







 文章介绍了Tesseract-OCR的用途,它是一个开源的OCR项目,支持多种语言。在Windows上安装包括下载安装包,选择所需语言。通过命令行使用tesseract.exe进行识别,并讲解了如何设置全局PATH。此外,文章还展示了如何在Java项目中使用tess4j库进行调用,包括设置识别语言、引擎模式以及处理图片进行OCR识别。
文章介绍了Tesseract-OCR的用途,它是一个开源的OCR项目,支持多种语言。在Windows上安装包括下载安装包,选择所需语言。通过命令行使用tesseract.exe进行识别,并讲解了如何设置全局PATH。此外,文章还展示了如何在Java项目中使用tess4j库进行调用,包括设置识别语言、引擎模式以及处理图片进行OCR识别。
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
前言
公司使用AI进行OCR文字识别效果不好,并且提供的服务不稳定,本次查找到使用java也能连接的OCR开源项目进行识别的学习
一、tesseract-ocr是什么?
tesseract-ocr是一个开源的OCR文字识别项目,目前版本已经更新到5.X.X了,并且提供多种环境的安装,本次我们在window进行安装并且使用。
二、使用步骤
1.下载exe安装包
说明:tesseract-ocr目前训练的数据是放在tessdata文件夹下,后缀为traineddata文件,目前支持100多种语言。今天安装的为第三方支持的安装包。
https://github.com/UB-Mannheim/tesseract/wiki
该页面下有支持64位和32位的安装包
tesseract-ocr-w32-setup-5.3.0.20221222.exe (32 bit) and
tesseract-ocr-w64-setup-5.3.0.20221222.exe (64 bit) resp.
``
2.安装
在软件安装时,默认只会安装英文训练的数据集合,要使用其他文字,需要在安装时,进行勾选。
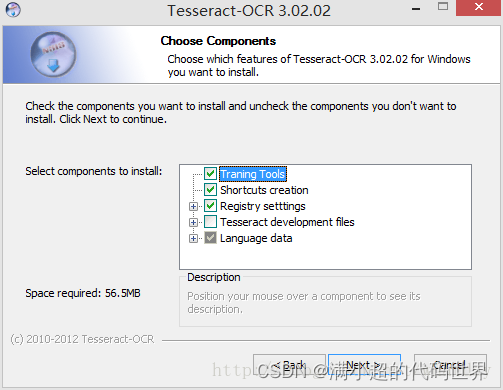
3.使用
该exe安装的软件可以直接使用tesseract.exe进行命令行执行文字识别。进入到exe存在的目录下。cmd进入到命命令执行框
//官方
tesseract imagename outputbase [-l lang] [--oem ocrenginemode] [--psm pagesegmode] [configfiles...]
imagename :图片的位置
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1212
1212

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









