







前沿:强化学习RL的目标是训练出一个好的策略,即在状态s下,采取一个最优的动作a,当agent采取这个动作后,可以使最后的长期累积回报最大化。
Policy gradient
1. 总体概述
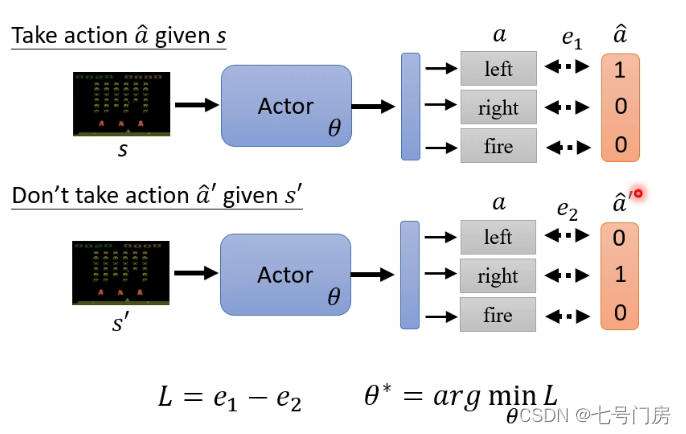
如下图所示,目前有一个状态s,与分类问题类似,通过一个Actor网络,我们将该状态进行分类,将其分类的结果记为a,已知目前总的不同类别有3种,为[left,right,fire],我们的目标是使分类的结果尽可能接近真实值
a
^
\hat{a}
a^,因此此时应该定义损失函数,分类问题中的损失函数通常用交叉熵表示即L = e1, 由于我们想让s输出
a
^
\hat{a}
a^,所以应该最小化损失函数,如果想让s不输出
a
′
^
\hat{a'}
a′^,则定义L = - e2, 所以最终的损失函数可以定义如下:L = e1 - e2
我们对每个<状态,动作>序列进行评估,用Ai表示,其中Ai可以理解为一个振幅,会将每个序列对的影响扩大,用来表示是否希望在该状态下采取特定的动作,因此一个完成的RL过程就被定义了。
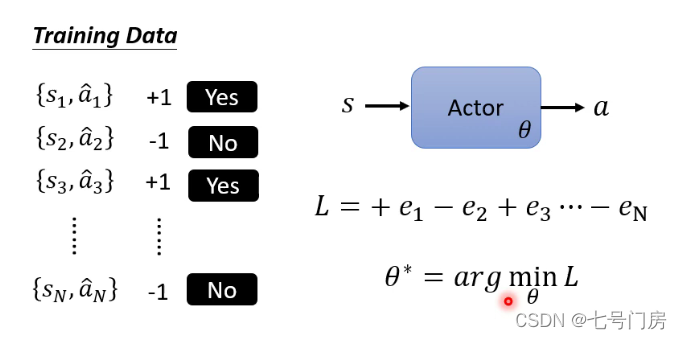
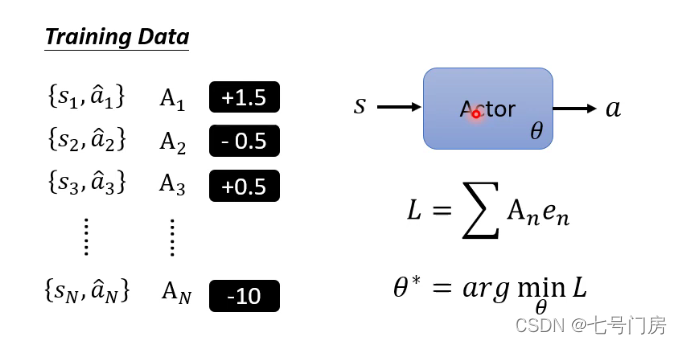
2. 解决Ai的定义和Training Data的来源
Ai的定义分为一下几个版本:
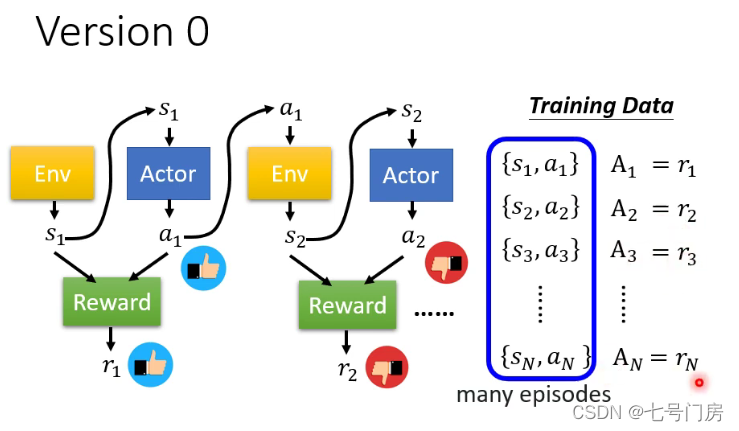
考虑奖励的延迟到达问题,因此将Gt定义为从t时刻开始,一直到结束的累积奖励。

继续考虑,由于当前的动作对前期奖励r影响比较大,后期影响比较小,因此考虑折扣问题。

由于无法对奖励的好坏进行判定,因此需要引入一个baseline,从而进行评价。

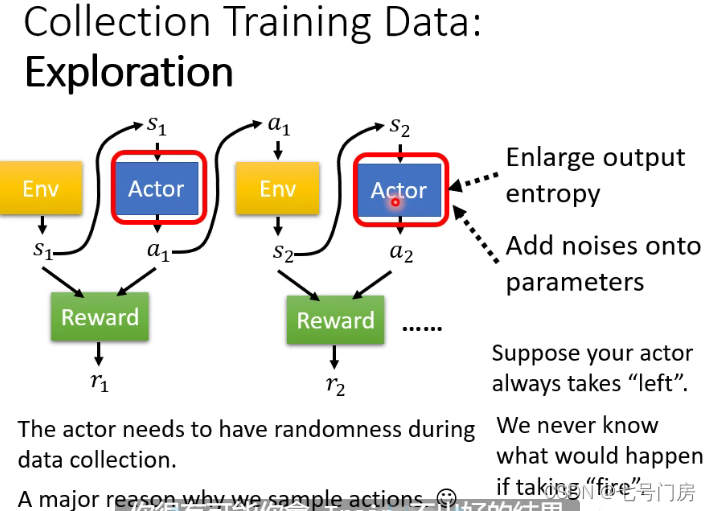
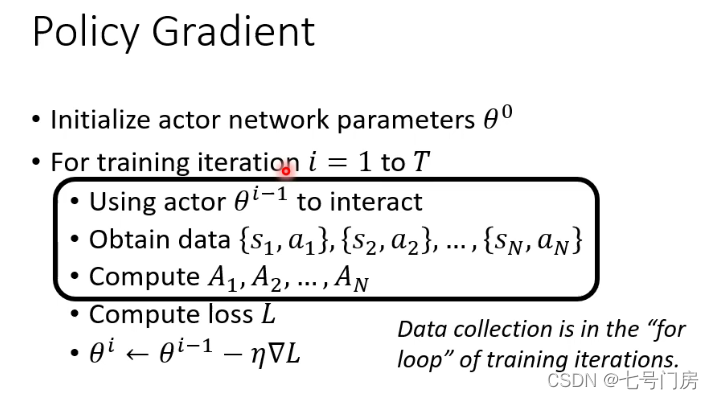
3. Policy Gradint 算法
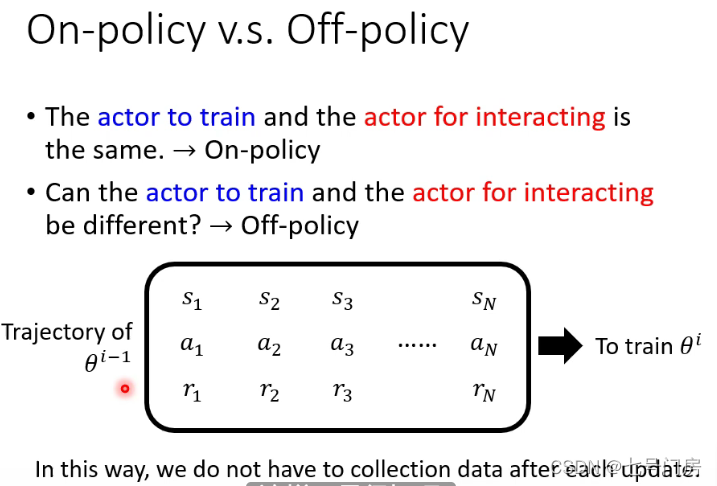
on-policy 和 off-policy

















 3037
3037

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









