







图解
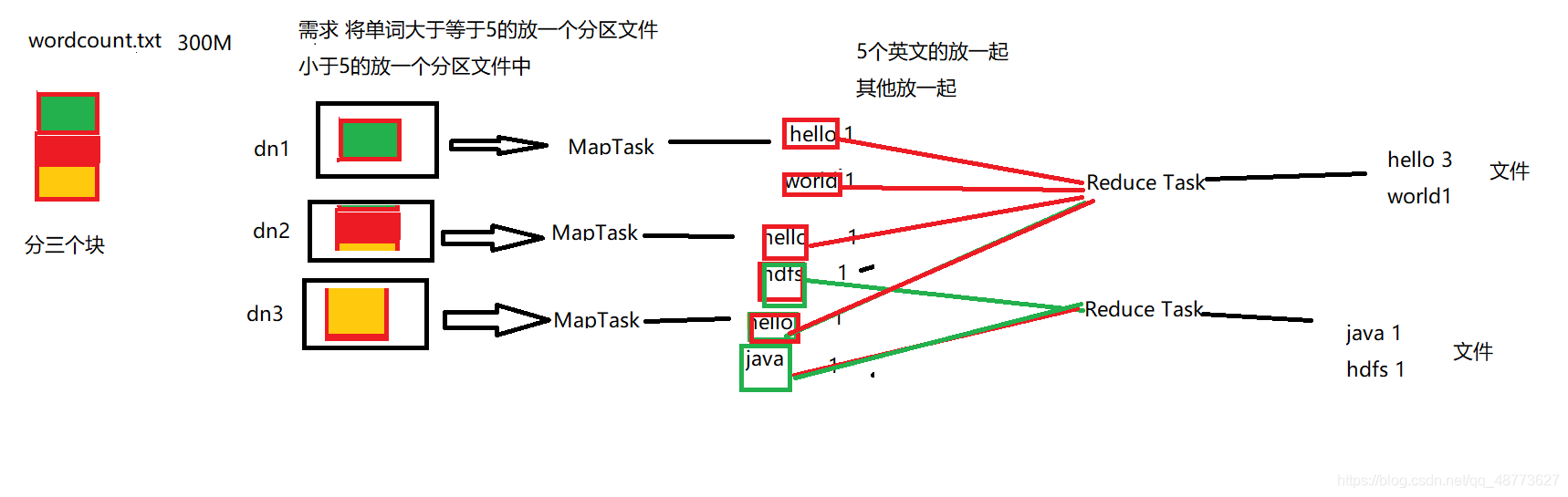
worldcount.txt 300M的单词文件分成3个块,map类把单词分开固定为1,redueceTask把大于等于5个单词的放一起,其他的放一起,最后算到各自的分区文件中。
Java代码
编写PartitionerOwn类继承Partitioner进行分区,大于等于5的返回值为0,其他的返回值为1,如果有很多个分区可以在加返回值2、3、4。详情查看Partitioner和HashPartitioner,在idea ctrl+n搜索他们两个查看源代码。
具体PartitionerOwn代码
rg.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
public class PartitionerOwn extends Partitioner<Text, LongWritable> {
@Override
/*
text:表示k2
longWritable:表示v2
i:reduce的个数
*/
public int getPartition(Text text, LongWritable longWritable, int i) {
//如果单词大于等于5的进入一个分区 ---> 第一个reduceTask --->reduce编号为0
if (text.toString().length() >=5 ){
return 0;
}else {
//如果单词小于5的进入一个分区 ---> 第二个reduceTask --->reduce编号为1
return 1;
}
}
}
去job里增加
//设置我们的分区类
job.setJarByClass(PartitionerOwn.class);
//设置reduce的个数
job.setNumReduceTasks(2);
结果
看分成两个文件了


















 267
267

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









