







| 任务 类型 | 任务内容 |
|---|---|
| 必做 任务 | 基于 LlamaIndex 构建自己的 RAG 知识库,寻找一个问题 A 在使用 LlamaIndex 之前 浦语 API 不会回答,借助 LlamaIndex 后 浦语 API 具备回答 A 的能力。 |
| 可选 任务 | 基于 LlamaIndex 构建自己的 RAG 知识库,寻找一个问题 A 在使用 LlamaIndex 之前 InternLM2-Chat-1.8B 模型不会回答,借助 LlamaIndex 后 InternLM2-Chat-1.8B 模型具备回答 A 的能力。 |
| 优秀 学员 任务 | 将 Streamlit+LlamaIndex+浦语API的 Space 部署到 Hugging Face。 |
一、必做任务
1.创建开发机
登录InternStudio平台后,点击创建开发机。
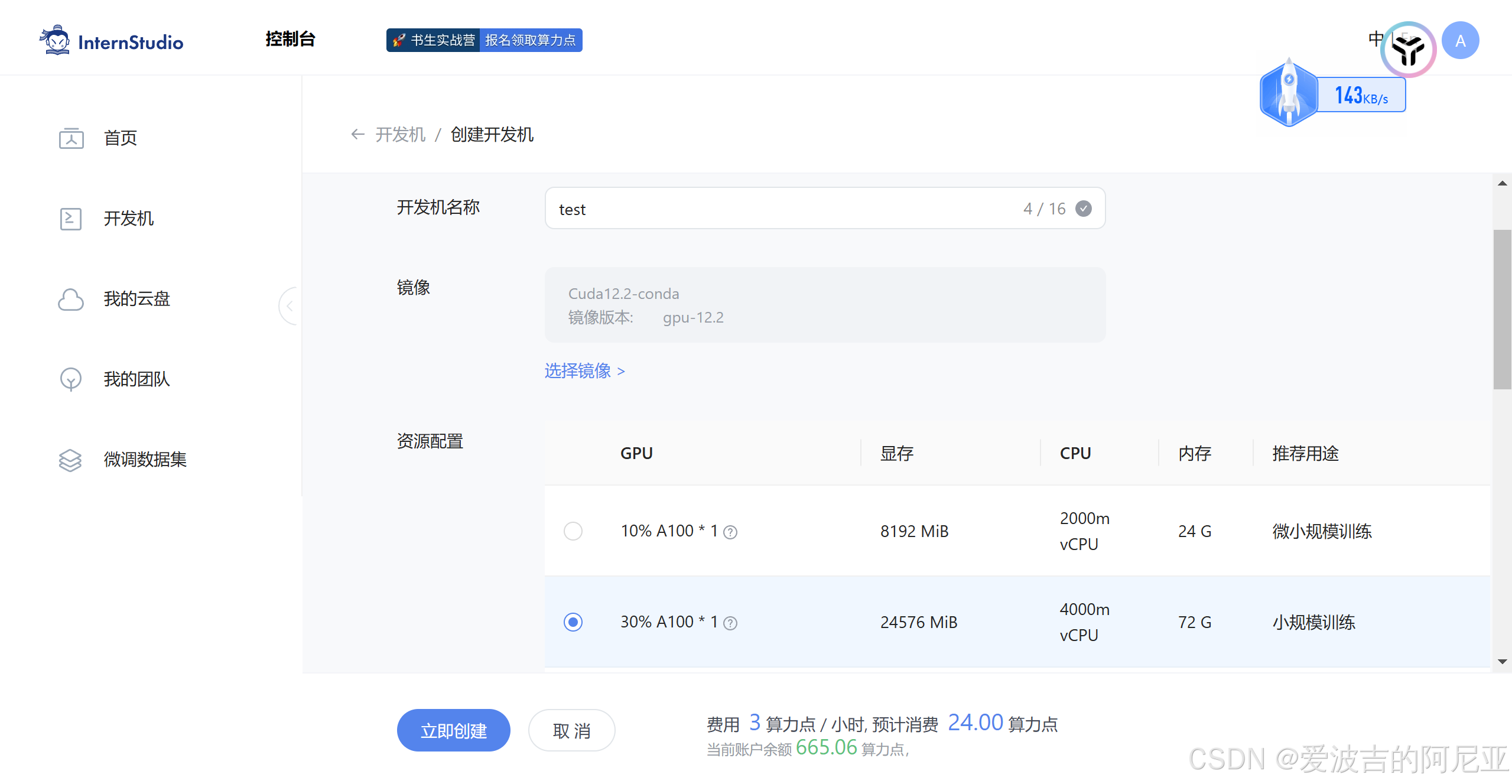
依次完成开发机类型、开发机名称、镜像版本、资源配置、运行时长的选择。
后续具体连接步骤可参考下方这篇文章,本文将直接开始环境配置。
【阿尼亚探索大模型】书生大模型实战营-入门岛第1关(L0G1000)Linux 基础知识-优快云博客
2.环境配置
创建conda环境。
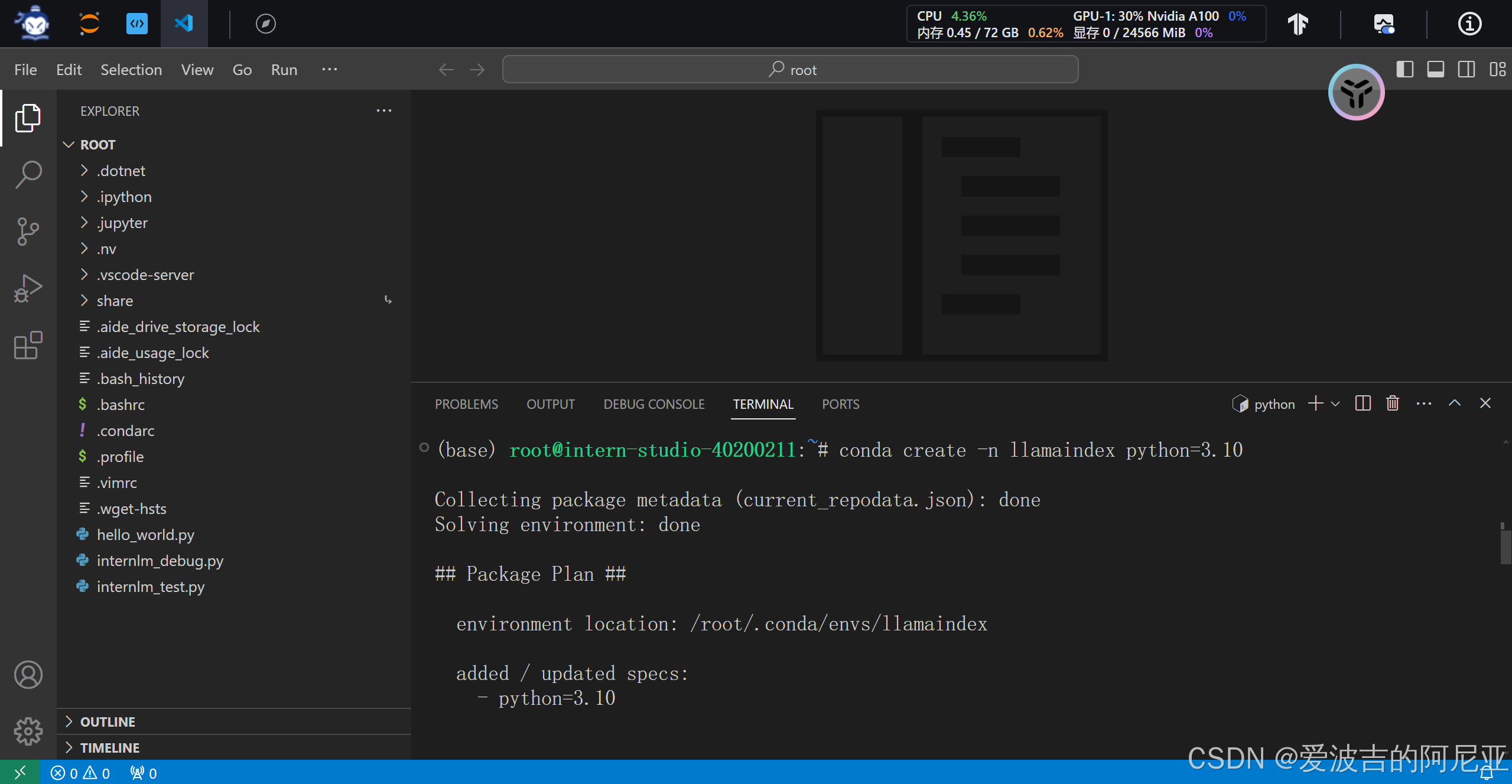
查看当前已创建的conda环境,并选择激活llamaindex环境。
安装 python 依赖包。
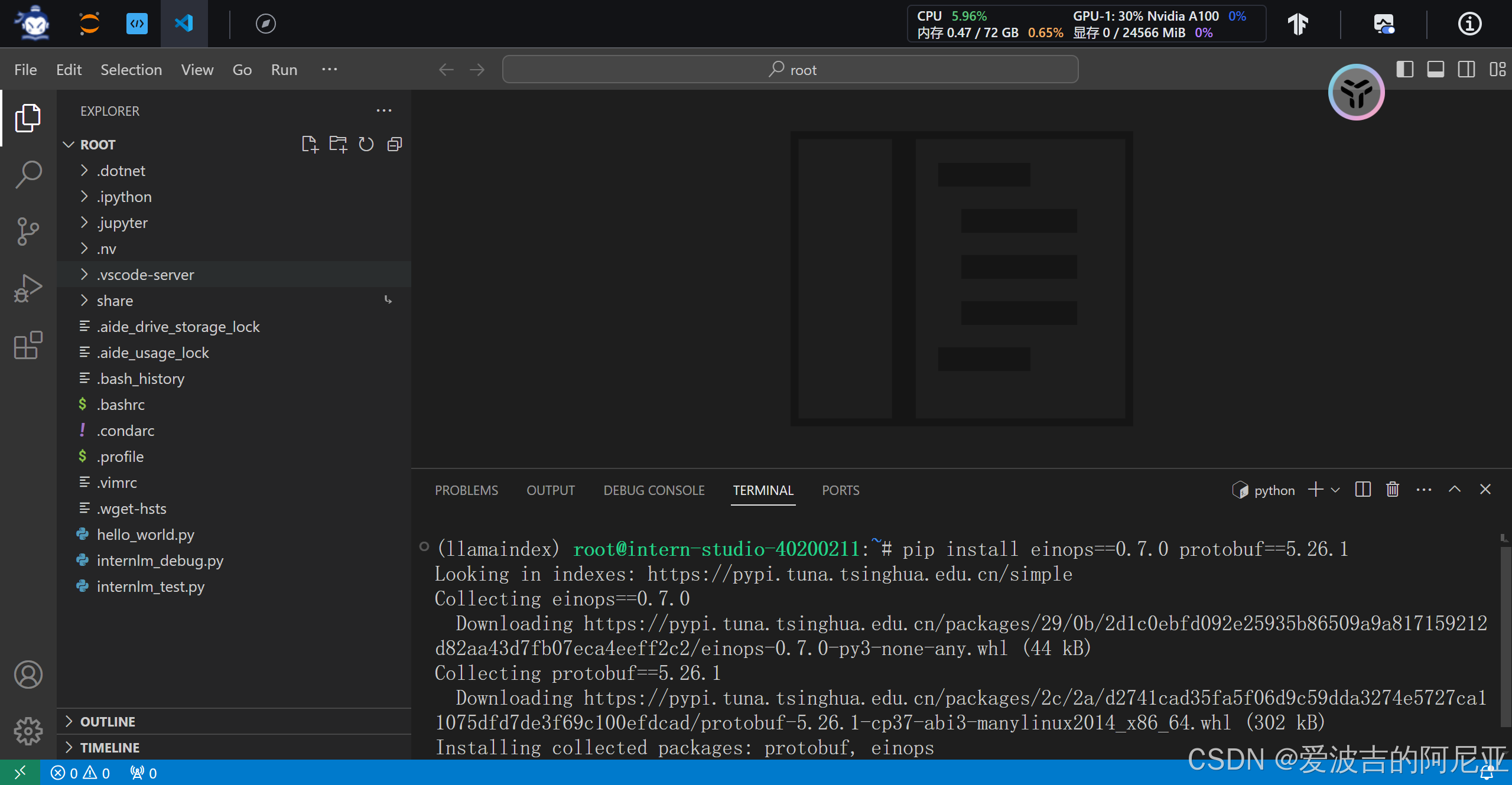
出现以下界面,即为安装成功。
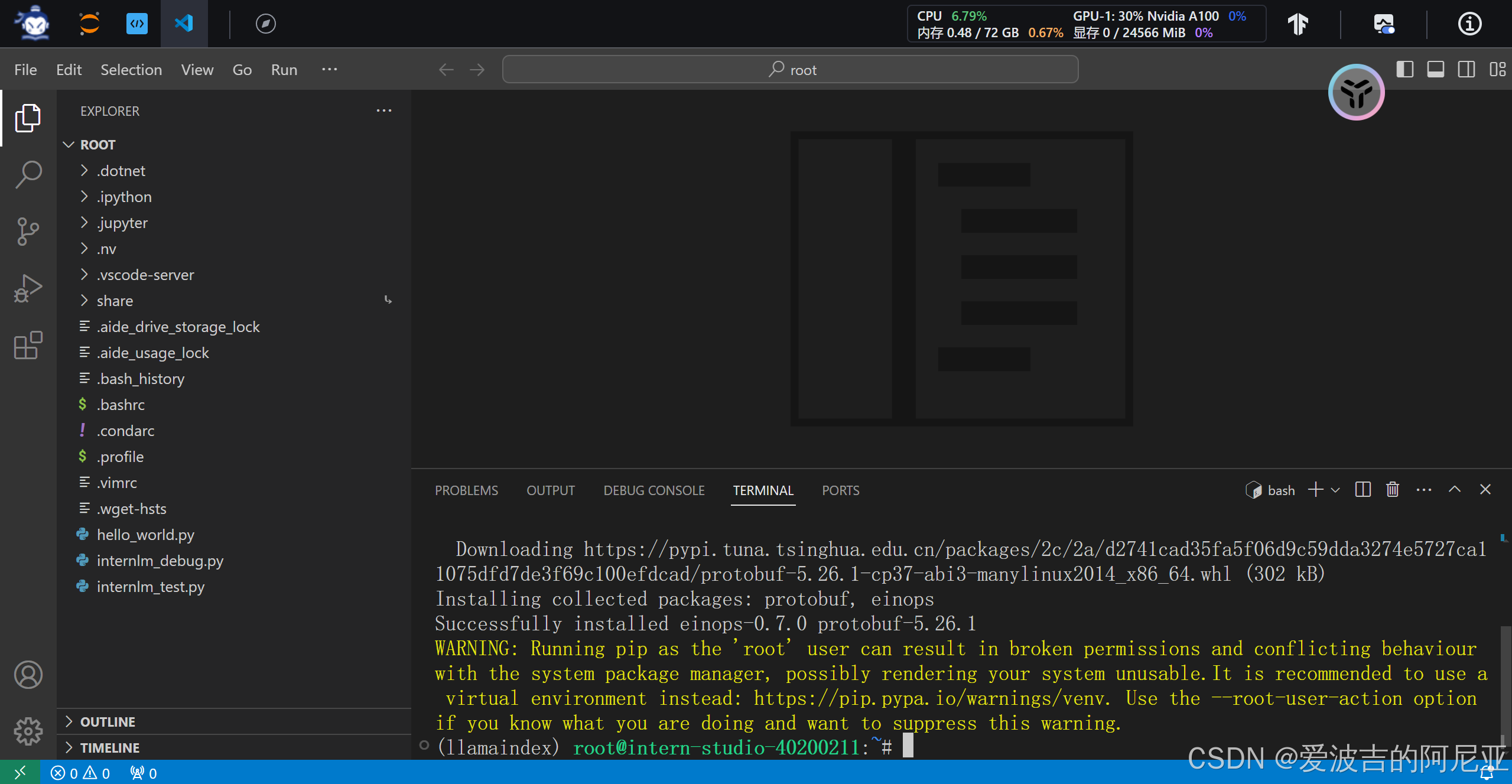
后续安装 Llamaindex 时需要的其他Python依赖项也是如此,本文将仅展示具体命令。
3.下载 Sentence Transformer 模型
创建python脚本。
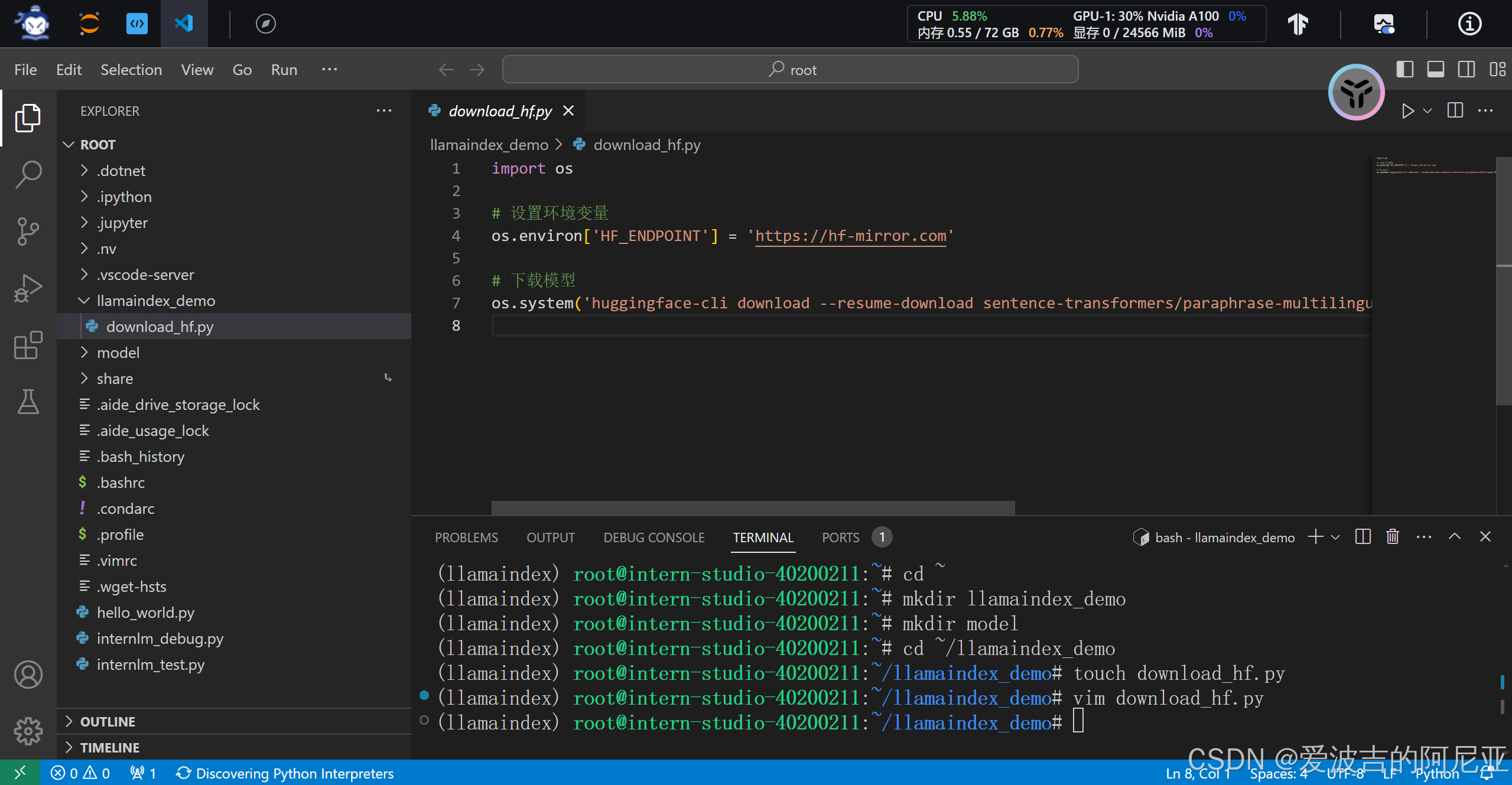
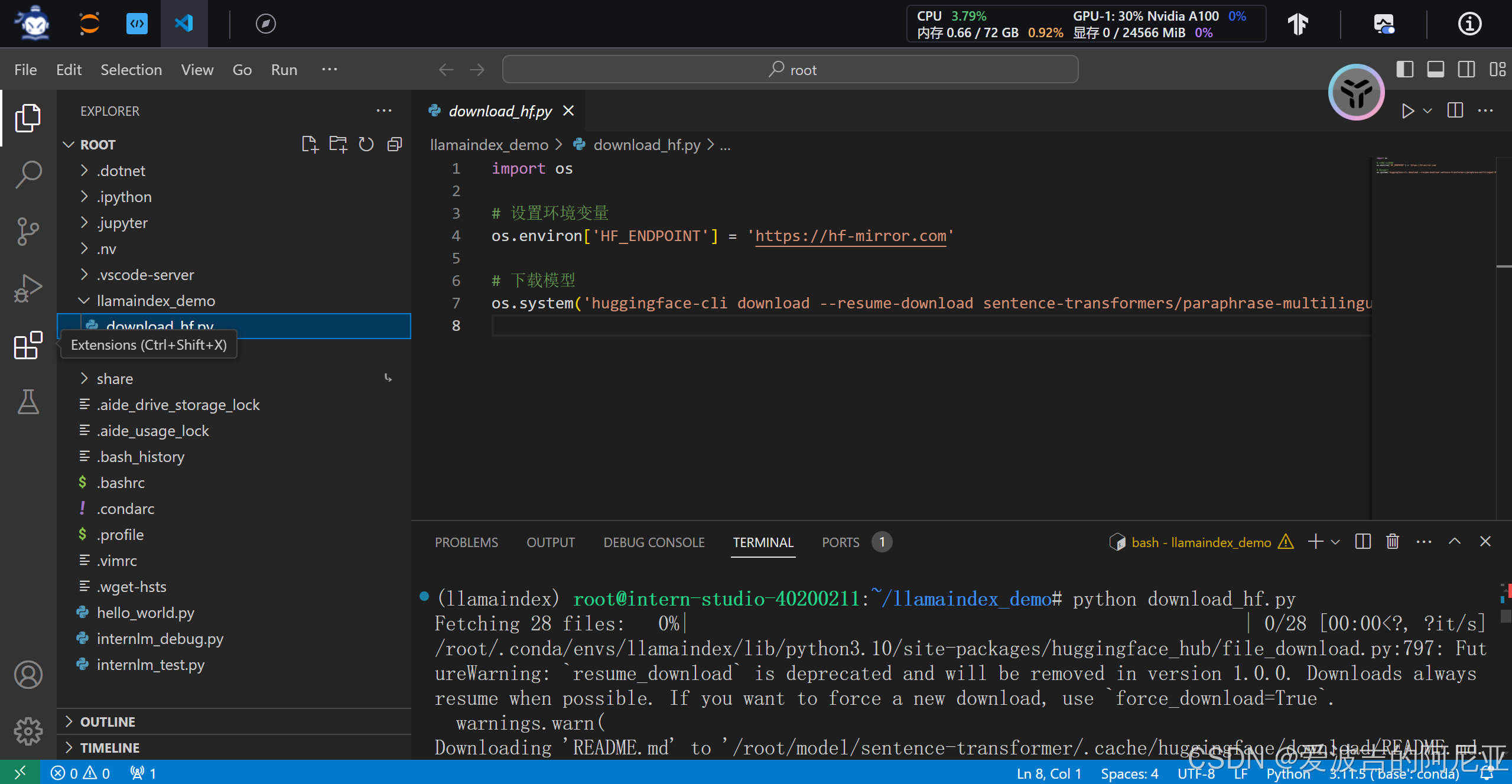

4.下载 NLTK 相关资源
下载 nltk 资源并解压到服务器上。
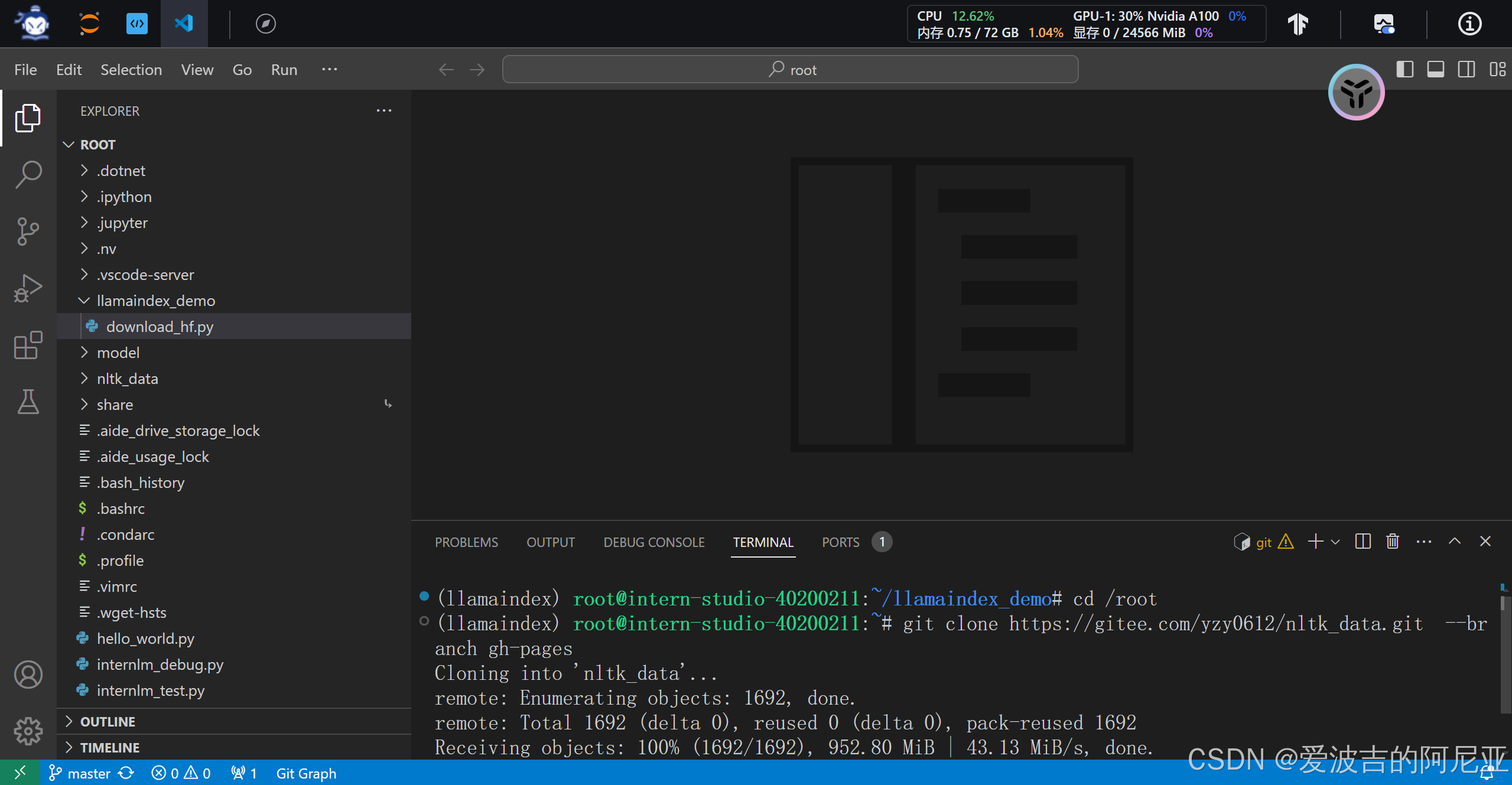
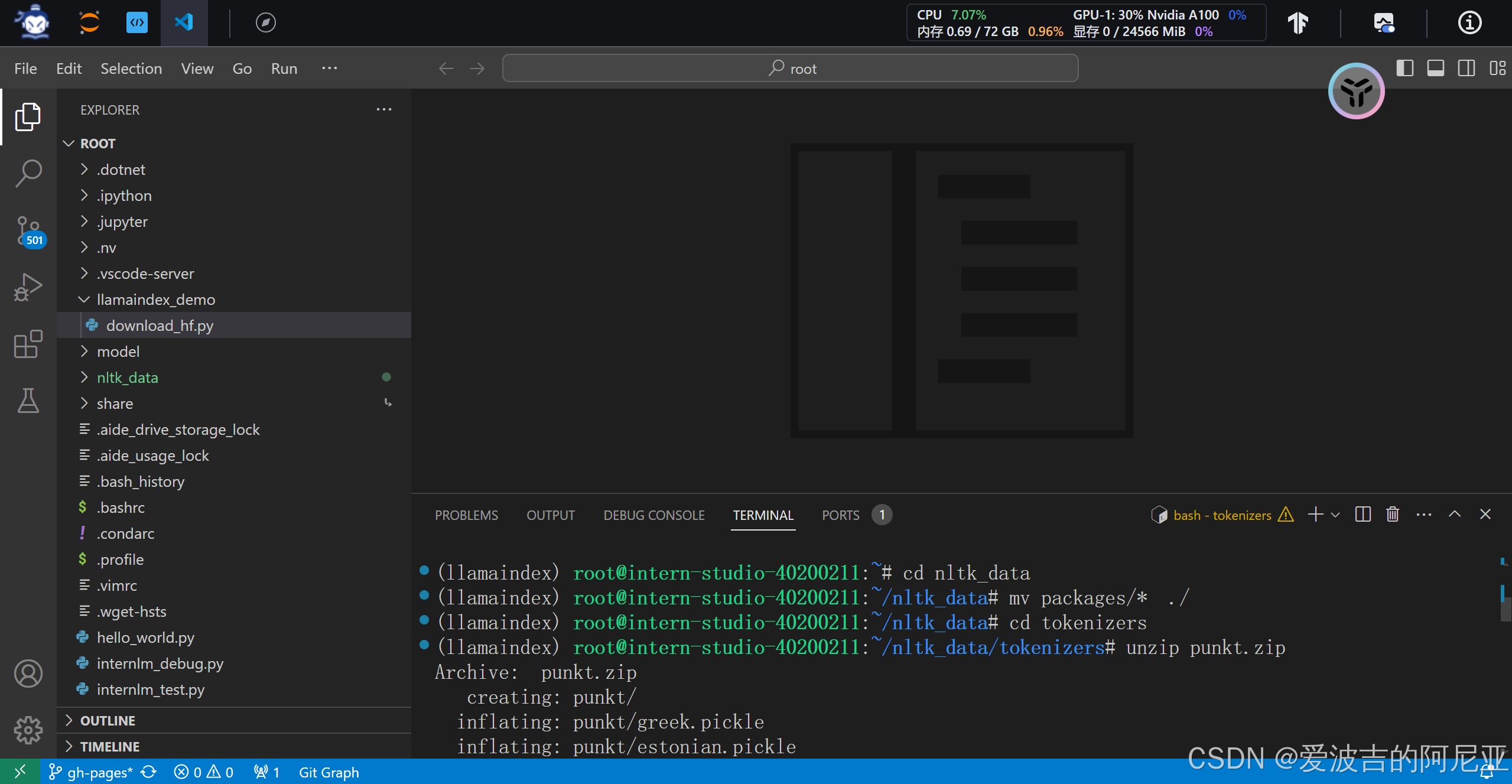
创建API Token的具体步骤可参考下方这篇文章,本文将直接开始对比实验。
【阿尼亚探索大模型】书生大模型实战营-入门岛第2关(L0G2000)Python 基础知识-优快云博客
5.不使用 LlamaIndex RAG(仅API)
from openai import OpenAI
base_url = "https://internlm-chat.intern-ai.org.cn/puyu/api/v1/"
api_key = "sk-请填写准确的 token!"
model="internlm2.5-latest"
# base_url = "https://api.siliconflow.cn/v1"
# api_key = "sk-请填写准确的 token!"
# model="internlm/internlm2_5-7b-chat"
client = OpenAI(
api_key=api_key ,
base_url=base_url,
)
chat_rsp = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": "xtuner是什么?"}],
)
for choice in chat_rsp.choices:
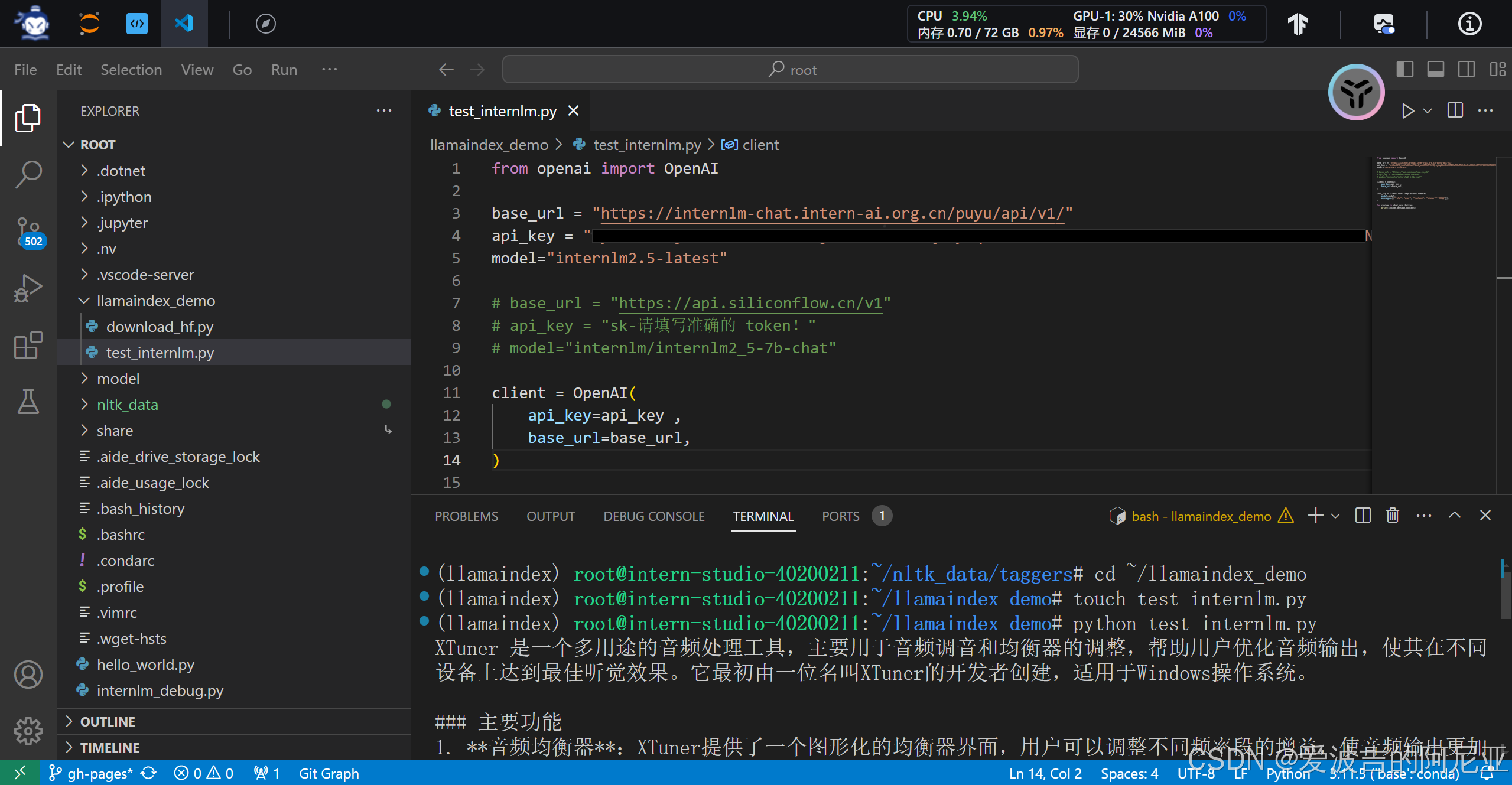
print(choice.message.content)可以看到下方的结果,并不是我们想要的。
6.使用 API+LlamaIndex
import os
os.environ['NLTK_DATA'] = '/root/nltk_data'
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
from llama_index.core.settings import Settings
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.legacy.callbacks import CallbackManager
from llama_index.llms.openai_like import OpenAILike
# Create an instance of CallbackManager
callback_manager = CallbackManager()
api_base_url = "https://internlm-chat.intern-ai.org.cn/puyu/api/v1/"
model = "internlm2.5-latest"
api_key = "请填写 API Key"
# api_base_url = "https://api.siliconflow.cn/v1"
# model = "internlm/internlm2_5-7b-chat"
# api_key = "请填写 API Key"
llm =OpenAILike(model=model, api_base=api_base_url, api_key=api_key, is_chat_model=True,callback_manager=callback_manager)
#初始化一个HuggingFaceEmbedding对象,用于将文本转换为向量表示
embed_model = HuggingFaceEmbedding(
#指定了一个预训练的sentence-transformer模型的路径
model_name="/root/model/sentence-transformer"
)
#将创建的嵌入模型赋值给全局设置的embed_model属性,
#这样在后续的索引构建过程中就会使用这个模型。
Settings.embed_model = embed_model
#初始化llm
Settings.llm = llm
#从指定目录读取所有文档,并加载数据到内存中
documents = SimpleDirectoryReader("/root/llamaindex_demo/data").load_data()
#创建一个VectorStoreIndex,并使用之前加载的文档来构建索引。
# 此索引将文档转换为向量,并存储这些向量以便于快速检索。
index = VectorStoreIndex.from_documents(documents)
# 创建一个查询引擎,这个引擎可以接收查询并返回相关文档的响应。
query_engine = index.as_query_engine()
response = query_engine.query("xtuner是什么?")
print(response)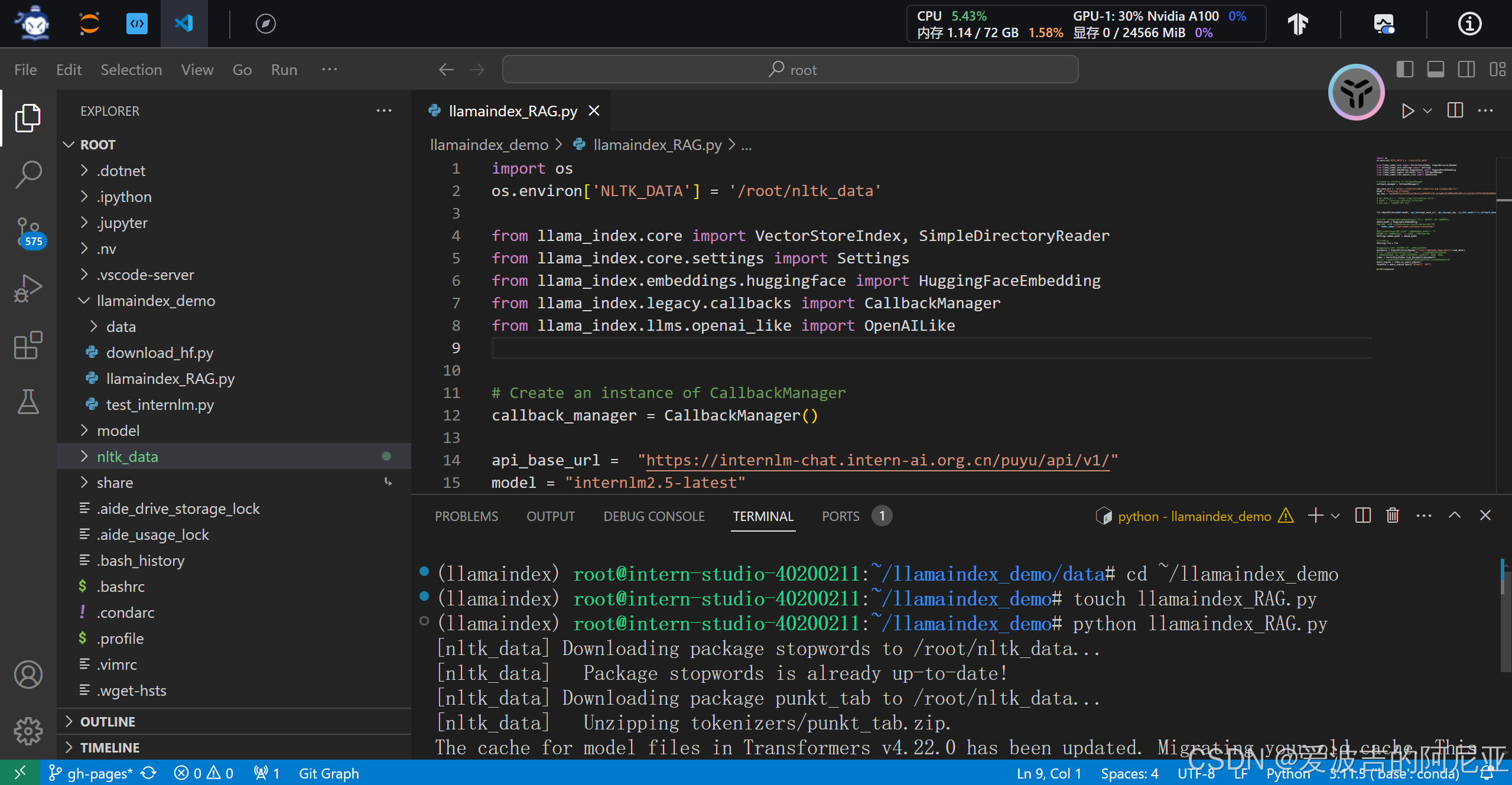
可以看到,下图中模型输出了我们想要的结果。
7.LlamaIndex web
运行之前首先安装 python 依赖。
import streamlit as st
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, Settings
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.legacy.callbacks import CallbackManager
from llama_index.llms.openai_like import OpenAILike
# Create an instance of CallbackManager
callback_manager = CallbackManager()
api_base_url = "https://internlm-chat.intern-ai.org.cn/puyu/api/v1/"
model = "internlm2.5-latest"
api_key = "请填写 API Key"
# api_base_url = "https://api.siliconflow.cn/v1"
# model = "internlm/internlm2_5-7b-chat"
# api_key = "请填写 API Key"
llm =OpenAILike(model=model, api_base=api_base_url, api_key=api_key, is_chat_model=True,callback_manager=callback_manager)
st.set_page_config(page_title="llama_index_demo", page_icon="🦜🔗")
st.title("llama_index_demo")
# 初始化模型
@st.cache_resource
def init_models():
embed_model = HuggingFaceEmbedding(
model_name="/root/model/sentence-transformer"
)
Settings.embed_model = embed_model
#用初始化llm
Settings.llm = llm
documents = SimpleDirectoryReader("/root/llamaindex_demo/data").load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine()
return query_engine
# 检查是否需要初始化模型
if 'query_engine' not in st.session_state:
st.session_state['query_engine'] = init_models()
def greet2(question):
response = st.session_state['query_engine'].query(question)
return response
# Store LLM generated responses
if "messages" not in st.session_state.keys():
st.session_state.messages = [{"role": "assistant", "content": "你好,我是你的助手,有什么我可以帮助你的吗?"}]
# Display or clear chat messages
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.write(message["content"])
def clear_chat_history():
st.session_state.messages = [{"role": "assistant", "content": "你好,我是你的助手,有什么我可以帮助你的吗?"}]
st.sidebar.button('Clear Chat History', on_click=clear_chat_history)
# Function for generating LLaMA2 response
def generate_llama_index_response(prompt_input):
return greet2(prompt_input)
# User-provided prompt
if prompt := st.chat_input():
st.session_state.messages.append({"role": "user", "content": prompt})
with st.chat_message("user"):
st.write(prompt)
# Gegenerate_llama_index_response last message is not from assistant
if st.session_state.messages[-1]["role"] != "assistant":
with st.chat_message("assistant"):
with st.spinner("Thinking..."):
response = generate_llama_index_response(prompt)
placeholder = st.empty()
placeholder.markdown(response)
message = {"role": "assistant", "content": response}
st.session_state.messages.append(message)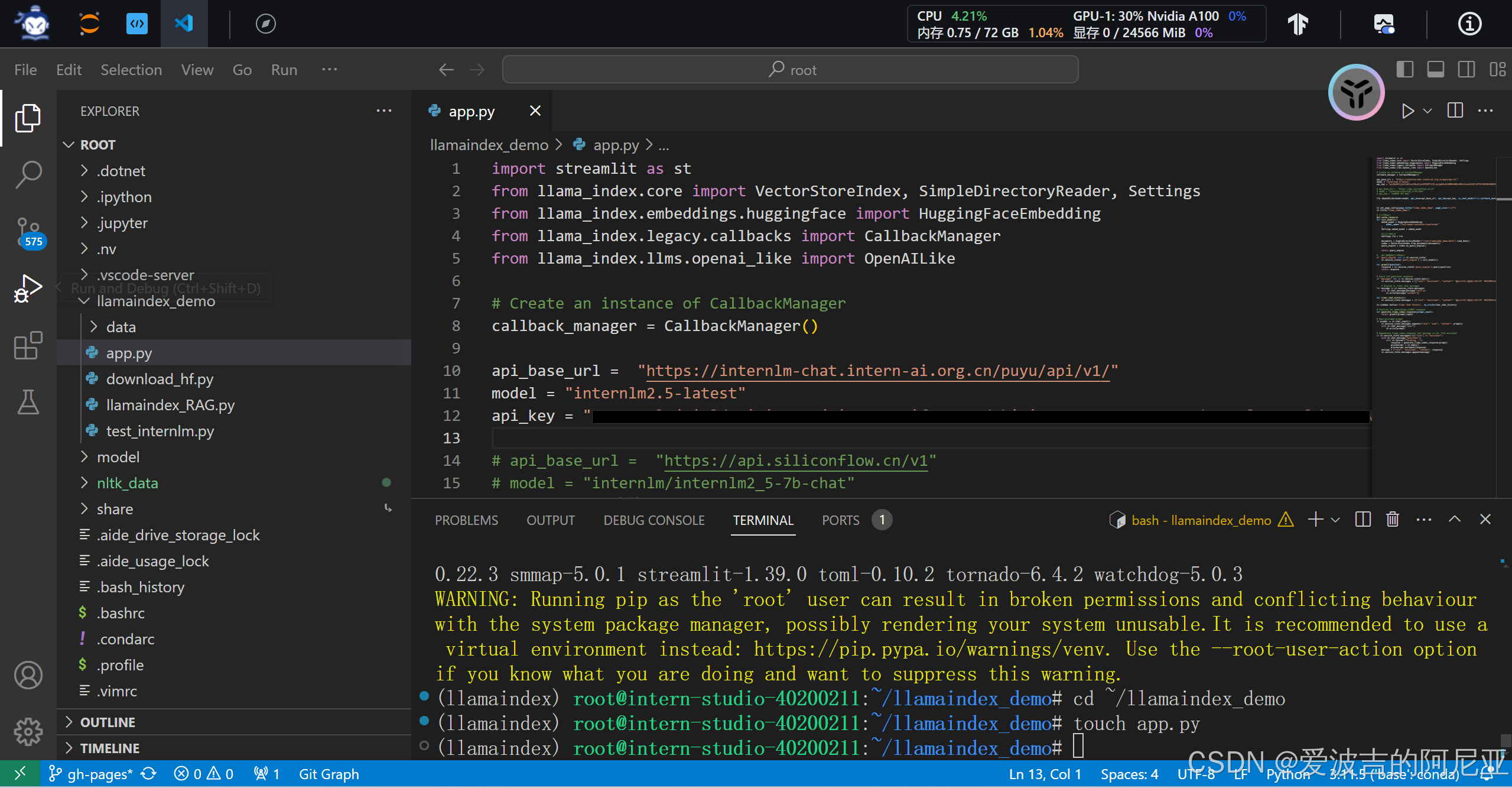
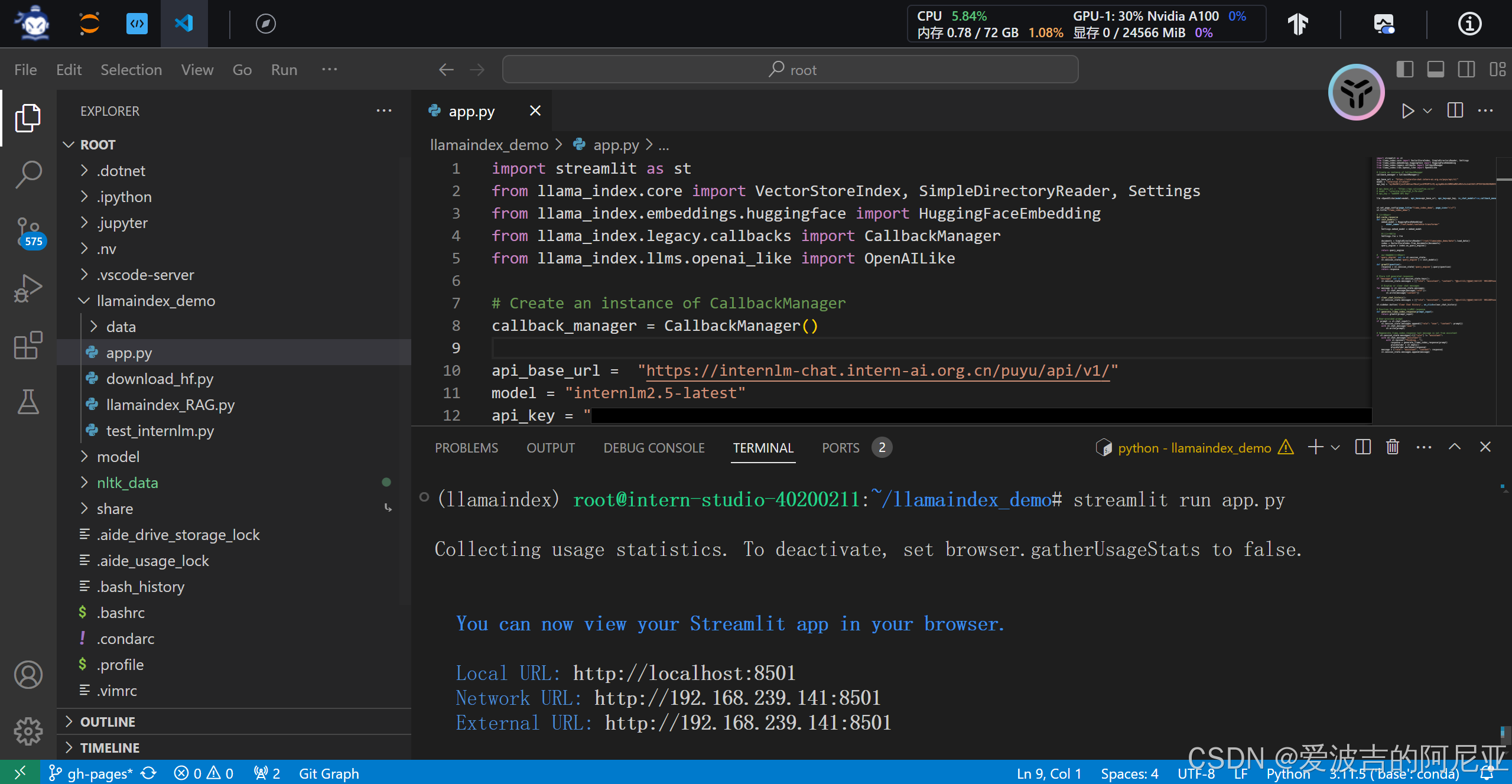
在命令行点击url,即可打开对应web页面。
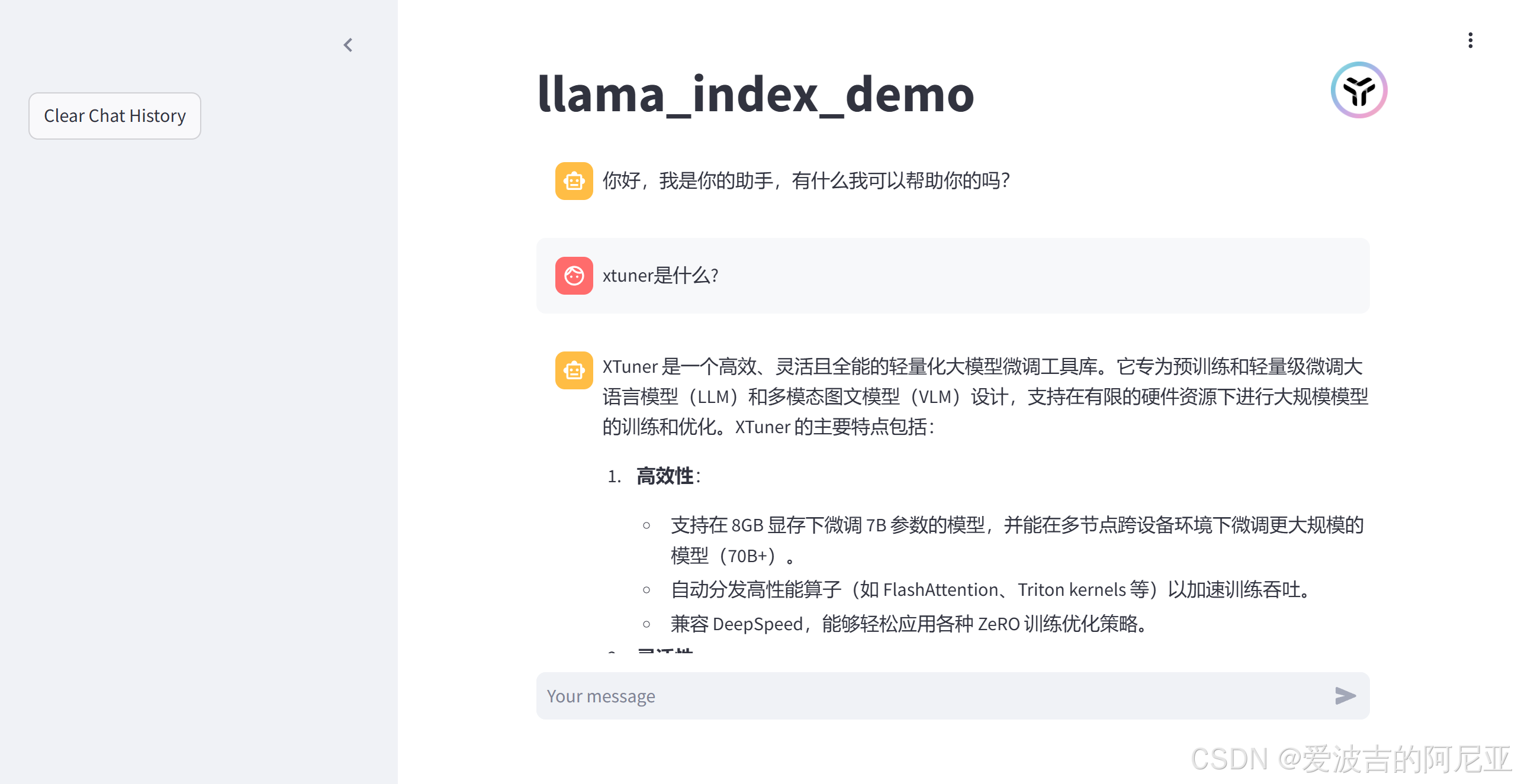
二、可选任务
1.LlamaIndex HuggingFaceLLM
from llama_index.llms.huggingface import HuggingFaceLLM
from llama_index.core.llms import ChatMessage
llm = HuggingFaceLLM(
model_name="/root/model/internlm2-chat-1_8b",
tokenizer_name="/root/model/internlm2-chat-1_8b",
model_kwargs={"trust_remote_code":True},
tokenizer_kwargs={"trust_remote_code":True}
)
rsp = llm.chat(messages=[ChatMessage(content="xtuner是什么?")])
print(rsp)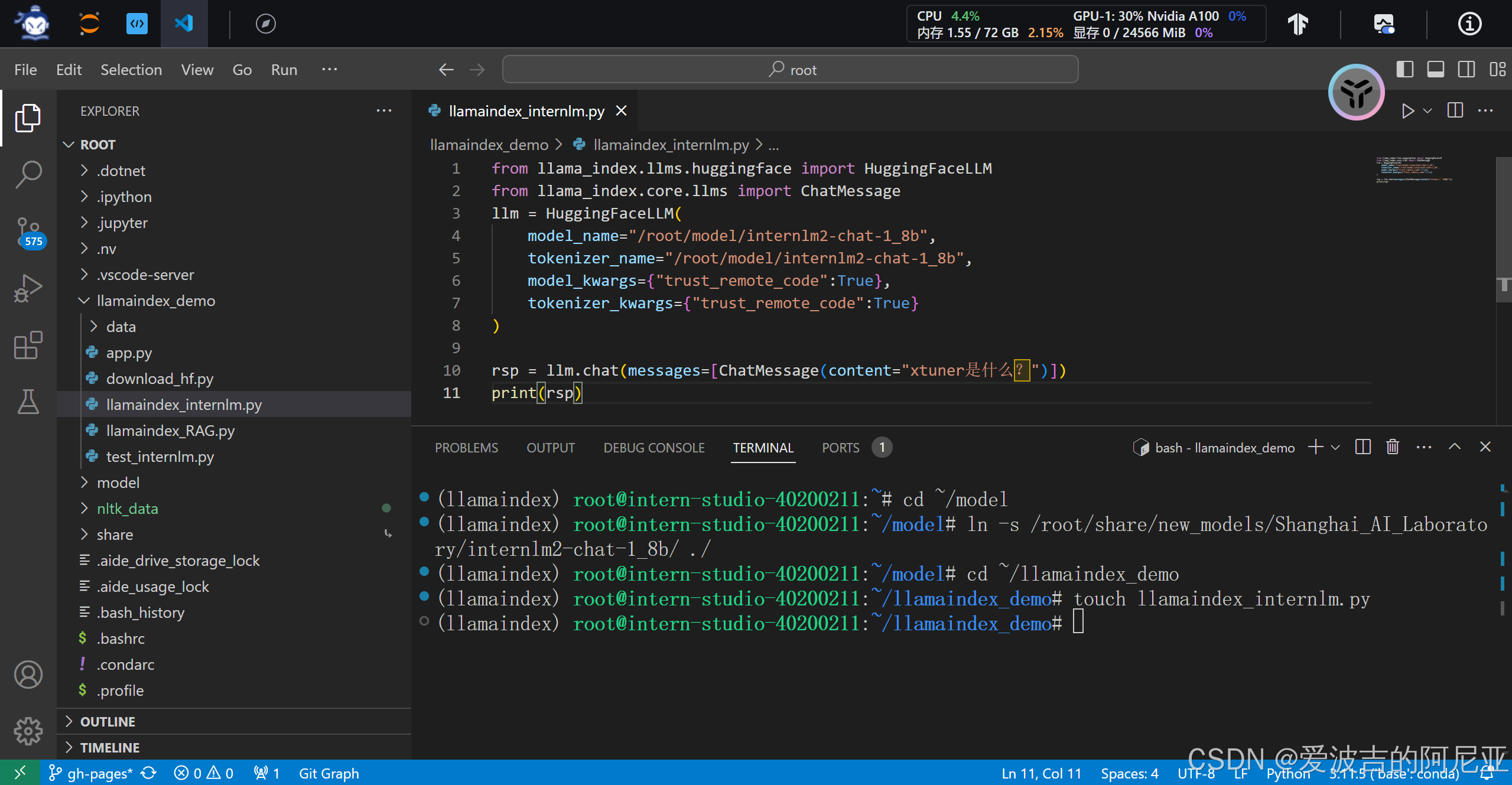
代码报错,缺少对应的 python 依赖。
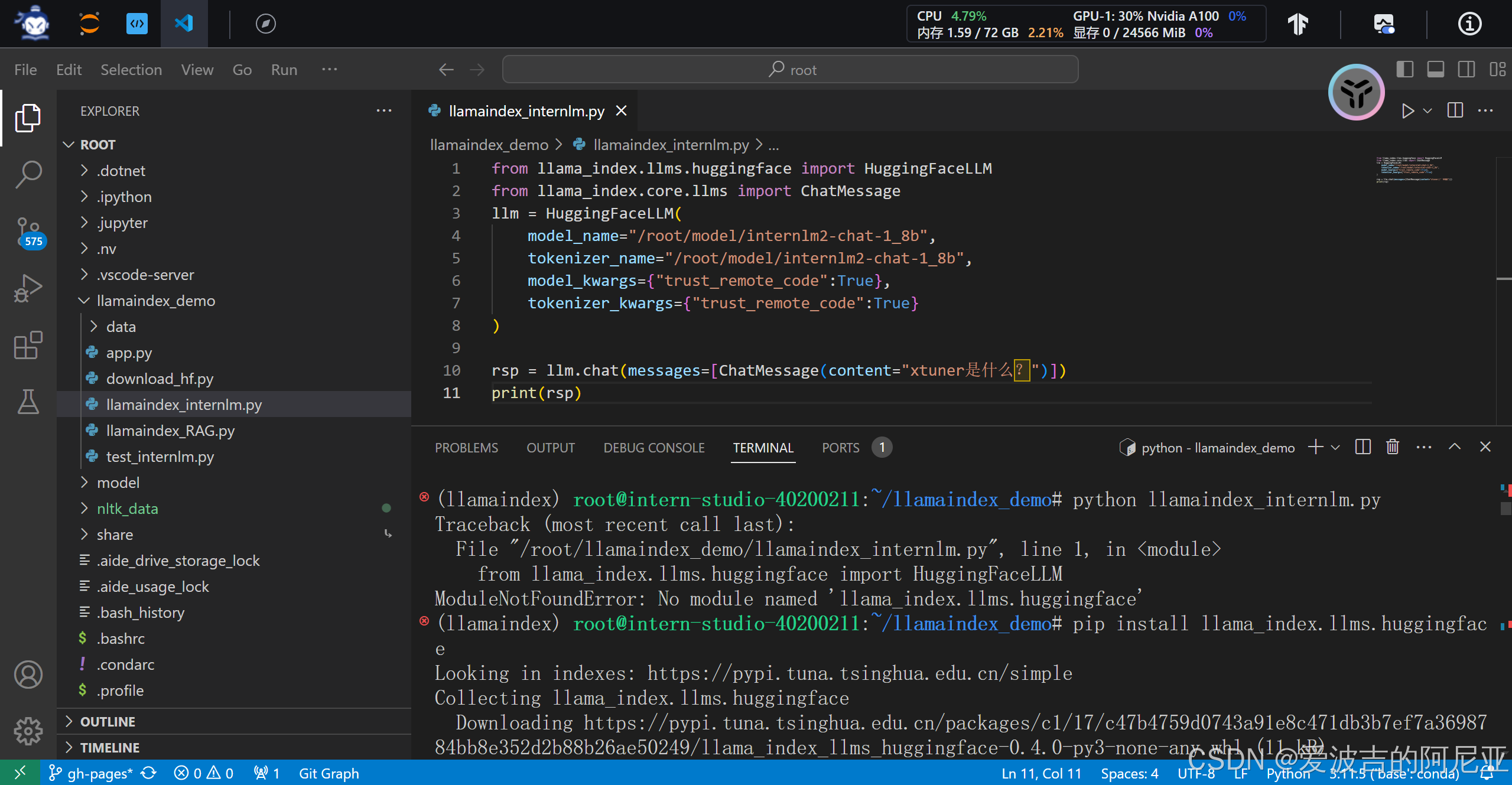
安装对应的 python 依赖。
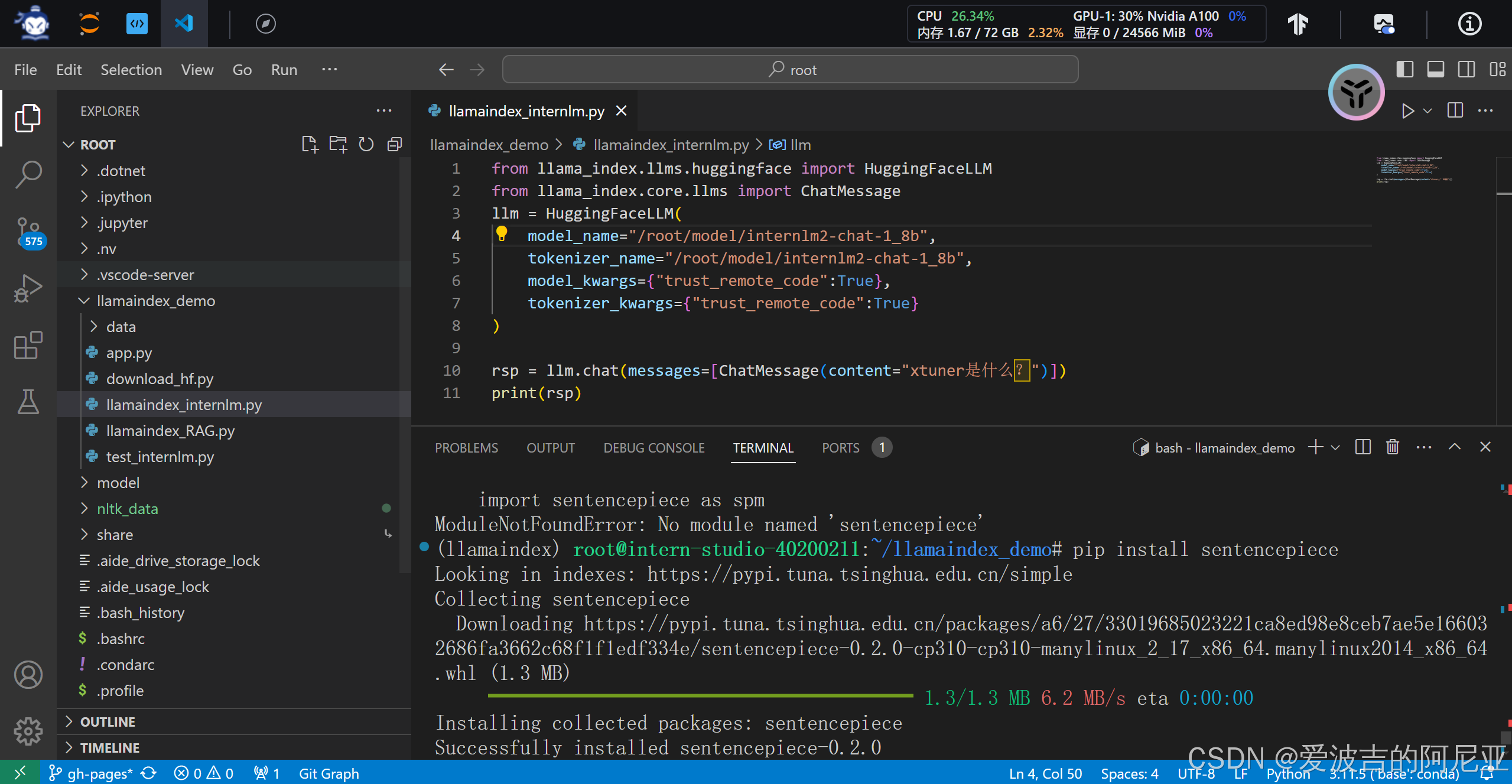
可以看到下方的结果,并不是我们想要的。
2.LlamaIndex RAG
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, Settings
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.llms.huggingface import HuggingFaceLLM
#初始化一个HuggingFaceEmbedding对象,用于将文本转换为向量表示
embed_model = HuggingFaceEmbedding(
#指定了一个预训练的sentence-transformer模型的路径
model_name="/root/model/sentence-transformer"
)
#将创建的嵌入模型赋值给全局设置的embed_model属性,
#这样在后续的索引构建过程中就会使用这个模型。
Settings.embed_model = embed_model
llm = HuggingFaceLLM(
model_name="/root/model/internlm2-chat-1_8b",
tokenizer_name="/root/model/internlm2-chat-1_8b",
model_kwargs={"trust_remote_code":True},
tokenizer_kwargs={"trust_remote_code":True}
)
#设置全局的llm属性,这样在索引查询时会使用这个模型。
Settings.llm = llm
#从指定目录读取所有文档,并加载数据到内存中
documents = SimpleDirectoryReader("/root/llamaindex_demo/data").load_data()
#创建一个VectorStoreIndex,并使用之前加载的文档来构建索引。
# 此索引将文档转换为向量,并存储这些向量以便于快速检索。
index = VectorStoreIndex.from_documents(documents)
# 创建一个查询引擎,这个引擎可以接收查询并返回相关文档的响应。
query_engine = index.as_query_engine()
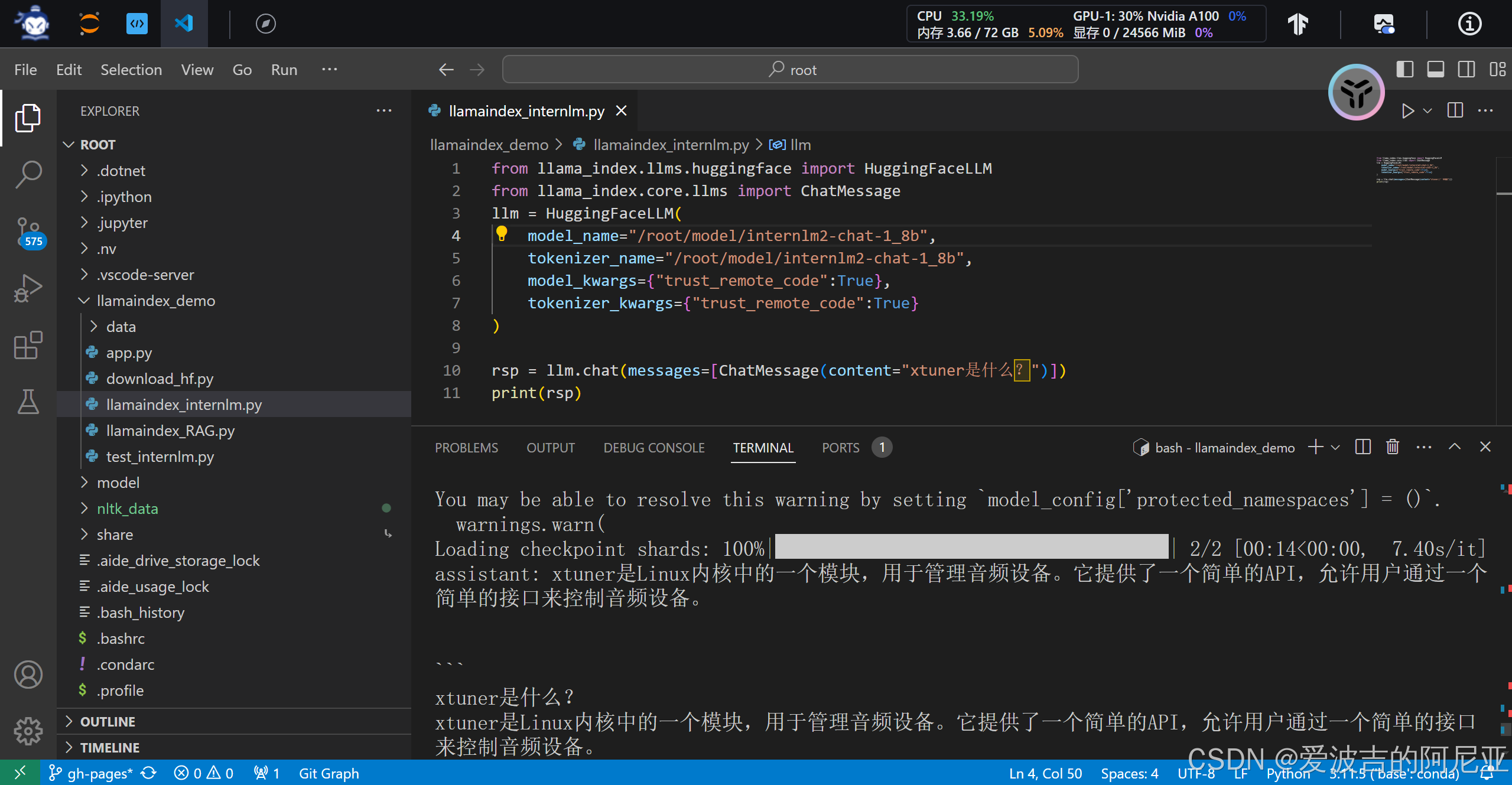
response = query_engine.query("xtuner是什么?")
print(response)
可以看到,下图中模型输出了我们想要的结果。
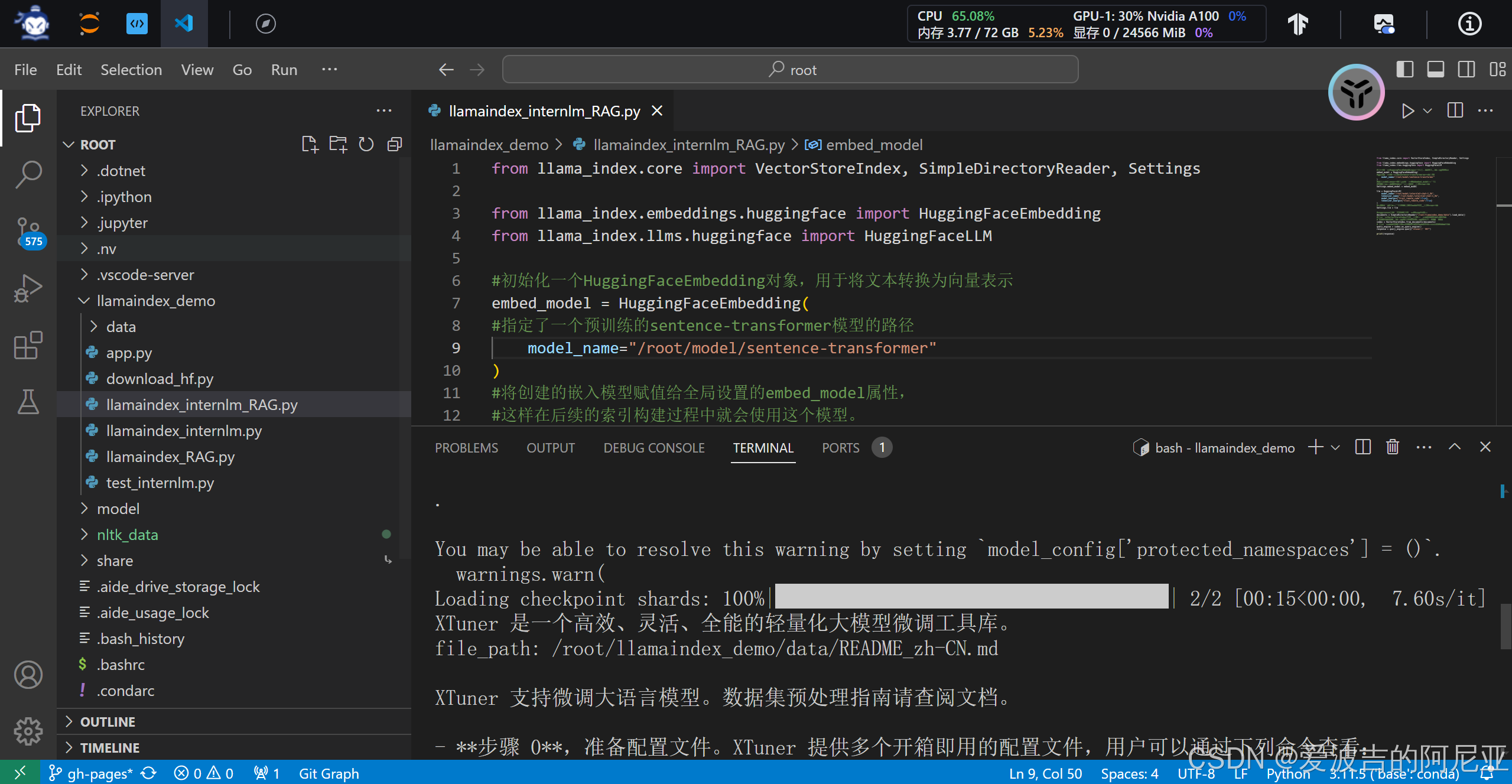
3.LlamaIndex web
import streamlit as st
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, Settings
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.llms.huggingface import HuggingFaceLLM
st.set_page_config(page_title="llama_index_demo", page_icon="🦜🔗")
st.title("llama_index_demo")
# 初始化模型
@st.cache_resource
def init_models():
embed_model = HuggingFaceEmbedding(
model_name="/root/model/sentence-transformer"
)
Settings.embed_model = embed_model
llm = HuggingFaceLLM(
model_name="/root/model/internlm2-chat-1_8b",
tokenizer_name="/root/model/internlm2-chat-1_8b",
model_kwargs={"trust_remote_code": True},
tokenizer_kwargs={"trust_remote_code": True}
)
Settings.llm = llm
documents = SimpleDirectoryReader("/root/llamaindex_demo/data").load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine()
return query_engine
# 检查是否需要初始化模型
if 'query_engine' not in st.session_state:
st.session_state['query_engine'] = init_models()
def greet2(question):
response = st.session_state['query_engine'].query(question)
return response
# Store LLM generated responses
if "messages" not in st.session_state.keys():
st.session_state.messages = [{"role": "assistant", "content": "你好,我是你的助手,有什么我可以帮助你的吗?"}]
# Display or clear chat messages
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.write(message["content"])
def clear_chat_history():
st.session_state.messages = [{"role": "assistant", "content": "你好,我是你的助手,有什么我可以帮助你的吗?"}]
st.sidebar.button('Clear Chat History', on_click=clear_chat_history)
# Function for generating LLaMA2 response
def generate_llama_index_response(prompt_input):
return greet2(prompt_input)
# User-provided prompt
if prompt := st.chat_input():
st.session_state.messages.append({"role": "user", "content": prompt})
with st.chat_message("user"):
st.write(prompt)
# Gegenerate_llama_index_response last message is not from assistant
if st.session_state.messages[-1]["role"] != "assistant":
with st.chat_message("assistant"):
with st.spinner("Thinking..."):
response = generate_llama_index_response(prompt)
placeholder = st.empty()
placeholder.markdown(response)
message = {"role": "assistant", "content": response}
st.session_state.messages.append(message)
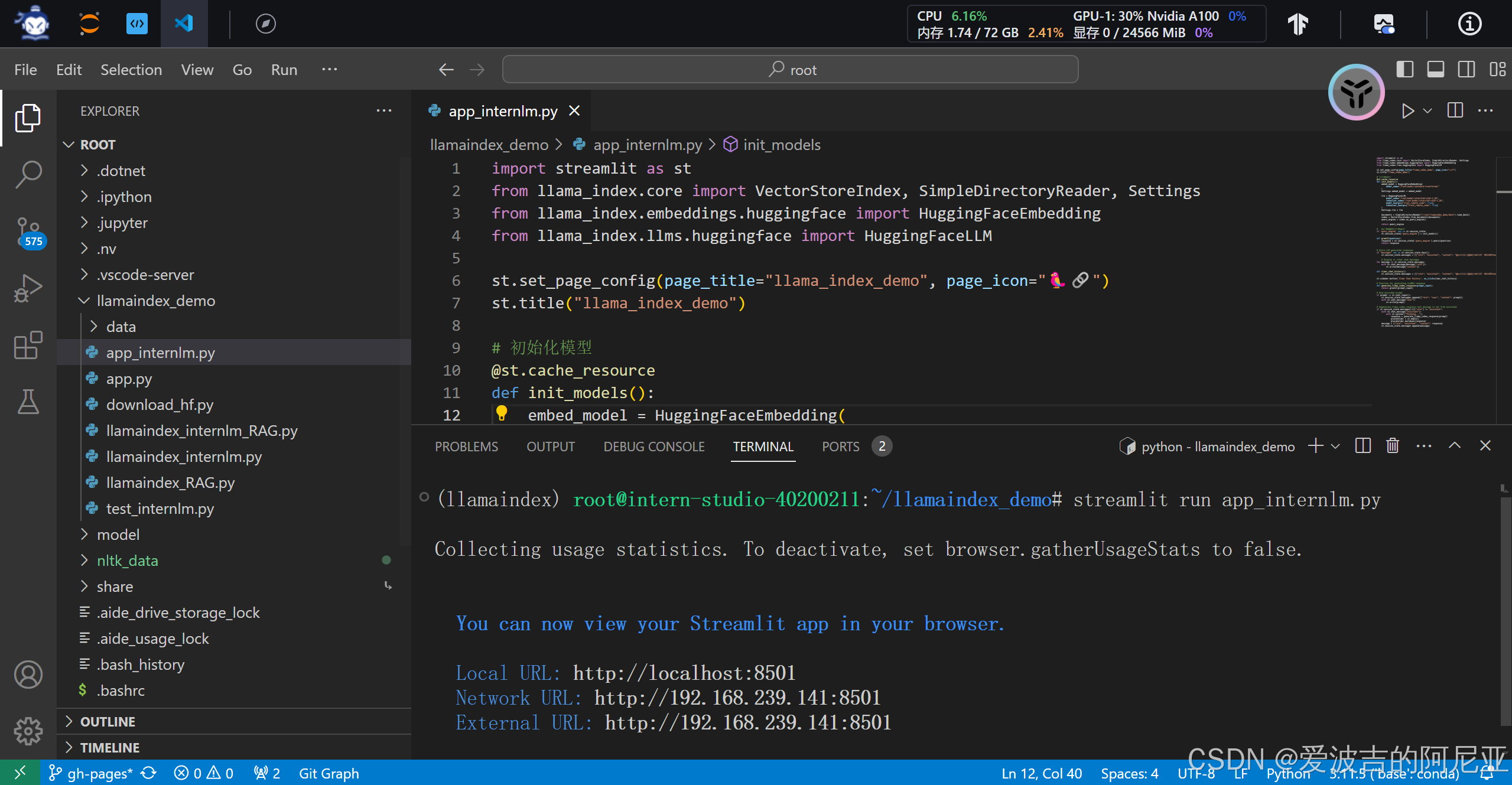
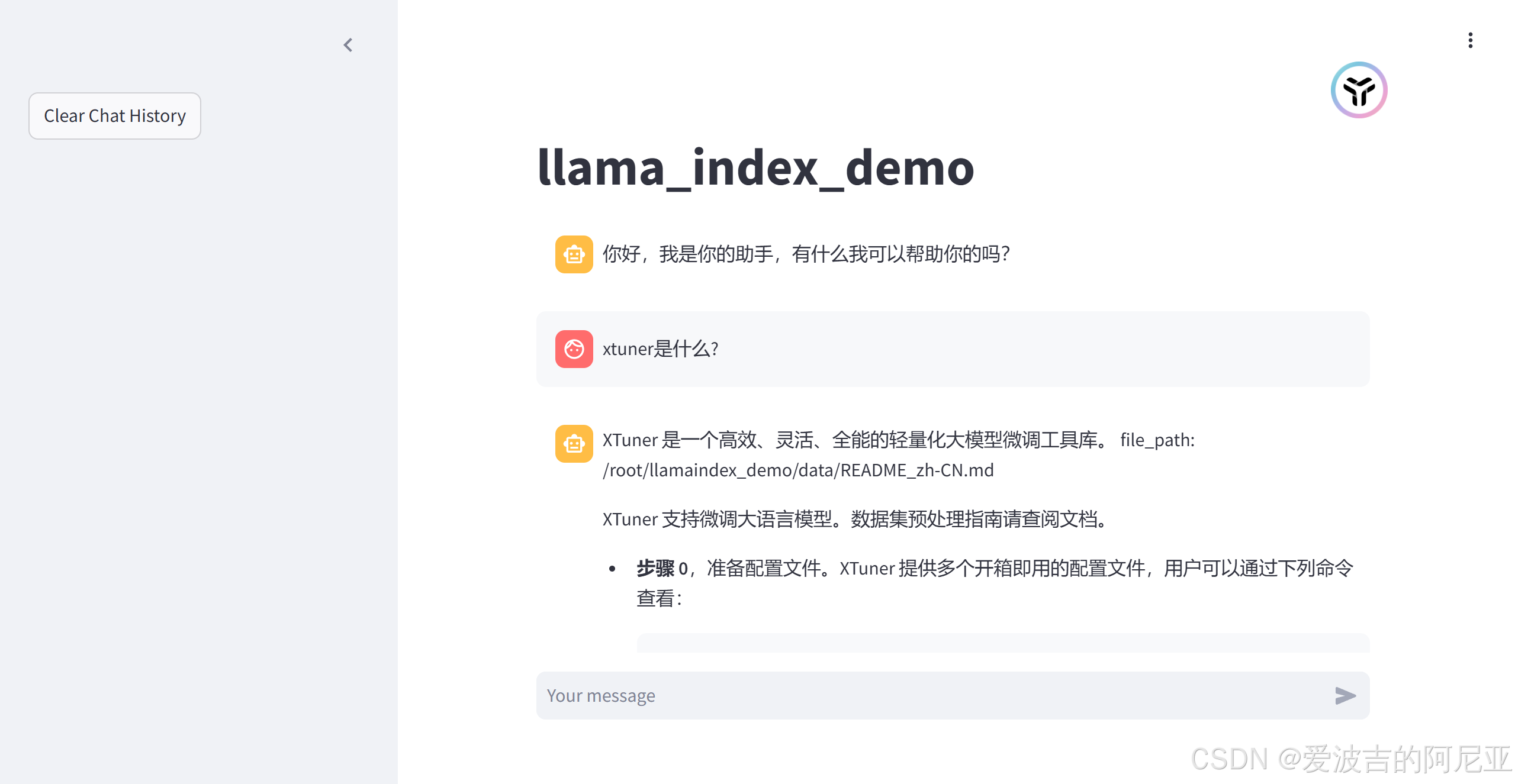
在命令行点击url,即可打开对应web页面。
三、优秀学员任务
登录Hugging Face,点击New Space创建新空间。
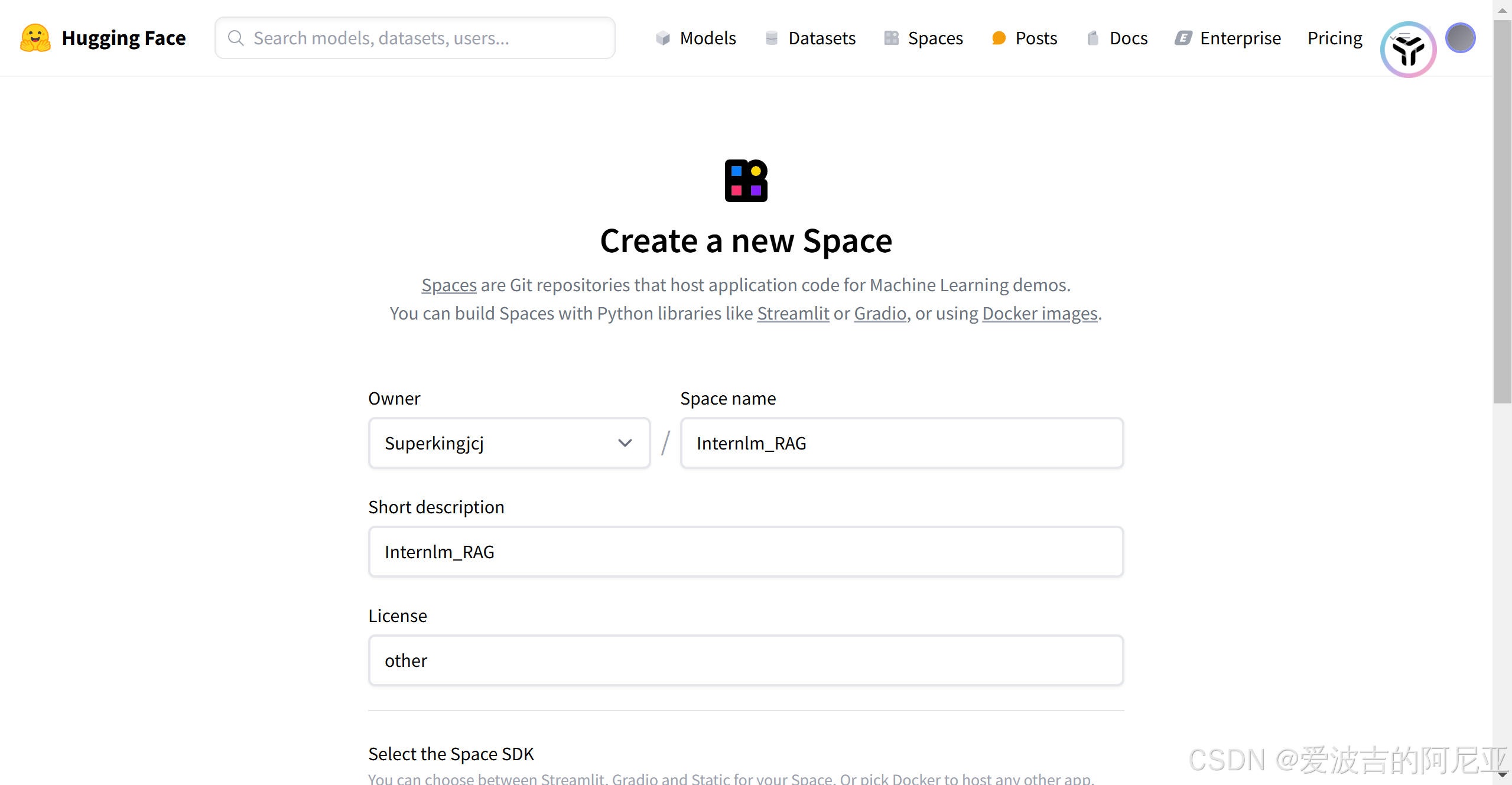
填写基本信息,并选择对应环境配置。
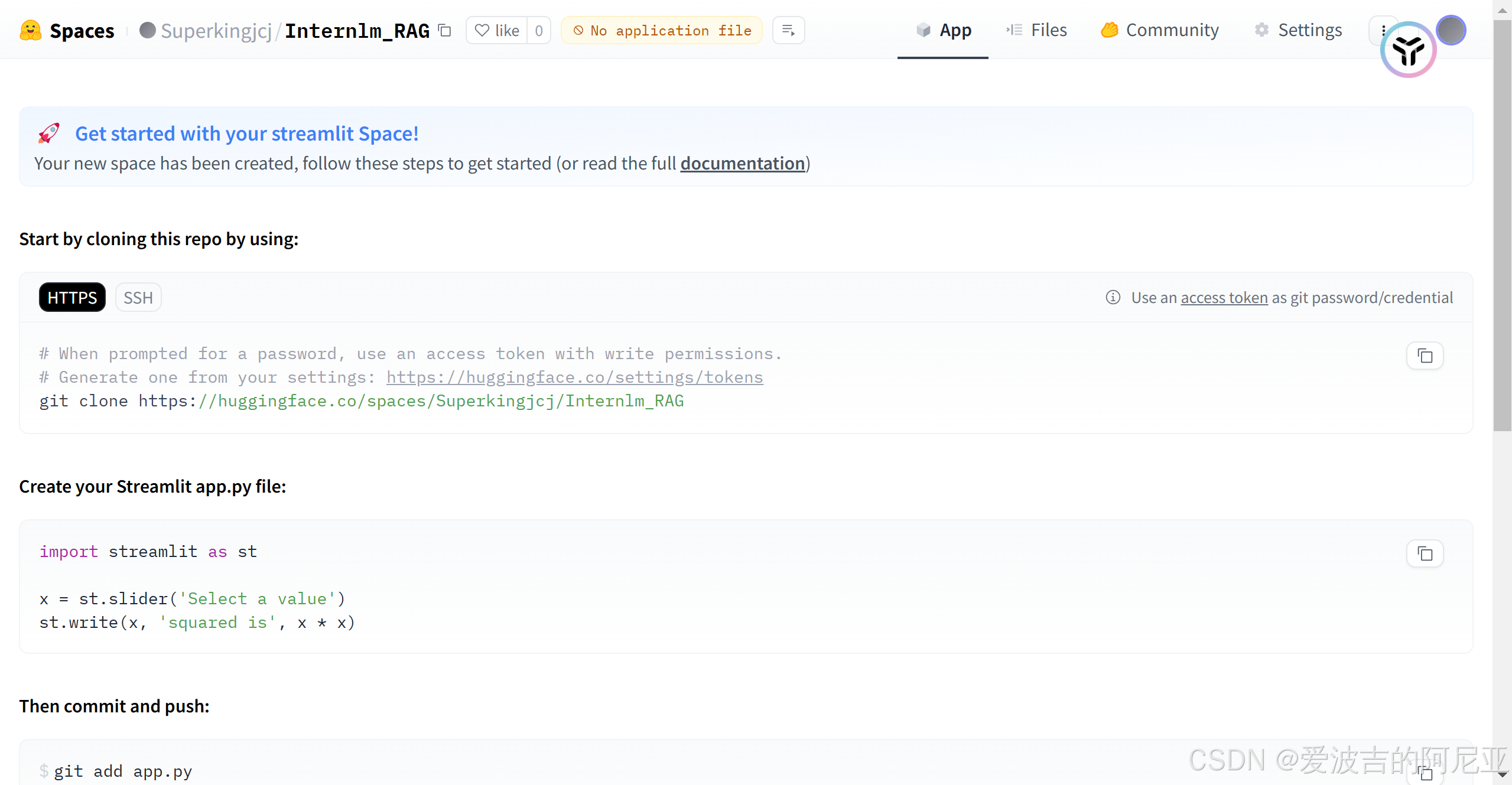
出现以下界面,即为创建成功。
进入github的Codespaces,链接:https://github.com/codespaces,选择Jupyter Notebook。
从Hugging Face上git clone对应项目。
创建requirements.txt,用于Hugging Face构建容器环境。
创建代码app.py,为了保证安全性,这里通过设置API_KEY进行传入。
import os
import streamlit as st
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, Settings
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.legacy.callbacks import CallbackManager
from llama_index.llms.openai_like import OpenAILike
# Create an instance of CallbackManager
callback_manager = CallbackManager()
from configparser import ConfigParser
# 通过Spaces的secret传入
api_key = os.environ.get('API_KEY')
# 下载模型
os.system('git lfs install')
os.system('git clone https://www.modelscope.cn/Ceceliachenen/paraphrase-multilingual-MiniLM-L12-v2.git')
api_base_url = "https://internlm-chat.intern-ai.org.cn/puyu/api/v1/"
model = "internlm2.5-latest"
llm =OpenAILike(model=model, api_base=api_base_url, api_key=api_key, is_chat_model=True,callback_manager=callback_manager)
# 设置页面配置,包括页面标题和图标,以提供更丰富的用户体验
st.set_page_config(page_title="由llama_index构建的RAG应用demo", page_icon="🦜🔗")
# 显示页面标题,让用户了解当前页面的功能或主题
st.title("llama_index_demo")
# 初始化模型
@st.cache_resource
def init_models():
"""
初始化并缓存模型。
本函数通过加载预训练的嵌入模型和语言模型来初始化设置,并构建查询引擎。
使用缓存装饰器是为了提高效率,避免重复初始化模型。
返回:
query_engine: 用于查询的引擎。
"""
# 初始化嵌入模型
embed_model = HuggingFaceEmbedding(
model_name="./paraphrase-multilingual-MiniLM-L12-v2"
)
Settings.embed_model = embed_model
# 初始化语言模型
Settings.llm = llm
# 加载文档并构建向量索引
documents = SimpleDirectoryReader("./data").load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine()
return query_engine
# 检查是否需要初始化模型
if 'query_engine' not in st.session_state:
st.session_state['query_engine'] = init_models()
def greet2(question):
"""
使用预设的question参数调用session_state中的query_engine来生成响应。
参数:
question (str): 一个字符串,代表用户的问题或查询。
返回:
response: query_engine对question的响应结果,类型依据具体实现而定。
"""
# 从session_state字典中获取名为'query_engine'的引擎,并使用它来查询问题
response = st.session_state['query_engine'].query(question)
# 返回查询得到的响应结果
return response
# 检查会话状态中是否存在 'messages' 键,如果不存在则初始化
# 初始化时,设置一个默认的助手消息,用于首次与用户交互
if "messages" not in st.session_state.keys():
st.session_state.messages = [{"role": "assistant", "content": "你好,我是你的助手,有什么我可以帮助你的吗?"}]
# 遍历当前会话状态中的所有消息
for message in st.session_state.messages:
# 根据消息的角色类型创建聊天消息框
with st.chat_message(message["role"]):
# 在消息框中写入消息内容
st.write(message["content"])
def clear_chat_history():
"""
清除聊天记录并重置会话状态。
此函数将当前会话状态的消息清空,仅保留一条表示助手问候的初始消息。
这有助于为用户提供一个新的开始,并确保聊天记录不会变得过于冗长。
"""
st.session_state.messages = [{"role": "assistant", "content": "你好,我是你的助手,有什么我可以帮助你的吗?"}]
# 在侧边栏添加一个'Clear Chat History'按钮,点击时调用clear_chat_history函数来清除聊天记录
st.sidebar.button('清空聊天历史', on_click=clear_chat_history)
def generate_llama_index_response(prompt_input):
"""
根据输入的提示生成基于llama索引的响应。
此函数的作用是通过特定的提示输入,生成一个相应的响应。它调用了另一个函数greet2,
以完成响应的生成过程。这种封装方式允许在greet2函数中实现复杂的处理逻辑,
同时对外提供一个简单的接口。
参数:
prompt_input (str): 用于生成响应的输入提示。
返回:
str: 由greet2函数生成的响应。
"""
return greet2(prompt_input)
# User-provided prompt
# 如果用户通过聊天输入提供了信息,则执行以下操作
if prompt := st.chat_input():
# 将用户的聊天信息添加到会话状态的消息列表中
st.session_state.messages.append({"role": "user", "content": prompt})
# 在聊天界面的用户消息区域显示用户输入的内容
with st.chat_message("user"):
st.write(prompt)
# Gegenerate_llama_index_response last message is not from assistant
# 检查最近的一条消息是否不是由助手发送的
if st.session_state.messages[-1]["role"] != "assistant":
# 在助手的聊天消息框中
with st.chat_message("assistant"):
# 显示“Thinking...”动画,表示正在处理请求
with st.spinner("Thinking..."):
# 生成响应
response = generate_llama_index_response(prompt)
# 创建一个占位符,用于显示响应内容
placeholder = st.empty()
# 在占位符中显示响应内容
placeholder.markdown(response)
# 创建一个新的消息对象,表示助手的响应
message = {"role": "assistant", "content": response}
# 将助手的响应消息添加到会话状态的消息列表中
st.session_state.messages.append(message)
回到Hugging Face,点击Settings。
找到Variables and secret,并点击New secret进行创建。
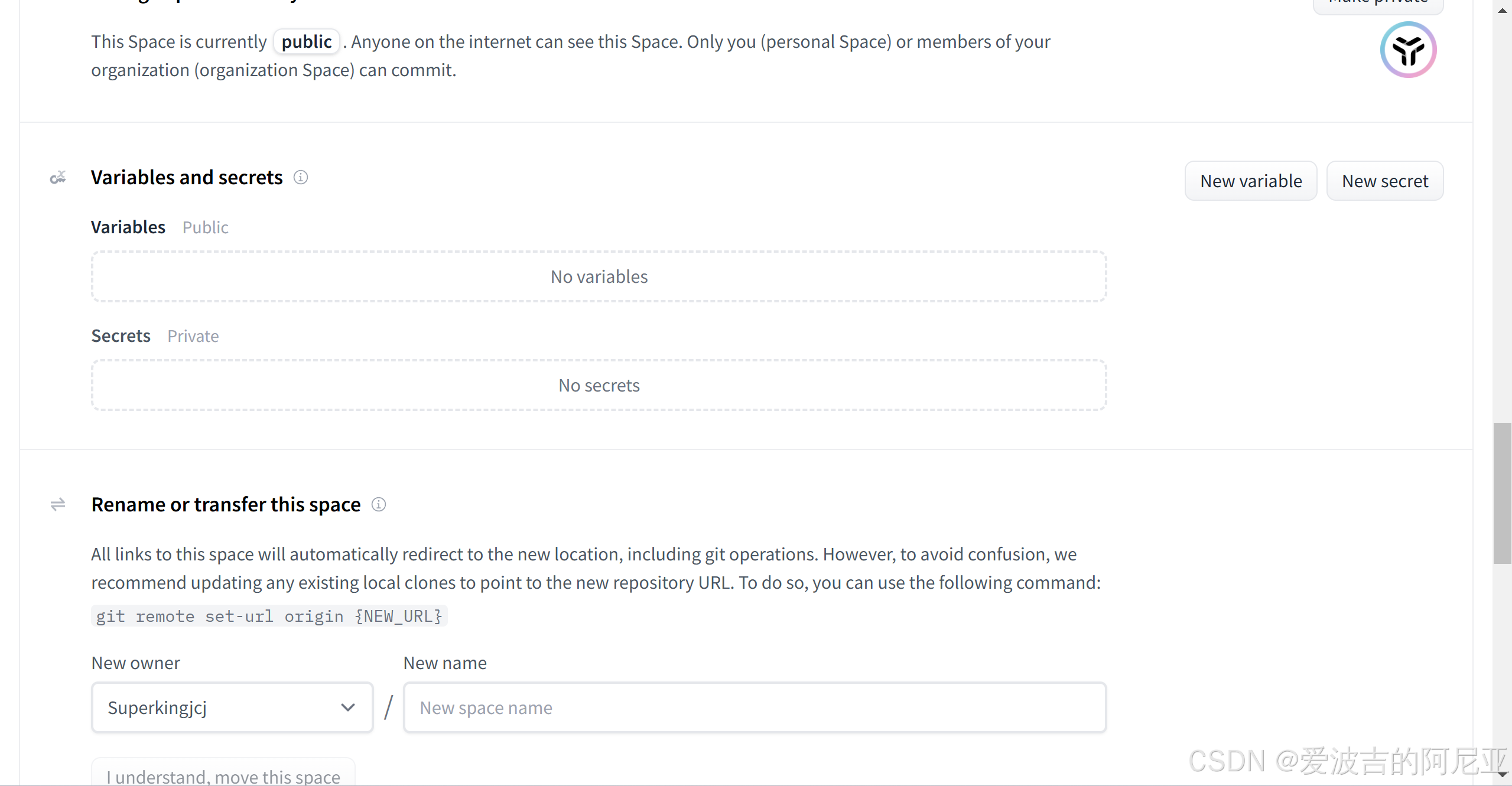
将api_token填写在这里。
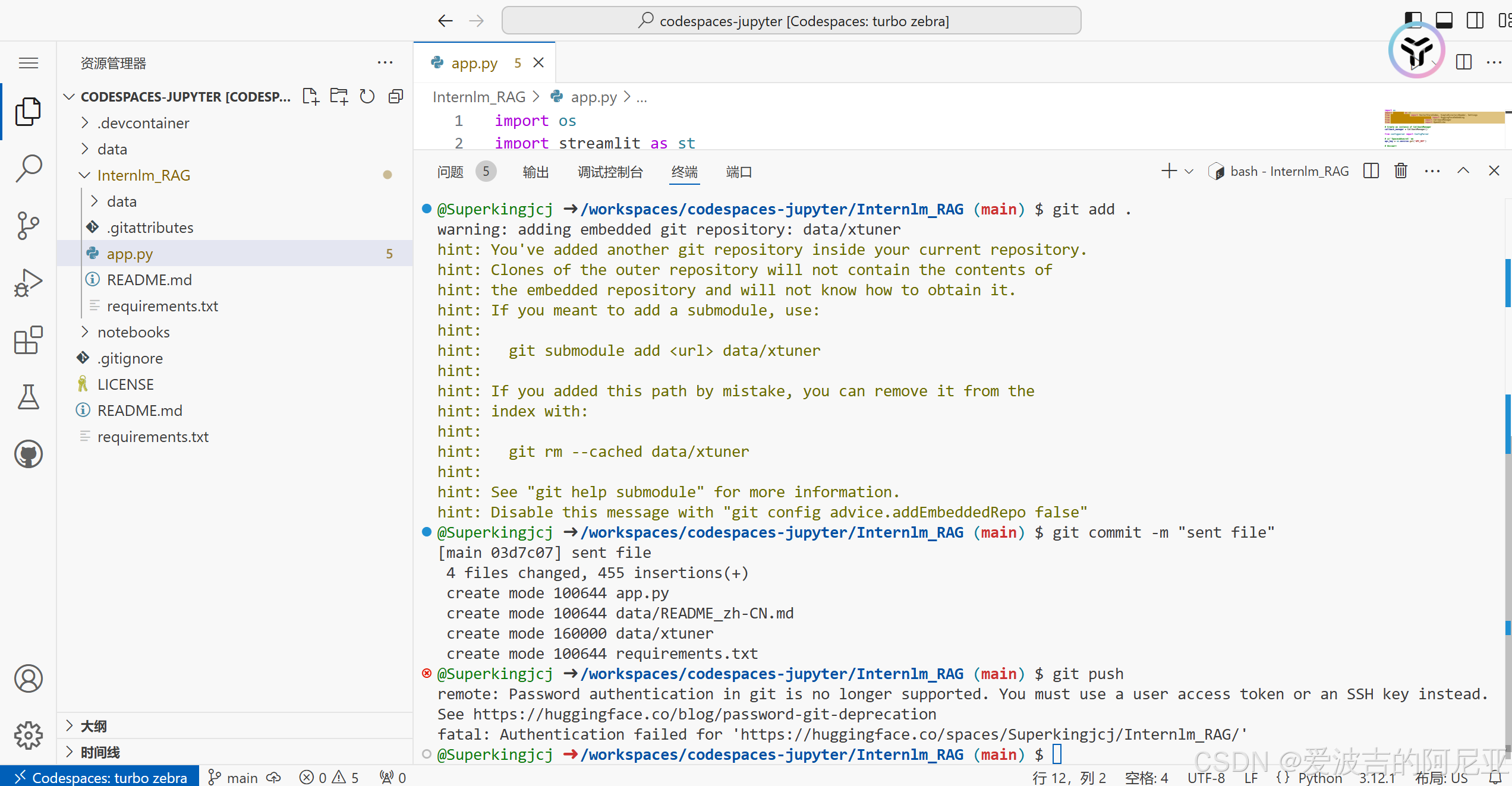
将经过修改的内容推到远程仓库,报错显示无权限。
回到Hugging Face,点击Access Tokens。
创建一个具有Write权限的Token。
然后运行git remote set-url origin https://<你的名字>:<创建的token>@huggingface.co/spaces/<你的名字>/<仓库名称>命令,并再次git push。
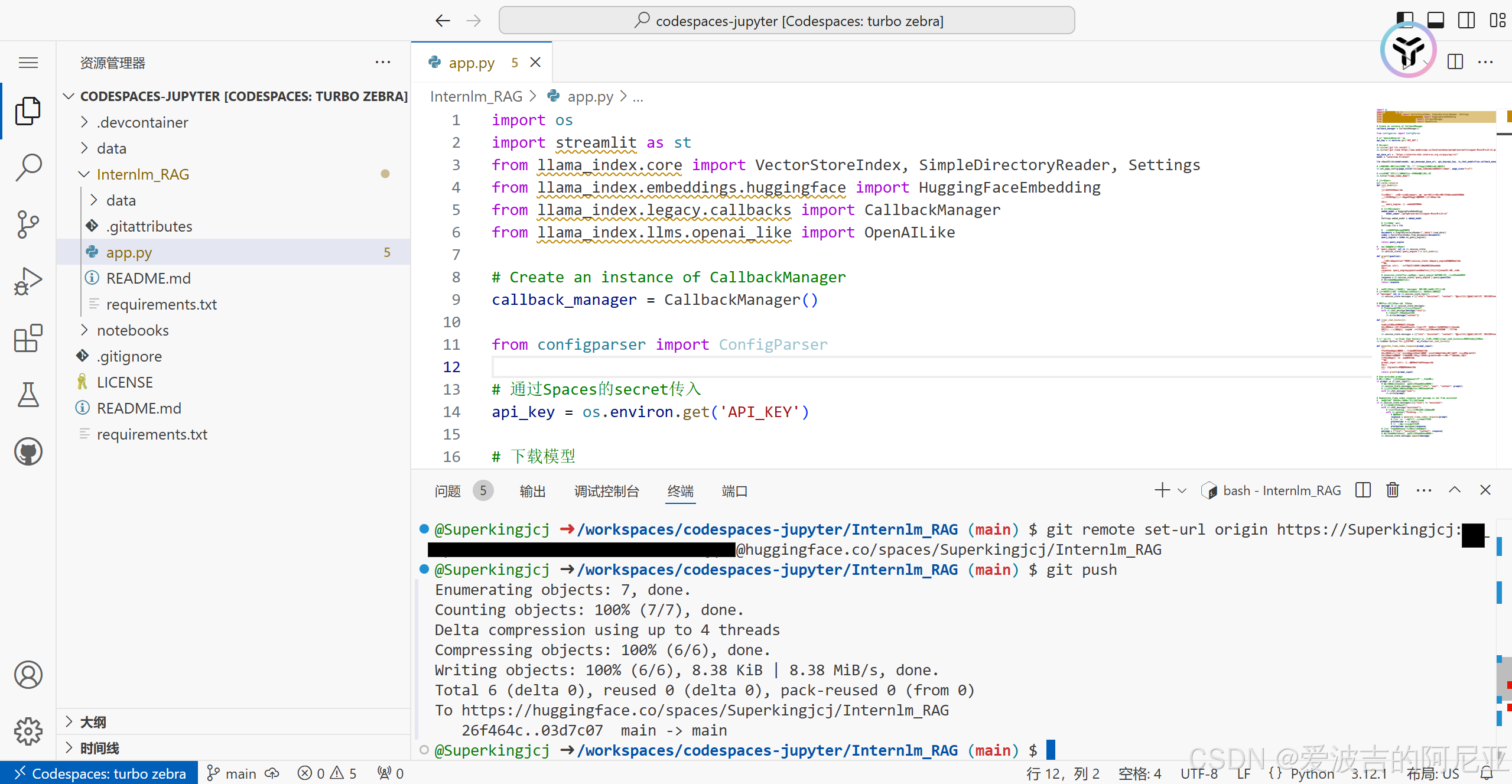
再回到Hugging Face,就可以看到我们的仓库已成功修改。
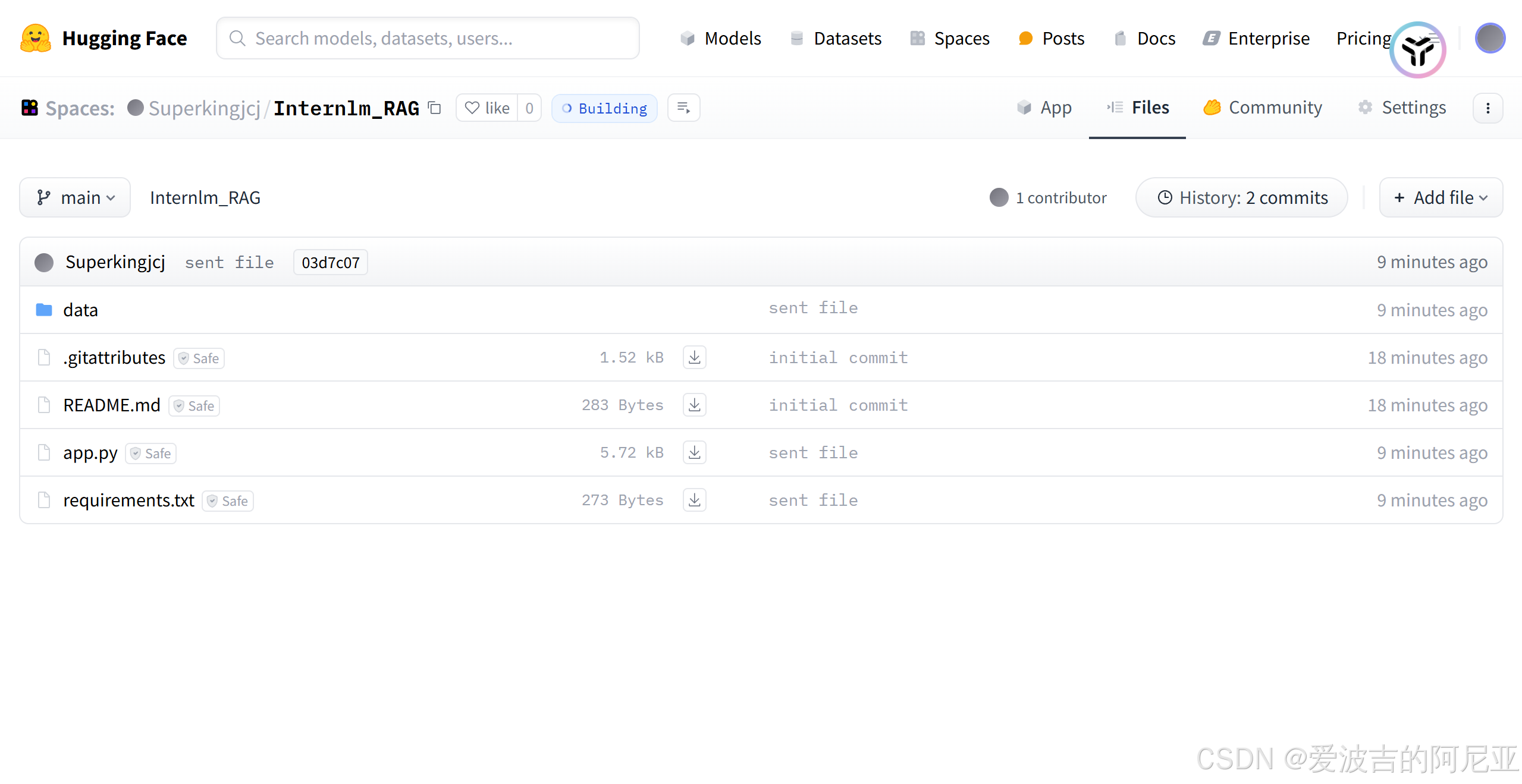
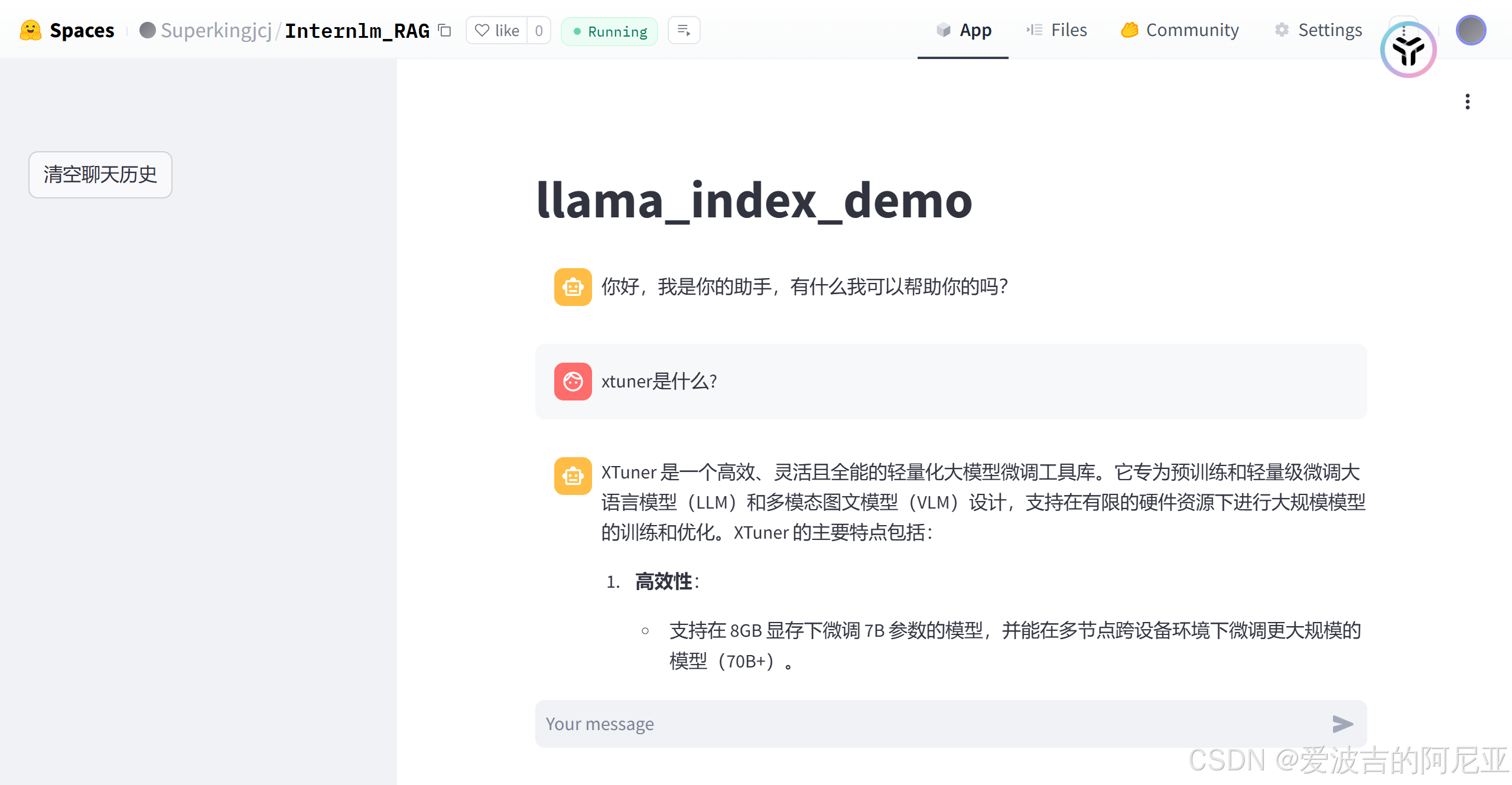
然后点击App,耐心等待,即可正常进行交互。
Hugging Face Space链接:https://huggingface.co/spaces/Superkingjcj/Internlm_RAG



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











