






该文章参考李宏毅课程:https://www.bilibili.com/video/BV1Gf4y1p7Yo?spm_id_from=333.337.search-card.all.click&vd_source=7266164bac828afa96b5c3e3dcb1b738
自监督学习
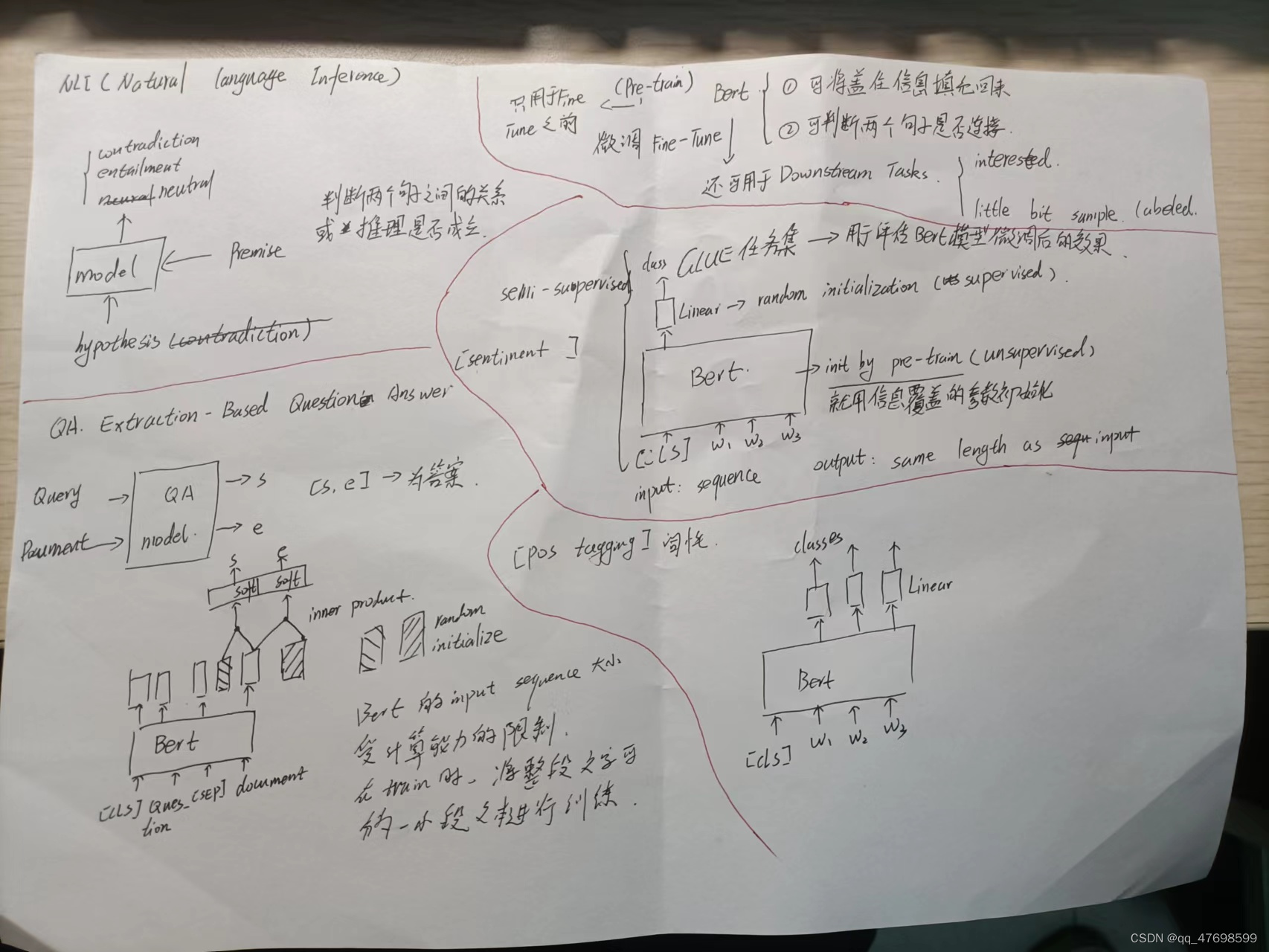
定义:假设目前有一堆数据样本,用特征作为标签进行学习,因此将一部分样本做覆盖,输入到模型中,再与真实样本进行cross entropy的计算,最小化交叉熵来训练模型。这个过程就是自监督学习。下图为Bert的pre-train的流程图。

Bert模型
Bert模型最初是用于文本的缺失字符的填充或判断两个句子之间是否链接起来,之后用Fine-Tune的方式应用到更多的领域任务中
- Pre-Train:使用上述masking(缺失字符的填充)的训练过程来对Bert自身参数进行初始化
- Fine-Tune:使用少量目标任务相关的样本数据进行整体模型(Bert+Linear)的训练
上述两个过程可以分别视为1-无监督学习 2-有监督学习,整个过程相当于半监督学习。
Bert的输入一般包括**[CLS] 字符段 [Sep]**,[CLS]通常用于对整句句子进行统一分析,Bert的输出是与输入相同长度的Sequence,但是更具不同的任务进行后续微调,加入Linear与特定Bert输出结合,得到最终目标输出
微调Bert所应用的范围: - sentiment classification,情感分类,如根据一段话对某个餐厅进行评分,使用[CLS]字段的输出+Linear处理,得到class分类;
- Pos tagging词性标记,标记输入的次是名词、动词等,这就需要使用所有字符段的Bert输出进行Linear,得到词性输出;
- NLI自然语言推断,判断根据一段话另外一句话是否成立
- QA全文摘录问答,输入问题和文本,输出答案在文本的起始位置和终止位置,start->end这段文本构成答案
***Bert模型输入是否有长度限制?***当然,因为长度越长,Bert网络参数量就会越多(input和output的维度一致),本身Bert就是大规模模型。
***Bert为什么有用?***有研究表明其可以结合文本的上下语境对字符进行编码,如苹果的“果”,如果上下文有“吃”等字出现,说明其是真实苹果,就会和食物类编码接近,但是如果是iphone,则会和电子类编码接近。但是有研究表明上述解释也可能不成立。
对于multi-Bert,使用不同语言pre-train后,即使使用英语fine tune,在中文的任务上也能取得不错的效果,这是由于不同语言之间相同含义的语句可能存在固定距离差距来区分语言,也就是Bert明白语言之间的差别。
GPT
GPT太大,微调可能不可以实现,GPT常用于预测下一个token字符是什么作为pre-train
GPT后续用于输入任务目标,输入几个转化样例,要求GPT能够按照样例的形式对任务进行求解


自编码器auto-encoder
视频链接:https://www.bilibili.com/video/BV1oq4y1E77X?spm_id_from=333.337.search-card.all.click&vd_source=7266164bac828afa96b5c3e3dcb1b738
自编码器其实上也是一种自监督学习方式,使用输入样本来复现输入样本,实现网络参数的初始化。
自编码器包括:编码器encoder 和 解码器decoder。其结构是输入样本–》编码器–》vector–》解码器–》输出样本。其目标是尽量让输出样本与输入样本相似度更高。
**自编码器的作用:**1. 可以利用encoder来进行信息压缩,用decoder进行解压缩;2. 用encoder来做特征选择,实现特征降维,提取输入中的关键信息




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









