






文章目录
摘要
本周主要深入研究了AlexNet这一经典的卷积神经网络,通过阅读相关论文和研究工作,我对AlexNet的结构和创新有了更深刻的理解。AlexNet是深度学习领域的一个重要里程碑,因为它首次证明了深度神经网络在大规模数据集上的有效性。AlexNet包含5个卷积层、3个全连接层和最后的softmax分类层,总共有8层。AlexNet首次在卷积神经网络中广泛使用了ReLU(Rectified Linear Unit)作为激活函数,这使得网络的训练速度比使用sigmoid或tanh激活函数的网络快很多。为了防止过拟合,AlexNet在全连接层中使用了dropout技术。这是一个正则化技术,它在训练过程中随机关闭一部分神经元。在某些卷积层之后,AlexNet使用了局部响应归一化来模拟神经生物学中的侧抑制机制。为了进一步防止过拟合,AlexNet使用了数据增强技术,如随机裁剪、水平翻转和颜色变化。由于其深度结构和大量的参数,AlexNet的训练非常计算密集。为了加速训练,AlexNet被设计为在两个GPU上并行运行。AlexNet使用了重叠的最大池化,这意味着池化窗口之间有重叠,这有助于减少过拟合。最后进行了pytorch代码实践。
Abstract
This week, I delved deeply into the classic CNN model, AlexNet. By analyzing related papers and research, I gained a profound understanding of AlexNet’s architecture and innovations. AlexNet is a significant milestone in the DL domain, as it was the first to demonstrate the efficacy of DNNs on large-scale datasets. The network comprises 5 Conv layers, 3 FC layers, and a final softmax output layer, totaling 8 layers. It was pioneering in its widespread use of ReLU (Rectified Linear Unit) as an activation function in CNNs, which significantly accelerated the training speed compared to networks using sigmoid or tanh activations. To combat overfitting, AlexNet employed dropout in its FC layers, a regularization technique that randomly deactivates a subset of neurons during training. In certain Conv layers, AlexNet utilized Local Response Normalization, simulating lateral inhibition in neurobiology. To further mitigate overfitting, AlexNet incorporated data augmentation techniques like random cropping, horizontal flipping, and color jittering. Due to its deep architecture and extensive parameters, training AlexNet is computationally intensive. To expedite training, it was designed to run in parallel on two GPUs. AlexNet also introduced overlapping max-pooling, implying overlaps between pooling windows, which aids in reducing overfitting. Finally, I implemented it using PyTorch code.
1、研究背景和目的
20世纪80年代和90年代,神经网络曾经兴盛一时,但后来由于计算能力不足和训练技术的限制而逐渐式微。然而,在2000年后,随着计算能力的显著提高和更好的训练方法的出现,深度学习再次成为研究的焦点。在计算机视觉领域,图像分类一直是一个重要的问题。传统的计算机视觉方法通常需要手工设计特征,这在处理复杂数据集时存在限制。Alex Krizhevsky、Ilya Sutskever和Geoffrey Hinton提出了AlexNet,这是一个深度卷积神经网络架构,具有多个卷积层和池化层。AlexNet在ILSVRC 2012竞赛中以巨大的优势赢得了冠军,将图像分类错误率降低到了历史上的最低水平,标志着深度学习在计算机视觉领域的复兴。研究的主要目的是展示深度卷积神经网络在大规模图像分类任务上的有效性。通过使用大型数据集(如ImageNet)和深度CNN,作者希望提高图像分类的准确性,并超越之前的最先进方法。此外,还引入了新的正则化技术(如dropout)来防止过拟合,并展示了GPU在加速深度网络训练中的重要性。
2.研究内容
2.1 主要内容
作者使用深度卷积神经网络(CNN)对ImageNet LSVRC-2010比赛的1.2百万高分辨率图像进行了分类,分为1000个不同的类别。该神经网络有6000万个参数和650000个神经元,由五个卷积层组成,其中一些层后面是最大池层,还有三个全连接层,最后是1000路softmax。该网络的top-1和top-5错误率分别为37.5%和17.0%,超越了之前的最先进方法。这里提到的 top-1 和 top-5错误率:
top-1:通俗的讲 假如模型预测只有一张狗的图片,且只能输出一个预测结果,如果预测的结果刚好为狗,则叫top-1正确率,反之,预测错误就叫top-1错误率。
top-5:同理top-1 ,这里输出的为五个预测结果,五个预测结果中错误的概率,就是top-5错误率。
2.2 AlexNet模型结构
AlexNet包含八个带权重的层;前五个是卷积层,其余三个是全连接层。最后一个全连接层的输出被馈送到1000路softmax,该softmax在1000个类标签上产生分布。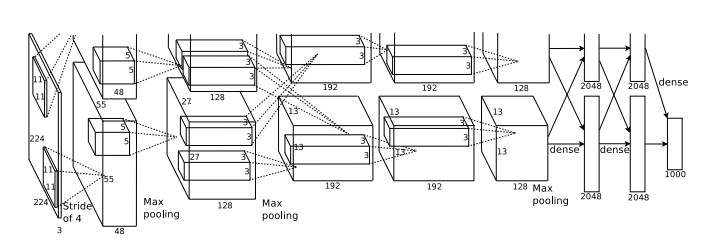
因为当时GPU内存的限制,在图中作者使用了多路GPU并行,但是以目前GPU的处理能力,单GPU足够了,因此其结构图可以如下所示:
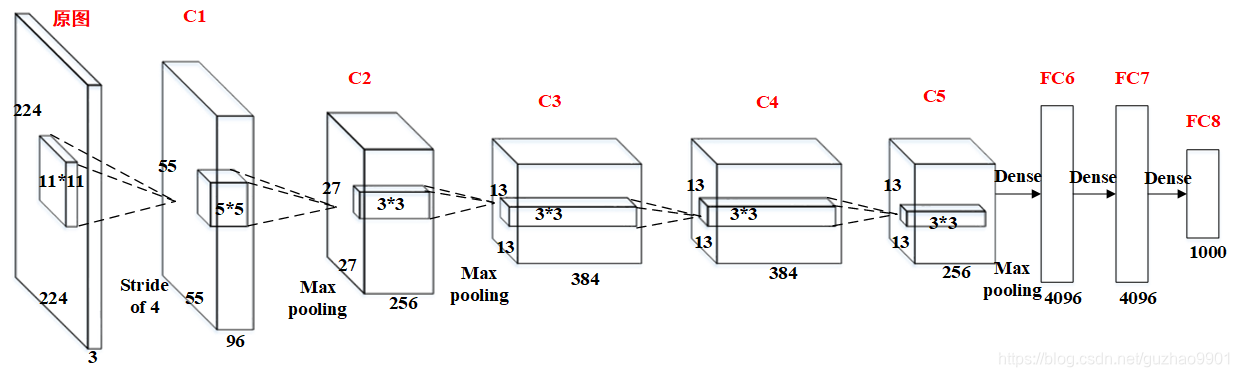
下面将对AlexNet的每一层进行详细介绍:
(1)第一层:卷积层
AlexNet的第一层是一个卷积层,该层使用96个卷积核对输入图像进行卷积操作。卷积核的大小为11×11,步长为4,填充为0。这样可以保证输出的特征图大小为55×55,同时减少了特征图的数量,从而避免了过拟合的风险。此外,该层还使用了ReLU激活函数来增加非线性性,并使用了局部响应归一化技术来进一步优化模型。
(2)第二层:池化层
AlexNet的第二层是一个池化层,该层使用3×3的最大池化操作对输入图像进行下采样。池化的步幅为2,这样可以将特征图的大小减半。该层的目的是减少特征图的大小,并增加模型的稳定性。
(3)第三层:卷积层
AlexNet的第三层是一个卷积层,该层使用256个卷积核对输入进行卷积操作。卷积核的大小为5×5,步长为1,填充为2。这样可以保证输出的特征图大小为27×27。该层还使用了ReLU激活函数和局部响应归一化技术来增加非线性性和优化模型。
(4)第四层:池化层
AlexNet的第四层是一个池化层,该层使用3×3的最大池化操作对输入图像进行下采样。池化的步幅为2,这样可以将特征图的大小减半。该层的目的是减少特征图的大小,并增加模型的稳定性。
(5)第五层:卷积层
AlexNet的第五层是一个卷积层,该层使用384个卷积核对输入进行卷积操作。卷积核的大小为3×3,步长为1,填充为1。这样可以保证输出的特征图大小为13×13。该层还使用了ReLU激活函数来增加非线性性。
(6)第六层:卷积层
AlexNet的第六层是一个卷积层,该层使用384个卷积核对输入进行卷积操作。卷积核的大小为3×3,步长为1,填充为1。这样可以保证输出的特征图大小为13×13。该层还使用了ReLU激活函数来增加非线性性。
(7)第七层:卷积层
AlexNet的第七层是一个卷积层,该层使用256个卷积核对输入进行卷积操作。卷积核的大小为3×3,步长为1,填充为1。这样可以保证输出的特征图大小为13×13。该层还使用了ReLU激活函数来增加非线性性。
(8)第八层:池化层
AlexNet的第八层是一个池化层,该层使用3×3的最大池化操作对输入图像进行下采样。池化的步幅为2,这样可以将特征图的大小减半。该层的目的是减少特征图的大小,并增加模型的稳定性。
(9)第九层:全连接层
AlexNet的第九层是一个全连接层,该层包含4096个神经元。该层的输入是前面所有卷积层和池化层的输出结果,即13×13×256=43264个特征。该层使用ReLU激活函数来增加非线性性。
(10)第十层:全连接层
AlexNet的第十层是一个全连接层,该层包含4096个神经元。该层使用ReLU激活函数来增加非线性性。
(11)第十一层:输出层
AlexNet的第十一层是一个输出层,该层包含1000个神经元,对应于ImageNet数据集中的1000个类别。该层使用softmax激活函数来计算每个类别的概率值。
需要注意的是:AlexNet第三、第四和第五卷积层彼此连接,没有任何中间池化或归一化层。这个设计背后有几个主要原因:
- 增加网络深度: AlexNet的设计目标之一是创建一个相对较深的卷积神经网络,以捕捉图像中的更复杂和抽象的特征。通过将多个卷积层连接在一起,可以增加网络的深度,从而更好地学习图像的高级特征表示。
- 增强非线性性: 每个卷积层之后都使用了ReLU激活函数,这增加了网络的非线性性。在卷积层之间插入池化或归一化层可能会减弱网络的非线性性,因此这些层被省略,以便更好地捕捉图像的非线性特征。
- 减少参数数量: 卷积层之间的池化或归一化层会增加网络的参数数量,这可能会导致过拟合的问题。通过省略这些层,可以降低模型的复杂性,从而更容易训练。
- 有效的感受野: 连续的卷积层可以有效地增加网络的感受野(Receptive Field),使网络能够捕获更大范围的图像信息。这有助于提高对不同尺度和复杂度的特征的敏感性。
- 模型性能: 实验结果表明,将多个卷积层连接在一起而不进行池化或归一化,有助于提高模型的性能。这种架构在ImageNet等大规模图像分类任务上表现出色,赢得了2012年ImageNet竞赛的冠军,从而证明了其有效性。
3、AlexNet网络结构的主要贡献
3.1 ReLU激活函数的引入
采用修正线性单元(ReLU)的深度卷积神经网络训练时间比等价的tanh单元要快几倍。而时间开销是进行模型训练过程中很重要的考量因素之一。同时,ReLU有效防止了过拟合现象的出现。由于ReLU激活函数的高效性与实用性,使得它在深度学习框架中占有重要地位。
3.2 层叠池化操作
以往池化的大小PoolingSize与步长stride一般是相等的,例如:图像大小为256*256,PoolingSize=2×2,stride=2,这样可以使图像或是FeatureMap大小缩小一倍变为128,此时池化过程没有发生层叠。但是AlexNet采用了层叠池化操作,即PoolingSize > stride。这种操作非常像卷积操作,可以使相邻像素间产生信息交互和保留必要的联系。论文中也证明,此操作可以有效防止过拟合的发生。
3.3 Dropout操作
Dropout叫做随机失活,简单来说就是在模型训练阶段的前向传播过程中,让某些神经元的激活值以一定的概率停止工作,如下图所示,这样可以使模型的泛化性更强。
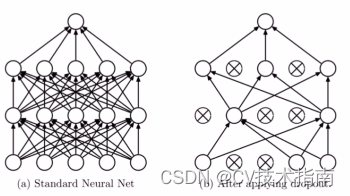
Dropout操作会将概率小于0.5的每个隐层神经元的输出设为0,即去掉了一些神经节点,达到防止过拟合。那些“失活的”神经元不再进行前向传播并且不参与反向传播。这个技术减少了复杂的神经元之间的相互影响。在论文中,也验证了此方法的有效性。
3.4 网络层数的增加
与原始的LeNet相比,AlexNet网络结构更深,LeNet为5层,AlexNet为8层。在随后的神经网络发展过程中,AlexNet逐渐让研究人员认识到网络深度对性能的巨大影响。当然,这种思考的重要节点出现在VGG网络(下文中将会讲到),但是很显然从AlexNet为起点就已经开始了这项工作。
4.代码实现:
import time
import torch
from torch import nn, optim
import torchvision
# 检查是否有可用的GPU,如果有则使用,否则使用CPU
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 定义AlexNet网络结构
class AlexNet(nn.Module):
def __init__(self):
super(AlexNet, self).__init__()
# 卷积层部分
self.conv = nn.Sequential(
# 第一层卷积,输入通道为1,输出通道为96,卷积核大小为11x11,步长为4
nn.Conv2d(1, 96, 11, 4),
nn.ReLU(), # 使用ReLU激活函数
nn.MaxPool2d(3, 2), # 最大池化,核大小为3x3,步长为2
# 第二层卷积,输入通道为96,输出通道为256,卷积核大小为5x5,步长为1,填充为2
nn.Conv2d(96, 256, 5, 1, 2),
nn.ReLU(),
nn.MaxPool2d(3, 2),
# 接下来是三个连续的卷积层,都使用3x3的卷积核,步长为1,填充为1
nn.Conv2d(256, 384, 3, 1, 1),
nn.ReLU(),
nn.Conv2d(384, 384, 3, 1, 1),
nn.ReLU(),
nn.Conv2d(384, 256, 3, 1, 1),
nn.ReLU(),
nn.MaxPool2d(3, 2) # 最后一个最大池化层
)
# 全连接层部分
self.fc = nn.Sequential(
# 第一个全连接层,输入维度为256*5*5,输出维度为4096
nn.Linear(256*5*5, 4096),
nn.ReLU(),
nn.Dropout(0.5), # 使用Dropout防止过拟合,丢弃率为0.5
# 第二个全连接层,输入维度为4096,输出维度也为4096
nn.Linear(4096, 4096),
nn.ReLU(),
nn.Dropout(0.5),
# 输出层,输入维度为4096,输出维度为10(因为使用的是Fashion-MNIST数据集,有10个类别)
nn.Linear(4096, 10),
)
# 前向传播函数
def forward(self, img):
# 先通过卷积层
feature = self.conv(img)
# 然后将卷积层的输出展平,并通过全连接层
output = self.fc(feature.view(img.shape[0], -1))
return output
5.总结
在本周学习中,我详细了解了AlexNet的网络结构,包括其多个卷积层、池化层和全连接层。了解到ReLU激活函数的引入使得网络的训练速度大大加快,并有助于防止过拟合。还有层叠池化操作可以使相邻像素间产生信息交互,增强模型的泛化能力。通过这篇文章,我不仅学习了AlexNet的基本知识和其在计算机视觉领域的重要性,还掌握了其核心技术和实现方法。

















 283
283

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









