







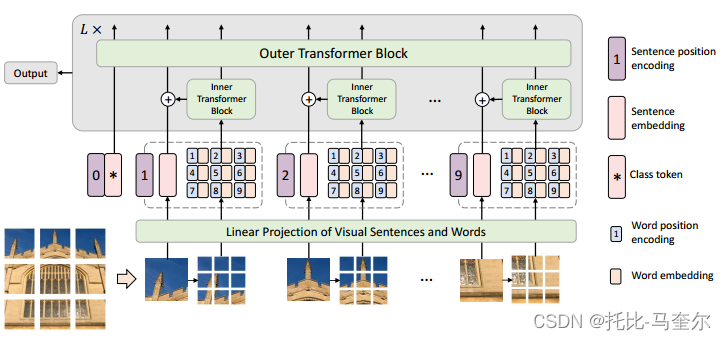
Transformer iN Transformer (TNT)。具体来说,我们将局部补丁(例如,16×16)视为“视觉句子”,并将它们进一步划分为更小的补丁(例如,4×4)作为“视觉单词”。每个单词的注意力将与给定视觉句子中的其他单词一起计算,计算成本可以忽略不计。单词和句子的特征将被聚合以增强表示能力。
1. 介绍
Transformer是一种主要基于自注意力机制的神经网络,它可以提供不同特征之间的关系。
CV 任务中的输入图像和真实标签之间存在语义差距。ViT 将给定图像划分为多个局部块作为视觉序列。然后,可以自然地计算任意两个图像块之间的注意力,以便为识别任务生成有效的特征表示。
文章贡献
一种用于视觉识别的新型 Transformer-in-Transformer (TNT) 架构。为了增强视觉 Transformer 的特征表示能力,首先将输入图像划分为多个块作为“视觉句子”,然后进一步将它们分成子补丁作为“视觉单词”。
除了用于提取视觉句子的特征和注意力的传统Transformer Block之外,我们进一步将子变压器嵌入到架构中以挖掘较小视觉单词的特征和细节。
具体来说,每个视觉句子中视觉单词之间的特征和注意力是使用共享网络独立计算的,因此增加的参数量和 FLOP(浮点运算)可以忽略不计。然后,单词的特征将被聚合成相应的视觉句子。该类令牌还通过全连接头用于后续视觉识别任务。通过所提出的TNT模型,我们可以提取细粒度的视觉信息并提供更多细节的特征。
2. 方法
2.1 预先工作
多头自注意力
在自注意力模块中,输入 被线性变换为三个部分,查询
,键
和值
。其中 n 是序列长度,
、
、
分别是输入、查询(键)和值的维度。缩放点积注意力:
最后,使用线性层来产生输出。多头自注意力将查询、键和值拆分为
个部分并并行执行注意力函数,然后将每个头的输出值连接并线性投影以形成最终输出。
多层感知器(MLP)
MLP 应用于自注意力层之间,用于特征变换和非线性:
其中W和b分别是全连接层的权重和偏置项,σ(·)是激活函数。
层归一化(LN)
层归一化 是 Transformer 中稳定训练和更快收敛的关键部分。LN 应用于每个样本,
,其中
分别是特征的平均值和标准差,
是逐元素点积,
是可学习的变换参数。
2.2 Transformer in Transformer
给定一个 2D 图像,我们将其均匀分割为 n 个补丁,其中
是每个图像块的分辨率。ViT 仅利用标准转换器来处理补丁序列,这会破坏补丁的局部结构,Transformer-in-Transformer (TNT) 架构来学习图像中的全局和局部信息。
在 TNT 中,我们将补丁视为代表图像的视觉句子。每个补丁又分为m个子补丁,即一个视觉句子由一系列视觉单词组成:,其中
是第 i 个视觉句子的第 j 个视觉词;
是子块的大小,
。
通过线性投影,我们将视觉单词转换为一系列单词嵌入:
其中是第 j 个词嵌入,c 是词嵌入的维度,Vec(·) 是向量化操作。
在 TNT 中,我们有两个数据流,其中一个数据流跨视觉句子进行操作,另一个数据流处理每个句子内的视觉单词。对于词嵌入,我们利用Transformer Block来探索视觉单词之间的关系:
其中是第
个块的索引,L是堆叠块的总数。第一个块
的输出就是
。变换后图像中的所有词嵌入均为
,可以看作内部Transformer Block,表示为
。该过程通过计算任意两个视觉单词之间的交互来构建视觉单词之间的关系。
对于句子级别,创建句子嵌入记忆来存储句子级别表示的序列:
其中
是类似于ViT的类标记,并且它们都被初始化为零。在每一层中,词嵌入的序列通过线性投影变换到句子嵌入的域中,并添加到句子嵌入中:
,其中
。使用标准Transformer Block来转换句子嵌入:
外部变压器块 用于对句子嵌入之间的关系进行建模。
TNT块的输入和输出包括视觉词嵌入和句子嵌入。
在TNT 块中,内部 Transformer 块用于对视觉单词之间的关系进行建模以进行局部特征提取,外部 Transformer 块从句子序列中捕获内在信息。最后,分类标记用作图像表示,并应用全连接层进行分类。
位置编码
空间信息是图像识别的重要因素。对于句子嵌入和词嵌入,我们都添加相应的位置编码来保留空间信息,使用标准的可学习一维位置编码。具体来说,每个句子都分配有一个位置编码:
,其中
是句子位置编码。对于句子中的视觉单词,每个单词嵌入都添加一个单词位置编码:
其中是跨句子共享的单词位置编码。这样,句子位置编码可以保持全局空间信息,而词位置编码用于保持局部相对位置。
2.3 复杂性分析
标准变压器块包括两部分,即多头自注意力和多层感知器。MSA的FLOPs为
,MLP的FLOPs为
。其中 r 是MLP中隐藏层的维度扩展比。总体而言,标准变压器块的 FLOPs 为
。由于 r 通常设置为4,并且输入、键(查询)和值的维度通常设置为相同,因此FLOPs计算可以简化为
FLOPs值越高,说明模型或算法的计算复杂度越高,可能需要更强大的计算资源来支持其运行
参数个数为。
TNT 块由三部分组成:内部变压器块 Tin、外部变压器块 Tout 和线性层。 Tin和Tout的计算复杂度分别为2nmc(6c + m)和2nd(6d + n)。线性层的 FLOPs 为 nmcd。总共,TNT 块的 FLOP 为
。TNT块的参数复杂度计算为
。
TNT 块与标准 Transformer 块的 FLOPs 比率约为 1.14×。同样,参数比例约为1.08×。随着计算和内存成本的小幅增加,我们的 TNT 模块可以有效地对局部结构信息进行建模,并在准确性和复杂性之间实现更好的权衡。
2.4 网络架构
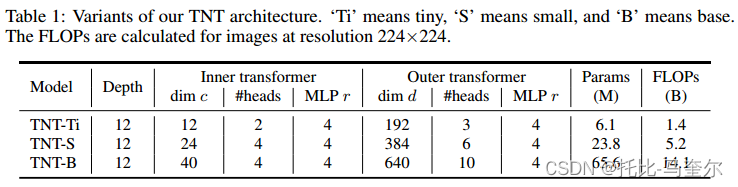
3. 实验
3.1 数据集和实验设置
ImageNet ILSVRC 2012 [26] 是一个图像分类基准,由属于 1000 个类的 120 万张训练图像和 50K 个验证图像(每类 50 张图像)组成。数据集下载链接
3.2 ImageNet 上的 TNT
在TNT结构中,句子位置编码用于维护全局空间信息,单词位置编码用于保留局部相对位置。
3.3 消融实验
视觉词的数量:
在TNT中,输入图像被分割成许多16×16的块,并且每个块进一步被分割成 m 个大小为(s, s)的子块(视觉词)以提高计算效率。
本文中 m 默认取值为16.
3.4 可视化
特征图的可视化
将 DeiT 和 TNT 的学习特征可视化,以进一步了解所提出方法的效果。为了更好的可视化,输入图像的大小调整为 1024×1024。特征图是通过根据块的空间位置重塑块嵌入来形成的。
第 1 个、第 6 个和第 12 个块中的特征图如图(a)所示,其中每个块随机采样 12 个特征图。与 DeiT 相比,TNT 中本地信息得到了更好的保存。我们还使用 t-SNE 对第 12 个块中的所有 384 个特征图进行可视化。
t-SNE算法的核心思想是将高维空间中的数据点映射到低维空间中,使得相似的数据点在低维空间中靠近彼此,而不相似的数据点则被远离。

可视化了 TNT 的像素级嵌入。对于每个补丁,我们根据词嵌入的空间位置重塑词嵌入以形成特征图,然后按通道维度对这些特征图进行平均。对应于14×14块的平均特征图

注意力图的可视化。我们的 TNT 块中有两个自注意力层,即内部自注意力层和外部自注意力层,分别用于建模视觉单词和句子之间的关系。内部变压器中不同查询的注意力图。对于给定的查询视觉词,具有相似外观的视觉词的注意力值较高,表明它们的特征将与查询交互更相关。


















 762
762

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









