g_t^{AMFM}, s_t^{TIEM}
gtAMFM,stTIEM分别是AMFM和TIEM中得到的特征。
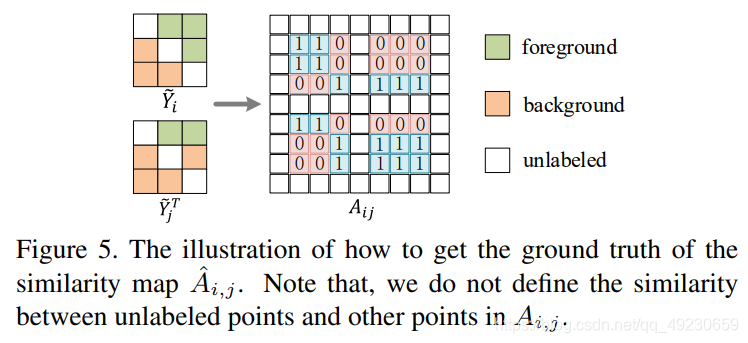
3.6. Foreground-background similarity loss
《Weakly-supervised salient object detection via scribble annotations》从独立的静止图像中学习显著性,然而我们的模型用眼动点scribbles学习视频显著性,这样临近帧的标注是相关的。相邻帧的冗余使得可以重复使用其他帧的涂鸦注释来监督当前帧。 另外,我们观察到如果没有每个像素的标注,网络难以分辨出每个像素点。受《Context prior for scene segmentation》启发,我们提出了“Foreground-background similarity loss”去充分利用弱监督标注,对临近帧的所有点建立关系。我们认为一些类别(两帧的显著性区域或两帧的背景)的特征的similarity应该比不同类别之间的大。基于此,我们首先计算了两个特征图的similarity。更具体地说,对于第
i
i
i帧特征图
f
i
f_i
fi和第
j
j
j帧特征图
f
j
f_j
fj,我们首先使用一个
1
×
1
1×1
1×1的卷积层把它们映射到一个embedding space(embedding)。随后,reshape它们成
C
×
W
H
C×WH
C×WH大小。然后我们在sigmoid激活函数
σ
\sigma
σ后面做矩阵乘积得到similarity map
A
^
\hat{A}
A^,大小为
H
W
×
H
W
HW×HW
HW×HW。如下所示:
A
^
i
,
j
=
σ
(
C
o
n
v
(
f
i
)
T
C
o
n
v
(
f
j
)
)
{\hat{A}}_{i,j}=\sigma(Conv(f_i)^TConv(f_j))
A^i,j=σ(Conv(fi)TConv(fj))
其中
C
o
n
v
(
∗
)
Conv(*)
Conv(∗)是一个
1
×
1
1×1
1×1的卷积层。
A
^
i
,
j
{\hat{A}}_{i,j}
A^i,j表示第
i
i
i帧和第
j
j
j帧之间的similarity map。然后我们需要建立一个gt map去监督
A
^
i
,
j
{\hat{A}}_{i,j}
A^i,j。通过给定的第
i
i
i帧弱监督标注
Y
i
Y_i
Yi,我们首先对其下采样到和特征图
f
i
f_i
fi同样大小,这样我们就得到了一个更小的标注
Y
~
i
\tilde{Y}_i
Y~i。我们将
Y
~
i
\tilde{Y}_i
Y~i前景部分encode成[1,0],背景为[0,1],这样的话tensor
Y
~
i
\tilde{Y}_i
Y~i的大小是
2
×
H
×
W
2×H×W
2×H×W。然后,把它reshape成
2
×
H
W
2×HW
2×HW的大小。同样地我们也对第
j
j
j帧做同样的操作得到
Y
~
j
\tilde{Y}_j
Y~j。然后,我们再次做矩阵乘法得到
A
i
,
j
=
Y
~
i
Y
~
j
T
A_{i,j}=\tilde{Y}_i \tilde{Y}_j^T
Ai,j=Y~iY~jT,大小为
H
W
×
H
W
HW×HW
HW×HW。我们在Fig. 5中将这一过程可视化。注意以上这些所有操作都在被标注的像素点上进行,意味着对于没有标注的像素点不做similarity的计算。我们使用
J
J
J代表
A
i
,
j
A_{i,j}
Ai,j的点的集合。然后我们改编partial cross entropy loss去监督similarity map:
L
s
i
,
j
=
−
∑
u
,
v
∈
J
(
A
u
,
v
l
o
g
A
^
u
,
v
+
(
1
−
A
u
,
v
)
l
o
g
(
1
−
A
^
u
,
v
)
)
L_s^{i,j}=-\sum_{u,v\in J}(A_{u,v}log\hat{A}_{u,v}+(1-A_{u,v})log(1-\hat{A}_{u,v}))
Lsi,j=−u,v∈J∑(Au,vlogA^u,v+(1−Au,v)log(1−A^u,v))
假设每次迭代我们有
T
T
T帧,我们就能计算出当前帧和其他帧及自身的similarity loss,总的loss如下所示:
L
s
=
∑
i
=
1
T
∑
j
=
i
T
L
s
i
,
j
L_s=\sum_{i=1}^T\sum_{j=i}^TL_s^{i,j}
Ls=i=1∑Tj=i∑TLsi,j
问题:这样求loss的优势在哪里?
回答:就是真实标注的similarity和预测的similarity应该是接近的。
3.7. Loss Function
如Fig. 2所示,我们用partial cross entropy loss
L
c
L_c
Lc和foreground-background similarity loss
L
s
L_s
Ls去训练我们的模型。除此之外,还使用了gated structure-aware loss
L
g
L_g
Lg和edge loss
l
e
l_e
le。为了简洁,我们没有在Fig. 2中显示
L
g
L_g
Lg和
l
e
l_e
le。
L
s
,
L
g
L_s, L_g
Ls,Lg和
l
e
l_e
le是从静止图像的scribble标注中学习的loss,
L
s
L_s
Ls是从一系列帧中学习的loss。根据传统视频显著性检测的pipeline,我们用RGB显著性检测数据集进行预训练。不同的是,我们使用scribble标注数据集,叫做S-DUTS。然后,我们用眼动点scribble标注微调网络。为了预训练网络,我们这样定义loss:
L
p
r
e
t
r
a
i
n
=
β
1
⋅
L
c
+
β
3
⋅
L
g
+
β
4
⋅
L
e
L_{pretrain}=\beta_1\cdot L_c+\beta_3\cdot L_g+\beta_4\cdot L_e
Lpretrain=β1⋅Lc+β3⋅Lg+β4⋅Le
然后我们用以下的损失函数微调网络:
L
f
i
n
e
=
β
1
⋅
L
c
+
β
2
⋅
L
s
+
β
3
⋅
L
g
+
β
4
⋅
L
e
L_{fine}=\beta_1\cdot L_c+\beta_2\cdot L_s+\beta_3\cdot L_g+\beta_4\cdot L_e
Lfine=β1⋅Lc+β2⋅Ls+β3⋅Lg+β4⋅Le
根据经验,
β
1
=
β
2
=
β
4
=
1
,
β
3
=
0.3
\beta_1=\beta_2=\beta_4=1, \beta_3=0.3
β1=β2=β4=1,β3=0.3
3.8. Saliency boosting strategy
我们基于眼动点scribble标注的算法有着具有竞争力的表现。此外,我们注意到SOD算法也能在VSOD数据集上获得合理的结果。受《Weakly supervised salient object detection with spatiotemporal cascade neural networks》启发,我们提出了一种基于伪标注的显著性一致性增强技术(saliency consistency based pseudo label boosting technique),其受SOD模型的指导以进一步提炼我们的标注信息。
具体来说,我们采用EGNet生成RGB图像的saliency maps和我们视频显著性检测数据集的光流,分别记作
p
r
g
b
p_{rgb}
prgb和
p
m
p_m
pm。在这里,选择其他的SOD方法也是合理的。根据《A plug-and-play scheme to adapt image saliency deep model for video data》做的工作,我们选择
p
r
g
b
p_{rgb}
prgb和
p
m
p_m
pm的交集作为融合的saliency map
p
=
p
r
g
b
⨀
p
m
p=p_{rgb}\bigodot p_m
p=prgb⨀pm,用来捕捉
p
r
g
b
p_{rgb}
prgb和
p
m
p_m
pm的一致的显著性区域。我们的基本假设是
p
p
p包含了所有的前景scribble,且没有覆盖到背景scribble。基于此,我们将
p
p
p的quality score定义为:
s
c
o
r
e
=
∣
∣
T
(
p
)
⨀
s
f
o
r
e
∣
∣
0
∣
∣
s
f
o
r
e
∣
∣
0
⋅
(
1
−
∣
∣
T
(
p
)
⨀
s
b
a
c
k
∣
∣
0
∣
∣
s
b
a
c
k
∣
∣
0
)
score=\frac{||T(p)\bigodot s_{fore}||_0}{||s_{fore}||_0}\cdot(1-\frac{||T(p)\bigodot s_{back}||_0}{||s_{back}||_0})
score=∣∣sfore∣∣0∣∣T(p)⨀sfore∣∣0⋅(1−∣∣sback∣∣0∣∣T(p)⨀sback∣∣0)
其中
T
(
∗
)
T(*)
T(∗)二值化saliency map,threshold为0.5。
∣
∣
∗
∣
∣
0
||*||_0
∣∣∗∣∣0表示
L
0
L0
L0范式。
s
f
o
r
e
,
s
b
a
c
k
s_{fore}, s_{back}
sfore,sback分别是前景和背景scribble,如Fig. 3(d)所示。
quality score的第一部分目的在于评估前景scribble在 p p p的覆盖率,而后部分激励不是背景的scribble尽量与 p p p重合。通过这样的方式,高的quality score表示更好的saliency map p p p。然后我们选择那些quality score超过预设阈值( T r = 0.98 Tr=0.98 Tr=0.98)的saliency maps。对于每个视频序列,我们接下来可以得到一个高质量伪saliency maps的集合 P P P。如果伪saliency maps中的 P P P的数量超过当前视频序列帧数的10%,我们用高质量的伪标签代替scribble标注。否则整个视频序列的标注都不变。我们把这个新的弱监督标注集定义为我们的第一阶段伪标签集合 D b 1 D_{b1} Db1。
对于那些高质量伪标签的视频序列,我们用 D b 1 D_{b1} Db1中的相应标注单独训练。经过了 K K K次(K为当前视频序列大小的8倍)迭代的训练后,我们使用训练好的模型进行推理以获得第二阶段的伪标签集 D b 2 D_{b2} Db2。需要注意的是,第 4.2 节中介绍了训练每个序列的模型作为消融实验“B”。 然后我们将 D b 2 D_{b2} Db2作为我们的增强标注,用 D b 2 D_{b2} Db2来训练我们的整个模型。在训练过程中,如果一帧图像有一个生成的伪标签,我们直接以它作为监督。否则,我们用scribble标注作为监督。在Fig. 6中我们显示了增强标注“Boosted”,清晰展示了增强策略的有效性。

















 665
665

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









