







摘 要
随着交通工具的不断发展,交通事故已成为危害人类安全的主要隐患之一。据统计,全球每年有超过100万人死于 交通事故,而疲劳驾驶则是道路交通安全的主要隐患之一。由于疲劳驾驶会导致驾驶员反应能力、判断力和注意力等方面的下降,从而增加交通事故的风险。因此,本研究旨在采用视觉性检测的方法来研究驾驶员的人眼疲劳。该方法利用Matlab的图像处理能力和编程方式,对包含人脸的视频帧系列图像进行处理,通过灰度积分投影技术的眼睛定位方法准确地定位眼睛。接下来,通过PERCLOS计数和眨眼率的计算方法获得准确的疲劳状态,以对驾驶员的疲劳状态进行准确的监测和评估,并及时提醒驾驶员休息,降低疲劳驾驶带来的风险。
With the rapid development of transportation, traffic accidents have become one of the main hidden dangers endangering human safety. According to statistics, more than 1 million people die in traffic accidents worldwide every year. Among them, fatigue driving is one of the main hidden dangers of road traffic safety, because fatigue driving will lead to a decrease in the driver's reflexes, judgment and attention, thereby increasing the risk of traffic accidents. Therefore, this project aims to study the human eye fatigue of drivers using visual detection methods. This method uses Matlab's image processing capabilities and programming methods to process video frame series images containing faces. Then, the eye positioning method of grayscale integral projection technology is used to accurately locate the eye. Then, through the method of perclos counting and blink rate calculation, the accurate fatigue status is obtained to accurately monitor and evaluate the driver's fatigue state, and remind the driver to rest in time to reduce the risk caused by fatigue driving.
Keywords: MATLAB, image processing, grayscale integral projection technology, perclos counting
1 绪 论
1.1 疲劳驾驶预警系统设计的背景和意义
疲劳驾驶是导致交通事故的主要原因之一,而在现代社会中,交通事故已成为一个极为严重的问题。据统计,全球每年因交通事故导致的死亡人数高达60万人,其中57%的灾难性事故与疲劳驾驶有关。在中国,疲劳驾驶同样是导致交通事故的主要原因之一,每年约有9,000人死于疲劳驾驶所致的交通事故。这些数据表明,疲劳驾驶已成为严重威胁公共秩序和驾驶员生命安全的问题。
为了避免疲劳驾驶造成的交通事故,许多研究者开始研究开发疲劳驾驶预警系统。疲劳驾驶预警系统通过监测驾驶员的状态来提醒驾驶员注意安全,从而降低交通事故的发生率。这种系统可以通过监测驾驶员的脸部表情、眼部动作、心率和皮肤电阻等指标来识别疲劳驾驶的迹象,从而预测驾驶员的疲劳程度。当驾驶员出现疲劳驾驶迹象时,预警系统会发出提醒或警报,以便驾驶员及时采取措施,避免交通事故的发生。
总之,疲劳驾驶预警系统的研发和推广对于保障道路交通安全和驾驶员生命安全具有重要意义。随着科技的不断发展和应用,相信疲劳驾驶预警系统将会越来越普及,成为一个不可或缺的安全装备,进一步提升道路交通的安全性和可靠性。
疲劳驾驶预警系统设计的意义在于能够有效地提高驾驶员的安全性和道路交通的安全性。通过提醒疲劳驾驶的驾驶员及时采取措施,减少因疲劳驾驶引起的交通事故,从而保护驾驶员和其他路上的人的生命安全。另外,疲劳驾驶预警系统也可以提高道路交通的效率和可持续性。当驾驶员因疲劳而造成交通事故时,不仅会造成人员伤亡和财产损失,还会对道路交通的流畅性造成影响。疲劳驾驶预警系统能够减少交通事故的发生率,提高道路交通的效率和可持续性。
1.2 国内外疲劳驾驶研究现状综述
随着交通事故的不断增多,疲劳驾驶问题越来越受到重视,国内外也涌现出了众多的疲劳驾驶研究。在国外,疲劳驾驶研究已经有很长的历史,许多先进的技术和理论也已经应用于疲劳驾驶预警系统的研究和开发。在国内,尽管疲劳驾驶研究的时间不长,但随着近年来国内交通事故的不断增加,疲劳驾驶问题也越来越受到关注,国内的疲劳驾驶研究也逐渐得到了加强和发展。
国外疲劳驾驶研究主要集中在疲劳驾驶特征、疲劳驾驶检测和疲劳驾驶预警系统等方面。疲劳驾驶特征方面,许多研究表明,疲劳驾驶者的心理和生理状态会发生改变,如反应时间变慢、注意力不集中、动作不协调等。此外,疲劳驾驶者的行为也会有所不同,如频繁打哈欠、眼睛发涩、头痛等。针对这些疲劳驾驶特征,研究者们采用了各种方法进行检测和预警,如基于生理指标的检测方法,如瞳孔大小、心率、皮肤电阻等。同时,基于行为特征的检测方法也逐渐成为研究热点,如基于车辆行驶轨迹的检测方法、基于驾驶员操作的检测方法等。
在中国,疲劳驾驶研究的进展相对较慢,但在近年来得到了越来越多的关注和研究。疲劳驾驶预警系统作为疲劳驾驶研究的一项重要成果,近年来在国内也得到了广泛的应用和推广。目前,国内外研究者们主要关注的是疲劳驾驶预警系统的精度和可靠性,以及其在实际驾驶中的应用效果。国内外研究者们采用了多种不同的方法来研究疲劳驾驶预警系统。
在国外,早在20世纪80年代,欧洲就开始了疲劳驾驶预警系统的研究。目前,国外研究者们主要采用了两种方法来实现疲劳驾驶预警系统:一种是通过生理信号检测,另一种则是通过车辆行为特征检测。
生理信号检测法是一种比较成熟的疲劳驾驶预警系统研究方法。该方法通过检测驾驶员的生理信号,如眼动、心率、呼吸等来识别疲劳驾驶。比如,美国斯坦福大学的研究者们开发了一种基于头部姿态和眼睛运动的疲劳驾驶检测系统,该系统通过检测驾驶员头部的姿态和眼睛的运动情况,来识别疲劳驾驶。日本研究者们也开发了一种基于呼吸节律的疲劳驾驶检测系统,该系统通过检测驾驶员的呼吸节律来识别疲劳驾驶。
车辆行为特征检测法则是一种新兴的疲劳驾驶预警系统研究方法。该方法通过检测车辆行为特征,如车辆速度、方向盘转动、刹车等,来判断驾驶员是否疲劳驾驶。比如,美国佛罗里达大学的研究者们开发了一种基于车辆行为特征的疲劳驾驶检测系统,该系统通过检测车辆的速度和方向盘转动情况,来识别疲劳驾驶。
总之,疲劳驾驶是一个十分严重的问题,会危及驾驶员的生命安全,也会对公共秩序和交通安全造成威胁。目前,疲劳驾驶预警系统已经成为解决这个问题的一种有效手段。未来,研究人员将继续探索更加先进、精准的疲劳驾驶检测技术,以确保道路交通的安全和稳定。
1.3 课题研究方案
本文基于MATLAB平台设计了一种基于驾驶员眼部疲劳的检测系统。该系统采用了非接触式的摄像头捕捉驾驶员眼部图像,通过分析眼睑的开合程度、瞳孔大小等特征参数,来评估驾驶员的疲劳程度。在实验中,我们通过对不同驾驶员在不同时间段下的眼部图像进行采集,并对采集到的数据进行处理和分析,来确定阈值和疲劳评分标准。实验结果表明,该系统能够准确地识别出驾驶员的眼部疲劳状态,并给出相应的警示提示,能够有效地预防交通事故的发生。此外,该系统还具有简单易用、成本低廉、实时性好等优点,具有较高的实用价值和推广。
系统设计包括三个主要部分:人脸识别、人眼识别和疲劳检测。图像获取是整个系统的基础,其目的是获取驾驶员眼部图像或视频。图像获取采用了高清摄像头,并采用自动对焦和自动曝光技术,可以有效地提高采集图像的质量和准确性。在采集图像时,应尽可能减少干扰因素,例如光照条件、头部姿态等,以确保图像的稳定性和可靠性。
1.4 论文总体安排
本文总体安排如下:
第一章:绪论
本章阐述了课题的研究意义,对研究背景也进行了介绍。选择视觉性检测来进行对驾驶员疲劳检测的研究探讨,然后对本文人眼疲劳检测系统的结构体系进行分步介绍。
第二章:人脸检测
本章介绍了一种利用肤色信息实现人脸检测的方法。首先,本章介绍了几种常见的颜色空间以及肤色在颜色空间中的分布特点。为了建立高斯模型,选择颜色空间YCbCr。在得到二值图像后,使用中值滤波去除噪声,并通过形态学处理进一步提取人脸区域。判断人脸区域的高宽比等条件,最终得到经过标定的人脸区域。
第三章:人眼检测定位
本章介绍了利用灰度积分投影法进行人眼检测定位。灰度积分投影法是一种常用的图像处理方法,用于检测和定位图像中的物体。该方法通过计算图像的积分投影值,快速地确定物体在图像中的位置和大小。具体而言,灰度积分投影法将图像转换为灰度图像,然后对其进行积分,得到图像的积分图像。在积分图像中,每个像素值表示该像素点和其左上角区域内所有像素点的灰度值之和。通过计算不同方向上的积分投影值,可以确定物体在图像中的位置和大小
第四章:疲劳状态检测
本章主要介绍了基于视觉的方法来检测驾驶员的疲劳状态,重点介绍了一种常用的算法PERCLOS。
第五章:总结与展望
本章根据全文所用的方法的结果对疲劳检测技术的未来发展进行个人的展望
2 人脸检测
2.1 引言
人脸检测是计算机视觉领域中的一项重要任务,它在许多应用领域中扮演着关键角色。随着科技的不断发展,人工智能、计算机视觉技术在生活中得到了广泛应用,如人脸识别、人机交互、安防监控等。而人脸检测作为其中的一项重要技术,具有着广阔的应用前景。人脸检测的目的是从输入的图像或者视频序列中检测出可能包含人脸的区域,并对其进行定位和标记。在过去的几十年中,人脸检测技术已经有了巨大的进步。早期的方法是基于传统的特征提取和分类器,如Haar特征和Adaboost分类器,但这种方法的缺点是计算速度慢、准确率低,因此无法满足实时应用的需求。近年来,随着深度学习技术的发展,基于卷积神经网络(CNN)的人脸检测方法被广泛研究和应用,取得了很大的成功。
人脸检测在许多应用场景中都具有重要意义。例如,安防领域中的人脸识别技术,能够有效地识别和追踪嫌疑人,提高犯罪侦查效率;在视频监控中,人脸检测可以实现自动抓拍和识别,帮助安保人员发现异常情况并及时处理;在人机交互中,通过检测人脸,可以实现基于面部表情的交互,提高用户体验。此外,人脸检测还可以用于图像处理、图像编辑、人像美化等领域。总的来说,人脸检测作为计算机视觉领域中的一个重要任务,在众多领域中都具有广泛的应用前景和深远的影响。本文将介绍一些常用的人脸检测方法,并对其进行分析和比较,以期提供一些参考和启示,为后续的研究和应用提供支持。
2.2 人脸颜色空间
人脸颜色空间可以被广泛应用于人脸图像处理、人脸识别、人脸表情识别、人脸年龄估计、肤色检测、虚拟化妆等领域。通过对颜色空间的处理,可以提高人脸图像的质量、增强特征、减少噪声等。例如,人脸识别系统需要对人脸图像进行特征提取,其中颜色信息是很重要的一部分。使用不同的颜色空间,可以有效地提取不同的颜色特征,增强人脸识别系统的准确率和鲁棒性。常见的人脸颜色空间包括 RGB、HSV、YCbCr 等
此外,人脸颜色空间的处理方法也可以帮助解决一些人脸识别中的实际问题。例如,在肤色检测中,可以使用YCbCr颜色空间来检测人脸中的肤色区域,从而实现对肤色区域的有效分割和提取;在虚拟化妆中,可以使用 HSV 颜色空间来对人脸进行颜色转换和化妆模拟,实现更加真实的化妆效果。总之,人脸颜色空间是人脸图像处理中非常重要的一环,对于提高人脸识别的准确率、降低噪声、增强特征等方面都具有重要作用。
2.2.1 RGB颜色空间简介
RGB 颜色空间是一种常用的颜色空间,它是将颜色信息分解成红、绿、蓝三个分量进行描述的,其中红、绿、蓝三个分量分别表示图像中红色、绿色和蓝色的强度。在人脸图像处理中,使用 RGB 颜色空间可以对图像进行基础的颜色处理,如对颜色分量进行增强或降低。在人脸识别中,使用 RGB 颜色空间可以进行一系列基础的颜色处理操作。其中,最常见的是对颜色分量进行增强或降低。例如,如果要增强人脸图像中的红色分量,可以将每个像素的红色分量值增加一个常量值,以此来增强整个图像中的红色强度。同理,如果要降低图像中的绿色分量,可以将每个像素的绿色分量值减少一个常量值,从而降低图像中的绿色强度。此外,在 RGB 颜色空间中,也可以进行一些其他的颜色处理操作,如颜色平衡、色彩校正、色彩映射等。其中,颜色平衡可以调整整个图像的色调,使得整个图像的颜色更加均衡;色彩校正可以对不同设备上显示的颜色进行调整,以确保图像颜色的一致性;色彩映射可以将一种颜色空间中的颜色信息映射到另一种颜色空间中,以便进行更加精确的颜色分析和处理。
总之,RGB 颜色空间是人脸图像处理中常用的颜色空间之一,其基础的颜色处理操作可以用于提高人脸图像的质量、增强特征、减少噪声等。此外,还可以通过进一步的颜色处理操作,实现更加复杂的人脸图像分析和处理。
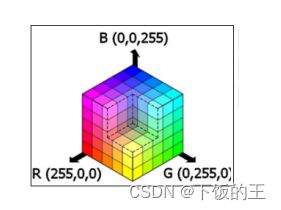
图2.1 RGB颜色空间图
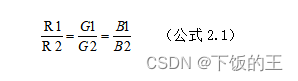
如下列公式2.1中可以发现,RGB 颜色空间中,人脸的颜色受光照的影响,但是对同一点,在不同亮度下的相应值是成比例的。
2.2.2 HSV颜色空间简介
HSV 颜色空间是将颜色信息分解成色调(Hue)、饱和度(Saturation)和亮度(Value)三个分量进行描述的。色调表示颜色在色轮上的位置,饱和度表示颜色的纯度,亮度表示颜色的明暗程度。在人脸识别中,使用 HSV 颜色空间可以对颜色进行更细致的调节,如改变图像的色调、饱和度和亮度等。与 RGB 颜色空间不同,HSV 颜色空间描述的不是颜色的分量,而是颜色的属性。HSV 颜色空间中,色调的取值范围为 0 到 360 度,表示颜色在色轮上的位置;饱和度的取值范围为 0 到 100%,表示颜色的纯度;亮度的取值范围为 0 到 100%,表示颜色的明暗程度。
在人脸识别中,使用 HSV 颜色空间可以对颜色进行更加细致的调节。其中,最常见的是改变图像的色调、饱和度和亮度。例如,如果要增加图像的饱和度,可以将每个像素的饱和度值增加一个常量值,从而使得整个图像的颜色更加鲜艳。同理,如果要调节图像的亮度,可以将每个像素的亮度值增加或减少一个常量值,以此来改变整个图像的明暗程度。此外,在 HSV 颜色空间中,还可以进行一些其他的颜色处理操作,如颜色分割、颜色调整、色彩映射等。其中,颜色分割可以将图像中的不同颜色分割成不同的区域,以便进行更加精细的颜色处理;颜色调整可以调整图像中的颜色分布,使得整个图像的色调更加均衡;色彩映射可以将一种颜色空间中的颜色信息映射到另一种颜色空间中,以便进行更加精确的颜色处理。
总之,HSV 颜色空间是人脸图像处理中常用的颜色空间之一,其细致的颜色调节操作可以用于优化图像的颜色、增强特征、减少噪声等。此外,还可以通过进一步的颜色处理操作,实现更加复杂的人脸图像分析和处理。HSV 颜色空间可由在三维空间直观表示出,如图 2-2 所示。
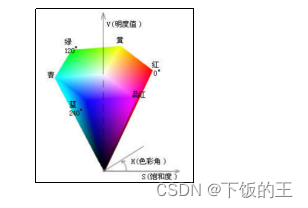
图2.2 HSV颜色空间图
将RGB颜色转换为HSV,可由以下公式转换,其主要是将RGB图像的红色、绿色和蓝色值转换为HSV图像的色调、饱和度和亮度。
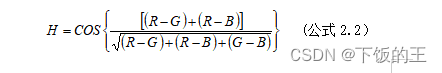

2.2.3 YCbCr颜色空间简介
YCbCr 颜色空间是一种将 RGB 颜色空间转换为亮度(Luminance)和色度(Chrominance)分量的方法。它是数字视频和数字图像处理中广泛使用的一种颜色编码方式。YCbCr 颜色空间的优势在于它可以提高图像或视频的压缩比,同时保持较好的图像质量。在 YCbCr 颜色空间中,Y 表示亮度,Cb 和 Cr 表示色度。其中,亮度表示图像的亮度信息,而色度则包含了图像的颜色信息。相比于 RGB 颜色空间,YCbCr 颜色空间的主要优点在于它将颜色信息分离出来,并采用了亮度和色度分离的方式进行处理,如公式2.6。这样一来,就可以更好地利用图像的特性,以及更加有效地压缩和处理图像或视频数据。在 YCbCr 颜色空间中,Y 分量表示图像的亮度信息。其取值范围为 0 到 255,表示黑色到白色的程度。而 Cb 和 Cr 分量则表示图像的色度信息。它们的取值范围也是 0 到 255,但是它们的范围并不代表任何颜色,而是用于描述相对于亮度的颜色偏差。具体地,Cb 和 Cr 表示的是颜色在蓝色-黄色和绿色-红色两个方向上的偏差。因此,Cb 和 Cr 的值越高,则表示颜色偏向蓝色或绿色;反之,值越低则表示颜色偏向黄色或红色。需要注意的是,Cb 和 Cr 值的取值范围可以是负数或大于 255,这些值的出现是由于压缩编码算法所产生的。
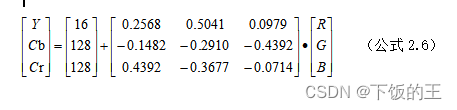
在实际的应用中,YCbCr 颜色空间常常用于数字视频和数字图像的编码和解码。其中,最常见的应用是将 RGB 颜色空间转换为 YCbCr 颜色空间,然后进行压缩和传输。这种方式能够有效地压缩图像和视频数据,并减少传输带宽的需求。
此外,YCbCr 颜色空间还具有一些其他的优点。例如,它能够更好地适应于不同的显示器和设备,因为它可以通过改变亮度和色度来适应不同的设备。同时,YCbCr 颜色空间还可以用于人脸识别和图像处理等领域。通过对 YCbCr 分量的处理,可以实现图像的色彩均衡、对比度调整和色彩平衡等效果,进一步提升图像的质量和清晰度。
除此之外,YCbCr 颜色空间还具有一些特殊的变种,例如 YUV 和 YIQ 颜色空间。其中,YUV 颜色空间是一种类似于 YCbCr 的颜色空间,主要用于模拟电视信号。而 YIQ 颜色空间则是一种专门用于 NTSC (美国电视标准)的颜色空间,它将图像的色度信息进一步分离出来,并根据人眼对颜色的感知特性进行了优化。
总的来说,YCbCr 颜色空间是一种非常有用的颜色编码方式,它不仅能够提高图像和视频的压缩比,同时还能够保持较好的图像质量。在数字视频和数字图像处理中,使用 YCbCr 颜色空间进行颜色编码和解码是非常常见的操作,因为它能够在保证图像质量的前提下,大幅降低传输带宽和存储空间的需求。同时,YCbCr 颜色空间还可以用于图像处理和人脸识别等领域,通过对亮度和色度分量的处理,可以实现多种图像处理效果,提升图像质量和清晰度。
2.2.4 关于人脸颜色空间总结
经过比较和分析,RGB 颜色空间虽然是最常用的颜色表示方式,但由于色度和亮度信息的混合,不太适合用于肤色的定位。HSV 颜色空间能够将颜色的色相、饱和度和亮度分开表示,因此肤色在该颜色空间中具有较好的聚类性,这使得它在肤色定位方面表现出色彩斑块聚类的优势。另一方面,YCbCr 颜色空间在肤色区域的聚类性方面也表现出较好的性能,并且可以通过对其肤色模型进行建模,实现肤色的检测和分割。因此,本文选择 YCbCr 颜色空间作为肤色定位的颜色表示方式,并采用高斯模型进行建模。这样,可以充分利用 YCbCr 颜色空间的聚类性优势,快速准确地定位肤色区域,为后续的人脸识别任务提供可靠的图像处理基础。
2.3 基于 YCbCr 颜色空间的驾驶员人脸检测
基于 YCbCr 颜色空间的人脸检测方法是一种广泛使用的技术,该方法是在 YCbCr 颜色空间中建立肤色模型,并使用这个模型来检测图像中可能存在的人脸区域。在驾驶员人脸检测方面,该方法也得到了广泛应用。由于驾驶员在驾驶时通常处于相对固定的位置和角度,因此可以采用固定的摄像头来进行人脸检测。基于 YCbCr 颜色空间的人脸检测方法可以通过预先设置好肤色阈值,对图像中的肤色区域进行检测,从而实现对驾驶员人脸的快速定位和识别。
在实现基于 YCbCr 颜色空间的驾驶员人脸检测方法时,首先需要收集大量的肤色样本,并计算出相应的肤色模型。然后,将图像从 RGB 颜色空间转换到 YCbCr 颜色空间,将其分解为 Y、Cb、Cr 三个分量。接着,将 YCbCr 颜色空间中的每个像素点与肤色模型进行比较,判断是否属于肤色区域。如果是,则将该像素点标记为肤色区域,否则将其标记为非肤色区域。最后,对肤色区域进行形态学操作,消除不必要的噪声和空洞,并确定人脸区域的边界和位置。虽然基于 YCbCr 颜色空间的人脸检测方法在驾驶员人脸检测方面表现出了优异的性能,但在实际应用中还需要考虑到一些实际问题。例如,肤色的颜色变化会受到不同光照条件和环境因素的影响,因此需要对肤色模型进行动态更新和调整。另外,如果驾驶员佩戴口罩或帽子等物品,也会对肤色区域的检测造成干扰,需要考虑到这些因素对检测结果的影响。
综上所述,基于 YCbCr 颜色空间的人脸检测方法是一种快速、准确的人脸检测技术,可用于驾驶员人脸检测和识别。在实际应用中,需要对肤色模型进行动态更新和调整,并考虑到环境因素对肤色区域检测的影响,才能实现更加可靠和稳定。检测流程图如2.3所示。
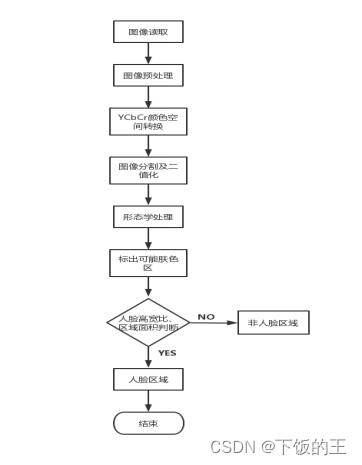
图2.3 驾驶员人脸检测流程图
2.3.1 关于YCbCr颜色空间转换
在 YCbCr 颜色空间中,Y 表示亮度,Cb 和 Cr 表示色度。其中,亮度表示图像的亮度信息,而色度则包含了图像的颜色信息。相比于 RGB 颜色空间,YCbCr 颜色空间的主要优点在于它将颜色信息分离出来,并采用了亮度和色度分离的方式进行处理。这样一来,就可以更好地利用图像的特性,以及更加有效地压缩和处理图像或视频数据。在 YCbCr 颜色空间中,Y 分量表示图像的亮度信息。其取值范围为 0 到 255,表示黑色到白色的程度。而 Cb 和 Cr 分量则表示图像的色度信息。它们的取值范围也是 0 到 255,但是它们的范围并不代表任何颜色,而是用于描述相对于亮度的颜色偏差。Cb 和 Cr 表示的是颜色在蓝色-黄色和绿色-红色两个方向上的偏差。因此,Cb 和 Cr 的值越高,则表示颜色偏向蓝色或绿色;反之,值越低则表示颜色偏向黄色或红色。需要注意的是,Cb 和 Cr 值的取值范围可以是负数或大于 255,这些值的出现是由于压缩编码算法所产生的。图2.4所示YCbCr颜色空间转换效果图。

图2.4 YCbCr颜色空间转换效果图
2.3.2 图像分割及二值化
在YCbCr颜色空间中进行图像分割及二值化可以有效地实现对肤色区域的检测和分割。具体的步骤如下:
1.转换为YCbCr颜色空间:首先需要将图像从RGB颜色空间转换到YCbCr颜色空间。这可以通过将RGB图像中的每个像素点转换为YCbCr空间中的一个向量来实现。转换后,每个像素点都可以用Y、Cb、Cr三个分量来表示。
2.肤色模型的建立:建立一个肤色模型,通过这个模型可以快速地检测图像中的肤色区域。肤色模型可以使用一些经验公式进行建立,如Cr > 1.5Cb + 10或Cb > 0.8Cr + 135等。通过这些公式,可以在YCbCr颜色空间中定义一个肤色区域,这个区域内的像素点被认为是肤色。
3.图像分割:将肤色区域从背景区域中分离出来,可以使用各种分割算法,如基于阈值的分割、基于聚类的分割或者基于边缘的分割等。其中,基于阈值的分割算法是最常用的,其主要思想是将肤色区域和背景区域分别二值化成黑白两个图像,然后将它们进行逐像素地比较。如果两个像素点的颜色值相似,则它们被认为属于同一区域,否则它们属于不同区域。图2.5所示肤色区域分割。
4.二值化:将肤色区域的图像二值化,将其转换为黑白二值图像,可以使用一些常见的二值化算法,如基于全局阈值的二值化、基于局部阈值的二值化或者基于自适应阈值的二值化等。其中,基于自适应阈值的二值化算法是最常用的,其主要思想是在不同的区域使用不同的阈值,以适应图像的不同亮度和对比度。
总之,在YCbCr颜色空间中进行图像分割及二值化可以有效地实现对肤色区域的检测和分割。这种方法在人脸识别、人脸检测等领域有广泛应用,可以有效地提高识别准确率和速度。

图2.5 肤色区域分割
2.3.3 形态学处理
形态学处理是数字图像处理中的一种重要方法,它主要是基于图像中的形态学结构,如边缘、孔洞、连通区域等进行分析和处理。形态学处理常用于图像增强、分割、去噪和形态学重构等领域。
形态学处理主要基于两个基本的图像操作:腐蚀和膨胀。腐蚀操作可以将图像中的小孔洞或者细节消除掉,同时也可以将边缘进行平滑处理;膨胀操作则可以将图像中的连通区域进行扩张或者连接,同时也可以增强边缘的锐化。
形态学处理通常使用结构元素来描述需要处理的图像特征。结构元素是一个小的二值图像,它通常是一个正方形、矩形、圆形或其他形状,它的形状和大小取决于需要处理的特定形态学特征。在进行形态学处理时,结构元素通过滑动的方式对原始图像进行处理,以达到所需的效果。
常用的形态学处理操作包括腐蚀、膨胀、开运算、闭运算、梯度运算、顶帽运算和底帽运算等。膨胀(dilation)和腐蚀(erosion)是形态学处理的两个基本操作。
膨胀可以将目标区域的边缘向外扩张,而腐蚀则可以将目标区域的边缘向内收缩。这两种操作可以被用于一些图像处理任务中,如去噪、边缘检测、图像分割等。膨胀操作可以用一个结构元素(structuring element)来定义,该结构元素通常是一个小的二值图像。对于每个像素点,将结构元素放置在该像素点的中心,如果结构元素与该像素点所在的区域存在重叠部分,那么该像素点的值就被赋为1。这样一来,目标区域的边缘会被扩张出去,从而使得目标区域变大。膨胀操作可以用来填补图像中的空洞、连接图像中的分散的区域以及使边缘更加连续。
腐蚀操作与膨胀操作类似,同样可以用一个结构元素来定义。对于每个像素点,将结构元素放置在该像素点的中心,如果结构元素与该像素点所在的区域完全重叠,那么该像素点的值就被赋为1。如果结构元素和该像素点所在的区域存在不重叠的部分,那么该像素点的值就被赋为0。这样一来,目标区域的边缘会被收缩,从而使得目标区域变小。腐蚀操作可以用来消除图像中的噪点、分离相互重叠的区域以及使边缘更加清晰。
膨胀和腐蚀操作可以结合起来使用,形成一种叫做开运算(opening)和闭运算(closing)的操作。开运算先进行腐蚀操作,再进行膨胀操作,可以用来消除小的噪点和连接相距较远的区域。闭运算则先进行膨胀操作,再进行腐蚀操作,可以用来填补小的空洞和连接相距很近的区域。图2.6为膨胀后效果图。

图2.6 膨胀后效果图
2.3.4 人脸定位
人脸定位是计算机视觉领域中的一项基础技术,它在图像处理、人脸识别等方面都有着重要的应用。在进行人脸定位时,如何从图像中准确地提取人脸区域是非常关键的。本文将介绍一种基于 YCbCr 颜色空间的人脸定位方法。
首先,将图像从 RGB 颜色空间转换到 YCbCr 颜色空间。在 YCbCr 颜色空间中,肤色区域具有较好的聚类性,可以通过阈值分割来提取出肤色区域。一般而言,可以通过试验得到较为合适的阈值。通过这种方式提取出来的肤色区域中可能会包含一些较小的非人脸区域,如手臂或背景中颜色类似于肤色的区域。因此,需要对提取出来的肤色区域进行形态学处理,以去除这些非人脸区域。
对于肤色区域的形态学处理,可以采用开运算和闭运算进行处理。开运算可以去除小的细节部分,而保留大的区域。闭运算可以填充小的空洞,同时保持大的连通区域的形态不变。因此,可以先进行开运算操作,然后进行闭运算操作,以去除非人脸区域并保留人脸区域。
接下来,对得到的二值化图像进行连通区域标记。连通区域标记是指将二值化图像中具有相同像素值的像素点进行分组,并为每个分组分配一个唯一的标记。根据标记的连通性,可以得到二值化图像中的所有连通区域。根据人脸的高宽比和区域面积等条件,可以剔除一些非人脸区域。一般而言,人脸的高宽比在 1:1到 1:2 之间,人脸区域的面积在一定范围内。根据这些条件可以筛选出符合要求的人脸区域,并将其作为人脸定位的结果。通过以上判断,检测到的人脸如图2.8 所示。

图2.8 人脸检测结果
2.3.5 本章小结
本文章介绍了一种基于肤色信息的人脸检测方法。首先,介绍了几种主要的颜色空间以及肤色在颜色空间中的分布情况。接着,选择 YCbCr 颜色空间,根据选取的肤色样本建立了有效的肤色模型。在输入图像后,首先进行几何变换和光照校正,然后将图像从 RGB 颜色空间变换到 YCbCr 颜色空间,通过肤色模型和最佳阈值对人脸进行肤色分割,得到二值图像。为了提高检测结果的准确性,采用中值滤波去噪和形态学处理,进一步优化二值图像的质量。在得到二值图像后,通过判断人脸区域的高宽比和区域面积等条件,剔除了一些可能的非人脸区域,最终得到标定的人脸区域。实验结果表明,该方法能够快速准确地检测出彩色图像中的人脸区域,具有较好的鲁棒性和可靠性。
总的来说,该方法以 YCbCr 颜色空间为基础,充分利用了肤色信息进行人脸定位。通过建立肤色模型和阈值分割等方式,可以快速地将人脸从背景中分离出来。同时,采用中值滤波和形态学处理等技术可以进一步提高检测的准确性和鲁棒性。此外,通过对人脸区域的高宽比和区域面积等条件进行筛选,可以有效地剔除非人脸区域,从而提高了检测的准确性和鲁棒性。
综上所述,该方法在实际应用中具有较好的实用性和可靠性。但是,由于颜色空间和肤色模型的选择与参数调整等因素的影响,该方法在一些特定情况下可能会出现检测不准确的情况。因此,在实际应用中需要根据具体情况进行调整和优化,以达到最佳的检测效果。
3 人眼检测定位
3.1 眼睛的检测方法
眼睛的检测是计算机视觉中的一项重要任务,因为它是人脸识别、情感识别等应用的重要基础。眼睛检测可以分为两个主要步骤:眼睛区域的定位和眼睛状态的分类。一般情况下,眼睛检测会在人脸检测的基础上进行,因为眼睛通常位于人脸的上部区域。眼睛状态的分类是指根据眼睛区域内的像素值判断眼睛状态,如睁开、闭合、眨眼等。本章介绍了几种常见的人眼定位方法:基于特征的方法,基于模板匹配的方法,基于几何学的方法,灰度积分投影法。
3.1.1 基于特征的方法
基于特征的方法是一种常见的眼睛检测方法,该方法通过提取眼睛的特征并利用分类器进行判断来实现眼睛的检测。
首先需要定义眼睛的特征。常见的特征包括眼球和眼眶的形状、眼睛周围的颜色信息等。通过对大量的眼睛图像进行特征提取,可以得到一组代表眼睛的特征向量。接着,需要训练一个分类器。分类器可以根据眼睛的特征向量进行判断,将其分为“眼睛”或“非眼睛”两类。训练分类器需要大量的标注好的眼睛图像和非眼睛图像作为样本,使用机器学习算法进行训练。常用的机器学习算法包括支持向量机(SVM)、神经网络和决策树等。
在实际应用中,对于待检测的图像,可以通过滑动窗口的方式在不同的位置和尺度上进行检测。对于每个窗口,提取眼睛的特征向量并输入到训练好的分类器中进行判断。如果被判断为“眼睛”,则可以将该窗口标记为包含眼睛的区域。
基于特征的方法在眼睛检测中具有较高的准确率和鲁棒性。然而,该方法也存在一些问题。首先,特征的选取和提取需要大量的经验和实验验证。其次,分类器的训练需要大量的标注好的数据集,且该数据集必须具有足够的多样性和代表性,否则可能导致过拟合或欠拟合等问题。此外,滑动窗口的方式在计算量和时间上也存在一定的挑战。总的来说,基于特征的方法是一种较为成熟的眼睛检测方法,其准确率和鲁棒性都得到了不断提高。但是,随着深度学习算法的发展,基于深度学习的方法也逐渐成为了眼睛检测的热门方向。
3.1.2 基于模板匹配的方法
基于模板匹配的方法是另一种常用的眼睛检测方法,它是通过事先准备好的模板来检测眼睛。在这种方法中,通过将已知的眼睛模板与图像中的每个区域进行匹配来检测眼睛的位置。
模板是一个预定义的眼睛形状,在模板匹配之前,需要将模板与图像进行预处理,通常使用灰度化和归一化处理来提高匹配的准确度。灰度化可以将图像转换为灰度图像,去除颜色信息,使图像处理更为简单。归一化处理则是将图像大小和光照条件标准化,使不同图像之间具有可比性。匹配过程中,首先将模板移动到图像的每个可能的位置,对每个位置计算匹配得分,匹配得分越高表示该位置越有可能是眼睛的位置。匹配得分可以使用相关系数或欧氏距离等指标来计算,通常会设定一个阈值,只有当匹配得分超过阈值时才被认为是眼睛的位置。
在实际应用中,模板匹配方法的主要局限是对光照和旋转的敏感性。光照条件的变化可能导致图像中的亮度和对比度不同,这会影响模板匹配的准确性。为了解决这个问题,可以使用多个不同光照条件下的模板来提高匹配的准确性。另外,由于人脸可能会发生旋转,所以模板匹配方法需要对旋转进行校正,通常使用旋转不变特征或Haar-like特征进行处理。基于模板匹配的方法是一种简单而有效的眼睛检测方法,但它对光照和旋转的敏感性限制了其应用范围,需要使用多个不同光照条件下的模板来提高匹配的准确性,并对旋转进行校正。
3.1.3 基于几何学的方法
基于几何学的方法是一种常用于眼睛检测的方法,它通过利用眼睛在人脸中的位置关系和几何特征进行眼睛定位。该方法不需要训练样本,因此比基于特征的方法更加通用。
该方法的基本思路是,先对人脸进行检测和定位,然后根据眼睛在人脸中的位置关系和几何特征,确定眼睛所在的区域。在这个过程中,需要考虑到以下几个因素:
1.眼睛的位置关系:眼睛通常位于人脸的上半部分,且相对位置固定,左右眼之间的距离也是固定的。
2.眼睛的几何形状:眼睛通常呈椭圆形状,且长轴方向与人脸中心轴线垂直。
基于这些几何特征,可以设计一些眼睛检测算法。其中一种常用的方法是基于Hough变换的方法。Hough变换是一种经典的几何学方法,它可以用于在图像中检测几何形状。在眼睛检测中,可以利用Hough变换检测眼睛的椭圆形状。具体方法是,先将图像转化为灰度图像,然后进行边缘检测,得到边缘点集。接着,对每个边缘点,根据它们的梯度方向,在椭圆参数空间中投票,将得票数高的参数组合认为是椭圆的参数。最后,根据得到的椭圆参数,确定眼睛所在的区域。
3.1.4 灰度积分投影法
灰度积分投影法(Gray-Scale Integral Projection)是一种基于灰度图像处理的眼睛检测方法。它利用了灰度图像中眼睛与周围区域的灰度值差异来进行检测,具有计算简单、速度快的优点。
灰度积分投影法的主要思想是,通过对灰度图像进行积分投影,得到一个二维灰度图像的一维投影图,即每行(或每列)的灰度值之和。由于眼睛区域的灰度值通常较高,因此眼睛区域的一维投影图应该具有较大的峰值。基于这个原理,我们可以通过检测灰度图像中的峰值来确定眼睛区域。灰度积分投影法的具体步骤如下:
1.将原始灰度图像进行预处理,包括去噪、增强等,以提高检测的准确性和鲁棒性。
2.对预处理后的灰度图像进行积分投影,得到一维投影图。具体来说,对于每一行或每一列,分别计算从图像顶部或左侧到当前位置的所有像素值之和,并保存到一维投影图中。
3.对一维投影图进行滤波处理,以消除干扰和噪声。通常采用中值滤波、高斯滤波等方法来实现。
4.确定眼睛区域。通过检测一维投影图中的峰值来确定眼睛的位置。一般可以采用峰值检测算法,如基于局部极值的方法或阈值分割的方法。在确定眼睛位置时,可以考虑眼睛的相对位置关系,如两眼间距、眼睛大小等,以进一步提高检测的准确性。
5.最后,可以在原始图像上标记出检测到的眼睛区域,以便进行后续处理或显示。
综上所述,本文选择灰度积分投影法进行人眼定位。
3.2 眼睛区域定位
通过灰度积分投影法实现眼睛区域定位的方法如下:首先将待处理的人脸图像进行灰度化处理,然后计算出水平和竖直方向的灰度积分图像。利用统计学原理,根据人脸区域的平均灰度值和方差,选取适当的阈值进行图像二值化处理。接着,通过计算二值化后的图像的水平和竖直方向的投影函数图像,即每一行或每一列中所有非零像素的个数之和,得到两张投影函数图像。然后利用阈值化、形态学处理等方法,找到投影函数图像中的峰值,即为眼睛所在的位置。最后,通过边缘检测等方法精确定位眼睛的边缘。
具体来说,灰度积分图像可以通过对每个像素进行一次累加来计算。即对于一个像素位置(x,y),它的灰度积分值等于它左边和上方所有像素的灰度值之和。计算完水平和竖直方向的灰度积分图像后,我们就可以得到人脸图像的平均灰度值和方差,并利用二值化技术将图像进行二值化处理。接下来,我们可以计算二值化后的图像的水平和竖直方向的投影函数图像,通过找到投影函数图像中的峰值,可以得到眼睛所在的位置。最后,我们可以利用边缘检测技术精确定位眼睛的边缘。
通过灰度积分投影法进行眼睛区域定位的优点是计算速度快,适合于实时应用场景,同时对光照变化不敏感。但它也有缺点,比如对于眼睛之间的距离较小的人脸图像,可能会出现误检的情况。因此,需要结合其他方法进行综合应用,提高检测的准确率。图3.1 为眼睛定位方法的过程示意图。
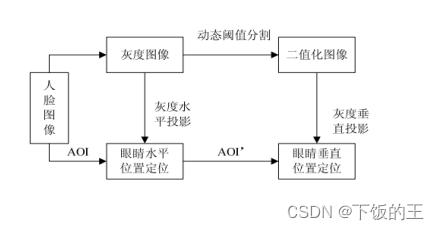
图3.1 眼睛定位方法的过程示意图
3.2.1 人眼水平积分投影
人眼图像中的灰度值在眼睛部位较小,而在其周围部位灰度值比较大,积分投影法正是利用了人眼的这一特征来对人眼进行定位。因此,通过睁眼和闭眼两幅灰度图像,来进行人眼检测的感兴趣区域(Area of Interest,AOI)定位,结果如图3.2 所示。
设图3.2 灰度图像为 F(x, y),则在初步定位人眼的 AOI 区域后,根据眼睛的灰度特征,对 AOI 内的像素灰度进行水平投影,如公式(3.1)。
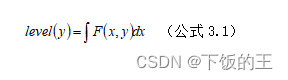

图3.2 眼睛区域初步定位
水平投影结果如图3.3 所示。图 3.3(a)为睁眼水平投影结果,图中白色为有效区域,黑色则为无效区域,其中从上到下第一个波峰处为眉毛以上的额头部分,第一个波谷是眉毛,第二个波峰是上眼睑部分,第二个波谷是瞳孔的位置,第三个波峰就是眼睛到 AOI 区域下边缘的位置。由此,检测出第二个波谷所在的行序号,就可定位眼睛的水平位置。由图 3.3(b)闭眼水平投影结果,也同样可以得到眼睛的水平位置。

图3.3 水平投影结果
3.2.2 人眼垂直积分投影
在眼睛的水平位置确定以及上下边界的粗略定位后,AOI 区域的高度便可以进一步缩小为眼睛的上下边界区域。因此,在 AOI 区域内,类似于人眼水平位置的定位方法,AOI 区域经过二值化后进行垂直灰度投影,如公式(3.2)。
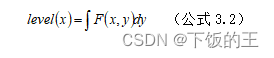
其睁眼与闭眼垂直投影结果如图3.4 所示。从左图中可知,波谷所在位置为眼睛的瞳孔位置,在它的最近左右两侧局部波峰的位置是瞳孔到内外眼角的位置,由此可确定眼睛的左右边界,右图闭眼投影结果与睁眼类似,则可定位眼睛的垂直位置。而睁眼与闭眼的眼睛最终定位结果如图3.5 所示。
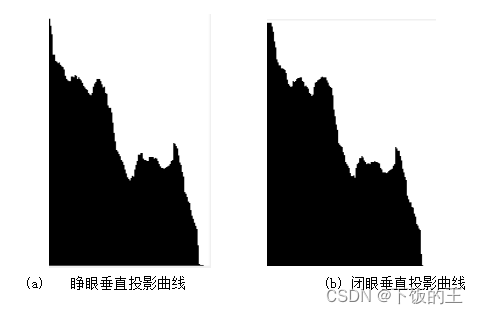
图3.4 垂直投影结果

图3.5 睁眼与闭眼的眼睛最终定位结果
3.3 本章小结
本章主要介绍了如何有效地进行人眼区域的检测定位。在已知的人脸区域内,要检测眼睛,首先需要找到眼睛所在的感兴趣区域(AOI),该区域通常位于面部区域的左上角。接着,在该感兴趣区域内分别对睁眼和闭眼的灰度图像进行水平投影,以确定眼睛的水平位置。然后,根据眼睛水平位置所在行的像素灰度值动态地确定图像的二值化分割阈值。接下来,对二值化后的图像进行垂直投影,以确定眼睛的垂直位置。最后,精确定位眼睛的位置并框出。
4 疲劳状态检测
4.1 引言
随着现代社会对工作和生产力的不断追求,人们往往需要花费更长时间进行工作,尤其是需要长时间盯着电脑屏幕进行办公的人群。长时间的工作会让人感到疲劳,如果疲劳程度加重,就有可能导致操作失误,引发一系列安全问题。因此,对于那些需要长时间从事高度集中的工作的人们,进行疲劳状态检测就显得十分重要。
PERCLOS(Percent of Eye Closure Over Time)是一种常见的疲劳程度指标,它可以通过检测人眼睑运动的方式来计算出闭眼的比例。过去的研究表明,PERCLOS可以在一定程度上反映人的疲劳程度,并且被广泛应用于睡眠研究、驾驶员疲劳监测等领域。基于PERCLOS的疲劳状态检测方法可以通过计算眼睑闭合的百分比来判断一个人的疲劳状态。因此,本章将介绍一个基于PERCLOS计数的方法,来实现对疲劳状态的自动检测。
4.2 PERCLOS 算法简介
PERCLOS(Percent of Eye Closure)算法是一种通过计算闭眼时间占总时间的百分比来评估疲劳状态的方法。该方法基于人的眨眼行为,通过分析眼睑运动的比例来判断疲劳程度。在使用PERCLOS算法时,需要使用红外摄像机或者高速摄像机记录被测者的眼睛运动轨迹,并通过图像处理技术提取眼睛的运动信息。PERCLOS算法的优点在于它是一种非接触式的测量方法,能够实时监测疲劳状态,并且可以在不同工作环境中使用。在实际应用中,PERCLOS算法已被广泛应用于交通运输、航空航天、医疗护理等领域,以提高工作安全性和工作效率。PERCLOS 一般用三种方法进行测量:
P70:眼皮覆盖瞳孔面积超过 70%的时间占测量时间的比例。
P80:眼皮覆盖瞳孔面积超过80%的时间占测量时间的比例。
EM:眼皮覆盖瞳孔面积超过50%的时间占测量时间的比例。
且有实验证明, P80与人眼疲劳状态相关性最好,如图4.1,PERCLOS值如
式(4.1)。

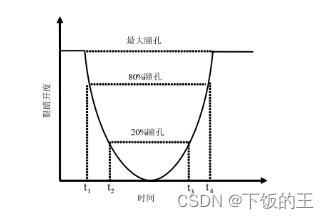
图4.1 PERCLOS 值测量原理
4.3 眨眼的判断检测
PERCLOS算法用于判断驾驶员是否处于疲劳状态,其基于计算单位时间内眼睛闭合的时间来进行判断。为了实现眼睛状态的识别,即判断眼睛是否闭合,本文使用跟踪结果来确定眼睛区域中包含的像素个数。通过计算眼睛区域中包含的黑色像素个数,可以判断眼睛的面积,从而计算PERCLOS值。为此,需要将跟踪到的人眼区域进行二值化处理。在此基础上,将眼睛区域中黑色像素个数与最大面积Cmax相比较,当面积最大时为睁开状态,最小时为闭合状态。定义一个临界值Cmax/5,当眼睛面积超过此值时为睁开状态,否则为闭合状态。通过这种方法,可以有效地判断驾驶员的疲劳状态。图4.2为驾驶员眼睛轮廓椭圆拟合部分结果图

(a) 眼睛睁眼
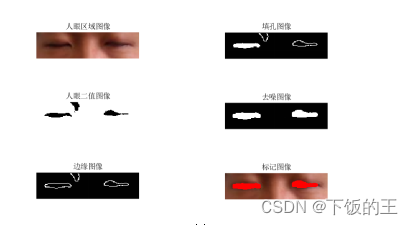
(b) 眼睛闭眼
图4.2 驾驶员眼睛轮廓椭圆拟合部分结果图
4.4 疲劳判断
实验中图像由视频采集并分帧得到,因而眨眼持续时间可以通过帧数累加得到,由此,PERCLOS 算法可修改为公式(4.2)

式中 N 为测量时间t 秒内视频图像的总帧数,n 为测量时间内眼睛闭合图像的帧数。
通过计算单位时间内闭眼的时间,即PERCLOS值,来判断驾驶员是否处于疲劳状态。在实际应用中,一般设置PERCLOS阈值,当PERCLOS值超过阈值时即认为驾驶员处于疲劳状态,需要进行警示或提醒。PERCLOS阈值一般在0.12到0.30之间,具体取值要结合实际情况进行调整。
4.5 实验仿真
实验仿真是一种重要的工具,用于验证设计中用于检测疲劳的算法的效果。通过进行实验仿真,我们可以模拟各种疲劳情况,并评估算法在这些情况下的检测能力。
首先,我们可以利用matlab软件创建一个gui人机交互界面环境,如图4.3所示,然后通过在仿真环境中输入一段视频进行疲劳驾车,再生成这些数据,统计出该视频的闭眼帧图像数目,再利用上述公式4.2就可以判断输出驾驶员是否疲劳。
为了验证算法的检测效果,本设计选择了部分展示,以序列为Video1.avi的视频片段。其中gui运行工作界面如图4.5所示。下图4.4展示了在同一目标检测算法下运行V1视频时所得到的眼睛定位结果。通过观察图中的结果,我们可以看到算法在眼睛定位方面的表现。眼睛定位是一项重要的任务,它能够准确地确定人眼在视频中的位置,为后续的疲劳检测提供关键信息。在图中,我们可以清晰地看到目标检测算法成功地定位了眼睛的位置。算法能够准确地识别眼睛的特征,并在视频中标注出其位置。这种定位的准确性对于疲劳检测算法具有重要的意义,因为它为我们提供了一个可靠的基准。

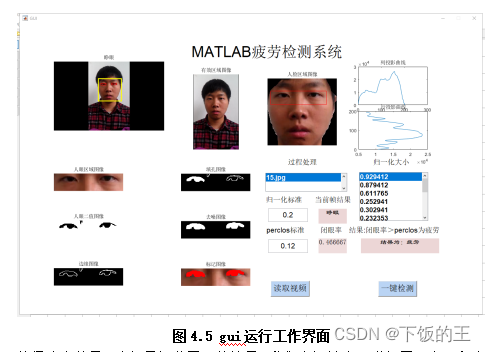
值得注意的是,这仅是部分展示的结果,我们在设计中还进行了更广泛和全面的测试和评估。通过对多个视频序列和不同场景的测试,我们可以对算法的鲁棒性和性能进行更全面的评估。
接下来,根据眼睛运动信息,采用上文所述说的PERCLOS算法进行疲劳评估。因为PERCLOS算法是通过计算闭眼时间占总时间的百分比来评估疲劳状态的方法。即在测量时间内,根据眼睛闭合图像的帧数n和视频图像的总帧数N,计算单位时间内闭眼的时间,即PERCLOS值,使用上述公式(4.2):f = n / N。
如图4.6所示,此视频计算得到的PERCLOS值即闭眼率为f1=0.46667,与预设的阈值f0=0.12进行比较,得出结果f1>f0,所以则认为驾驶员处于疲劳状态,需要进行警示或提醒。
实际应用中,可以根据具体情况调整PERCLOS阈值的取值,以适应不同场景和需求。

4.6 本章小结
本章主要探讨了视觉方法用于疲劳驾驶检测,重点介绍了常用的PERCLOS算法。该算法通过计算眼睑在一段时间内遮盖瞳孔的百分比来判断驾驶员的疲劳状态。实验结果表明,该算法具有较高的准确性和实用性。此外,本章还介绍了判断眼睛是否闭合的方法,通过跟踪眼睛区域中的像素数量来计算眼睛面积,并用于计算PERCLOS值。


















 288
288

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











