







training
Dropout的做法是每次对一个batch做训练前对network中的每一个neuron(包括input layer的neuron),做sampling(抽样) ,每个neuron都有p%的几率会被丢掉,如果某个neuron被丢掉的话,跟它相连的权值 w w w也都要被丢掉,剩下的neuron组成一个thinner network,以此thinner network为结构进行训练。
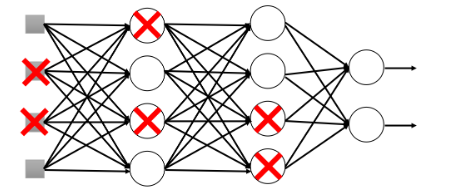 whole network whole network
|
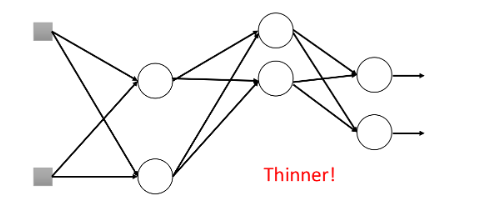 thinner network thinner network
|
虽然每次只是对一部分参数做训练,但是多次训练后整个network的neuron几乎全部被训练。
testing
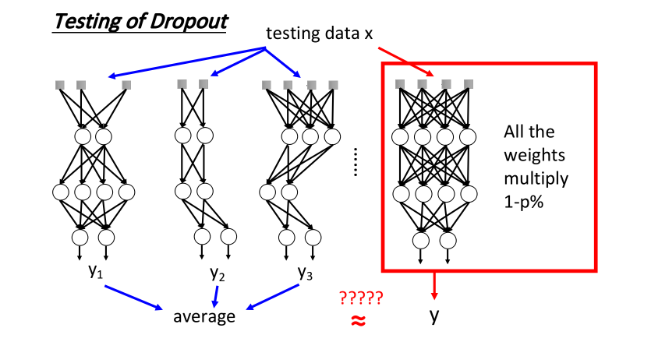
使用dropout方法testing的时候,需要使用整个network,无需对neuron做抽样。但在testing的时候需要对neuron上的每个权重 w w w乘以一个(1- dropout rate)。
why multiply (1-dropout rate)%
假设dropout rate是50%,在训练时候期望每次update之前会丢掉一半的neuron,并以一个thinner network的形式去逼近真实label。如果这个thinner network已经在training data上的误差达到了global minimal的地方,而且这个结果距离testing data的误差应不会太离谱,但在testing的时候,相比thinner network,使用whole network中额外的neuron将会给预测输出造成很大的偏差。
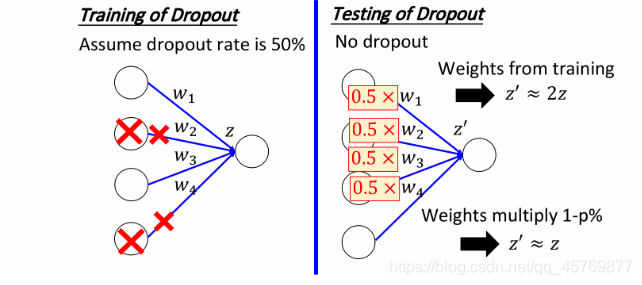
由于testing时没有对neuron做抽样,所以如果testing使用的是和training同一组
w
w
w,那training得到的output
z
z
z和testing得到的output
z
′
z'
z′,它们的值其实是会相差两倍的,即
z
′
≈
2
z
z'≈2z
z′≈2z,这样会造成testing的结果与training的结果并不match,最终的performance反而会变差。testing时将所有的
w
w
w乘上0.5,这样
z
z
z就约等于
z
′
z'
z′。
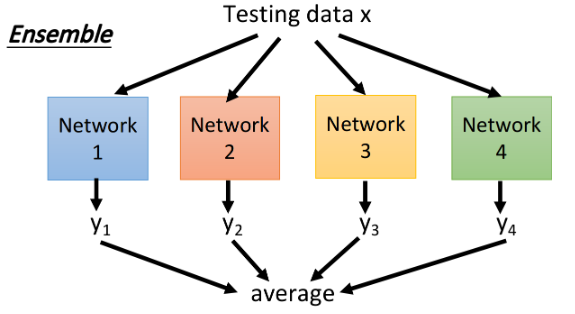
ensemble
- training:将整个training set,sample出很多subset,分别训练出各自的network(每一个network的structure可以不一样)。
- testing:将testing data分别输入到不同的network,将结果求平均做最后的预测输出。
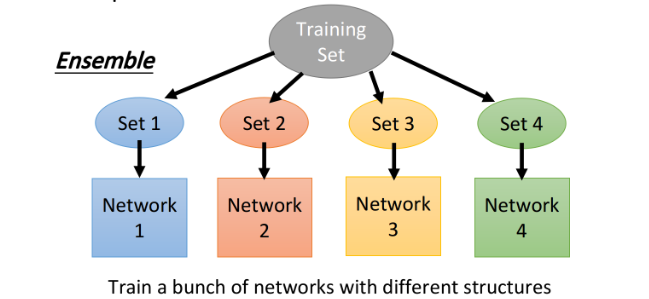 ensemble in training ensemble in training
|
 ensemble in testing ensemble in testing
|
如果model很复杂,它往往是bias小,但variance很大的情况,但多这样的model求平均,结果往往会很准。ensemble便利用这个特性。著名的random forest(随机森林)也是实践这个精神的一个方法,因为它很复杂没有那么容易overfitting,但如果是decision tree(决策树),它就会很弱,也很容易overfitting。
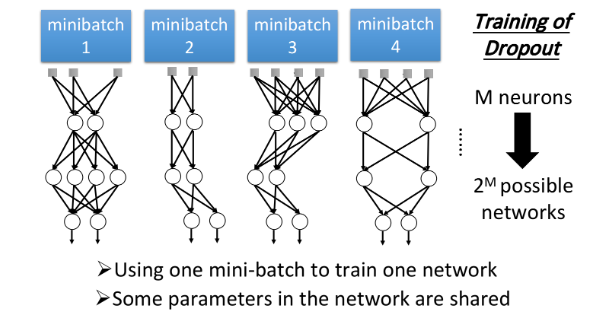
dropout vs. ensemble
在training network的时候,每次拿一个minibatch出来就做一次update,而根据dropout的特性,每次update之前都要对所有的neuron进行sample,因此每一个minibatch所训练的network都是不同的,所以做了几次update,就相当于train了几个不同的network。假设有 M M M个neuron则network structure可能有 2 M 2^M 2M种。
 dropout in training dropout in training
|
 dropout in testing dropout in testing
|
Dropout不同于ensemble的地方
training上的不同之处
- ensemble的每个subset通常很大,Dropout的minibatch只有少量数据
- ensemble中每个subset训练独立的network,Dropout中每个minibatch训练的network之间的参数部分共享
也正是由于第二点,虽然Dropout的minibatch只有少量数据,看起来训练结果并不可靠,但由于不同的network之间参数共享,同一个参数 w w w可以在不同的network里被不同的minibatch训练。
testing上的不同之处
- ensemble是将每个network的结果求平均得到最后的output
- dropout是把训练出来的整个network每个权值 w w w乘上 ( 1 − p % ) (1-p\%) (1−p%),得到output
dropout并没有把这些network分开考虑,而是用一个完整的network,实际的结果是近似。
summary
当activation是linear的,ensemble和dropout的output是近似的。
以一个简单的network为例
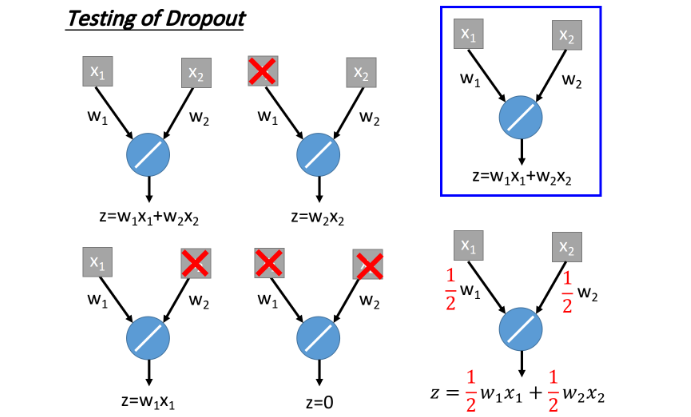
假设neuron的输入是 x 1 , x 2 x_1, x_2 x1,x2,假设做ensemble,每个neuron被sampling,可能有四种network,它们所对应的结果分别为 z = w 1 x 1 , z = w 2 x 2 , z = w 1 x 1 , z = 0 z=w_1x_1, z=w_2x_2, z=w_1x_1, z=0 z=w1x1,z=w2x2,z=w1x1,z=0。将这4个network的结果平均起来,得到的output是 z = 1 2 w 1 x 1 + 1 2 w 2 x 2 z=\frac{1}{2}w_1x_1+\frac{1}{2}w_2x_2 z=21w1x1+21w2x2。
假设做dropout,以整体训练network以后得到的weights是 w 1 , w 2 w_1, w_2 w1,w2,将这两个weights都乘以 1 2 \frac{1}{2} 21,得到的output也是 z = 1 2 w 1 x 1 + 1 2 w 2 x 2 z=\frac{1}{2}w_1x_1+\frac{1}{2}w_2x_2 z=21w1x1+21w2x2。
但是只有是linear network,ensemble才会等于weights multiply一个值。
-
只有在linear的network,才会得到上述的等价关系,如果network是非linear的,ensemble和dropout是不等价的;虽然在non-linear的情况下,它是和ensemble不等价,但最后的结果还是会起作用。
-
如果network接近linear,dropout所得到的performance会比较好,ReLU和Maxout的network相对来说是比较接近于linear,所以通常会把含有ReLU或Maxout的network与Dropout配合起来使用

















 31万+
31万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









