







Vision Transformer堆叠多个Transformer块来处理不重叠的图像(即视觉标记)序列,从而形成用于图像分类的无卷积模型。与CNN模型相比,Transformer模型具有更大的感受野,并且擅长对远程依赖关系进行建模,事实证明在大量训练数据和模型参数的情况下可以实现优异的性能。
视觉识别中的过多注意力是一把双刃剑,每个查询补丁需要参与的键数量过多会导致计算成本高、收敛速度慢,并且增加过度拟合的风险。
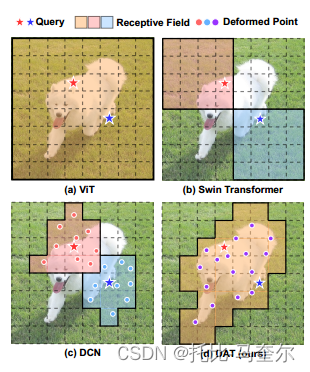
目前最大的难题:避免过多的注意力计算,Swin Transformer采用基于窗口的局部注意力来限制局部窗口内的注意力,而Pyramid Vision Transformer (PVT) 对键和值特征图进行下采样以节省计算量。
理想情况下,人们期望给定查询的候选键/值集是灵活的,并且能够适应每个单独的输入,从而可以缓解手工制作的稀疏注意力模式中的问题。
学习卷积核(卷积滤波器)的可变形感受野已经被证明可以有效地在数据依赖的基础上选择性地关注更多信息区域。
数据依赖是指数据之间的一种约束关系,即某些数据的取值依赖于其他数据的取值。
数据依赖分为函数依赖和多值依赖两种类型。
可变形偏移量的引入,使得开销是补丁数量的二次方。Transformer的变形机制要么在检测头中采用,要么用作预处理层,为后续主干网络采样补丁。
可变形注意力Transformer
可变形自注意力模块配备强大的金字塔主干,用于图像分类和各种密集预测任务。
具体来说,对于每个注意力模块,参考点首先生成为统一网格,这些网格在输入数据中是相同的。然后,偏移网络将查询特征作为输入,并为所有参考点生成相应的偏移。通过这种方式,候选键/值向重要区域转移,从而以更高的灵活性和效率增强原始自注意力模块,以捕获更多信息特征。
自 ViT引入以来,改进专注于 学习密集预测任务的多尺度特征和高效的注意力机制 。
高效的注意力机制包括窗口注意力、全局令牌、焦点注意力和动态令牌大小。
基于卷积的方法被引入Vision Transformer模型中,现有的研究重点是通过卷积运算补充 Transformer 模型以引入额外的归纳偏差。CvT在标记化过程中采用卷积,并利用步幅卷积来降低自注意力的计算复杂度。
在深度学习中,“归纳偏置”(inductive bias)是指在模型设计和学习过程中对可能解释
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2453
2453

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









