






Python基础学习
一,开发环境配置及安装
1.环境安装及配置环境变量
- 下载地址:https://www.python.org/downloads/

- 下载安装后,要想在系统的任何一个目录中,使用python.exe需要配置环境变量。

- 测试是否安装成功。

2.安装PyCharm
- 下载地址:https://www.jetbrains.com/zh-cn/pycharm/
社区版:免费。

二,Python语言概述
注意事项:
- python程序默认是顺序执行的。
- python区分大小写。
- python语句不需要以;结束,但是如果写上也不会报错,通常我们都不写。
1.转义字符
| 转义字符 | 效果 |
|---|---|
| \t | 制表位 |
| \n | 换行符 |
| \r | 一个回车 |
| \" | 一个 " |
| \’ | 一个 ’ |
| \\ | 一个 \ |
回车效果演示:
print("段誉向西行,\r他虽不会武功") # 他虽不会武功
2.注释
- 单行注释
# print("Hello,World")
- 多行注释
格式:三个单引号==‘’‘注释文字’''或者三个双引号"““注释文字””"==。
'''多行注释'''
"""多行注释"""
- 文件编码声明注释:在文件开头加上编码声明,用于指定文件的编码格式。
# coding:编码
3.变量
3.1 type()
name = "张无忌"
age = 18
score = 88.2
is_male = True
# 使用type(object)函数查看数据类型
print(type(name))
print(type(age))
print(type(score))
print(type(is_male))
print(f"\"hello\"的数据类型是:{type("hello")}")

任何程序的执行都必须放入内存中。
3.2 全局变量和局部变量
- 全局变量:在整个程序范围内都可以访问,定义在函数外部,拥有全局作用域的变量。
- 局部变量:只能在其被声明的函数范围内访问,定义在函数内部,拥有局部作用域的变量。
n = 100 # 全局变量
def fun():
n = 200 # 局部变量
print(n)
fun() # 200
print(n) # 100
n = 100 # 全局变量
def fun():
global n # 全局变量
n = 200
print(n)
print(n) # 100
fun() # 200
print(n) # 200
4.格式化输出
前置知识:加号的使用。
# 加号的使用:
print(100 + 100) # 200,数字拼接为数字
print("100" + "100") # 100100,字符串拼接为字符串
# print(100 + "100") # 报错,unsupported operand type(s) for +: 'int' and 'str'
- %操作符。
print("个人信息:%s %d" % (name,age))
- format()函数。
print("个人信息:{} {} {}".format(name,age,gender))
- f-strings。
print(f"个人信息:{name} {age} {gender}")
5.数据类型
5.1整型
- python语言有十进制,二进制,八进制,十六进制。
- 无论数字有多小,在python中也是要占用28个字节。python字节数随着数字的增大而增大,每次所占用字节的增长幅度为4个字节。
n1 = 8
n2 = 8 ** 8
n3 = 8 ** 88
n4 = 8 ** 888
n5 = 8 ** 2222
print(n1,sys.getsizeof(n1),type(n1))
print(n2,sys.getsizeof(n2),type(n2))
print(n3,sys.getsizeof(n3),type(n3))
print(n4,sys.getsizeof(n4),type(n4))
print(n5,sys.getsizeof(n5),type(n5))
- sys.getsizeof(object) 用于获取变量所占用的字节数量。
- 使用type(object)函数查看数据类型。
5.2浮点型
# 1.浮点型的表示方式
n1 = 4.5
n2 = 4.5e+2 # 科学计数法,表示4.5 * 10 ^ 2
n3 = 4.5e-2 # 科学计数法,表示4.5 / 10 ^ 2
print(n1)
print(n2)
print(n3)
# 2.浮点数的大小范围
print(sys.float_info)
# 3.浮点数的精度丢失问题
n4 = 8.1 / 3
print(n4) # 2.6999999999999997
# 解决方案:使用Decimal类
from decimal import Decimal
n4 = Decimal("8.1") / Decimal("3")
print(n4) # 2.7
5.3布尔型
- python中会将True视为1,False视为0。
print(False + 10) # 10
print(True + 10) # 11
- 在python中非0被视为真值,0被视为假值。
5.4字符串
- 使用引号(’ 或 ")包括起来,创建字符串。
- python不支持字符类型,单字符在python中也是作为一个字符串使用。
- 使用"""或’''输出,可以保持原来的格式。
- 在字符串前加入r,转义字符将不会转义。
print('Tom说"哈哈"')
print("Jack说'哈哈'")
print("""n1 = 8
n2 = 8 ** 8
n3 = 8 ** 88
n4 = 8 ** 888""")
print(r"\n")

5. 字符串驻留机制
- 字符串驻留机制:Python仅保存一份相同且不可变的字符串。不同的值被存放在字符串驻留池中,Python的驻留机制会对相同的字符串只保留一份拷贝,后续创建相同字符串时,不会开辟新空间,而是把该字符串的地址赋给新创建的变量。
- 内存图示:

- 驻留机制发生的几种情况:
- 字符串是由26个英文字母的大小写,0-9,_组成。
- 字符串的长度为0或者1时。
- 字符串在编译时进行驻留,而非运行时。
- [-5,256]的整数数字。


- PyCharm对字符串进行了优化处理。
str1 = "abc#"
str2 = "abc#"
print(id(str1) == id(str2)) # True
num1 = -6
num2 = -6
print(id(num1) == id(num2)) # True
- 字符串驻留机制的好处:当需要值相同的字符串时,可以直接从字符串池里拿来使用,避免频繁的创建与销毁,提升效率和节约内存。
6.数据类型转换
1.隐式类型转换
- python变量的类型不是固定的,会根据变量当前值在运行时决定的,可以通过内置函数type(变量)来查看其类型,这种方式就是隐式转换(自动转换)。
var1 = 10
print(type(var1)) # int
var1 = 1.1
print(type(var1)) # float
var1 = "哈哈"
print(type(var1)) # str
- 在运算的时候,数据类型会向高精度自动转换。
var2 = 10
var3 = 1.2
var4 = var2 + var3
print("var4 = ",var4,"var4的类型是:",type(var4)) # 11.2 float
2.显式(强制)类型转换
- 如果需要对变量数据类型进行转换,只需要将数据类型作为函数名即可,这种方式就是显示转换/强制转换。
- 函数会返回一个新的对象/值,这就是强制类型转换的结果。函数不会改变传入对象的值。
temp = 1
print(f"type: {type(temp)} value: {temp}")
final = float(temp)
print(f"temp_type: {type(temp)} temp_value: {temp} final_type: {type(final)} final_value: {final}")
'''
输出结果:
type: <class 'int'> value: 1
temp_type: <class 'int'> temp_value: 1 final_type: <class 'float'> final_value: 1.0
'''
3.显式类型转换注意事项
- 不管什么值的int,float都可以转换为str,str(x)将对象x转换为字符串。在python中万事万物皆对象,包括int,float等等。
- int转成float时,会增加小数部分,比如123->123.0,float转成int时,会去掉小数部分,比如123.65->123。
- str转int,float使用int(x),float(x) 将对象 x 转换为int/float。要求字符串本身是可以转换为int/float的。否则会出现ValueError,程序就会终止。
var = "哈哈"
int(var)

- 练习:
i = 10
j = float(i)
print(type(i)) # int
print(type(j)) # float
i = j + 1
print(type(i)) # float
print(type(j)) # float
print(i) # 11.0
print(int(i)) # 11
print(type(i)) # float
7.运算符
7.1算术运算符
| 运算符 | 运算 | 范例 | 结果 |
|---|---|---|---|
| / | 除 | 9/3 | 3.3333 |
| % | 取模(取余) | 7%5 | 2 |
| // | 取整除-返回商的整数部分(向下整除) | 9//2 | 4 |
| ** | 返回x的y次幂 | 2**4 | 16 |
- 对于除号 / ,返回结果是小数。
- 对于取整除 // ,返回商的整数部分(向下整除)。
- 当对一个数取模时,对应的运算公式:a % b = a - a // b * b。
# a % b = a - a // b * b
# 10 % 3 = 10 - 10 // 3 * 3 = 10 - 3 * 3 = 1
print(10 % 3) # 1
# 5 % -2 = 5 - 5 // (-2) * (-2) = 5 - (-3) * (-2) = 5 - 6 = -1
print(5 % -2) # -1
7.2比较运算符
| 运算符 | 效果 |
|---|---|
| is | 判断两个变量引用对象是否为同一个 |
| is not | 判断两个变量引用对象是否不同 |
- 比较运算符的结果要么是True,要么是False。
a = 9
b = 8
print(a > b) # T
print(a >= b) # T
print(a <= b) # F
print(a < b) # F
print(a == b) # F
print(a != b) # T
flag = a > b
print("flag =",flag) # T
print(a is b) # F
print(a is not b) # T
7.3逻辑/布尔运算符
以下假设变量a为10,b为20。
| 运算符 | 逻辑表达式 | 描述 | 实例 |
|---|---|---|---|
| and | x and y | 布尔“与”:如果x为False,x and y 返回x的值,否则返回y的计算值 | (a and b)返回20 |
| or | x or y | 布尔“与”:如果x为True,x or y 返回x的值,否则返回y的计算值 | (a or b)返回10 |
| not | not x | 布尔“非”:如果x为True,返回False。如果x为False,它返回True。 | not (a and b)返回False |
a = 10
b = 20
print(a and b) # 20
print(a or b) # 10
print(not (a and b)) # False
- and是种“短路运算符”,只有当第一个为True时才去验证第二个。
- or是种“短路运算符”,只有当第一个为False时才去验证第二个。
- 在python中,非0被视为真值,0值被视为假值。
7.4赋值运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| **= | 复合幂赋值运算符 | c**=a等价于c = c ** a |
| //= | 复合整除赋值运算符 | c//=a等价于c = c // a |
- python中交换两个变量值的三种方法:
# 方式一:通过中间变量
a = 10
b = 20
print("交换前,a = {},b = {}".format(a,b))
temp = a
a = b
b = temp
print("交换后,a = {},b = {}".format(a,b))
# 方式二:python特有语法
a = 10
b = 20
print("交换前,a = {},b = {}".format(a,b))
a,b = b,a
print("交换后,a = {},b = {}".format(a,b))
# 方式三:算法
a = 10
b = 20
print("交换前,a = {},b = {}".format(a,b))
a = a + b
b = a - b
a = a - b
print("交换后,a = {},b = {}".format(a,b))
7.5三元运算符
- python是一种极简主义的编程语言,它没有引入? : 这个运算符,而是使用if else关键字来实现相同的功能。
- 语法:max = a if a > b else b。
num1 = 10
num2 = -2
num3 = 38
max = (num1 if num1 > num2 else num2) if (num1 if num1 > num2 else num2) > num3 else num3
print(f"max = {max}")
7.6位运算符
- 二/八/十六进制转十进制:按权展开求和。
- 十进制转二/八/十六进制:除二/八/十六取余倒叙法。
- 二进制转八进制:从低位开始,将二进制数每三位一组,转成对应的八进制数即可。
- 二进制转十六进制:从低位开始,将二进制数每四位一组,转成对应的十六进制数即可。
- 原码,反码,补码:
- 二进制的最高位是符号位:0表示正数,1表示负数。
- 正数的原码,反码,补码都一样(三码合一)。
- 负数的反码 = 它的符号位不变,其他位取反。
- 负数的补码 = 它的反码 + 1,负数的反码 = 负数的补码 - 1。
- 0的反码,补码都是0。
- 在计算机运算的时候,都是以补码的方式来运算的。
- 当我们看运算结果的时候,要看它的原码。
假定用一个字节来表示:
3 => 原码:0000 0011
反码:0000 0011
补码:0000 0011
-3 => 原码:1000 0011
反码:1111 1100
补码:1111 1101
1 + 3 => 1的补码:0000 0001
3的补码:0000 0011
————————————————————
0000 0100(补码)=> 原码:0000 0100(4)
1 - 3 => 1的补码:0000 0001
-3的补码:1111 1101
————————————————————
1111 1110(补码) => 反码:1111 1101 => 原码:1000 0010(-2)
7.7运算符的优先级

7.8标识符
- python对各种变量,函数和类等命名时使用的字符序列成为标识符。
- 标识符命名规则(必须遵守):
- 由26个英文字母大小写,0-9,_组成。
- 数字不可以开头,开头必须是字母或下划线。
- 不可以使用关键字,但能包含关键字。
- python区分大小写。
- 命名规范(非必须遵守):
- 变量名:变量要小写,若有多个单词,使用下划线分开。常量要全部大写。
- 函数:函数名一律小写,如果有多个单词,用下划线隔开。另外,私有函数以双下划线开头。
- 类名:使用大驼峰命名,如:MyName。
def my_func(var1,var2)
pass
def __private_func(var1,var2)
pass
8.数据输入

- input(prompt)读入的类型为str。
name = str(input("请输入姓名:"))
age = int(input("请输入年龄:"))
score = float(input("请输入成绩:"))
print("\n您输入的信息如下:")
print("姓名:{},类型为:{}".format(name,type(name)))
print("年龄:{},类型为:{}".format(age,type(age)))
print("成绩:{},类型为:{}".format(score,type(score)))
9.流程控制
9.1顺序控制
9.2分支控制
- Python缩进非常重要,是用于界定代码块的,相当于其他编程语言里的大括号。
- 最短的缩进对较长的缩进有包含关系,缩进前后没有要求,但是每个代码块应具有相同的缩进长度。
9.3循环控制
9.3.1 for语句
- for语句基本语法:
for <变量> in <范围/序列>:
<循环操作语句>
- for基本语法说明:
- for,in是关键字,是规定好的。
- <范围/序列>可以理解要处理的数据集,需要是可迭代的对象(比如字符串,列表等)
- python中的for循环是一种“轮询机制”,是对指定的数据集,进行“轮询处理”。
- 循环时,依次将序列中的值取出赋给变量。
- 如需要遍历数字序列,可以使用内置range()函数,它会生成数列。range()生成的数列是前闭后开。
- range()的使用:

- for-else语法说明:
# 进入else的情况:for循环正常完成遍历,在遍历过程中,没有被打断(比如:没有执行到break语句)。
for <variable> in <sequence> :
<statements>
else:
<statements>
- 内存分析法(for语句执行):

9.3.2 while语句
- while语句基本语法:
while condition:
statements
- while-else语法:
# 在while...else判断条件为false时,会执行else的语句块,即:在遍历过程中,没有被打断(比如:没有执行到break语句)。
while condition:
statements
else:
additional_statements
10.函数
- 基本语法:

- 调用机制:

- 注意事项和使用细节:
- 如果同一个文件,出现两个函数名相同的函数,则以就近原则进行调用。
- 调用函数时,根据函数定义的参数位置来传递参数,这种传参方式就是位置参数,传递的实参和定义的形参顺序和个数必须一致,同时定义的形参,不用指定数据类型,会根据传入的实参类型决定。
- 函数可以有多个返回值,返回数据类型不受限制(多个返回值本质上返回一个元组)。
- 函数支持关键字参数,即:函数调用时,可以通过“形参名=实参值”形式传递参数。这样可以不受参数传递顺序的限制。
- 函数支持默认参数/缺省参数。默认参数,需要放在参数列表后。
- 函数支持可变参数/不定长参数,应用于调用函数时,不确定传入多少个实参的情况。传入的多个参数会组成一个元组(tuple)。
- 函数的可变参数/不定长参数,还支持多个关键字参数(key-value形式的参数),也就是多个”形参名=实参值“。传入的多个参数会组成一个字典(dict)。
- 在函数定义的过程中,可以同时用到必选参数、默认参数、可变参数、关键字参数中的一种或几种。但是需要特别注意的是,这四种参数在使用过程中是有顺序的,顺序依次应该是必选参数、默认参数、可变参数和关键字参数。
- 小结:
- 不同类型的参数是有顺序的,依次是必选参数、默认参数、可变参数和关键字参数。
- 默认参数一定要用不可变对象,用可变对象容易产生逻辑错误。
- *args表示的是可变参数,*args接收的是一个元组。
- **kw表示的是关键字参数,**kw接收的是一个字典。
def cry():
print("cry()..hi...")
def cry():
print("cry()..ok...")
# python中不存在函数的重载
# 输出:cry()..ok...
cry()
def f2(n1,n2):
return n1+n2,n1-n2
r1,r2 = f2(10,20)
# 输出:r1->30 r2->-10
print(f"r1->{r1} r2->{r2}")
# 函数支持可变参数/不定长参数
def sum(*args):
# args的类型为tuple
total = 0
for ele in args:
total += ele
return total
result = sum(1,2,3,100)
# 函数支持关键字可变参数
def person_info(**args):
# args的类型为dict
for arg_name in args:
print(f"参数名->{arg_name} 参数值->{args[arg_name]}")
person_info(name="tom", age=18, email="tom@qq.com")
- 将函数作为参数传递:
def get_max(num1,num2):
return num1 if num1 >= num2 else num2
def myfun(fun,num1,num2):
return fun(num1,num2)
print(get_max(20,38))
print(myfun(get_max,20,38))
# 函数关键字参数的使用
# 1 正向使用
def keywords_function(**args):
print(args)
keywords_function(name="Jack", age=20)
# 2 反向使用
def plus(x, y, z):
return x + y + z
dict = {"x": 1, "y": 2, "z": 3}
d1 = plus(dict["x"], dict["y"], dict["z"]) # 调用方式1:过于繁琐
d2 = plus(**dict) # 调用方式2
print(f"d1 = {d1} d2 = {d2}")
def plus(x, y, z=0, *args, **kw):
print("x=", x)
print("y=", y)
print("z=", z)
print("args=", args)
print("kw=", kw)
plus(1, 2)
print("*" * 100)
plus(1, 2, 3, 4, 5, 6, a=1, b=2)
"""
输出为:
x= 1
y= 2
z= 0
args= ()
kw= {}
**************************************
x= 1
y= 2
z= 3
args= (4, 5, 6)
kw= {'a': 1, 'b': 2}
"""
- lambda匿名函数:
- def关键字,可以定义有名称的函数,这个函数可以重复的使用。
- lambda关键字,可以定义匿名函数(无名称),匿名函数只能使用一次。
- 匿名函数用于临时创建一个函数,只使用一次的场景。
- 匿名函数的基本语法:
- lambda 形参列表: 函数体(一行代码)
- lambda关键字,表示定义匿名函数。
- 函数体:完成的功能,只能写一行,不能写多行代码。
- 匿名函数不需要return,运算结果就是返回值。
def myfun(fun,num1,num2):
return fun(num1,num2)
print(myfun(lambda num1,num2: num1 if num1 >= num2 else num2,20,38))
11.数据容器(Collections)
- 数据容器中存放的数据可以是任意类型。
11.1 列表(list)
- 列表的元素可以有多个,而且数据类型没有限制,允许有重复元素,并且是有序的。
- 反向索引:索引也可以从尾部开始,最后一个元素的索引为-1,往前一位为-2,以此类推。

- 列表生成式:
# 列表生成式
# 基本语法 [列表元素的表达式 for 自定义变量 in 可迭代对象]
list1 = [ele*2 for ele in range(1,5)]
# [2, 4, 6, 8]
print(list1)
list2 = [ele+ele for ele in "Java"]
# ['JJ', 'aa', 'vv', 'aa']
print(list2)
list3 = [ele*ele for ele in range(1,11)]
# [1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
print(list3)
tokens = [
["Hello", "world"],
["Python", "is", "awesome"],
["List", "comprehensions"]
]
# 将嵌套列表(二维列表)展平成一个一维列表,其中外循环是:for line in tokens,内循环是:for token in line
corpus = [token for line in tokens for token in line]
# ['Hello', 'world', 'Python', 'is', 'awesome', 'List', 'comprehensions']
print(corpus)
- 列表的元素是可以修改的,修改后,列表变量指向地址不变,只是数据内容变化。



list_color = ["red","green","white","grey","black"]
index = 0
while index < len(list_color):
print(list_color[index])
index += 1
print("-----------------------------")
for i in range(len(list_color)):
print(list_color[i])
print("-----------------------------")
for element in list_color:
print(element)
# 更新 ['purple', 'green', 'white', 'grey', 'black']
list_color[0] = "purple"
print(list_color)
# 添加 ['purple', 'green', 'white', 'grey', 'black', 'yellow']
list_color.append("yellow")
print(list_color)
# 删除 ['purple', 'green', 'white', 'grey', 'black']
del list_color[-1]
print(list_color)
11.2 元组(tuple)
- 元组可以存放多个不同类型数据,元组是不可变序列。元组的不可变是指当你创建元组的时候,它就不能改变了,也就是说它也没有append(),insert()这样的方法,但它也有获取某个索引值的方法,但不能重新赋值。
- 元组的元素可以有多个,而且数据类型没有限制(甚至可以嵌套元组),允许有重复元素,并且是有序的。
- 元组的内容不可以修改,但是可以修改元组内list的内容。
- 定义只有一个元素的元组,需要带上逗号,否则就不是元组类型。
- 为什么有了列表,python设计还要搞一个元组?

11.3 字符串(str)
- 在Python中处理文本数据是使用str对象,也成为字符串。字符串是由Unicode码位构成的不可变序列。
- ord()返回单个字符对应的Unicode编码值。
- chr()返回码值对应的字符。
- 字符串字面值的三种写法:

- 字符串是不可变序列,不能修改。
str = "hello world"
str[0] = "s" # str不能修改,地址不发生变化,不允许
str = "abc" # 地址发生变化,允许
- 在Python中,字符串的长度没有限制,取决于计算机内存的大小。
- 在Python中,字符串可以比较大小,比较规则类似于C语言中的strcmp。
- 切片:从一个序列中,取出一个子序列。
- 序列:内容连续,有序,可使用索引的一类数据容器。
# 基本语法:序列[起始索引:结束索引:步长],起始索引默认为0,结束索引默认截取到结尾,步长默认为1
str="hello world"
# 切片操作并不会影响原序列,而是返回了一个序列
slice1 = str[0:5:1]
print(slice1) # hello
# 步长为负数,表示反向取,同时注意起始索引和结束索引也要反向标记
slice2 = str[-1:-6:-1]
print(slice2) # dlrow
slice2 = str[-1:-6:-2]
print(slice2) # drw
11.4 集合(set)
- 集合是由不重复元素组成的无序容器。
- 不重复元素:集合中不会有相同的元素。
- 无序:集合中元素取出的顺序,和定义时元素顺序并不能保证一致。
- 创建空集合只能用set(),不能用{},{}创建的是空字典。
- 集合中不支持索引,所以对集合进行遍历,只能用for,不能用while。
- 集合底层会按照自己的一套算法来存储和取数据,所以每次取出顺序是不变的。
- 集合生成式:
# 集合生成式基本语法:{集合元素表达式 for 自定义变量 in 可迭代对象}
set1 = {ele*2 for ele in range(1,5)}
print(set1)
set2 = {ele+ele for ele in "韩曙平"}
print(set2)
11.5 字典(dict)
- 字典是一种映射类型,Key–Value的映射关系。字典的key必须是唯一的,如果指定了多个相同的key,后面的键值对会覆盖前面的。
- 字典的遍历:
dict_a = {'one': 1,'two': 2,'three': 3}
# 遍历方式一:依次取出key,在通过dict[key]取出对应的value
for key in dict_a:
print(f"key为{key},value为{dict_a[key]}")
# 遍历方式二:依次取出value
for value in dict_a.values():
print(value)
# 遍历方式三:依次取出key-value
for key,value in dict_a.items():
print(f"key:{key},value:{value}")
- 创建空字典可以通过dict()或{}。
- 字典生成式:
# 字典生成式
# 基本语法:{字典key的表达式:字典value的表达式 for 表示key的变量,表示value的变量 in zip(可迭代对象,可迭代对象)}
books = ["红楼梦","西游记","三国演义","水浒传"]
authors = ["曹雪芹","吴承恩","罗贯中","施耐庵"]
dict_b = {key:value for key,value in zip(books,authors)}
# {'红楼梦': '曹雪芹', '西游记': '吴承恩', '三国演义': '罗贯中', '水浒传': '施耐庵'}
print(dict_b)
11.6 小结




12.传参机制
12.1 字符串和数值类型传参机制
- 字符串和数值类型传参机制:
- 字符串和数值类型是不可变数据类型,当对应的变量的值发生了变化时,它对应的内存地址会发生改变。

- 字符串和数值类型是不可变数据类型,当对应的变量的值发生了变化时,它对应的内存地址会发生改变。
12.2 list,tuple,set,dict的传参机制

12.3 小结
- Python数据类型主要有:int,float,bool,str,list,tuple,set,dict。分为可变数据类型和不可变数据类型。
- 可变数据类型:当该数据类型的变量的值发生了改变,如果它的内存地址不变,那么这个数据类型就是可变数据类型。(list,set,dict)
- 不可变数据类型:当该数据类型的变量的值发生了改变,如果它的内存地址也发生了变化,那么这个数据类型就是可变数据类型。(int,float,bool,str,tuple)
13.模块
- 模块:模块是一个py文件,后缀名为.py。模块可以定义函数、类和变量,模块里也可能包含可执行的代码。
- 模块导入:
# import语句通常写在文件开头
# 1.导入一个或多个模块
"""
import 模块
import 模块1,模块2
import math,random
"""
# 2.导入模块的指定功能
"""
from 模块 import 函数,类,变量...
from math import fabs
"""
# 3.导入模块的全部功能
"""
from 模块 import *
from math import *
"""
# 4.给导入的模块或功能取别名
"""
from 模块 import 函数,类,变量... as 别名
from math import fabs as fa
"""
- 注意事项:
- 使用__name__可以避免模块中测试代码的执行。
- 使用__all__可以控制import *时,哪些功能被导入。注意:import 模块,不受__all__的限制。
# module文件
def fun1():
print("fun1()")
def fun2():
print("fun2()")
# 避免运行主程序后,测试代码的加载
if __name__ == "__main__":
print("测试代码")
# main文件
import module
print("主程序代码")
module.fun1()
module.fun2()
# module文件
__all__ = ['fun1']
def fun1():
print("fun1()")
def fun2():
print("fun2()")
# main文件
from module import *
fun1()
# 报错,module文件中限制使用fun2()
# fun2()
14.包

14.1 pip的使用
- 进入到命令控制台。
- pip install 库名/包名
- 注意:pip是通过网络安装的,需要网络是连通的。
14.2 指定pip源

15.类型注解
- 类型注解(type-hint)的作用:

# 提示传入参数的类型
def fun1(a: str)
for ele in a:
print(ele)
15.1 变量类型注解
class Cat:
pass
n1: int = 10
name: str = "张三"
n2 = 2.1 # type: float
cat: Cat = Cat()
my_list: list[int] = [100, 200, 300]
my_tuple: tuple[str, str] = ("run", "sing")
my_set: set[str] = {"jack", "tim"}
my_dict: dict[str, int] = {"no1": 1, "no2": 2}
15.2 注释类型注解
n2 = 2.1 # type: float
15.3 函数类型注解
def fun(a: int, b: int) -> int:
return a + b
15.4 Union类型
- Union:对一个变量或形参指定它可以为哪些类型。

from typing import Union
def fun(a: Union[int, float], b: Union[int, float]) -> Union[int, float]:
return a + b
fun(1.0, 2)
16.常用函数
16.1 zip
- zip()用于将多个可迭代对象(列表、元组等)"打包"成一个个元组,然后返回一个zip对象(可迭代对象)。
names = ['Alice', 'Bob', 'Charlie']
ages = [25, 30, 35]
countries = ['USA', 'UK', 'Canada']
# 使用zip组合三个列表
zipped = zip(names, ages, countries)
# 转换为列表查看
print(list(zipped))
# 输出: [('Alice', 25, 'USA'), ('Bob', 30, 'UK'), ('Charlie', 35, 'Canada')]
for name, age, country in zip(names, ages, countries):
print(f"{name} is {age} years old from {country}")
# 输出:
# Alice is 25 years old from USA
# Bob is 30 years old from UK
# Charlie is 35 years old from Canada
keys = ['name', 'age', 'country']
values = ['Alice', 25, 'USA']
# 使用zip创建字典
person = dict(zip(keys, values))
print(person) # {'name': 'Alice', 'age': 25, 'country': 'USA'}
三,面向对象
1.类和对象
class Cat:
# None是Python的内置常量,通常被用来代表空值的对象
# None是NoneType类型的唯一实例
name = None # 姓名属性
age = None # 年龄属性
color = None # 颜色属性
xb_cat = Cat()
xb_cat.name = "小白"
xb_cat.age = 2
xb_cat.color = "白色"
print(f"姓名:{xb_cat.name},颜色:{xb_cat.color},年龄:{xb_cat.age}")
-
内存解析:

-
对象的传递机制:

-
对象的传参机制:

-
对象的布尔值:

2.成员方法
# 定义成员方法的基本语法:
"""
def 方法名(self,形参列表):
方法体
1.在方法定义的参数列表中,有一个self
2.self是定义成员方法时,需要写上的
3.self表示当前对象本身
4.当我们通过对象调用方法时,self会隐式传入
5.在方法内部,需要使用self,才能访问到成员变量
"""
class Person:
name = None
age = None
def hi(self):
print("hi, python")
def cal01(self):
sum = 0
for i in range(1, 1001, 1):
sum += i
return sum
def cal02(self, n):
sum = 0
for i in range(1, n + 1, 1):
sum += i
return sum
def get_sum(self, num1, num2):
return num1 + num2
p = Person()
p.hi()
p.cal01()
- Python支持对象动态添加方法。
def hi():
print("hi,python")
class Person:
name = None
def ok(self):
print("ok")
p1 = Person()
p2 = Person()
# 为p1对象动态添加hi(),只针对p1
p1.m1 = hi
p1.m1()
# 报错,p2无m1()
# p2.m1()
# <class 'function'> 动态添加的方法类型为:function
print(type(p1.m1))
# <class 'method'> 成员方法类型为:method
print(type(p1.ok))
3.self
- 在方法定义的参数列表中,有一个self。
- 在方法内部,要访问成员变量和成员方法,需要使用self。
- self是定义成员方法时,需要写上的,如果不写,则需要使用@staticmethod标注,否则会报错。
- 通过@staticmethod可以将方法转为静态方法。
- 静态方法,可以不带self。
- 静态方法调用方式:①对象调用,②类名调用。
class Person:
name = None
age = None
def compare_to(self,other):
if id(self) == id(other):
return True
if self.age == other.age and self.name == other.name:
return True
return False
@staticmethod
def fun():
print("static method")
p1 = Person()
p1.name = "张无忌"
p1.age = 18
p2 = Person()
p2.name = "张无忌"
p2.age = 17
print(p1.compare_to(p2))
p2.age = 18
print(p1.compare_to(p2))
p1.fun()
Person.fun()
4.构造方法
"""
构造方法基本语法:
def __init__(self,参数列表):
代码
1.在初始化对象时,会自动执行__init__方法
2.构造方法完成对象的初始化任务
3.一个类中只有一个__init__方法,即使写了多个,也只有最后一个生效
4.构造方法不能有返回值
5.Python支持动态生成对象属性
"""
class Person:
name = None
def __init__(self,name,age):
print(f"地址为:{id(self)}的对象进行初始化……")
self.name = name
# Python支持动态生成对象属性
self.age = age
p1 = Person("张三",18)
print(f"{p1.name} {p1.age}")
5.面向对象三大特征
5.1封装性
- 封装:把抽象出来的数据和对数据的操作封装在一起,数据被保护在内部。
- 类中的变量或方法以双下划线__命名开头,则该变量或方法为私有的,私有的变量或方法,只能在本类内部使用,类的外部无法使用。
- 默认情况下,类中的变量和方法都是公有的,它们的名称前都没有下划线。公共的变量和方法,在类的外部和内部都可以正常访问。
class Clerk:
name = None
__job = None
__salary = None
def __init__(self, name, job, salary):
self.name = name
self.__job = job
self.__salary = salary
def set_job(self, job):
self.__job = job
def get_job(self):
return self.__job
def set_salary(self, salary):
self.__salary = salary
def get_salary(self):
return self.__salary
- Python语言动态特性,会出现伪私有属性的情况。

"""
Python语言动态特性,会出现伪私有属性的情况。
Python语言动态特性,会动态创建属性__job,但这个属性
和我们在类中定义的私有属性__job并不是同一个变量,我们在类中定义的__job私有属性完整的名字为_Clerk__job
"""
clerk = Clerk("张三", "Python工程师", 8000)
print(clerk.get_job()) # Python工程师
clerk.__job = "Go工程师"
print(clerk.__job) # Go工程师
5.2继承性

- 子类继承了父类所有的属性和方法,非私有的属性和方法可以在子类直接访问,但是私有属性和方法不能在子类中直接访问,要通过父类提供公共的方法去访问。
- Python语言中,object是所有类的基类。在pyCharm中,通过ctrl + h查看继承关系。
- Python支持多重继承。
- 在多重继承中,如果有同名的成员,遵守从左到右的继承优先级(即:写左边的父类优先级高,写在右边的父类优先级低)。
class Computer:
cpu = None
memory = None
hard_disk = None
def __init__(self, cpu, memory, hard_disk):
self.cpu = cpu
self.memory = memory
self.hard_disk = hard_disk
def get_details(self):
return f"cup:{self.cpu},memory:{self.memory},hard_disk:{self.hard_disk}"
class PC(Computer):
brand = None
def __init__(self, cpu, memory, hard_disk, brand):
# self.cpu = cpu
# self.memory = memory
# self.hard_disk = hard_disk
# self.brand = brand
super().__init__(cpu,memory,hard_disk)
self.brand = brand
def print_info(self):
print(super().get_details() + f",brand:{self.brand}")
class NotePad(Computer):
color = None
def __init__(self, cpu, memory, hard_disk, color):
super().__init__(cpu,memory,hard_disk)
self.color = color
pc = PC("因特尔", "金士顿", "三星", "联想")
notePad = NotePad("AMD", "西部", "三星", "小米")
pc.print_info()
class C1:
variable = 1
class C2:
variable = 2
class C3(C1,C2):
# 定义空类,需要使用pass作为占位符
pass
c3 = C3()
print(c3.variable)
- 调用父类成员需要注意的细节:
- 如果子类和父类出现同名的成员,可以通过父类名、super()访问父类的成员。super()不支持链式写法。使用父类名调用父类方法需要传入self。
- 子类不能直接访问父类的私有成员。
- 访问不限于直接父类,而是建立从子类向上级父类的查找关系A->B->C。
- 建议使用super()的方式,因为如果使用父类名方式,一旦父类变化,类名需要统一修改,比较麻烦。
5.3多态性
6.魔术方法(Magic Method)
- 什么是魔术方法:

- 常用的魔术方法:

- __eq__是一个比较运算符:对象之间进行比较时,比较的是内存地址是否相等,即判断是不是同一对象。
7.Class对象
- Python中,类本身就是一种对象。通过类名也可以实现调用非静态成员方法。
class Monster:
name: str = "青牛精"
age: int = 22
def hi(self):
print("hi")
print(Monster)
# 通过Class对象,可以引用属性(没有创建实例对象也可以引用/访问)
print(f"{Monster.name} {Monster.age}")
# 通过类名调用非静态成员方法
Monster.hi(Monster)
8.静态方法

9.抽象类

from abc import ABC, abstractmethod
class Animal(ABC):
@abstractmethod
def shout(self):
pass
class Tiger(Animal):
def shout(self):
print("老虎 嗷嗷叫~~")
tiger = Tiger()
tiger.shout()
- 抽象类注意事项:
- 抽象类不能实例化。
- 抽象类需要继承ABC,并且需要至少一个抽象方法。
- 没有抽象方法,只继承ABC的类不是抽象类。
- 抽象类中可以有普通方法。
- 如果一个类继承了抽象类,则它必须实现抽象类的所有抽象方法,否则它仍然是一个抽象类。
四,错误和异常
- 语法错误/句法错误在执行前,编译器就可以检测到,而异常是执行时检测到的。
- 查看异常的层级关系:PyCharm中Ctrl + H。
1.异常处理
1.1 捕获异常
- 如果异常发生了,则异常发生后面的代码不会执行,直接进入到except子句。
- 如果异常没有发生,则顺序执行try的代码块,不会进入到except子句。
- 一个except子句,可以捕获多个不同的异常。
- 如果希望没有发生异常的时候,要执行某段代码,则使用else子句。
- 如果希望不管是否发生异常,都执行某段代码(比如关闭连接,释放资源)则使用finally子句。
- 可以有多个except子句,捕获不同的异常(进行不同的业务处理),如果发生异常,只会匹配一个except,建议把具体的异常写在前面,基类异常写在后面(比如:IndexError在前,Exception在后),这样当具体异常匹配不到时,再由基类异常匹配。
1.2触发异常/抛出异常
try:
raise ZeroDivisionError("主动抛出ZeroDivisionError异常")
except ZeroDivisionError as e:
print(f"异常类型:{type(e)},异常信息:{e}")
2.异常传递
- 如果一个异常发生了,但是没有捕获处理异常,那么这个异常会传递给调用者处理。
- 如果所有的调用者都没有处理,最终会由系统处理。
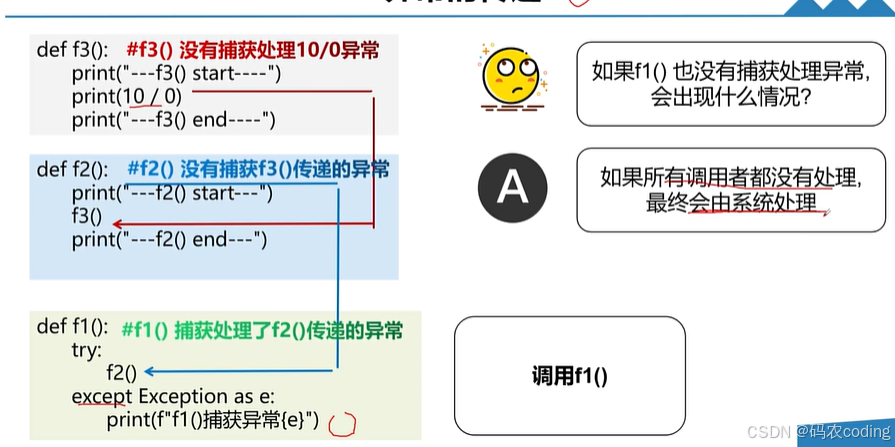
3.自定义异常

class AgeError(Exception):
pass
age = 0
while True:
try:
age = int(input("请输入年龄(整数):"))
if not(18 <= age <= 120):
raise AgeError("年龄范围有误,正确范围:[18,120]")
except (ValueError,AgeError) as e:
if isinstance(e,ValueError):
print("请输入一个整数")
else:
print(e)
else:
break
print(f"输入年龄为:{age}")
五,文件处理
1.写操作
f1 = open("./write.txt","w",encoding="utf-8")
# "w"会截断文件,"a"追加文件
i = 1
while i <= 10:
f1.write("University\n")
i += 1
f1.close()
2.读操作
f1 = open("./hi.txt","r",encoding="utf-8")
# content = f1.readline()
# while content != "":
# print(content,end="")
# content = f1.readline()
# f1.close()
lines = f1.readlines()
for line in lines:
print(line,end="")
f1.close()
3.删除操作
import os
if os.path.exists("./write.txt"):
os.remove("./write.txt")
else:
print("不存在")
4.目录操作
import os
# os.path.isdir(path)如果path是现有的目录,则返回True
# 创建一级目录
# if not os.path.isdir("./testDir"):
# os.mkdir("./testDir")
# else:
# print("目录已存在")
# 创建多级目录
# if not os.path.isdir("./testDir/aaa"):
# os.makedirs("./testDir/aaa")
# else:
# print("目录已存在")
# 删除一级目录
# if os.path.isdir("./testDir/aaa"):
# os.rmdir("./testDir/aaa")
# 删除多级目录
if os.path.isdir("./testDir/aaa"):
os.removedirs("./testDir/aaa")
5.文件信息
import os
import time
f_stat = os.stat("./write.txt")
print("---------文件信息---------")
print(f"文件大小->{f_stat.st_size}\n"
f"最近访问时间->{time.ctime(f_stat.st_atime)}\n"
f"最近修改时间->{time.ctime(f_stat.st_mtime)}\n"
f"文件创建时间->{time.ctime(f_stat.st_ctime)}")
6.注意事项
- f.flush():刷新流的写入缓冲区到文件。
- 调用f.write(),内容并没有真正写入文件,而是先积攒到缓存区。
- 当调用flush()时,内容会真正写入到文件。
- 这样是为了避免频繁的操作硬盘,导致效率降低(积攒一定量的数据,一次性写入文件,提高效率)。
- f.close():刷新并关闭此流,也就是f.close()内置的flush功能。
- with open() as f:在处理文件对象时,子句体结束后,文件会自动关闭。
with open("d:/a/hello.txt","r",encoding="UTF-8") as f:
lines = f.readlines()
print("文件内容")
for line in lines:
print(line, end="")
print("文件是否关闭->",f.closed)

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









