






文章目录
场景
现有场景
在整个Kubernetes集群中有多套环境多套服务如果需要查询日志较为繁琐,并且考虑到开发查询日志并不太方便,所以我们通过hostpath方式将日志文件持久化存储到服务器本地,然后通过ELK将日志收集并进行展示,这样就解决了日志查看繁琐问题。
痛点:
因为使用hostpath持久化到本地,每个pod都会将日志存储在运行节点的固定目录上,所有的pod都是同样的操作,一个node节点上好几十个pod,就会导致同一个文件被多个pod写入内容导致日志覆盖的问题,往往最后一个pod才可以真正的将日志写入到该文件中,就会导致日志丢失的问题。
解决方案
痛点分析
- 日志覆盖的根源
1、共享路径冲突:所有的pod日志文件路径相同(历史遗留问题,但是如果我们根据每个服务的名称去划分路径的话,如果启动多个pod副本,几个服务同时向同一个文件写入,也会有概率导致丢失)
2、文件写入模式:pod以覆盖模式(非追加模式)打开日志文件(hostpath是直接挂载上去的)
解决思路
从上述的覆盖根源来看,我们需要将每个pod隔离出来就可以解决覆盖问题,但是怎么将每个pod都单独出来呢?
- 通过kubernetes的pv、pvc的方式,动态的给每个pod都生成一个存储路径
- 通过subPathExpr 的方式自动为每个pod创建一个独立的目录进行存储
- 使用daemonset方式启动filebeat收集日志
- 部署 ELK,接收filebeat收集的日志并进行展示
注意:subPathExpr 这种方式需要Kubernetes 1.15+版本支持
pv、pvc的这种方式需要为每个deploy都新增pvc,加大了运维维护成本,所以暂时不考虑该方案
实施指南
一、Kubernetes pod单独存储操作示例
1. 应用deploy配置
- deploy注入pod名称环境变量
env:
- name: POD_NAME # 变量名
valueFrom:
fieldRef:
fieldPath: metadata.name # 自动获取 Pod 名称
- 使用subPathExpr 动态生成子目录
volumeMounts:
- mountPath: /opt/logs
name: logs-dir
subPathExpr: $(POD_NAME) # env变量引用
- 配置houstpath卷
volumes:
- name: logs-dir
hostPath:
path: /data/logs/uat
type: DirectoryOrCreate # 自动创建目录
- 完整配置示例
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: ioscar-commonsystem-callcenter-server
name: ioscar-commonsystem-callcenter-server
namespace: uat
spec:
replicas: 1
selector:
matchLabels:
app: ioscar-commonsystem-callcenter-server
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
annotations:
kubectl.kubernetes.io/restartedAt: "2025-01-10T14:27:52+08:00"
creationTimestamp: null
labels:
app: ioscar-commonsystem-callcenter-server
spec:
containers:
- env:
- name: pod_name
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.name
- name: ns
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.namespace
- name: MY_POD_IP
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: status.podIP
image: harbor-ioscar.cbf.com/ioscar-uat/commonsystem-callcenter-server:116
imagePullPolicy: Always
name: ioscar-commonsystem-callcenter-server
ports:
- containerPort: 9103
protocol: TCP
readinessProbe:
failureThreshold: 15
httpGet:
path: /actuator/health
port: 9103
scheme: HTTP
initialDelaySeconds: 60
periodSeconds: 20
successThreshold: 1
timeoutSeconds: 1
resources:
limits:
cpu: "1"
memory: 1Gi
requests:
cpu: 200m
memory: 200Mi
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /opt/logs
name: logs-dir
subPathExpr: $(pod_name)
dnsPolicy: ClusterFirst
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
terminationGracePeriodSeconds: 30
volumes:
- hostPath:
path: /data/logs/uat
type: DirectoryOrCreate
name: logs-dir
2. 效果验证
最终实现的效果:将pod中的/opt/logs挂载到宿主机的/data/logs/uat/pod具体名称
# 1. 查看服务部署的具体node节点
kubectl get pod -n uat -o wide |grep ioscar-commonsystem-callcenter-server
# 2. 进入到node节点上
ssh node-1
# 3. 查看日志目录是否生成
ll /data/logs/uat/ioscar-commonsystem-callcenter-server-65b7f54f7b-6mmpr
至此日志覆盖的问题已经解决不回再出现日志丢失的问题,此时接入ELK进行日志收集即可
3. 可能遇到的问题
- 环境变量未定义
subPathExpr: $(pod_name) 引用了未声明的 pod_name,实际路径会变成空值,导致所有 Pod 共享 /data/logs/uat 根目录。
所以必须配置env环境变量,并且变量名称的大小写必须注意,env是什么subPathExpr就配置成什么
env:
- name: POD_NAME # 变量名
valueFrom:
fieldRef:
fieldPath: metadata.name # 自动获取 Pod 名称
二、日志收集操作示例
1. 日志收集核心组件角色
filebeat(日志收集) --> kafka(削峰) --> logstach(日志解析) --> es(存储与检索(必选)) --> kibana(展示(必选))
filebeat:go语言编写,轻量级,支持断点续传适合部署在当量生产服务器上
kafka:缓冲层,解耦生产者和消费者,削峰。可以临时存储突增的日志数据,不会使下游服务因激增导致过载
logstach:日志脱敏或者日志打标签深度解析等功能(虽然也支持日志收集和输出,但是体量太大jvm运行,不如filebeat强大)
es:数据库对日志进行存储,并支持检索
kibana:日志展示,方便了开发人员直接查询到服务的日志
2. filebeat 安装与部署
filebeat是日志收集器需要在每个节点进行部署安装配置,比较麻烦,可以使用kubernetes集群的daemonset(会默认在每个节点启动一个实例,避免重复的安装部署操作)和configmap(类似于配置文件,将配置文件持久化出来,方便修改配置)来部署
# configmap配置
apiVersion: v1
data:
filebeat.yml: |
logging.level: error
filebeat.inputs: # 日志收集字段
- type: log
enabled: true
paths:
- /data/logs/uat/*/*.log # 日志采集(日志存放路径,支持通配符)
scan_frequency: 10s # 每10s扫描一次
tail_files: true # 从文件末尾开始读取
json.keys_under_root: true # 自动解析json日志
json.overwrite_keys: true
json.add_error_key: false
spool_size: 1000
idle_timeout: 10s
close_removed: true
output.kafka: # 日志发送给kafka
enabled: true
hosts: ["192.168.1.1:9092"] # kafka地址端口
#topic: "cbc"
topic: "ants-%{[app_name]}" # 自动创建topic app_name是一个json变量是日志文件中的内容(可以自己定义topic的名字)
partition.round_robin:
reachable_only: true
kind: ConfigMap
metadata:
name: filebeat
namespace: default
# daemonset
apiVersion: apps/v1
kind: DaemonSet
metadata:
labels:
name: log-filebeat
name: log-filebeat
namespace: default
spec:
selector:
matchLabels:
name: log-filebeat
template:
metadata:
labels:
name: log-filebeat
spec:
containers: # 下列就是使用的镜像
- image: harbor-ioscar.cbf.com/cbf/filebeat:7.1.1
imagePullPolicy: IfNotPresent
name: log-filebeat
resources: # 资源的限制
limits:
cpu: 800m
memory: 1G
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
- mountPath: /usr/share/filebeat/filebeat.yml # 映射到pod中的路径
name: filebeat # 关联volumes的名称实现关联关系
subPath: filebeat.yml
dnsPolicy: ClusterFirst
restartPolicy: Always
schedulerName: default-scheduler
volumes:
- configMap: # configmap座位挂载点
defaultMode: 420
items:
- key: filebeat.yml # configmap的键值对
mode: 420
path: filebeat.yml
name: filebeat # 引用的configmap名称
name: filebeat
3. kafka 安装与部署
kafka是日志收集中用来解耦、削峰的组件,主要的作用就是应对日志激增的问题,保护下游组件不会因为激增的日志崩溃。
依赖环境
1、jdk(不详细赘述了)
2、zookeeper(可以使用自己环境中的zookeeper如果没有kafka的安装包中也包含一个简易的)
- 解压安装包
# 解压安装包
tar -zxvf kafka_2.11-1.1.0.tgz
# 进入到kafka配置文件中创建zookeeper文件夹
mkdir zookeeper
# 创建下列文件夹用于存储日志和数据(后续在zookeeper配置文件中写入)
cd zookeeper
mkdir {logs,data}
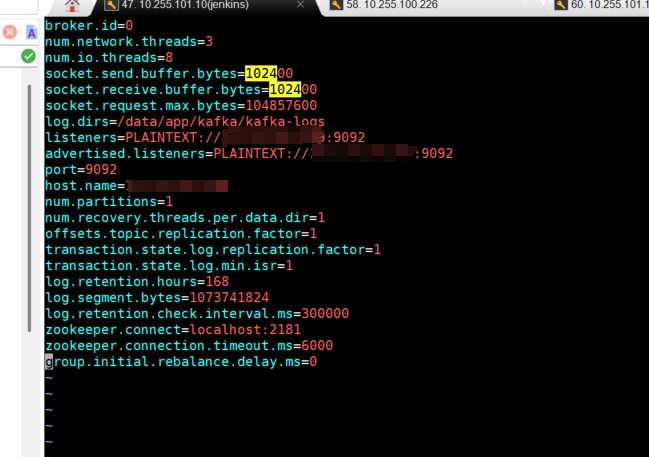
- 修改kafka配置文件
# 修改kafka的配置文件
vim /kafka/config/server.properties
broker.id=1 #这个id是唯一标识(必须唯一)
listeners=PLAINTEXT://ip:9092 #是kafka真正的bind的地址
advertised.listeners=PLAINTEXT://ip:9092 #将listener信息发布到zookeeper中去
port=9092 #端口号
host.name=ip #服务器IP地址,修改为自己的服务器IP
log.dirs=/mnt/soft/kafka_data/log/kafka #日志存放路径,上面创建的目录,需要手动创建,否则会启动报错
zookeeper.connect=localhost:2181 #zookeeper地址和端口,单机配置部署,localhost:2181
示例:
- 修改zookeeper配置文件
vim /kafka/config/zookeeper.properties
dataDir=/kafka/zookeeper/data # zookeeper的data目录(就是之前创建的zookeeper的data文件夹)
dataLogDir=/kafka/zookeeper/logs # zookeeper日志目录
clientPort=2181 # zookeeper端口号
maxClientCnxns=0
示例:

- 启动kafka服务
因为kafka依赖于zookeeper服务所以我们需要先将zookeeper启动起来,在启动kafka
# 先启动zookeeper
/kafka/bin/zookeeper-server-start.sh -daemon ../config/zookeeper.properties
# 确定zookeeper启动成功
netstat -lntp |grep 2181
# 启动kafka
/kafka/bin/kafka-server-start.sh ../config/server.properties
# 确定kafka启动成功
netstat -lntp |grep 9092
启动之后等待接收日志数据即可。
4. logstach安装部署
logstach在日志收集过程中承担日志的转发和日志深度解析的角色(比如日志打标签,日志脱敏等)
依赖环境
1、jdk1.8
# 解压logstach压缩包(包名称自己指定)
tar -zxvf logstash.tar.gz
# 修改logstach的配置文件
cd logstash/config
vim logstash-sample.conf
# 日志导入
input {
kafka {
bootstrap_servers => "192.168.1.1:9092" # 读取kafka的地址以及端口
topics_pattern => "cbc-.*" # 读取kafka的topic名称,如果多个以,分割
group_id => "logstash"
consumer_threads => 40
codec => "json"
decorate_events => true
auto_offset_reset => "latest"
codec => "json"
}
}
# 日志匹配输出
output {
elasticsearch { # 这里表示将日志输出给es
hosts => ["http://192.168.1.1:9200"] # es的地址以及端口
index => "%{[@metadata][kafka][topic]}-%{+YYYYMMdd}"
}
}
# 修改启动参数
vi /logstash/config/jvm.options
-Xms4g # 指定启动占用内存为4g
-Xmx4g
# 启动logstach
cd logstash/bin
./logstash -f ../config/logstash-sample.conf
# 检查是否启动成功
netstat -lntp |grep 9600
还可以做一些日志的高级设置,因为我这里没需求,如果感兴趣可以自己查阅资料
5. elasticsearch安装部署
Elasticsearch是日志收集过程中用于存储和检索日志的一个组件,其实就是一个日志数据库
依赖环境
1、jdk1.8以上
2、需要使用es自己的系统账号(自己创建一个账号)
3、配置系统最大线程数为最大,否则无法启动
安装部署
# 解压es安装包
tar -zxvf elasticsearch.tar.gz
# 修改配置文件
vim config/elasticsearch.yml
cluster.name: ela-cbc # 设置集群名称,所有节点的这个配置应该都是一样的
node.name: cbc-es02-al # 设置当前节点名称
node.master: true # 设置当前节点为主节点
node.data: true # 设置当前节点为数据节点
path.data: /data/app/elasticsearch/data/data # 存储数据的路径
path.logs: /data/app/elasticsearch/logs/ # 存储日志的路径
bootstrap.memory_lock: false # 是否允许es将自己锁定在内存中,以提高性能,false不允许
network.host: 10.60.250.67 # 监听地址
network.tcp.no_delay: true # 启用tcp无延迟模式,提高数据传输效率
network.tcp.keep_alive: true # 保持tcp连接活跃
network.tcp.reuse_address: true # 启动tcp地址重用
network.tcp.send_buffer_size: 128mb # 设置tcp发送缓冲区大小
network.tcp.receive_buffer_size: 128mb # 设置tcp接受缓冲区大小
transport.tcp.port: 9300 # 设置es传输层通信端口
transport.tcp.compress: true # 启用传输层通信的数据压缩
http.max_content_length: 200mb # 设置http请求的最大内容长度
http.cors.enabled: true # 是否启用跨域资源共享,允许其他域名的应用访问es
http.cors.allow-origin: "*" # 设置语序的跨域源,即允许访问的域名
http.port: 9200 # 设置http服务监听端口
# 集群部署es可以写地址集,当然也可以单节点部署,只写一个节点ip加端口即可
discovery.seed_hosts: ["192.168.1.1:9300", "192.168.1.2:9300", "192.168.1.3:9300"] # 设置其他节点内部通信端口
cluster.initial_master_nodes: ["192.168.1.1:9200", "192.168.1.2:9200", "192.168.1.3:9200"] # 初始化列表
cluster.fault_detection.leader_check.interval: 15s # 设置集群故障检测的主节点检查间隔
discovery.cluster_formation_warning_timeout: 30s # 超时告警时间
cluster.join.timeout: 30s # 加入集群超时时间
cluster.publish.timeout: 90s # 集群发布超时时间
cluster.routing.allocation.cluster_concurrent_rebalance: 32 # 设置集群并发重新平衡数量
cluster.routing.allocation.node_concurrent_recoveries: 32 # 设置节点并发恢复数量
cluster.routing.allocation.node_initial_primaries_recoveries: 32 # 设置节点初始化主分片恢复的数量
vim config/jvm.options
- Xms1g #表示初始化内存大小
- Xmx1g #表示最大可以使用的内存大小
# 修改操作系统最大线程数
vim /etc/security/limits.conf
* soft nofile 65536 #用户打开文件数最大为65536(软资源限制)
* hard nofile 131072 #操作系统打开文件数不超过131072(硬性资源限制)
* soft nproc 2048 #用户和进程能打开的最大进程数2048(软资源限制)
* hard nproc 4096 #操作系统能打开的最大进程数4096(硬资源限制)
vim /etc/sysctl.conf
vm.max_map_count=262145 #这个参数设置一个进程可以创建的虚拟内存映射数量,在es中lucene使用大量的虚拟内存映射来管理索引数据,默认太小了,不满足es的允许
sysctl -p #刷新一下线程配置
# 创建es账号
useradd elsearch
passwd elsearch
# 启动es
chown elsearch.elsearch /elasticsearch # 属主属组全部给es账号
su elsearch # 使用es账号启动否则会报错
./bin/elasticsearch
# 检查是否成功
netstat -lntp |grep 9200
netstat -lntp |grep 9300
6. kibana安装部署
kibana是日志收集过程中用于日志展示的,格式化日志方便日志查看
依赖环境
1、jdk1.8以上
tar -zxvf kibana.tar.gz
# 修改配置文件
cd kibana/config
vim kibana.yml
# kibana端口
server.port: 5601
server.host: "0.0.0.0"
elasticsearch.hosts: ["http://192.168.1.1:9200"] # 这里配置es的地址加端口
i18n.locale: "zh-CN"
# 启动kibana
kibana/bin/kibana
# 访问
http://localhost:5601
总结
对于大多数 Kubernetes 1.15+ 环境,推荐将 subPathExpr 方案作为日志隔离的 标准化配置。该方案在以下场景表现尤为突出:
- 快速实施需求:新服务上线需立即实现日志隔离
- 混合部署环境:同一集群运行多团队/多项目服务
- 成本敏感场景:无法承担云存储费用的测试/开发环境
通过本方案,团队可建立起 分钟级 的日志隔离能力,同时为后续构建统一的日志观测平台奠定坚实基础。


















 2712
2712

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









