







 本文详细阐述了MapReduce的工作流程,从文件读取开始,包括split生成、Map阶段的Key-Value解析、数据排序与分区,再到Reduce阶段的Copy、Merge、Sort及最终的Reduce计算,全面揭秘大数据处理的核心步骤。
本文详细阐述了MapReduce的工作流程,从文件读取开始,包括split生成、Map阶段的Key-Value解析、数据排序与分区,再到Reduce阶段的Copy、Merge、Sort及最终的Reduce计算,全面揭秘大数据处理的核心步骤。
MapReduce整个工作流程图示:
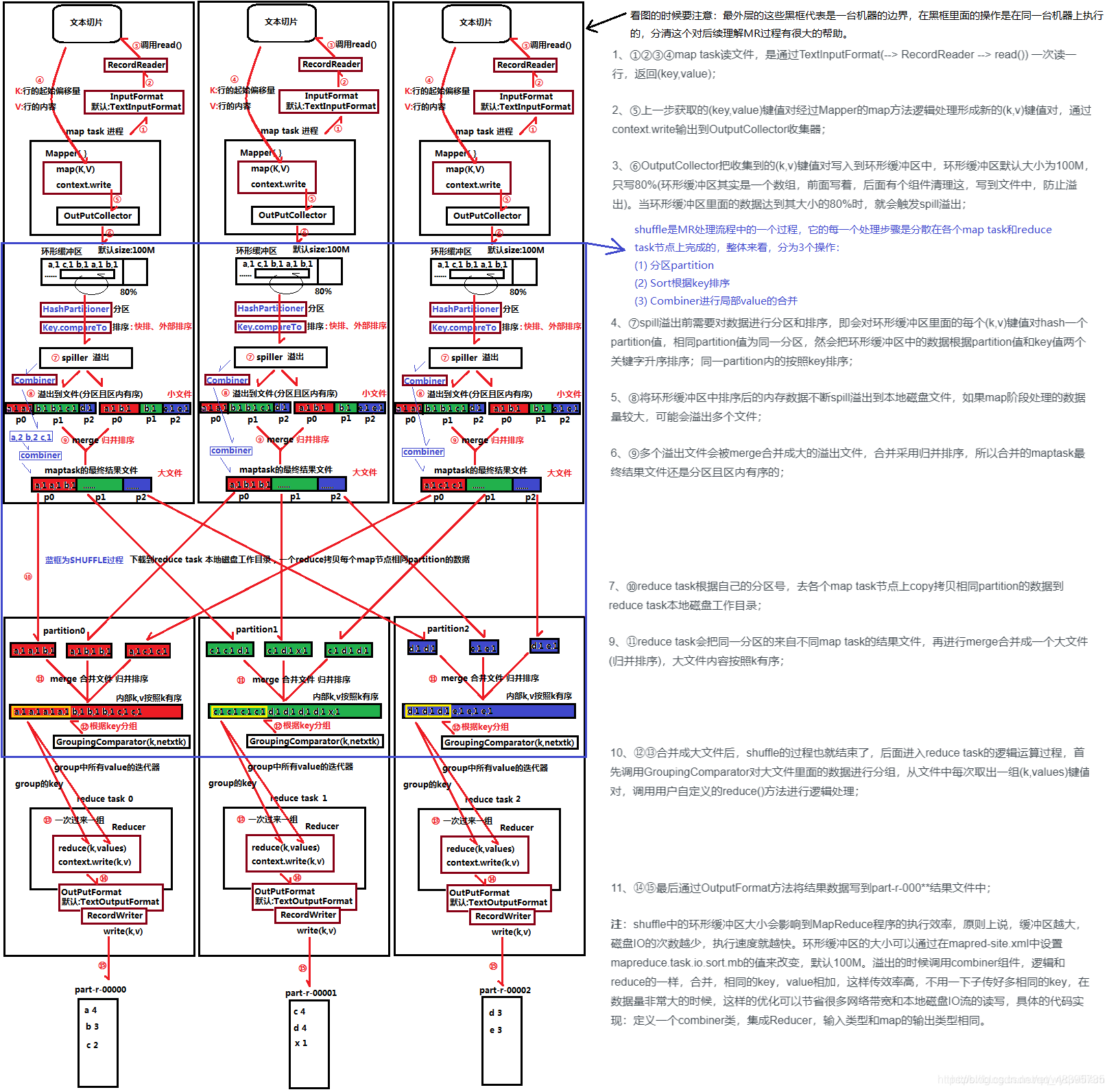
1、文件读取
(1)文件读取默认调用InputFormat,而其中有两个方法:getSplits()和createRecordReader()
(2)getSplits()是对输入目录的文件进行分片得到splis,有多少个split就对应启动多少个MapTask
(3)createRecordReader()是对split文件读取,将每个splie解析成records, 再依次将record解析成<Key,Values>,(Key表示每行首字符偏移值,value表示这一行文本内容)返回<Key,Values>
2、Map阶段
(1)读取split返回<Key,Values>,用户重写的map函数。
map函数会将接收到的<Key,Values>解析为新的<k,v>键值对(k为值,values为输出的类型)
(2)map函数执行完毕,通过context.write输出到OutputCollector收集器。
(3)经过收集器之后数据会写入到内存,这一块被称为环形缓冲区
环形缓冲区其实是一个数组,前面写,后面有组件在清理,写入到文件中 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 8394
8394

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









