






重头构建线性模型(线性模型+随机梯度+batch分配)
线性回归模型
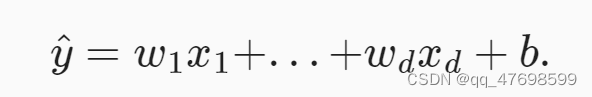
def linreg(x,w,b):
y=torch.matmul(x,w)+b
return y
可以使用解析解的方式求解线性回归:
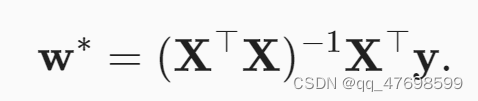
随机梯度下降SGD
通过在一系列样本中随机抽取部分样本,计算batch的梯度,更新参数,即SGD
def sgd(params,lr,batchsize):
with torch.no_grad():#防止进行反向传播
for param in params:#对w和b分别进行更新
param-=lr*param.grad/batchsize
param.grad.zero_()
SGD的缺陷是怕鞍点和山谷,会导致训练速度下降或收敛点不是最佳,导致SGD失效
最终代码
流程是读取数据->建立模型->batch分解->模型预测->损失计算->参数更新(SGD)->结果分析
import torch
import numpy as np
import random
import math
def synthetic_data(sampleNum,w,b):
x=torch.normal(0,1,[sampleNum,len(w)],dtype=float)
y=torch.matmul(x,w)+b
y+=torch.normal(0,1,[len(y)])
return x,y
def linreg(x,w,b):
y=torch.matmul(x,w)+b
return y
def squared_loss(y_true,y_pred):
return (y_true-y_pred)**2/2
def sgd(params,lr,batchsize):
with torch.no_grad():
for param in params:
param-=lr*param.grad/batchsize
param.grad.zero_()
def batch_form(x,y,batchsize):#实现batch的分解
index=list(range(len(x)))
random.seed(1000)
random.shuffle(index)
for i in range(math.floor(len(x)/batchsize)):
batch_index=torch.tensor(index[i*batchsize:min((i+1)*batchsize,len(x))])
features=x[batch_index]
target=y[batch_index]
yield features,target
#形成生成器,运行到yield后中止程序,return参数,使用next(object)才能继续调用该生成器,并且位置保持在上一次运行后的位置
if __name__=='__main__':
w_true=torch.arange(2,dtype=float)
b_true=100*torch.ones(1,dtype=float)
x,y=synthetic_data(sampleNum=1000,w=w_true,b=b_true)
w=torch.ones(2,requires_grad=True,dtype=float)
b=torch.ones(1,requires_grad=True,dtype=float)
lr=0.01
batchsize=100
for epoch in range(100):
for features,targets in batch_form(x,y,batchsize):
y_pred=linreg(features,w,b)
loss=(squared_loss(targets,y_pred)).sum()
loss.backward()
sgd([w,b],lr,batchsize)
with torch.no_grad():#防止进行反向传播
y_pred=linreg(x,w,b)
loss=(squared_loss(y,y_pred)).sum()
print(f'epoch:{epoch},loss:{loss:.5f}')
print(f'difference_w:{w-w_true}')
print(f'difference_b:{b - b_true}')
模块化实现线性模型
用到的语句主要有
dataset=torch.utils.data.TensorDataset(*(x,y))形成dataset,对大量数据可以减少读取时间。iterator=torch.utils.data.DataLoader(dataset, batchsize=, shuffle=True)形成生成器,可进行迭代取值计算torch.nn.Linear(input_shape,output_shape)线性模型定义torch.optim.SGD(model.parameters(),lr=0.01)优化器定义loss=torch.nn.MSEloss()损失函数定义,建立对象后计算损失,lossNum=loss(y_true,y_pred)model.zero_grad()清零梯度;model.backward()反向传播;torch.step()参数更新
主代码
import torch
from torch.utils import data
def synthetic_data(sampleNum,w,b):
x=torch.normal(0,1,[sampleNum,len(w)],dtype=torch.float32)
y=torch.matmul(x,w)+b
y+=torch.normal(0,1,[len(y)])
return x,y
def load_dataset(datas,batchsize,is_train=True):
dataset=data.TensorDataset(*datas)
return data.DataLoader(dataset,batch_size=batchsize,shuffle=is_train)
if __name__=='__main__':
#生成数据
w_true=torch.tensor([5.0,14.5],dtype=torch.float32)
b_true=torch.tensor([10],dtype=torch.float32)
x,y=synthetic_data(sampleNum=1000,w=w_true,b=b_true)
y=y.reshape((-1,1))
#形成dataset
datas=(x,y)
data_iter=load_dataset(datas,batchsize=100,is_train=True)
loss=torch.nn.MSELoss()
model=torch.nn.Linear(2,1)
trainer=torch.optim.SGD(model.parameters(),lr=0.01)#训练配置
for epoch in range(10):
for feature,label in data_iter:#使用DataLoader
label=label.reshape((-1,1))
lossNum=loss(model(feature),label)
trainer.zero_grad()#先梯度清零
lossNum.backward()#梯度计算
trainer.step()#参数更新
with torch.no_grad():
lossNum=loss(model(x),y)
print(f'epoch:{epoch},loss:{lossNum:.2f}')


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









