







昇思25天学习打卡营第2天|oldog

1.学习内容
用MindSpore搭建一个深度学习网络,完成简单任务:手写数字识别。
基本流程为:获取数据集,构建网络,模型训练,保存模型,加载模型(用于预测推理)。
2. 数据集
MindSpore的dataset使用数据处理流水线(Data Processing Pipeline),需指定map、batch、shuffle等操作。在本次任务中使用map对图像数据及标签进行变换处理,然后将处理好的数据集,包括训练集和验证集打包为大小为64的batch。
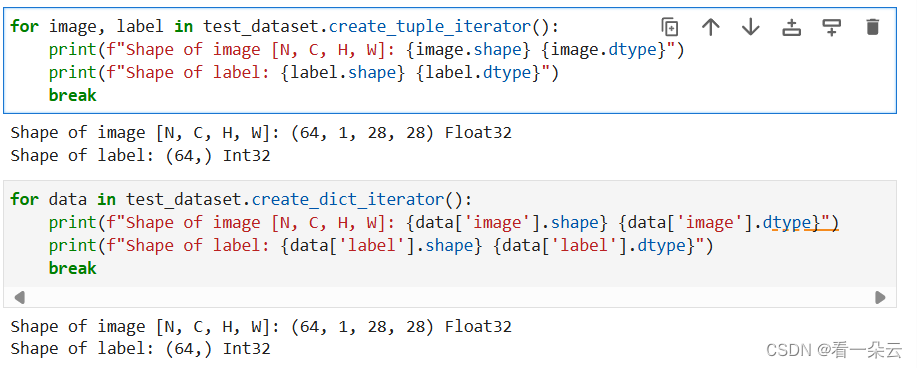
如果要查看数据和标签的shape、datatype等信息,可以使用create_tuple_iterator 或create_dict_iterator等操作。操作是对整个数据集直接封装好的,使用很方便。
3. 构建网络
网络构建简单、灵活。其中mindspore.nn类是构建所有网络的基类,如果有特殊、具体的需要,也可以继承nn.Cell类,并重写相应的网络层定义,__init__方法和数据变换过程,construct方法。
4. 模型训练和保存模型
训练过程分为三步:正向计算、反向传播、参数优化。训练之后,还需要使用测试函数以评估模型的性能。
当训练结束以后,还需要记得保存模型参数——保存模型。
5. 加载模型
当将模型投入使用时,需要先将模型加载出来,包括两步:
- 重新实例化模型对象,构造模型。
- 加载模型参数,并将其加载至模型上。
模型加载成功后,就可以用于预测推理了。
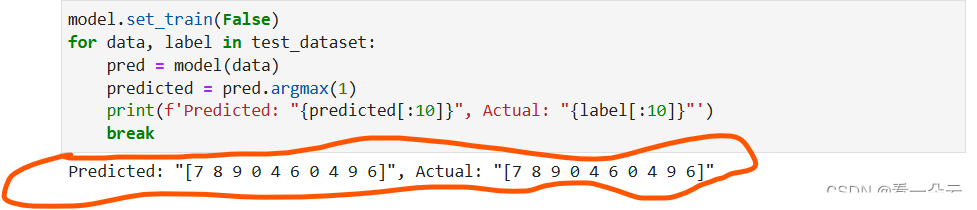
6. 总结
整个流程都是简单清晰的,关键在于每一步的具体实现。框架已经提供高度集成化的API,但是这并不是一个函数解决所有问题的事情,因为任何模型的生成和训练都有自己的独特的方式和细节。以模型训练为例,了解为什么使用损失函数、优化器以及如何选择、使用和调整,对在自己的任务中构建和训练深度学习网络是必要的。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









