







SQL慢查询优化
两个案例
案例一是从一个没索引到有索引的优化。
案例二是有索引但是还是出现了慢查询的情况。
背景
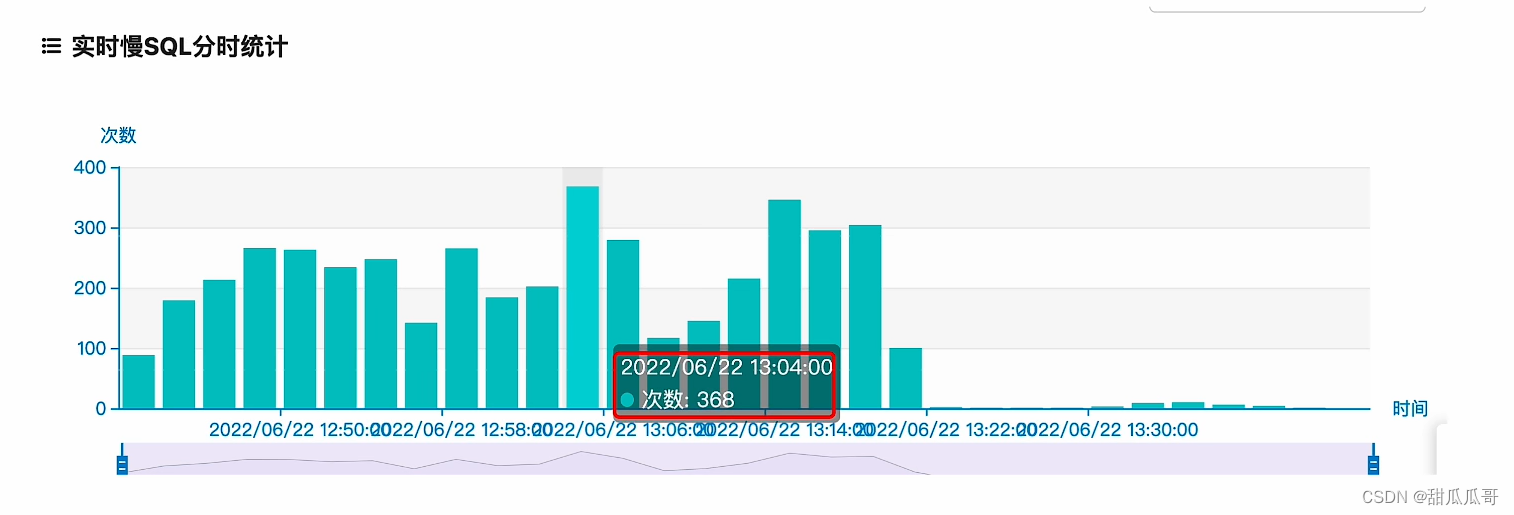
- 场景:慢查询已经报警,一天有几万条报警。
- 目标:每天出现的次数小于100次。
- 方案:分析慢SQL原因,执行方案。
- 结果:之前每分钟平均300次慢查询报警,降低到每分钟平均5次。
案例一
慢SQL
慢查询当中,最多的一条SQL语句,就是SELECT * FROM white_user WHERE user_id = ? AND status = ? AND level = ? AND type = ? LIMIT ?,?
通过某些条件来查询白名单用户。
表结构
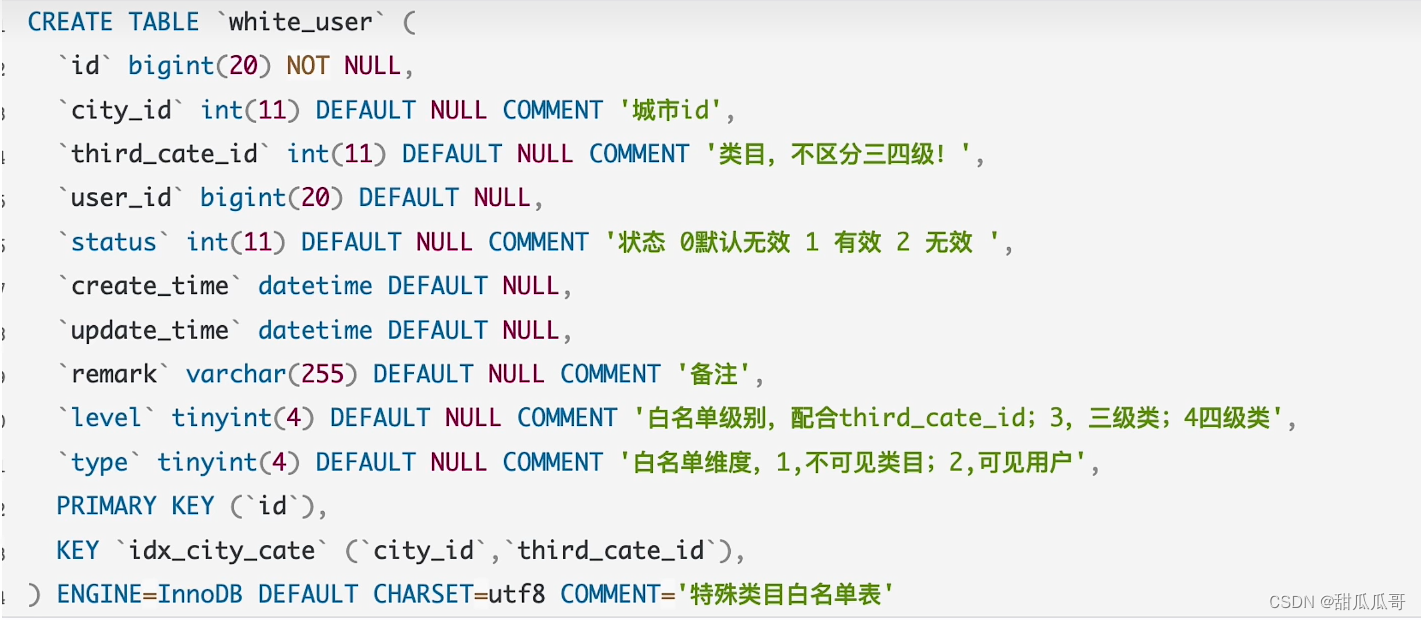
目前只有一个索引,是由city_id和third_cate_id构成的一个联合索引。
执行计划
第一个看的字段是possible_keys, 含义就是理论上用到的索引,现在为null。
第二个看的字段是key,含义就是实际上用到的索引,现在为null,就是没用到索引。
第三个看的的字段是type,含义就是采取什么类型的扫描数据,现在为all,就是全表扫描(补充知识:type)。
第四个看的字段是extra,含义就是额外的动作,现在为using where,意思就是使用了where查询(补充知识:extra)。

分析
现在问题已经很清楚了,就是因为查询没用到索引,没用到索引有2种原因,一种是没索引,另一种是有索引却没走索引,现在显然是前者。因此我们要做的就是创建索引。
创建索引又有一些学问了,就是在什么字段上创建索引?创建的索引的类型是什么?是普通索引,还是联合索引?
第一个问题-在什么字段上创建索引
简单点来讲,就是在区分度大的字段上创建索引。
第二个问题-创建什么类型的索引

where条件中,目前是一个多条件查询,如果只建一个字段的普通索引user_id,这样子,后面的status,level,type字段就没法命中索引了。
因此,这里比较适合建多值的联合索引。
加索引
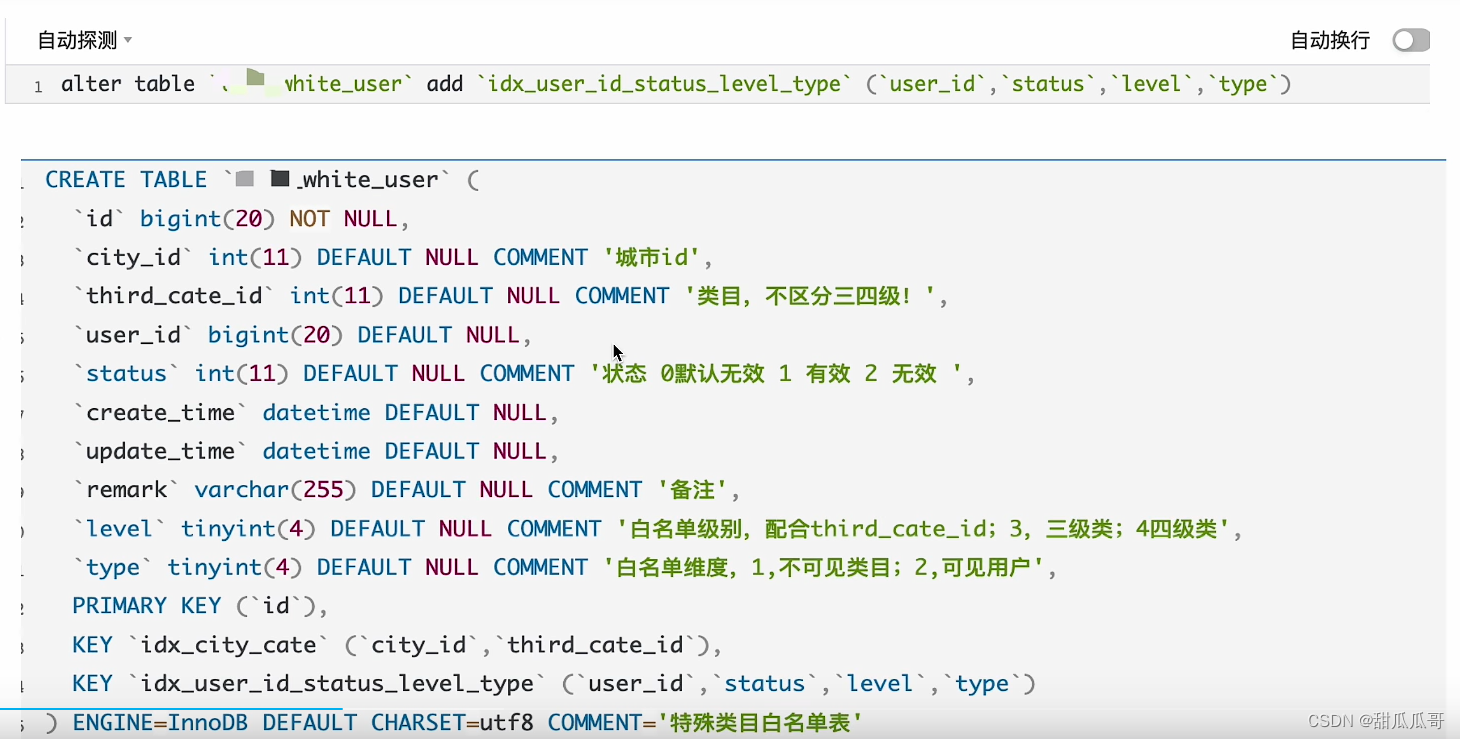
加索引后,执行计划
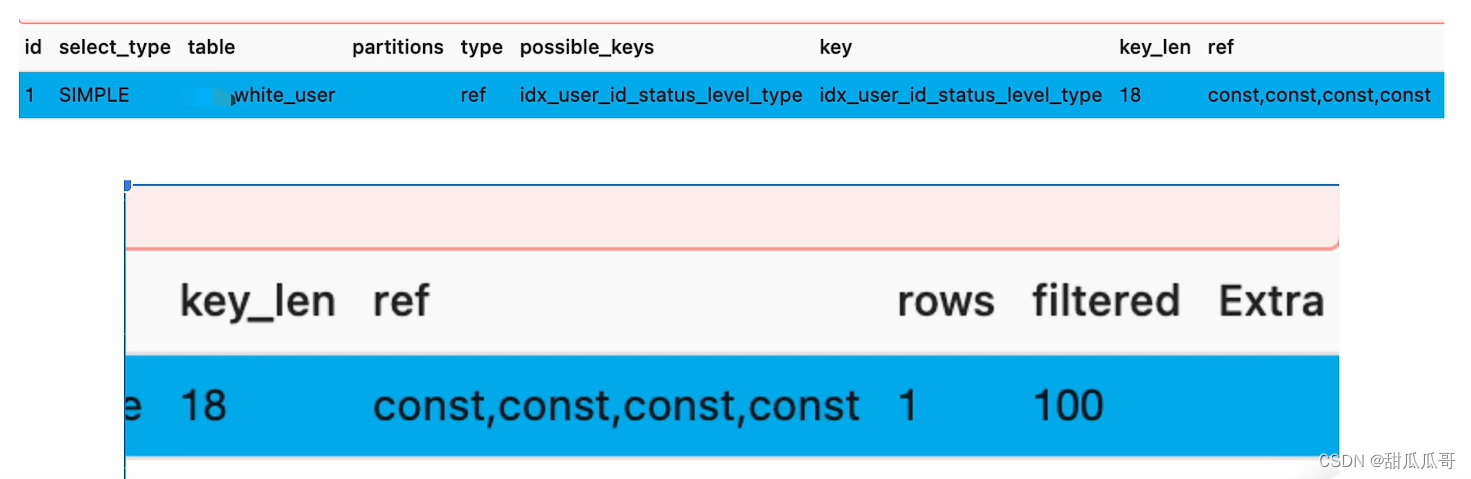
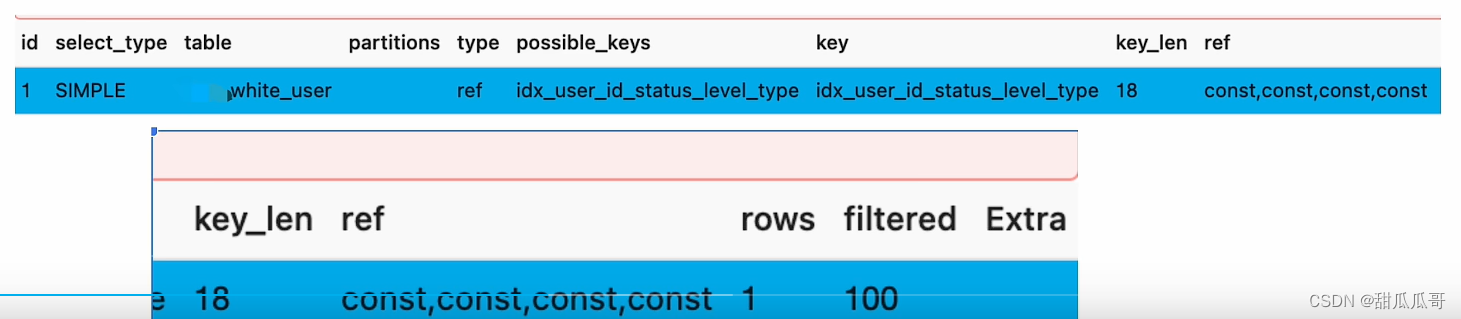
第一个看的字段是possible_keys,含义就是理论上用到的索引,现在为idx_user_id_status_level_type。
第二个看的字段是keys,含义就是实际上用到的索引,现在为idx_user_id_status_level_type,就是用到索引了。
第三个看的字段是type,含义就是采取什么类型的扫描数据,现在为ref。
第四个看的字段是extra,含义就是额外的动作,现在为null。
优化后,看看实时的慢SQL语句数量

案例二
场景:某些商家的退款列表查不出来。是指退款订单比较多的商家。
服务器日志:
Statement cancelled due to timeout or client request
就是查询超时了,也就是慢查询了。需要优化了。
SQL语句
场景: 根据某些条件,查询商家的退款订单列表,且按倒序排序,这个场景,生产上很常见。
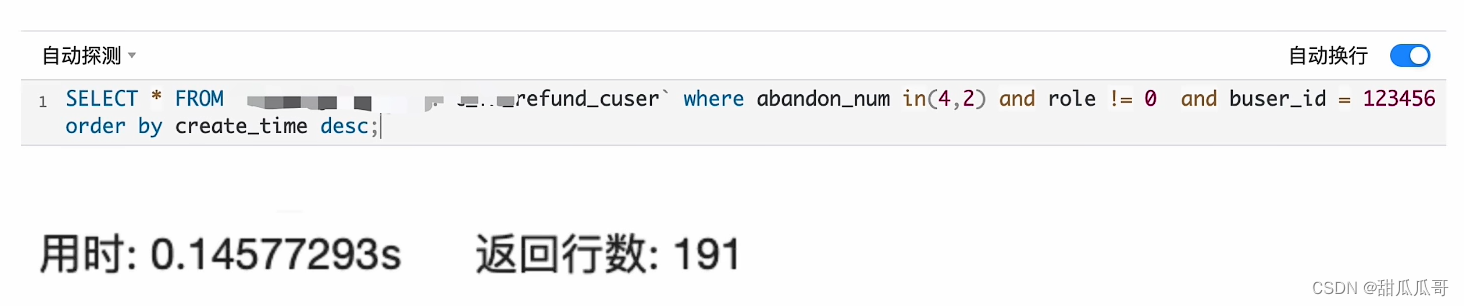
这个时候已经超过了慢查询的一个条件,慢查询的时间是超过一百毫秒就是慢查询。
表结构

执行计划
首先,我们直接来看了
key:用到索引idx_buser_id_cate_id
这次的确命中索引了,这次我们关注的重点在extra。
这次extra多了using filesort,一旦我们看到using filesort,就要警觉了,这是一个危险信号。

他代表一个文件排序,文件排序就会带来更多的耗时。
因为using filesort的意思,就是文件排序,一旦进行文件排序,SQL就变慢了。因为正常来说,索引排序是内存排序。

分析
既然现在出现了using filesort,那问题来了?什么时候会出现using filesort。
一般在order by的时候出现,比如现在我们的sql语句。

根据buser_id查询过滤完后,要根据create_time创建时间进行倒序排序。
但是在索引idx_buser_id_cate_id中,是没create_time的排序的。现在你要返回的数据是根据创建时间create_time倒序的,但是现在索引中没create_time的排序,那只好进行filesort文件排序后,才能完成返回create_time倒序的数据。

现在的问题就是这样的:
已经用到了索引:idx_buser_id_cate_id, 但因为有filesort才导致慢查询。
那我们的目标就是:用到索引的同时,也不要进行filesort。
解决方案
解决方案就是:建一个索引,既能满足查询的同时,也要进行create_time的排序。
因为查询语句中,只用到了buser_id和create_time。
这两个字段的顺序是先buser_id,后create_time,因为我们的执行计划是:先查询过滤,得到结果集后,才进行order by排序。
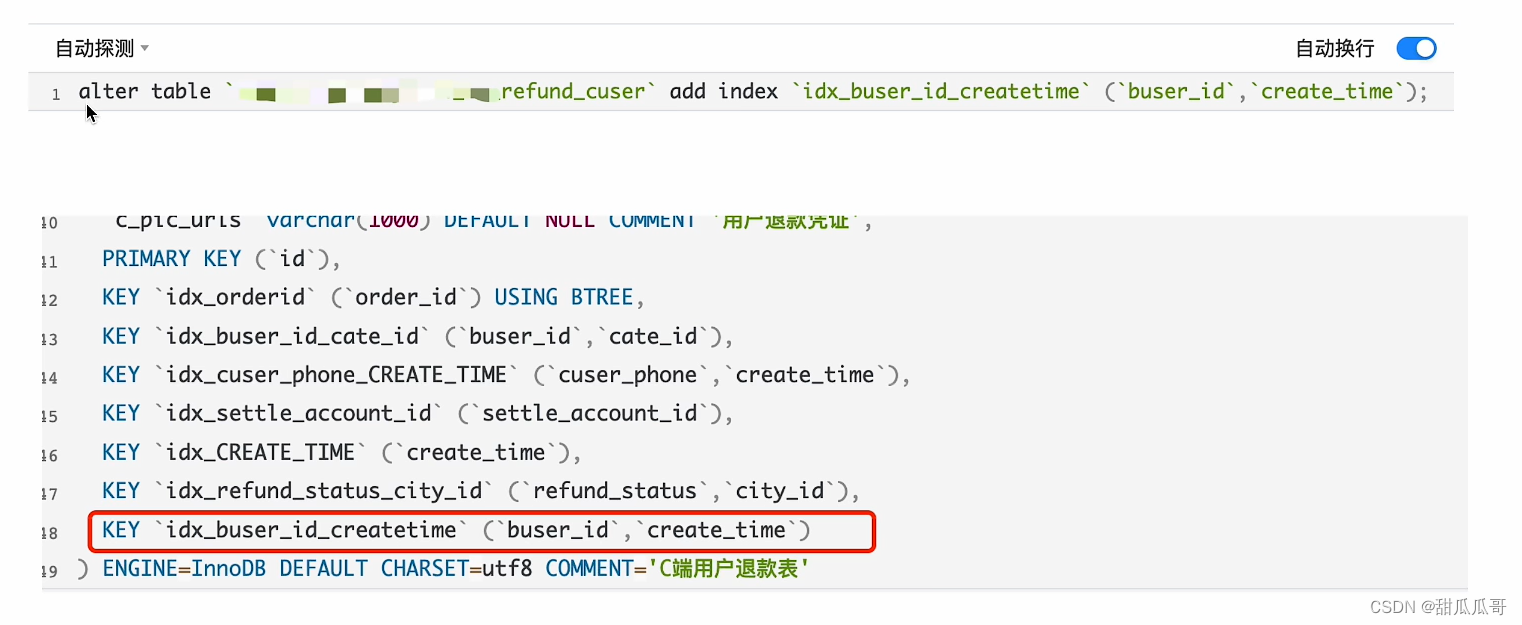
建索引
执行计划
现在我们possible_keys中,可能用到的索引是:idx_buser_id_cate_id和idx_buser_id_createtime
key, 实际用到的索引是:idx_buser_id_createtime
同时:extra中只剩下using where,已经把using filesort给去掉了。

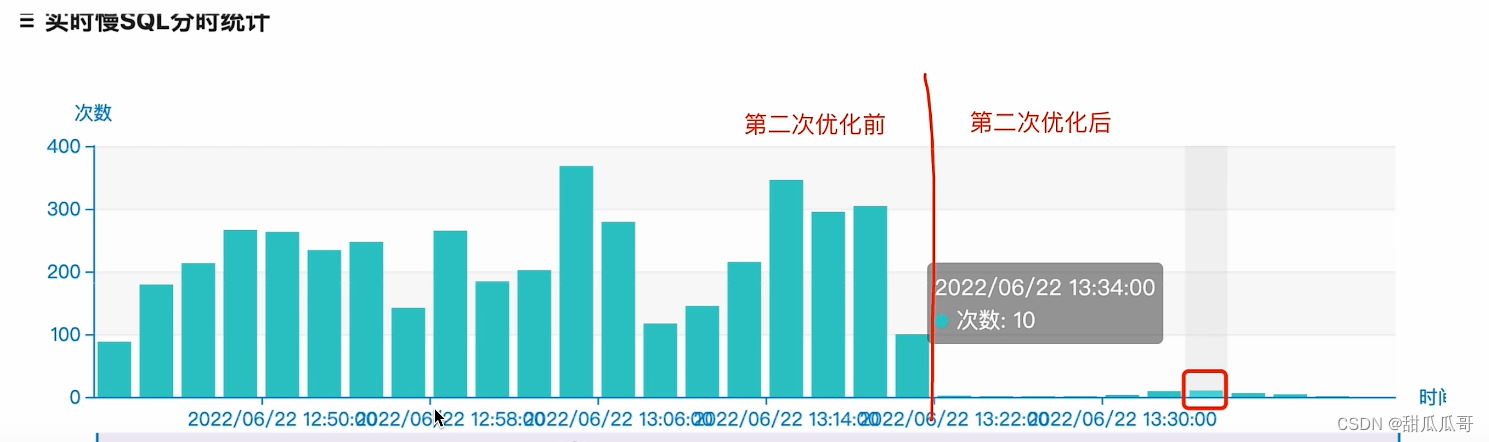
结果
这个时候,一分钟的次数,最高是10,最低的次数是1。
总结
场景1,慢SQL的原因是没命中索引,这个建索引就完事了。这个是从无到有。
场景2,慢SQL的原因是命中索引了,但是缺有Using filesort,这个是建的所以不好,因此需要新建索引,去掉using filesort即可。
看完这2个场景,你面试时,被面试官问到:是否有做过慢查询优化,这两个场景,你完全可以拿去用。因为上面的细节都有了。只要把细节说出来,那这个慢查询就是你做过的。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









