







一、哈希表概述
在Redis中,哈希表用的很多,首先是我们的数据库,数据库表采用的就是两张哈希表,用于扩容转化,然后我们的数据类型,像Hash和Set两种类型都有Hash的编码类型,然后接下来说说Hash表
二、哈希表结构
哈希表
typedef struct dictht {
// 哈希表数组
dictEntry **table;
// 哈希表大小
unsigned long size;
// 哈希表大小掩码,用于计算索引值
// 总是等于 size - 1
unsigned long sizemask;
// 该哈希表已有节点的数量
unsigned long used;
} dictht;
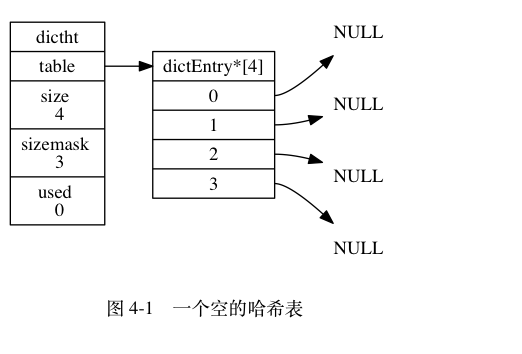
上面是我们的哈希表的总结构,我们可以看到他记录了一个size大小,指向哈希表的指针,已使用的数量。
然后来看看他的节点的类型
dictEntry
typedef struct dictEntry {
// 键
void *key;
// 值
union {
void *val;
uint64_t u64;
int64_t s64;
} v;
// 指向下个节点,形成链表
struct dictEntry *next;
} dictEntry;
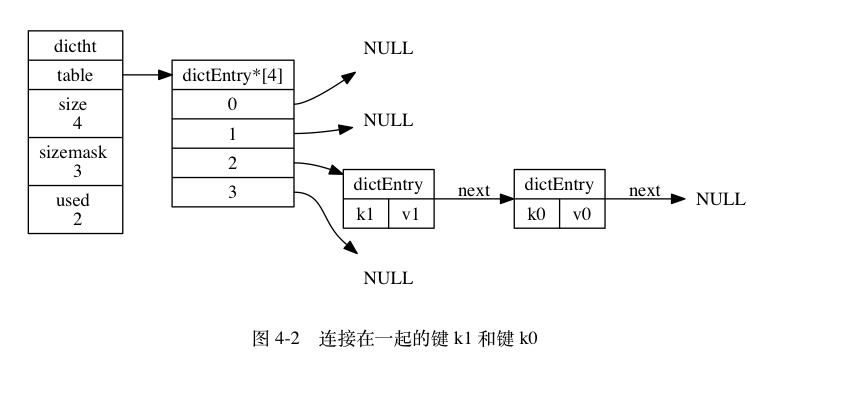
可以看到我们的节点中会包含下一个结点的指针,K的指针,以及Value的指针
来看看我们Redis中的字典
typedef struct dict {
// 类型特定函数
dictType *type;
// 私有数据
void *privdata;
// 哈希表两张
dictht ht[2];
// rehash 索引
// 当 rehash 不在进行时,值为 -1
int rehashidx; /* rehashing not in progress if rehashidx == -1 */
} dict;
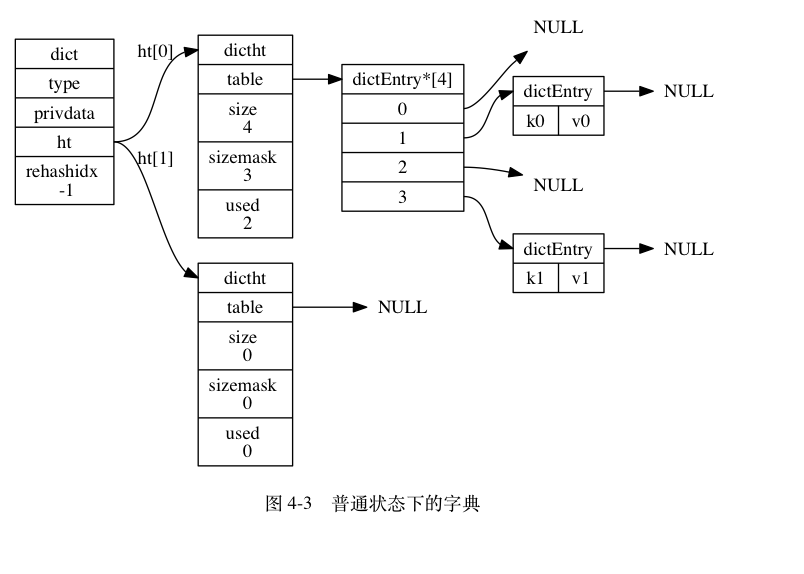
三、渐进式rehash
因为我们这边有size的字段来记录我们的哈希表的大小,当超过一定的阈值,就会进行扩容,但是如果阻塞所有操作,然后进行扩容,因为Redis是单线程的,此时不能对外响应,肯定会有很多问题,而且,我们的数据库也使用的哈希结构,如果进行扩容,当有很多数据的时候,肯定一时半会搞不定,所以Redis提出了渐进式Rehash来进行扩容,使用了两张表,然后不是一次性全部弄完的
下面介绍rehash的步骤
1、为h[1]分配空间,让我们的字典同时拥有ht[0]和ht[1]两张表
2、在字典中维护一个索引计数器变量rehashidx,初始值为0,表示rehash还没哟开始
3、在rehash运行期间,每次对字典执行添加,删除,查找,更新等操作的时候,程序除了响应这些操作外,还会顺带将ht[0]哈希表上rehashidx处索引的键值对放到ht[1],然后将这个rehashidx++
4、最终ht[0]所有键值对都会被放到ht[1],然后设置rehashidx为-1,表示操作已经完成
这边利用了一个懒的思想,不会一次性先把所有的数据转移,而是利用用户线程去完成一部分的操作,ConcurrentHashMap中也会依赖用户线程去进行我们的帮助扩容

















 354
354

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









