







 本文介绍了MapReduce中的三种分区方式:默认分区、自定义分区及全局排序。默认分区使用HashPartitioner类实现,自定义分区需继承Partitioner类并实现getPartition()方法,而全局排序则在所有数据收集完毕后进行。
本文介绍了MapReduce中的三种分区方式:默认分区、自定义分区及全局排序。默认分区使用HashPartitioner类实现,自定义分区需继承Partitioner类并实现getPartition()方法,而全局排序则在所有数据收集完毕后进行。
何时分区
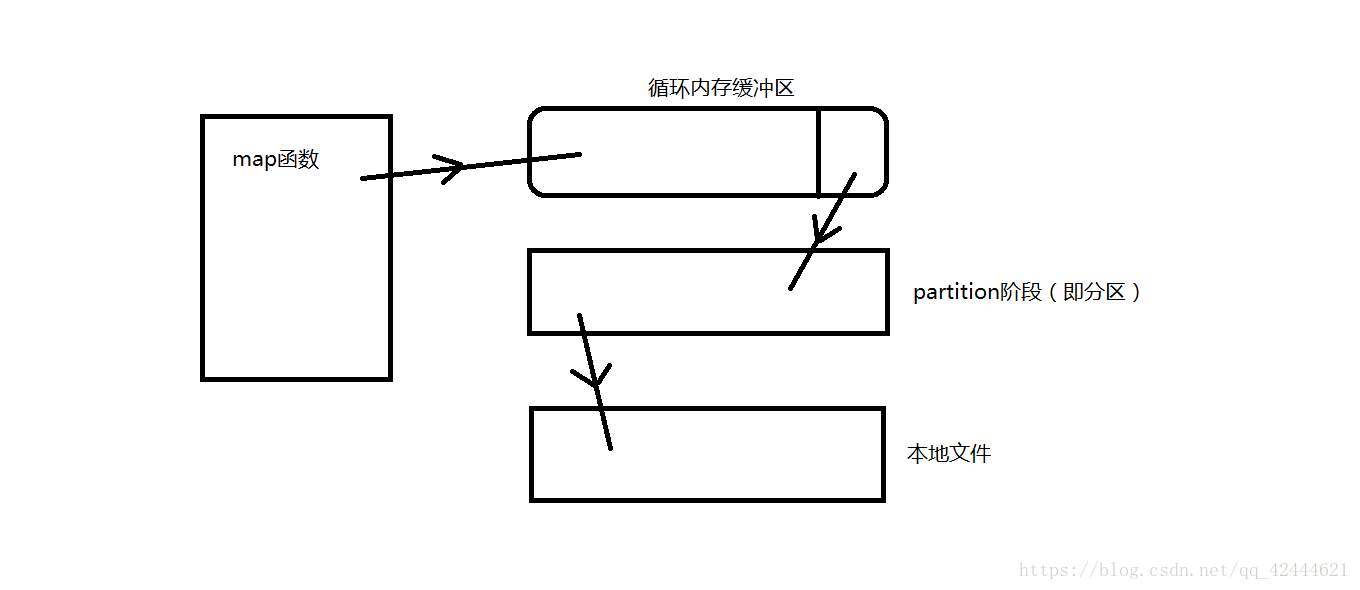
当map函数输出数据到循环内存缓冲区,数据达到循环内存缓冲区的阀值时,会将数据溢写到文件中,在写入文件之前会对数据进行分区
分区分类及如何实现
第一种:默认分区
系统自动调用HashPartitioner类进行分区,原码如下:
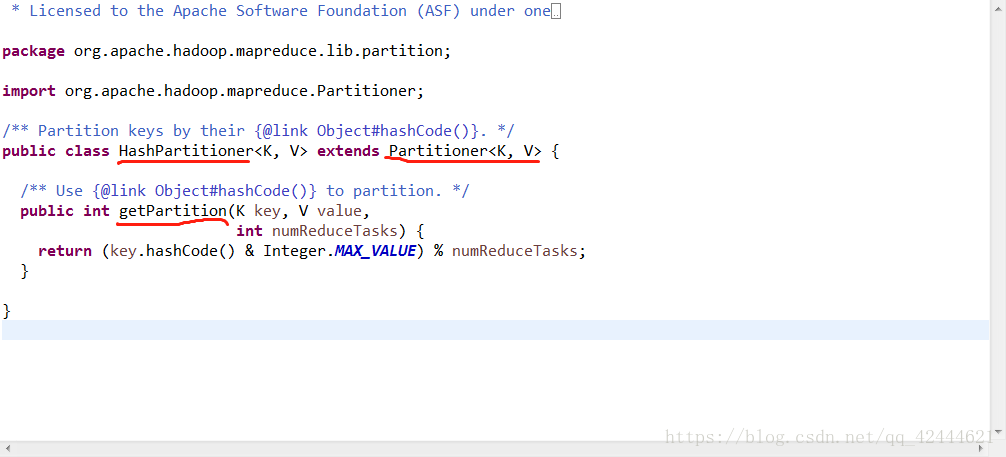
该类通过继承Partitioner类实现分区,将key的哈希值与integer的最大值做&运算,并%1来设置分区
第二种:自定义分区
1、 创建一个类并继承Partitioner类<K,V>
K-------------map函数的输出key类型
V-------------map函数的输出value类型
2、实现getPartition()方法,在该方法中设置分区逻辑
第三种:全局排序

















 6553
6553

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









