






 本文详细介绍了Spark核心架构,包括RDD、分区、算子、Transformation与Action、窄依赖与宽依赖等概念,以及Job、Stage、Task的执行流程。此外,还探讨了Spark的不同运行模式与用户交互方式,如spark-shell、spark-submit,以及如何在不同模式下提交任务。
本文详细介绍了Spark核心架构,包括RDD、分区、算子、Transformation与Action、窄依赖与宽依赖等概念,以及Job、Stage、Task的执行流程。此外,还探讨了Spark的不同运行模式与用户交互方式,如spark-shell、spark-submit,以及如何在不同模式下提交任务。
1、Spark架构设计
1.1 架构设计图
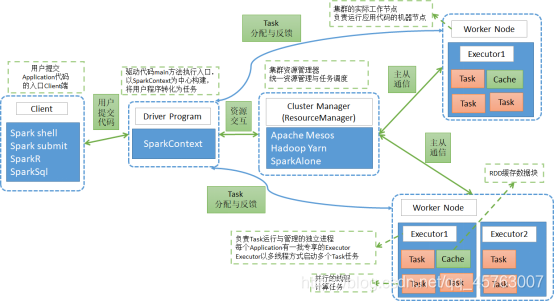
1.2 相关术语名词解释
1、RDD (Resilient Distributed DataSet)
o弹性分布式数据集,是对数据集在spark存储和计算过程中的一种抽象。
o是一组只读、可分区的的分布式数据集合。
o一个RDD 包含多个分区Partition(类似于MapReduce中的InputSplit),分区是依照一定的规则的,将具有相同规则的属性的数据记录放在一起。
o横向上可切分并行计算,以分区Partition为切分后的最小存储和计算单元。
o纵向上可进行内外存切换使用,即当数据在内存不足时,可以用外存磁盘来补充。
2、Partition(分区)
oPartition类似hadoop的Split,计算是以partition为单位进行的,提供了一种划分数据的方式。
opartition的划分依据有很多,常见的有Hash分区、范围分区等,也可以自己定义的,像HDFS文件,划分的方式就和MapReduce一样,以文件的block来划分不同的partition。
o一个Partition交给一个Task去计算处理
3、算子
o英文简称:Operator,简称op
o广义上讲,对任何函数进行某一项操作都可以认为是一个算子
o通俗上讲,算子即为映射、关系、变换。
oMapReduce算子,主要分为两个,即为Map和Reduce两个主要操作的算子,导致灵活可用性比较差。
oSpark算子,分为两大类,即为Transformation和Action类,合计有80多个。
4、Transformation类算子
o操作是延迟计算的,也就是说从一个RDD 转换生成另一个 RDD 的转换操作不是马上执行,需要等到有 Action 操作的时候才会真正触发运算。
o细分类
Value数据类型的Transformation算子
Key-Value数据类型的Transfromation算子
5、Action类算子
o会触发 Spark 提交作业(Job),并将数据输出 Spark系统。
6、窄依赖
o如果一个父RDD的每个分区只被子RDD的一个分区使用 ----> 一对一关系
7、宽依赖
o如果一个父RDD的每个分区要被子RDD 的多个分区使用 ----> 一对多关系
8、Application
oSpark Application的概念和MapReduce中的job或者yarn中的application类似,指的是用户编写的Spark应用程序,包含了一个Driver功能的代码和分布在集群中多个节点上运行的Executor代码
o一般是指整个Spark项目从开发、测试、布署、运行的全部。
9、Driver
o运行main函数并且创建SparkContext的程序。
o称为驱动程序,Driver Program类似于hadoop的wordcount程序中的driver类的main函数。
10、Cluster Manager
o集群的资源管理器,在集群上获取资源的服务。如Yarn、Mesos、Spark Standalone等。
o以Yarn为例,驱动程序会向Yarn申请计算我这个任务需要多少的内存,多少CPU等,后由Cluster Manager会通过调度告诉驱动程序可以使用,然后驱动程序将任务分配到既定的Worker Node上面执行。
11、WorkerNode
o集群中任何一个可以运行spark应用代码的节点。
oWorker Node就是物理机器节点,可以在上面启动Executor进程。
12、Executor
oApplication运行在Worker节点上的一个进程,该进程负责运行Task,并且负责将数据存在内存或者磁盘上,每个Application都有各自独立专享的一批Executor。
oExecutor即为spark概念的资源容器,类比于yarn的container容器,真正承载Task的运行与管理,以多线程的方式运行Task,更加高效快速。
13、Task
o与Hadoop中的Map Task或者Reduce Task是类同的。
o分配到executor上的基本工作单元,执行实际的计算任务。
oTask分为两类,即为ShuffleMapTask和ResultTask。
ShuffleMapTask:即为Map任务和发生Shuffle的任务的操作,由Transformation操作组成,其输出结果是为下个阶段任务(ResultTask)进行做准备,不是最终要输出的结果。
ResultTask:即为Action操作触发的Job作业的最后一个阶段任务,其输出结果即为Application最终的输出或存储结果。
14、Job(作业)
oSpark RDD里的每个action的计算会生成一个job。
o用户提交的Job会提交给DAGScheduler(Job调度器),Job会被分解成Stage去执行,每个Stage由一组相同计算规则的Task组成,该组Task也称为TaskSet,实际交由TaskScheduler去调度Task的机器执行节点,最终完成作业的执行。
15、Stage(阶段)
oStage是Job的组成部分,每个Job可以包含1个或者多个Stage。
oJob切分成Stage是以Shuffle作为分隔依据,Shuffle前是一个Stage,Shuffle后是一个Stage。即为按RDD宽窄依赖来划分Stage。
o每个Job会被拆分很多组Task,每组任务被称为Stage,也可称TaskSet,一个作业可以被分为一个或多个阶段
2、spark运行模式与用户交互方式
2.1运行模式
即作业以什么样的模式去执行,主要是单机、分布式两种方式的细节选择。
序号 模式名称 特点 应用场景
1 本地运行模式(local) 单台机器多线程来模拟spark分布式计算 机器资源不够
测试验证程序逻辑的正确性
2 伪分布式模式 单台机器多进程来模拟spark分布式计算 机器资源不够
测试验证程序逻辑的正确性
3 standalone(client) 独立布署spark计算集群
自带clustermanager
driver运行在spark submit client端 机器资源充分
纯用spark计算框架
任务提交后在spark submit client端实时查看反馈信息
测试使用还可以,生产环境极少使用该种模式
4 standalone(cluster) 独立布署spark计算集群
自带clustermanager
driver运行在spark worker node端 机器资源充分
纯用spark计算框架
任务提交后将退出spark submit client端
测试和生产环境均可以自由使用,但更多用于生产环境
5 spark on yarn
(yarn-client) 以yarn集群为基础
只添加spark计算框架相关包
driver运行在yarn client上 机器资源充分
多种计算框架混用
数据共享性强
任务提交后在yarn client端实时查看反馈信息
6 spark on yarn
(yarn-cluster) 以yarn集群为基础
只添加spark计算框架相关包
driver运行在集群的am contianer中 机器资源充分
多种计算框架混用
数据共享性强
任务提交后将退出yarn client端
7 spark on mesos/ec2 与spark on yarn类似 与spark on yarn类似
在国内应用较少
2.2用户交互方式
1、spark-shell:spark命令行方式来操作spark作业。
o多用于简单的学习、测试、简易作业操作。
2、spark-submit:通过程序脚本,提交相关的代码、依赖等来操作spark作业。
o最多见的提交任务的交互方式,简单易用、参数齐全。
3、spark-sql:通过sql的方式操作spark作业。
osql相关的学习、测试、生产环境研发均可以使用该直接操作交互方式。
4、spark-class:最低层的调用方式,其它调用方式多是最终转化到该方式中去提交。
o直接使用较少
5、sparkR,sparkPython:通过其它非java、非scala语言直接操作spark作业的方式。
oR、python语言使用者的交互方式。
2.2.1重要交互方式使用介绍
重点说明spark-shell,spark-submit两大方式,spark-sql后有专门章节介绍,其它小众方式不做介绍。
1、spark-shell
交互方式定位
o一个强大的交互式数据操作与分析的工具,提供一个简单的方式快速学习spark相关的API。
启动方式
o前置环境:已将spark-shell等交互式脚本已加入系统PATH变量,可在任意位置使用。
o以本地2个线程来模拟运行spark相关操作,该数量一般与本机的cpu核数相一致为最佳spark-shell --master local[2]
相关参数
o1.参数列表获取方式:spark-shell --help
o2.其参数非常多,但由于该方式主要是简单学习使用,故其参数使用极少,故不做详解。
使用示例介绍
o交互式入口
o构建一个scala列表,并输出
o通过scala列表,构造一个rdd,并进行基本操作
o通过本地文本文件构建rdd,并进行基本操作
o通过hdfs文本文件构建rdd,并进行基本操作
o对rdd进行字符串过滤操作
o对rdd进行求最大值操作
o对输入进行wodcount计算-无排序
o对输入进行wodcount计算-按词频降序排列输出
2、spark-submit
交互方式定位
o最常用的通过程序脚本,提交相关的代码、依赖等来操作spark作业的方式。
启动方式
ospark-submit提交任务的模板
spark-submit
–class
–master
–jars jar_list_by_comma
–conf =
… # other options
[application-arguments]
spark-submit 详细参数说明
参数名 参数说明
–master master 的地址,提交任务到哪里执行,例如 spark://host:port, yarn, local
–deploy-mode 在本地 (client) 启动 driver 或在 cluster 上启动,默认是 client
–class 应用程序的主类,仅针对 java 或 scala 应用
–name 应用程序的名称
–jars 用逗号分隔的本地jar 包,设置后,这些 jar 将包含在 driver 和 executor 的 classpath 下
–packages 包含在driver 和executor 的 classpath 中的 jar 的 maven 坐标
–exclude-packages 为了避免冲突 而指定不包含的 package
–repositories 远程 repository
–conf PROP=VALUE 指定 spark 配置属性的值,
例如 -conf spark.executor.extraJavaOptions="-XX:MaxPermSize=256m"
–properties-file 加载的配置文件,默认为 conf/spark-defaults.conf
–driver-memory Driver内存,默认 1G
–driver-java-options 传给 driver 的额外的 Java 选项
–driver-library-path 传给 driver 的额外的库路径
–driver-class-path 传给 driver 的额外的类路径
–driver-cores Driver 的核数,默认是1。在 yarn 或者 standalone 下使用
–executor-memory 每个 executor 的内存,默认是1G
–total-executor-cores 所有 executor 总共的核数。仅仅在 mesos 或者 standalone 下使用
–num-executors 启动的 executor 数量。默认为2。在 yarn 下使用
–executor-core 每个 executor 的核数。在yarn或者standalone下使用
关于–master取值的特别说明
local 本地worker线程中运行spark,完全没有并行
local[K] 在本地work线程中启动K个线程运行spark
local[*] 启动与本地work机器的core个数相同的线程数来运行spark
spark://HOST:PORT 连接指定的standalone集群的master,
默认7077端口
mesos://HOST:PORT 连接到mesos集群,国内用的极少
yarn 使用yarn的cluster或者yarn的client模式连接。取决于–deploy-mode参数,由deploy-mode的取值为client或是cluster来最终决定。
也可以用yarn-client或是yarn-cluster进行二合一参数使用,保留–master去掉—deploy-mode参数亦可。
–master yarn-client,相当于—master yarn –deploy-mode client的二合一
3、java实现spark wordcount示例
3.1 开发与测试环境准备
maven pom配置
o配置项
eclipse-jee版
spark-1.6.2
jdk1.7.x
log4j
opom配置模板
4.0.0
study
spark_study
0.1
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
import java.util.Arrays;
import java.util.List;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
/**
- java版spark wordcount实现
- @author zel
- @company 天亮教育
*/
public class JavaWordCount {
public static void main(String[] args) throws Exception {
// spark conf参数对象化
SparkConf sparkConf = new SparkConf().setAppName("JavaWordCount");
// spark运行模式设置
// sparkConf.setMaster("yarn-client");
sparkConf.setMaster("local");
// 通过spark conf构建spark上下文对象
JavaSparkContext ctx = new JavaSparkContext(sparkConf);
// 利用 textFile 接口从文件系统中读入指定的文件,返回一个 RDD 实例对象。
// RDD 的初始创建都是由 SparkContext 来负责的,将内存中的集合或者外部文件系统作为输入源
String path = "";
if (args == null || args.length == 0) {
path = "file:D:/temp/input.txt";
} else {
path = args[0];
}
// 将文件内容转化成一个rdd集合对象,内部元素为string类型,即一行一个string类型的对象
JavaRDD<String> lines = ctx.textFile(path);
// 对lines集合按空白符分隔后,做flatmap操作,形成一个统一的单词rdd集合对象
JavaRDD<String> words = lines
.flatMap(new FlatMapFunction<String, String>() {
private static final long serialVersionUID = 1L;
public Iterable<String> call(String s) {
return Arrays.asList(s.split("\\s+"));
}
});
// 对象words集合对象做kv化处理,形成<word,freq>结构,实际是按<word,1>结构
JavaPairRDD<String, Integer> ones = words
.mapToPair(new PairFunction<String, String, Integer>() {
private static final long serialVersionUID = 1L;
public Tuple2<String, Integer> call(String s) {
return new Tuple2<String, Integer>(s, 1);
}
});
// 对象ones集合做reduceByKey操作,即为group by key操作,相同key的做freq加和操作
JavaPairRDD<String, Integer> counts = ones
.reduceByKey(new Function2<Integer, Integer, Integer>() {
private static final long serialVersionUID = 1L;
public Integer call(Integer i1, Integer i2) {
return i1 + i2;
}
});
// 将counts结果rdd对象最终以ArrayList形式返回
List<Tuple2<String, Integer>> output = counts.collect();
// 将List对象遍历输出
for (Tuple2<String, Integer> tuple : output) {
System.out.println(tuple._1() + ":" + tuple._2());
}
// 该spark上下文对象的stop操作,达到停止该spark任务的作用
ctx.stop();
}
}
3.3 代码运行
本地方式-local-开发环境
o直接在主类中,run as application即可
linux本地方式-local-生产环境
o开发环境打包:跟之前的maven打包完全一致
o编写Shell运行脚本
注意修改代码中的setMaster代码,将之前代码设置注释掉
#! /bin/sh
配置成YARN配置文件存放目录
export HADOOP_CONF_DIR=/usr/hdp/2.5.3.0-37/hadoop/conf
SPARK_JAR=/usr/hdp/2.5.3.0-37/spark/lib/spark-assembly-1.6.2.2.5.3.0-37-hadoop2.7.3.2.5.3.0-37.jar
spark-submit
–class com.tl.job003.spark.demo.JavaWordCount
–master local
–driver-memory 512m
–executor-memory 512m
–num-executors 2
–jars $SPARK_JAR
/home/spark/TestFirst/spark_test/script_demo/spark_study.jar
file:home/spark/TestFirst/spark_test/script_demo/input.txt
#hdfs://sc-master-v2:8020/tmp/spark/input.txt
o输出效果
集群方式
oyarn-client
注意修改代码中的setMaster代码,将之前代码设置注释掉
#! /bin/sh
配置成YARN配置文件存放目录
export HADOOP_CONF_DIR=/usr/hdp/2.5.3.0-37/hadoop/conf
SPARK_JAR=/usr/hdp/2.5.3.0-37/spark/lib/spark-assembly-1.6.2.2.5.3.0-37-hadoop2.7.3.2.5.3.0-37.jar
/usr/hdp/2.5.3.0-37/spark/bin/spark-submit
–class com.tl.job003.spark.demo.JavaWordCount
–master yarn-client \ #此处有变化
–driver-memory 512m
–executor-memory 512m
–num-executors 2
–jars $SPARK_JAR
/home/spark/TestFirst/spark_test/script_demo/spark_study.jar
file:home/spark/TestFirst/spark_test/script_demo/input.txt
#hdfs://sc-master-v2:8020/tmp/spark/input.txt
o运行效果
注意输入路径,不能再为本地路径输入,应改为hdfs等分布式文件系统的路径
yarn-client等于–master设置成yarn,deploy-mode设置成client
yarn-cluster
#! /bin/sh
配置成YARN配置文件存放目录
export HADOOP_CONF_DIR=/usr/hdp/2.5.3.0-37/hadoop/conf
SPARK_JAR=/usr/hdp/2.5.3.0-37/spark/lib/spark-assembly-1.6.2.2.5.3.0-37-hadoop2.7.3.2.5.3.0-37.jar
/usr/hdp/2.5.3.0-37/spark/bin/spark-submit
–class com.tl.job003.spark.demo.JavaWordCount
–master yarn-cluster \ #此处有变化
–driver-memory 512m
–executor-memory 512m
–num-executors 2
–jars $SPARK_JAR
/home/spark/TestFirst/spark_test/script_demo/spark_study.jar
file:home/spark/TestFirst/spark_test/script_demo/input.txt
#hdfs://sc-master-v2:8020/tmp/spark/input.txt
运行效果
o注意输入路径,不能再为本地路径输入,应改为hdfs等分布式文件系统的路径
oyarn-master等于–master设置成yarn,–deploy-mode设置成master
4、scala实现spark wordcount示例
spark1.5.x及之前版本,比较方便通过祼eclipse直接开发及导出运行。
spark1.6.x及以上版本依赖增多,直接开发已非常不方便,强烈建议依赖于scala项目构建工具sbt进行开发与打包布署。

















 2276
2276

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









