







文章目录
MEGFormer: Enhancing Speech Decoding from Brain Activity Through Extended Semantic Representations
摘要
背景: 近年来,多个研究利用非侵入性技术探索从大脑活动解码语音。然而,由于解码质量仍然不足,该任务在实际应用中仍面临挑战。一个有效的解码方案不仅可以促进脑机接口(BCI)的发展,为言语障碍患者提供沟通恢复的可能性,还能为理解大脑如何处理语音和声音提供基础性见解。
目的: 本研究旨在改进基于脑磁图(MEG)的语音解码方法,以提升解码准确性,并增强对感知语音的建模能力。
方法: 采用对比学习训练的自监督模型,以零样本(zero-shot)方式匹配MEG信号与音频片段。在此基础上,引入了一种基于CNN-Transformer的新型架构,以优化感知语音的解码能力。
结果: 通过所提出的改进方法,感知语音解码的准确率在公开数据集上由69%提升至83%,由67%提升至70%。值得注意的是,该方法在包含语义信息的较长语音片段上取得了最显著的性能提升,而对于短时的音素和声音片段提升相对较小。代码已公开,链接为 https://github.com/maryjis/MEGformer。
方法
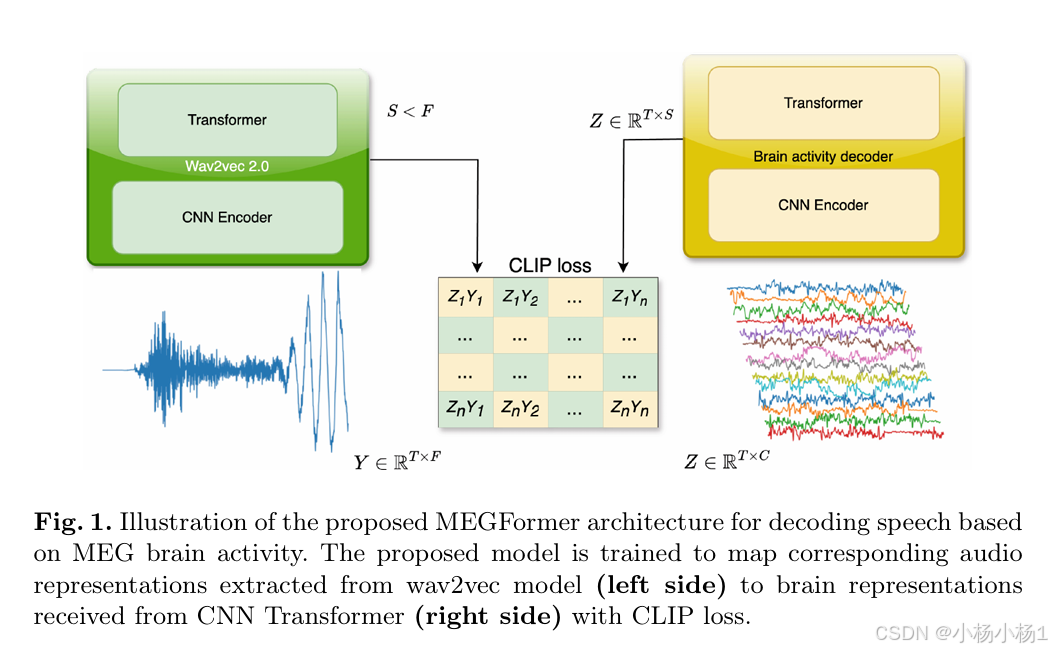
图 1. 所提出的模型经过训练,将从 wav2vec 模型(左侧)提取的相应音频表示映射到从 CNN Transformer(右侧)接收到的具有 CLIP 损失的大脑表示。
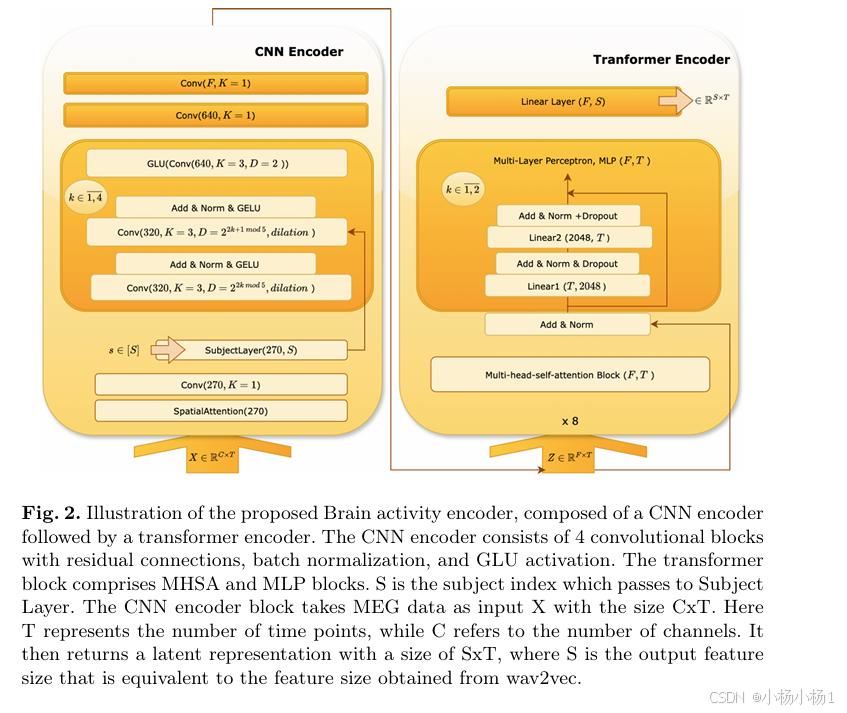
Fig. 2 展示了所提出的大脑活动编码器的示意图,该编码器由 CNN 编码器 和 Transformer 编码器 组成。CNN 编码器由四个 带残差连接、批量归一化(Batch Normalization) 和 GLU 激活函数 的卷积模块构成,而 Transformer 编码器包括 多头自注意力(MHSA) 和 MLP 模块。
在该框架中,CNN 编码器以 脑磁图(MEG)数据 (X) 作为输入,数据尺寸为 (C x T),其中 (T) 表示时间点的数量,(C) 代表通道数。经过 CNN 编码器处理后,模型返回一个 潜在表示,其尺寸为 (S x T),其中 (S) 为输出特征维度,与 wav2vec 提取的特征尺寸一致。此外,受试者索引 (S) 进一步输入至 受试者层(Subject Layer) 进行处理。
实验结果
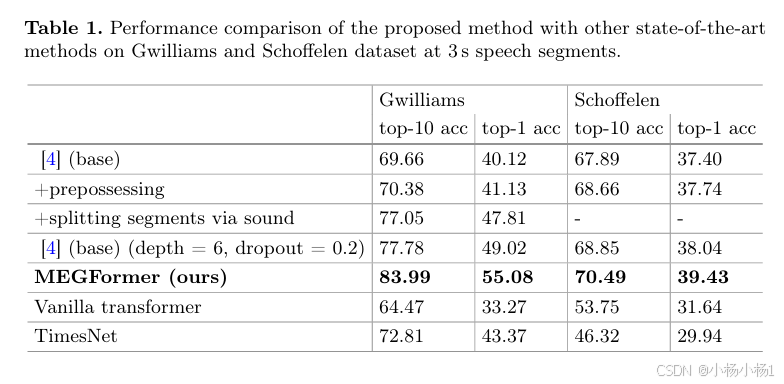
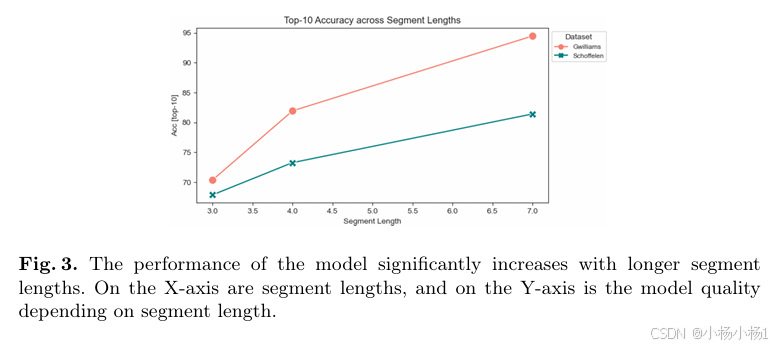


















 1733
1733

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











