






主要是对李宏毅LLM修炼史的总结,没啥专业的内容,只是讲故事而已(强推李宏毅的各类课程,学了这么久的深度学习直到看了李宏毅的网课才对各种概念和模型有了一点点理解,可恶啊!!!
一、LLM的行为模式
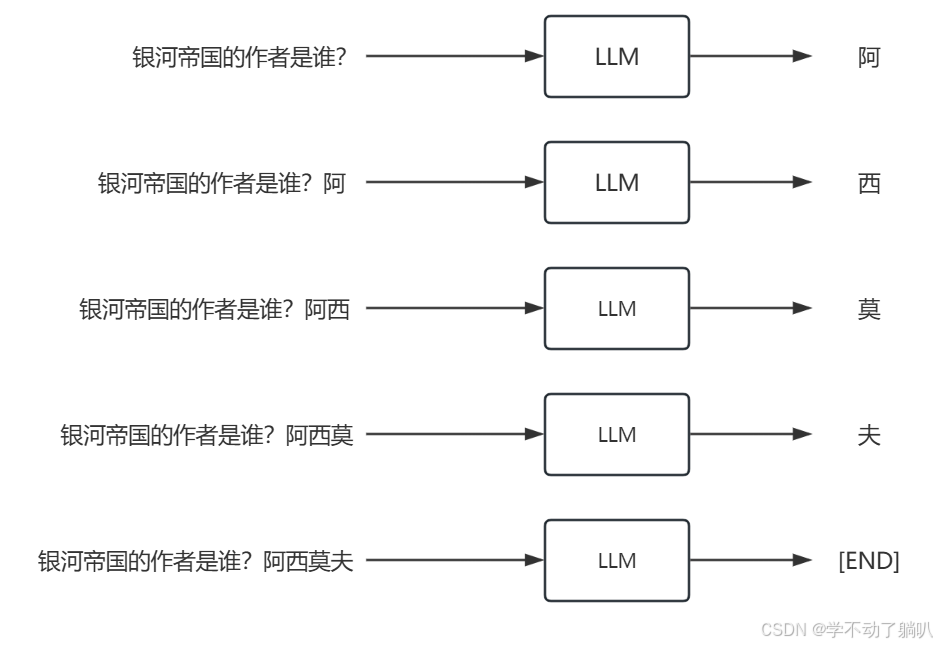
目前的大语言模型已经很火热了,例如常用的GPT、KimiChat、文心一言、Claude等等,我之前一直以为大语言模型的内核就是一个搜索引擎,将问题输给它,它就会在训练资料里或是调用其他的接口做相似度匹配(简直大错特错!!!),现在才了解到大语言模型其实是故事接龙,将句子喂给它,它就会预测下一个词是什么,然后以此类推,我画了个简单的草图。
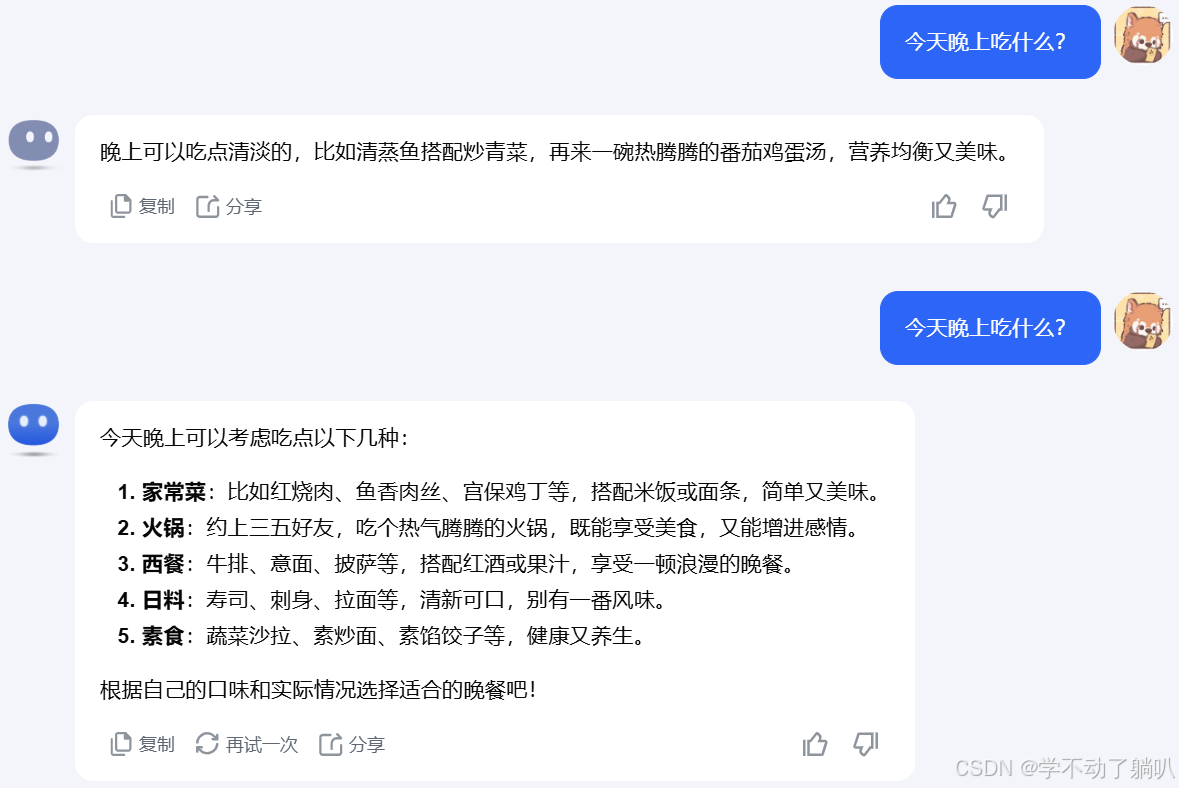
但是,当问LLM一些开放性的问题时,例如“今晚吃什么”、“买耳机哪家店铺最好”这种没有正确答案的问题时,LLM每次返回的答案会不一样,是具有多样性的。可以看下图,我问kimi两次相同的问题,但是它的答案是不同的。
这是因为LLM在预测下一个词时,它得到的实际上是一个概率分布,在预测时它得到的是这样的模式:今0.32,晚0.45,根0.21,家0.02(前面的是预测出来的字,后面的数字是概率,当然这个例子是我随便写的,但大概就是这样~)。虽然今的分数有0.32,但是LLM不会直接输出今,如果每次只挑选分数最高的进行输出,那么LLM将会失去多样性(可能在训练过程中也会出现过拟合(个人猜想))。所以,在得到概率时,LLM会进行一个“掷色子”的操作,随便选择,当然“掷色子”也是有不同的策略的(例如贪心、Top算法系列等),在此处不再展开。
二、LLM第一阶段:预训练
预训练是深度学习领域里太过常见的词语了,很多财力深厚的公司都会利用大型的数据集来训练一个预训练模型(多数以分类任务、机器翻译、多模态匹配等进行训练),而没有足够资源的个人就可以利用预训练模型来进行个人的训练。有人会选择直接采用预训练模型(不对预训练模型的权重参数进行训练,也就是论文里常提到的freezing,一个雪花的图标,多数论文的说法是保留原参数能更好地发挥预训练模型的能力),有人会选择对预训练模型进行微调,即在预训练模型的基础上利用其他数据集对模型的权重参数进行更新。
在LLM的预训练阶段里,开发人员只需要爬取大量的数据,喂给LLM进行文字接龙就好,不需要额外的人工介入,这一过程也被称为自监督式学习Self-supervised Learning,因为不需要人工标注的lable,传统意义下的label已经在数据集中了。
如果只有预训练这一个阶段,LLM就只是一个劣质的搜索引擎。如果将一个数学问题“
x
x
x等于
y
y
y开根号,如果
x
=
4
x=4
x=4,那么
y
y
y的平方等于多少?”喂给早期的LLM,结果就是LLM不会回答这个问题,它反而会回复“A.2”、“B.4”、“C.8”诸如此类的回答。
由于LLM是没有人工额外干预的,所以出现这种现象大概率是训练资料出了问题。这种现象也很好解释,因为有关数学问题的训练资料大多是来源于题库,而“
x
x
x等于
y
y
y开根号,如果
x
=
4
x=4
x=4,那么
y
y
y的平方等于多少?A.2 B.4 C.8”也是试题的常见形式,由于LLM只是在做文字接龙,所以LLM当然不会给出答案了,只会给出选项,因为它就是这么学习的。
三、LLM第二阶段:微调
因此第二阶段,研究人员就选择让人工介入,对数据集进行标注,这种方法也被称为监督学习Supervised Learning。在预训练阶段,LLM其实已经具备了足够的知识,目前它只是不会说话而已,因此不需要再对LLM重新训练,只要在原有的基础上再调整一下参数就可以了(只是从0.8到1而已)。而人工标注的训练资料大概长这个样子:
USER:美国众神的作者是谁?
AI:英国的尼尔·盖曼。
USER:你是谁?
AI:我是人工智能。
自此,LLM就具备了问答的能力,虽然对于某些数学问题,LLM还是不会给出精确的答案,但是它起码不会仿写了,例如提问“1加1等于几?”,LLM虽然可能会回答“3”,但是它不会再回复“A.3 B.2 C.1”,简直是一大进步(欢呼雀跃!!!)。
但不可否认,此时还是会面临一个问题:微调时,是调整LLM的全部参数,虽然不需要重新训练了,但是微调还是需要消耗大量的资源。如果只调整某几层,可能会影响最终的结果,毕竟每一层神经元的职责都是不同的(最浅显来说,低层的神经元负责处理单词,高层的神经元负责处理句子的意思)。
既然如此,那干脆掀桌不干了!!!
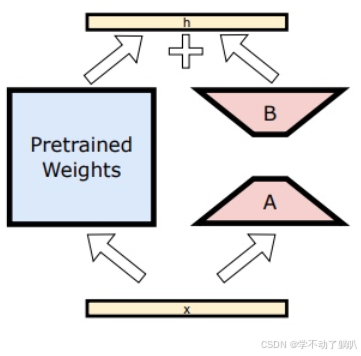
研究人员开始采用名叫LoRA的微调策略,也就是原本训练好的就不要再动了,在预训练模型的后面再加个小模型,然后只训练这个小模型就可以啦(这么想在我还不知道LoRA是啥的时候,其实很多时候我已经在用LoRA的策略训练模型了嘿)。下面这张图就是LoRA的架构图,左边的就是预训练模型,右面的就是需要训练的小模型。但是目前我还没有学到LoRA,所以就不再展开细说了(鞠躬)。
那么,既然可以对LLM进行微调了,也就是说我们想让它干什么,只要喂给它数据集就可以了。此时,LLM就又面临一个问题:LLM究竟是要成为一个独当一面的英雄好,还是训练出多个不同任务的LLM组成一个英雄联盟好?目前看来,LLM是属于后者的。李宏毅老师在网课中提到,虽然我们目前在用各种LLM平台,但是后台其实是多个LLM在运作。例如如果想让LLM做翻译,LLM就会调用翻译这个接口;想让LLM做画图,LLM就会去调用AI画图这个接口(啊LLM真是怪聪明的捏)。
四、LLM第三阶段:强化学习
目前我们使用的LLM早就进入了第三阶段,也就是利用强化学习阶段。此时,对于LLM来说,如何使得开放式回答得到人类的认可更为重要。在各个LLM模型中,此时都会出现一个评价的图标,用于评价这个回答究竟好不好。当收集到一定的资料时,研究人员就会将这些对话喂给LLM再次进行微调(研究人员会再训练一个奖励模型),如果某个回答得到的是负反馈,那么在训练时,LLM就会降低这些预测词出现的概率。
如果想了解更多的细节,可以看Instruct GPT这篇文章,这篇文章中提到,除了人类的回馈,还可以利用其他LLM的回馈,目前LLM在回答问题之前,已经在后台与其他LLM模型进行了交流,先一步判断这个回答是否是正确的,是否符合人类基本的价值观念,例如主LLM会自我反思“我的回答是正确的吗”,或是其他的LLM提问“你的回答正确吗?我认为答案并不唯一”诸如此类可以引导主LLM进行反思的问题,直至两个或多个LLM对答案进行统一的认可。
在李宏毅老师的课里,他还提到了许多LLM的发展与许多有趣的小例子,例如论文Generative Agents: Interactive Simulacra of Human Behavior就构建了一个LLM社区,社区里有许多npc,每个npc都有自己的设定,在某个时间内可以进行自己的事情,同时根据环境的改变,npc的行为也会发生改变,甚至LLM已经有了谈恋爱的倾向(可恶啊我还没有对象就让LLM谈上!
大概内容就这么多,接下来我可能会去找一些实践的课程(但是一直没有找到合适的,emm……就先这样叭


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









