






 该文详细介绍了如何利用Python与CST2021进行联合仿真,更新模型参数,例如变容二极管的R、C值,并导出反射相位数据。首先,设置Python环境及CST的环境变量,接着打开CST项目,避免重复创建DE。然后,定义VBA代码来执行参数更新,最后导出数据并使用VBA执行反射相位数据的收集与导出。此外,还提供了处理多条曲线数据的txt文件拆分方法。
该文详细介绍了如何利用Python与CST2021进行联合仿真,更新模型参数,例如变容二极管的R、C值,并导出反射相位数据。首先,设置Python环境及CST的环境变量,接着打开CST项目,避免重复创建DE。然后,定义VBA代码来执行参数更新,最后导出数据并使用VBA执行反射相位数据的收集与导出。此外,还提供了处理多条曲线数据的txt文件拆分方法。
使用python-cst联合仿真更新参数并导出数据
20250509修改:解决了留下的疑惑,并增加了新的发现。
目的
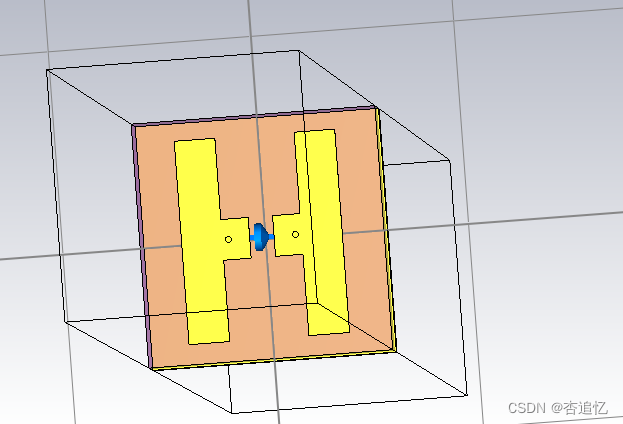
使用python-cst联合仿真对一个已有的CST文件进行指定参数更新、仿真,并导出反射相位数据。在这里,这里使用的是CST2021,以及一个反射超表面项目文件,其模型如下图所示。对模型中间的Lumped Element的RLC串联电路(即变容二极管的等效电路)的R、C值进行更新、测试。
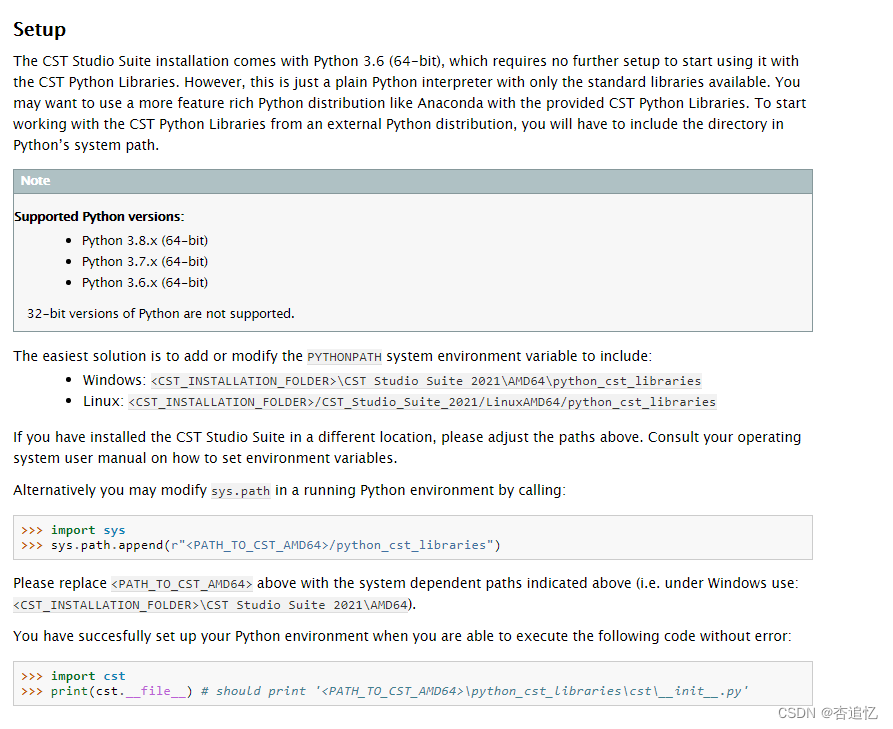
一,确定python环境
通过查看帮助文档可以知道所用的CST版本支持的python版本,并创建相对应的python环境。同时,文档下面还说明了加入环境变量的办法。
二, 设置环境变量
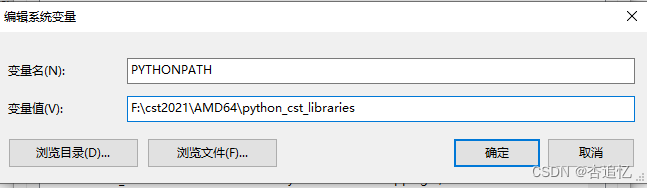
方法1:添加系统变量
在环境变量中添加下图所示的系统变量,AMD64文件在自己的CST安装路径中。
方法2:代码添加
在python代码文件中添加如下代码。注意:此代码必须添加到代码最开始,要不然后面导入cst.interface时会报错。
# 调用cst接口
import sys
cst_lib_path = r"F:\cst2021\AMD64\python_cst_libraries"
sys.path.append(cst_lib_path)
这种代码添加方式只能在当前类中生效。例如:当我在某个py文件使用了该语句,但是另一个py文件在调用cst模块时,可能报错:cst模块未找到。
当然,还有另一种方法可以实现联合仿真,即基于wincom组件,此时,这种方法就和matlab联合仿真思路完全一致。
三,CST项目创建
为了防止DE的重复建立,造成过多的CST进程;以及指定的CST文件的频繁打开。在这里,会先判断DE以及CST文件是否被打开。即:如果DE已被打开,则遍历DE中的所有项目文件,判断指定的CST文件是否已经打开。若已打开,则直接转到此项目;若未打开,则在最后一个DE中打开项目文件。如果DE未被打开,则直接创建一个新的DE,再在其中打开项目文件。
# 打开CST文件
def opencst(cst_path):
# 判断是否存在仿真结果文件,有的话则将其删除
# result_path = cst_path.split('.')[0]
# if os.path.exists(result_path):
# shutil.rmtree(result_path)
allpids = cst.interface.running_design_environments() # 以列表形式返回运行的cst环境名(PIDs)
DE_is_open = False # 判断是否有打开的DE
cst_is_open = False # 判断指定cst文件是否打开
for pid in allpids:
my_DE = cst.interface.DesignEnvironment.connect(pid) # 连接到指定PID的DE
# print(my_DE)
DE_is_open = True
for project_path in my_DE.list_open_projects(): # 返回已打开项目(cst文件)的路径,如果项目中存在未保存的文件、含中文等特殊字符的文件则会报错
# print(project_path)
if cst_path == project_path: # 如果已打开文件存在,直接使用此cst项目
my_project = my_DE.get_open_project(project_path)
cst_is_open = True
break
if not DE_is_open: # DE不存在,则新建一个DE,否则使用上面已打开的最后一个DE
my_DE = cst.interface.DesignEnvironment()
if not cst_is_open: # cst文件未打开,则在最后一个DE中打开指定cst文件
my_project = my_DE.open_project(cst_path)
return my_DE, my_project
四,定义VBA代码执行
sCommand是以列表形式保存的每一行的vba代码,并使用’\n’进行拼接,之后进行宏命令运行(历史书中不显示,等同于在Macro Editor进行编译)。
line_break = '\n' # 用于VBA代码的拼接
# 执行VBA代码
def execute_vba(cst_project, sCommand):
sCommand = line_break.join(sCommand)
res = cst_project.schematic.execute_vba_code(sCommand, timeout=None) # 执行VBA代码
return res
五,参数更新
在这里,对capacitance和resistance两个变量进行参数更新,更新的值位于par_change中。
# 更新参数
sCommand = ['Sub Main()',
f'StoreParameter("capacitance", {par_change[0]})',
f'StoreParameter("resistance", {par_change[1]})',
'RebuildOnParametricChange(False, True)',
'End Sub']
execute_vba(my_project, sCommand)
六,数据导出
由于遍历结果树时,显示的是SZmax(2),Zmax(2)的dB幅度数据曲线,因此,需要先绘制出反射Phase曲线,之后才能将结果导出为txt文件。
可以手动切换为香味数据
# 反射相位数据收集
sCommand = ['Sub Main',
'SelectTreeItem("1D Results\S-Parameters\SZmax(2),Zmax(2)")',
'With Plot1D',
'.PlotView "Phase"',
'.Plot',
'End With',
'With ASCIIExport',
'.Reset',
f'.FileName'
'.Execute',
'End With',
'End Sub']
execute_vba(my_project, sCommand)
由于我目前还不会使用vba代码进行Delete Results操作或者是使得Result Navigator只显示一条曲线, 因此,从第二次结果导出过程开始,导出的txt文件中都会包含之前所有的曲线数据,但会以如图所示的列名来进行分隔。同时,最新的仿真结果一定位于最后一个表格处。
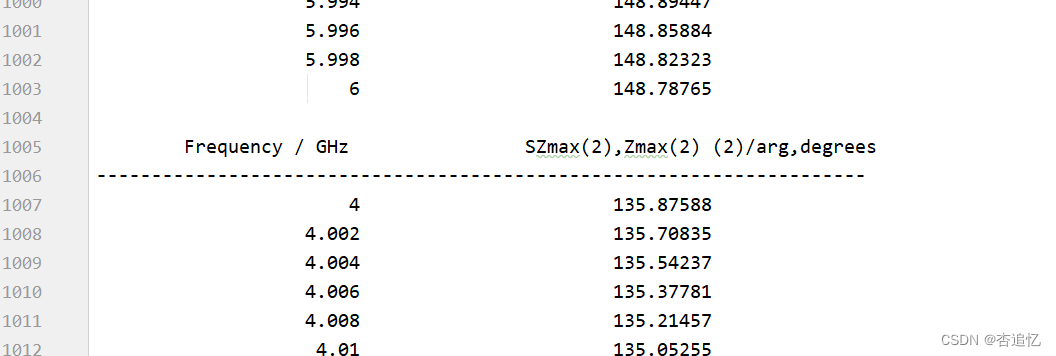
因此,需要对收集到的txt文件进行拆分,以保留最后一个结果。(哈,你说直接保存最后一个表不就得到了所有的数据?我也想啊,可是不知道为啥,曲线序号有时会和仿真序号不匹配。当然,如果你的曲线数据保证不会乱掉,也可以直接在最后一次仿真后进行保存,然后进行表格数据拆分。)
由帮助文档可知,在激活显示的曲线时,有一个绘制参数可以清除内存内的所有曲线,然后重新绘制,在这种情况下,导出的数据才是只有一个。此外,曲线序号有时会和仿真序号不匹配,是因为导出时是按照指定序号进行标定,即绘制时间顺序。而当排序按照参数大小排列时,就会修改其中一个序号,导致乱序。
此外,脚本导出数据时,对于0D/1D数据,使用官方给的接口反而更为直接,根本没必要使用vba代码。同时,还有一种更为简单直接地方式,即通过后处理模板直接导出文件,这样做效率更高更快。
# 对一个txt文件的多个表格进行拆分
def txt_split(txt_path, str_split):
txt_path = txt_path.replace('/', '\\')
all_data = pd.read_csv(txt_path, sep='\t', header=None)
up_index = 0 # 记录表格起始行数下标
# down_index = -1 # 记录表格终止行数下标
for index in range(all_data.__len__()):
if str_split in all_data.iloc[index].__str__():
up_index = index
data = all_data.iloc[up_index:]
save_path = os.path.join(r'./data/phase_pro', txt_path.split('\\')[-1])
data.to_csv(save_path, header=None, index=None)


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









