







v4解码
概述
在代码中就是首先生成
S
×
S
S\times S
S×S大小的网格,参考:特征层大小的网格,然后将我们预先设置好真实框的尺寸调整到有效特征层大小上,最后从v4的网络预测结果获得预测框的中心调整参数
x
o
f
f
s
e
t
x_offset
xoffset和
y
o
f
f
s
e
t
y_offset
yoffset和宽高的调整参数h和w,将目标网格中心点加上它对应的x_offset和y_offset的结果就是调整后的先验框的中心,也就是预测框的中心,然后再利用预测框和h、w结合 计算出调整后的预测框的的长和宽,最后我们将特征图上的预测框的位置再映射还原到原图416*416的大小上。此时在原图上就可以得到三个有效特征层的所有先验框,总数为
13
∗
13
∗
3
+
26
∗
26
∗
3
+
52
∗
52
∗
3
13*13*3 + 26*26*3 + 52*52*3
13∗13∗3+26∗26∗3+52∗52∗3个框框,—>,我们就可以获得预测框在原图上的位置,当然得到最终的预测结果后还要进行得分排序与非极大抑制筛选,由于一个网格点有3个先验框,则调整后有3个预测框,在原图上绘制的时候,同一个目标就有3个预测框,那要找出最合适的预测框,我们需要进行筛选。如下图举例:假设3个蓝色的是我们获得的预测框,黄色的是真实框,红色的是中心网格,我们就需要对这检测同一个目标的网格点上的3个调整后的先验框(也就是预测框)进行筛选。

概述
- 1.计算loss所需参数
在计算loss的时候,实际上是网络预测结果prediction和目标target之间的对比。 - 2.prediction是什么
对于v4的模型来说,网络最后输出的内容就是三个有效特征层,3个有效特征层的每个网格点(特征点)对应着预测框及其种类,即三个特征层分别对应着图片被分为不同size的网格后,每个网格点上三个先验框对应的位置、置信度及其种类。
输出层的shape分别为 ( 13 , 13 , 75 ) , ( 26 , 26 , 75 ) , ( 52 , 52 , 75 ) (13,13,75),(26,26,75),(52,52,75) (13,13,75),(26,26,75),(52,52,75),最后一个维度为75是因为是基于voc数据集的,它的类为20种,每一个特征层的每一个特征点(网格点)都预先设置3个先验框,每个先验框包含 1 + 4 + 20 1+4+20 1+4+20个参数信息,1代表这个先验框内部是否有目标,4代表框的中心点坐标(x,y)和框的宽高(h,w)参数信息,20代表框的种类信息,所以每一个特征点对应3*25参数, 即最后维度为3x25。如果使用的是coco训练集,类则为80种,最后的维度应该为255 = 3x85,三个特征层的shape为(13,13,255),(26,26,255),(52,52,255)
**注意:**此处得到的网络预测结果(3个有效特征层)y_prediction此时并没有解码,也就是yolov4.py文件中YoLoBody类的输出结果,有效特征层解码了之后才是真实图像上的情况。 - 3.target是什么
t a r g e t target target就是你制作的训练集中标注图片中的数据信息,这是网络的真实框情况。就是一个真实图像中,真实框的情况。第一个维度是batch_size,第二个维度是每一张图片里面真实框的数量,第三个维度内部是真实框的信息,包括位置以及种类。 - 4.loss的计算过程
拿到 p r e d pred pred和 t a r g e t target target后,不可以简单的减一下作为对比,需要进行如下步骤。
–> 第一步:对yolov4网络的预测结果进行解码,获得网络预测结果对先验框的调整数据
–> 第二步:对真实框进行处理,获得网络应该真正有的对先验框的调整数据,也就是网络真正应该有的预测结果 ,然后和我们得到的网络的预测结果进行对比,代码中 g e t t a r g e t get_target gettarget函数
-----> 判断真实框在图片中的位置,判断其属于哪一个网格点去检测。
-----> 判断真实框和哪个预先设定的先验框重合程度最高。
-----> 计算该网格点应该有怎么样的预测结果才能获得真实框(利用真实框的数据去调整预先设定好了的先验框,得到真实框该网格点应该预测的先验框的调整数据)
-----> 对所有真实框进行如上处理。
-----> 获得网络应该有的预测结果,将其与v4预测实际的预测结果对比。
–> 第三步: 将真实框内部没有目标对应的网络的预测结果,且重合程度较大的先验框进行忽略,因为图片的真实框中没有目标,也就是这个框的内部没有对象,框的位置信息是没有用的,网络输出的这个先验框的信息和其代表的种类是没有意义的,这样得到调整的先验框应该被忽略掉,网络只输出框内部有目标的数据信息,代码中get_ignore函数。
–> 第四步:利用真实框得到网络真正的调整数据和网络预测的调整数据后,我们就对其进行对比loss计算。
这里需要注意的是:上述处理过程依次对3个有效特征才层进行计算的,因为网络是分3个有效特征层进行预测的,计算3个有效特征层的loss的值相加之后就是我们模型最终的loss值,就可以进行反向传播和梯度下降了。
损失函数
YOLOv3的损失函数

GIOU
IOU图示如下:

公式:
G
I
o
U
=
1
−
I
o
U
+
∣
C
−
B
∪
B
g
t
∣
∣
C
∣
GIoU=1-IoU+\frac{\mid C-B\cup B^gt \mid}{ \mid C \mid }
GIoU=1−IoU+∣C∣∣C−B∪Bgt∣
引入了最小封闭形状
C
C
C(
C
C
C可以把A,B包含在内)
在不重叠的情况下能让预测框尽可能朝着真实框调整逼近
图示:

但是下面这种情况又存在缺陷:

DIOU

公式:
D
I
o
U
=
1
−
I
o
U
+
p
2
(
b
,
b
g
t
)
c
2
DIoU=1-IoU+\frac{p^2(b,b^gt)}{c^2}
DIoU=1−IoU+c2p2(b,bgt)
其中分子计算预测框与真实框的中心点欧氏距离
d
d
d。
分母能覆盖预测框与真实框的最小
B
O
X
BOX
BOX的对角线长度
c
c
c。
直接优化距离,速度更快,并解决
G
I
o
U
GIoU
GIoU的问题。

CIOU(v4使用)
公式:
C
I
o
U
=
1
−
I
o
U
+
p
2
(
b
,
b
g
t
)
c
2
+
α
ν
CIoU=1-IoU+\frac{p^2(b,b^gt)}{c^2}+\alpha \nu
CIoU=1−IoU+c2p2(b,bgt)+αν
其中: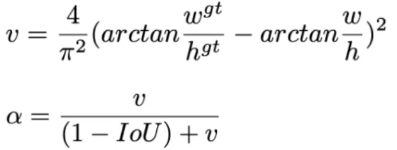
损失函数必须考虑三个几何因素:重叠面积,中心点距离,长宽比(其中
α
\alpha
α可以当做权重参数)
DIOU-NMS
之前使用NMS来决定是否删除一个框,现在改用
D
I
o
U
−
N
M
S
DIoU-NMS
DIoU−NMS
公式: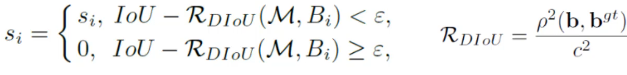
不仅考虑了
I
o
U
IoU
IoU的值,还考虑了两个
B
o
X
BoX
BoX中心点之间的距离。
其中
M
M
M表示高置信度候选框,
B
i
Bi
Bi就是遍历各个框跟置信度的重合情况。
Bag of specials(BOS)
增加稍许推断代价,但可以提高模型精度的方法。
SPPNet(Spatial Pyramid Pooling)
v3中为了更好的满足不同输入大小,训练的时候要改变输入数据的大小
SPP:
- 增大感受野
- SPP其实就是用最大池化来满足最终输入特征一致

CSPNet(Cross Stage Partial Network)
每一个
b
l
o
c
k
block
block按照特征图的
c
h
a
n
n
e
l
channel
channel维度拆分成两个部分。一部分正常走网络,另一份直接
c
o
n
c
a
t
concat
concat到这个
b
l
o
c
k
block
block的输出。(类似于残差结构)
:维度越高的时候,比如1024的通道使计算量一下子变大了好多,为了解决更高维度的计算问题:将输入特征图按着通道维度分为两个部分,一部分做卷积运算等,另一部分连过来相加,分为两个部分,解决了计算量的问题,因为计算的通道维度数直接为之前的1/2。(提升速度,训练的前向推理时间)

SAM(Spatial Attention Module)
在v4中没有使用CBAM注意力机制,使用的是
S
A
M
SAM
SAM注意力模型,
S
A
M
SAM
SAM也就是空间注意力模型。

空间注意力很好理解,假如输入的特征图为
16
∗
16
∗
1024
16*16*1024
16∗16∗1024其中16是特征的尺寸,1024是特征的通道数。可以理解为在空间中有1024个1616的特征图堆叠在一起,在这1024个特征图的同一位置:左上角位置为(0,0),该位置对于1024个特征图来说,有1024个值。然后对每一个这样的位置求平均,求最大,就可以得到由1024个到1个的特征图,这1个1616特征图的每个位置都是1024个特征图对应该位置的值的平均值或者最大值。得到这么一个特征图之后,经过
s
o
f
t
m
a
x
softmax
softmax或者
s
i
g
m
o
i
d
sigmoid
sigmoid函数,给每一个位置一个对应的分数,然后将这个特征图的得分乘以输入的
16
∗
16
∗
1024
16*16*1024
16∗16∗1024个特征信息的每个位置。这就是空间注意力。
PAN(Path Aggregation Network)
PAN的主要思想是:在特征融合阶段,好多提出的特征融合都是高层特征(13131024)去融合底层特征(5252256),引入了自底向上的路径,理解为底层特征去融合高层特征,使得底部信息更容易传到顶部。主要的核心感觉就是:将特征融合变成了双向的,而不再是单路径的。特征融合不在使用 a d d add add,而是使用 c o n c a t concat concat。
Mish激活
ReLu函数太绝对了,Mish函数更符合实际情况。
公式:
f
(
x
)
=
x
⋅
t
a
n
h
(
l
n
(
1
+
e
x
)
)
f(x)=x\cdot tanh(ln(1+e^x))
f(x)=x⋅tanh(ln(1+ex))




















 603
603

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











