









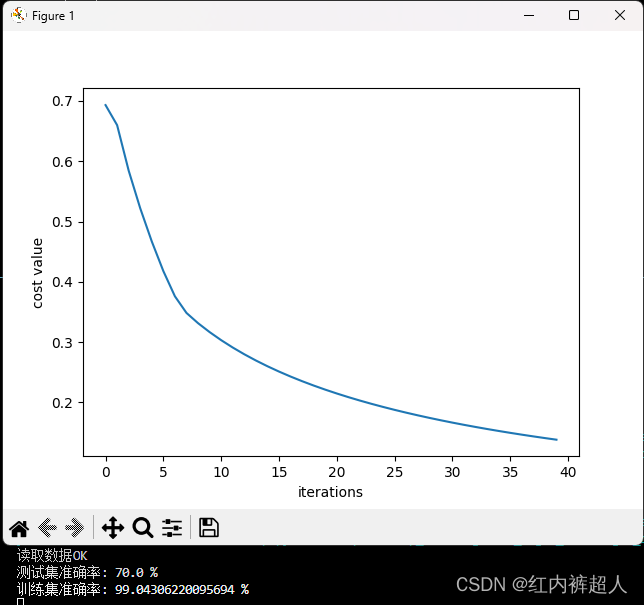
 本文介绍了使用Python实现逻辑回归模型的过程,包括类定义、参数初始化、前向传播、误差反向传播和优化算法。作者展示了如何在MNIST数据集上训练模型并计算训练集和测试集的准确率,同时可视化了损失函数随迭代次数的变化。
本文介绍了使用Python实现逻辑回归模型的过程,包括类定义、参数初始化、前向传播、误差反向传播和优化算法。作者展示了如何在MNIST数据集上训练模型并计算训练集和测试集的准确率,同时可视化了损失函数随迭代次数的变化。
代码使用类的形式
code:
import matplotlib.pyplot as plt
import h5py
import scipy
import numpy as np
from PIL import Image
from scipy import ndimage
from lr_utils import load_dataset
class logic_back():
def __init__(self,dim,rand_init=True) -> None:
'''dim是输入的维度
rand_init:是否随机初始化参数w,b始终为0'''
if rand_init==True:
self.w=np.random.random((1,dim))
else:
self.w=np.zeros((1,dim))
self.b=0
def set_w_b(self,w,b):
self.w=w
self.b=b
def sigmoid(self,z):
s=1/(1+np.exp(-z))
return s
def propagation(self,x,y,i):
'''返回一次迭代中的损失函数和dw,db'''
m=x.shape[1]
#前向传播
# self.w=(1,dim) x=(dim,m) z=(1,m)
z=np.dot(self.w,x)+self.b
a=self.sigmoid(z)
# 计算当前损失
cost=1/m*np.sum(-y*np.log(a)-(1-y)*np.log(1-a))#计算损失
# 误差反向传播
# 注意这是a-y,w=w-dw*a
# 如果是y-a,则w=w+dw*a
dz=a-y
dw=1/m*(np.dot(dz,x.T))
db=1/m*np.sum(dz)
# 核对矩阵维度
assert(dw.shape==(1,x.shape[0]))
assert(db.dtype==float)
grads={
"dw":dw,
"db":db,
}
# 执行一次需要返回的数据:梯度,损失
return grads,cost
def optimize(self,x,y,num_iterations,learning_rate,num):
costs=[]
for i in range(num_iterations):
grads,cost=self.propagation(x,y,i)
# 更新参数w,b
dw=grads["dw"]
db=grads["db"]
self.w=self.w-learning_rate*dw
self.b=self.b-learning_rate*db
if i%num==0:
costs.append(cost)
params={
"w":self.w,
"b":self.b
}
return params,costs
def predict(self,x):
m=x.shape[1]
y_predict=np.zeros((1,m))
a=self.sigmoid(np.dot(self.w,x)+self.b)
y_predict[a>0.5]=1
return y_predict
# 读取数据
train_set_x_orig, train_set_y, test_set_x_orig, test_set_y, classes = load_dataset()
print("读取数据OK")
# 对数据进行处理
train_x_flatten=train_set_x_orig.reshape(train_set_x_orig.shape[0],-1).T# 现在每一列都是一个输入:(12288,209),209个样本,每个样本的输入维度是12288
test_x_flatten=test_set_x_orig.reshape(test_set_x_orig.shape[0],-1).T# 现在每一列都是一个输入:(12288,50),50个样本,每个样本的输入维度是12288
# 标准化数据,对于图形数据直接除以225即可
train_x_flatten=train_x_flatten/255
test_x_flatten=test_x_flatten/255
# 创建一个逻辑回归对象
my_logic_back=logic_back(train_x_flatten.shape[0],False)
num_iterations=2000#迭代次数
learning_rate=0.005#学习率
num=50#每num次存储一次损失
#开始训练
params,costs = my_logic_back.optimize(train_x_flatten,train_set_y,num_iterations,learning_rate,num)
#预测
# 测试集
test_y_predict = my_logic_back.predict(test_x_flatten)
print("测试集准确率: {} %".format(100 - np.mean(np.abs(test_y_predict - test_set_y)) * 100))
# 训练集
train_y_predict=my_logic_back.predict(train_x_flatten)
print("训练集准确率: {} %".format(100 - np.mean(np.abs(train_y_predict - train_set_y)) * 100))
#画损失函数值的变化
plt.plot(costs)
plt.xlabel("iterations")
plt.ylabel("cost value")
plt.show()
结果:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









