






主要来源:《卷积神经网络研究综述》周飞燕等
会在这个框架上慢慢补充。
一.CNN基本知识
1.神经元
神经元是人工神经网络的基本处理单元,一般是多输入单输出的单元.
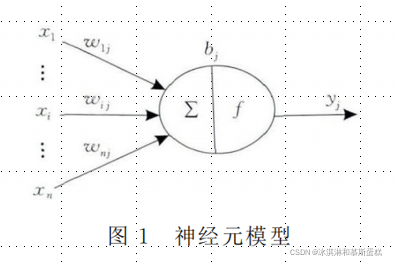
输入与输出之间的对应关系
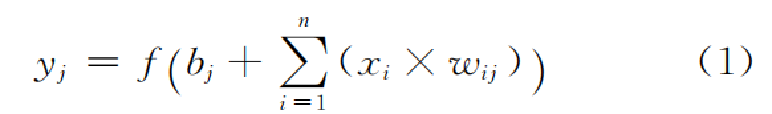 其中:
其中:
xi : 输入信号;n个输入信号同时输入神经元j.
wij : 输入信号xi与神经元j连接的权重值;
bj : 神经元的内部状态即偏置值;
yj : 为神经元的输出.
f(·)为激励函数,其可以有很多种选择,可 以 是线性纠正函数 (ReLu)、sigmoid函数、tanh(x)函数、径向基函数等
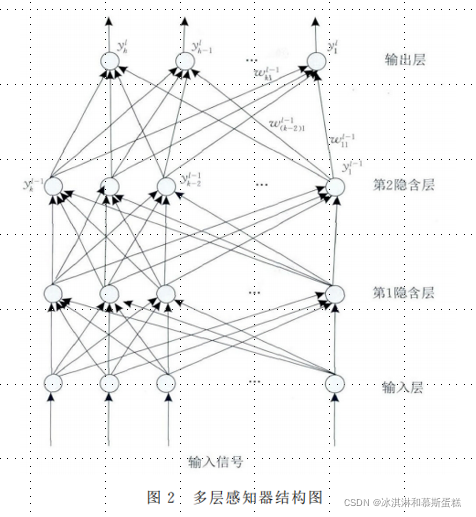
2.多层感知器(Multilayer Perceptron, MLP)
由输入层、隐含层 及输出层构成,可以解决单层感知器不能解决的线性不可分问题。
输入层神经元接收输入信号, 隐含层和输出层的每一个神经元与之相邻层的所有神经元连接, 即全连接。
每个连接都有一个连接权值.隐含层和输出层中每一个神经元的输入为前一层所有神经元输出值的加权和。

3.CNN基本结构
CNN的基本结构由输入层、卷积层 (convolutional layer) 、池化层 (pooling layer, 也称为取样层) 、全连接层及输出层构成.
卷积层和池化层一般会取若干个, 采用卷积层和池化层交替设置, 即一个卷积层连接一个池化层, 池化层后再连接一个卷积层, 依此类推.
由于卷积层中输出特征面的每个神经元与其输入进行局部连接, 并通过对应的连接权值与局部输入进行加权求和再加上偏置值, 得到该神经元输入值, 该过程等同于卷积过程, CNN也由此而得名
4.卷积层
CNN的卷积层由多个特征面 (Feature Map) 组成, 每个特征面由多个神经元组成, 它的每一个神经元通过卷积核与上一层特征面的局部区域相连.
卷积核是一个权值矩阵 (如对于二维图像而言可为3×3或5×5矩阵)
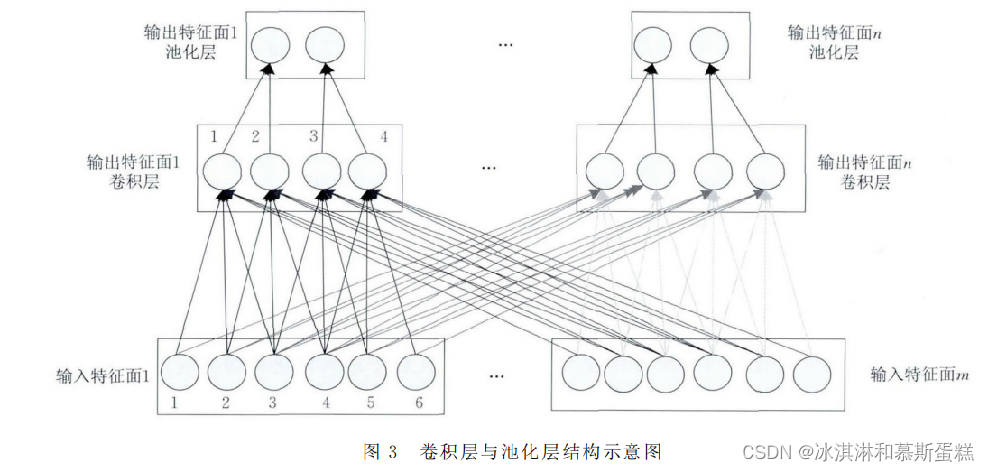
图3所示为一维CNN的卷积层和池化层结构示意图, 最顶层为池化层, 中间层为卷积层, 最底层为卷积层的输入层.
在CNN结构中, 深度越深、特征面数目越多, 则网络能够表示的特征空间也就越大、网络学习能力也越强, 然而也会使网络的计算更复杂, 极易出现过拟合的现象。
因而, 在实际应用中应适当选取网络深度、特征面数目、卷积核的大小及卷积时滑动的步长, 以使在训练能够获得一个好的模型的同时还能减少训练时间.
5.池化层
池化层紧跟在卷积层之后, 同样由多个特征面组成, 它的每一个特征面唯一对应于其上一层的一个特征面, 不会改变特征面的个数。
卷积层是池化层的输入层, 卷积层的一个特征面与池化层中的一个特征面唯一对应, 且池化层的神经元也与其输入层的局部接受域相连, 不同神经元局部接受域不重叠.
池化层旨在通过降低特征面的分辨率来获得具有空间不变性的特征,起到二次提取特征的作用, 它的每个神经元对局部接受域进行池化操作。
常用的池化方法有最大池化即取局部接受域中值最大的点、均值池化即对局部接受域中的所有值求均值、随机池化.
6.全连接层
在CNN结构中, 经多个卷积层和池化层后, 连接着1个或1个以上的全连接层,全连接层中的每个神经元与其前一层的所有神经元进行全连接.
全连接层可以整合卷积层或者池化层中具有类别区分性的局部信息.为了提升CNN网络性能, 全连接层每个神经元的激励函数一般采用ReLU函数。
最后一层全连接层的输出值被传递给一个输出层, 可以采用softmax逻辑回归 (softmax regression) 进行分类, 该层也可称为softmax层
7.特征面
特征面数目作为CNN的一个重要参数,通常根据实际应用设置。
如果特征面个数过少, 可能会使一些有利于网络学习的特征被忽略掉;
如果特征面个数过多, 可训练参数个数及网络训练时间也会增加, 这同样不利于学习网络模型.
目前, 通常采用的是人工设置方法, 进行实验并观察所得训练模型的分类性能, 最终根据网络训练时间和分类性能来选取特征面数目.
二.改进算法
1.网中网(Network in Network, NIN)结构
该模型使用微型神经网络 (micro neural network) 代替传统CNN的卷积过程。同时还采用全局平均池化层来替换传统CNN的全连接层, 它可以增强神经网络的表示能力.微神经网络主要是采用MLP模型。
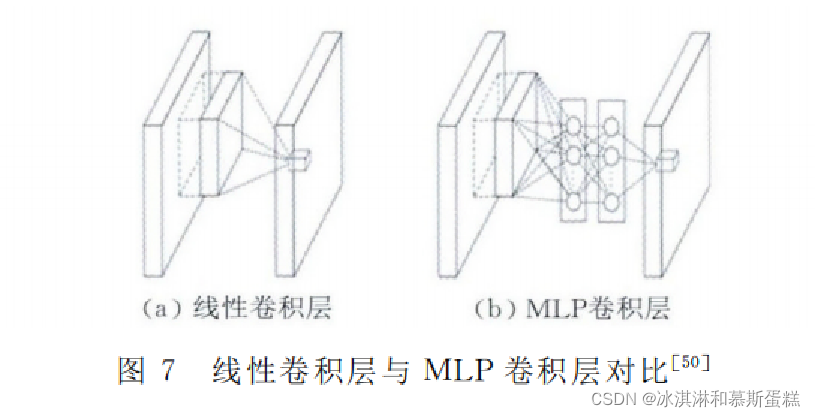
要点:
1.NIN通过在输入中滑动微型神经网络得到卷积层的特征面.与卷积的权值共享类似, MLP对同一个特征面的所有局部感受野也共享, 即对于同一个特征面MLP相同。
2.NIN模型采用全局平均池化代替原来的全连接层, 使模型的参数大大减少。
3.全局平均池化可看成是一个结构性的正则化算子 (structural regularizer) , 它可以增强特征面与类别的一致性.在全局平均池化层中没有需要优化的参数, 因此能够避免过拟合。
2.空间变换网络( STNs)
问题:CNN会受到数据在空间上多样性的影响.
解决:Jaderberg等人采用一种新的可学习模块—空间变换网络
具体实现:该模块由3个部分组成:本地化网络 、网格生成器及采样器 .
优点:
1.STNs可用于输入层, 也可插入到卷积层或者其它层的后面, 不需要改变原CNN模型的内部结构。
2.STNs能够自适应地对数据进行空间变换和对齐, 使得CNN模型对平移、缩放、旋转或者其它变换等保持不变性.
3.速度快
三.训练方法和开源工具
有监督学习训练:CNN通过BP算法进行有监督训练, 也需经过信息的正向传播和误差的反向传播两个阶段.
开始前:需要小随机数对网络中所有的权值和偏置值进行随机初始化。
目的:使用“小随机数”以保证网络不会因为权过大而进入饱和状态, 从而导致训练失败;“不同”用来保证网络可正常地学习训练, 如果使用相同的数值初始化权矩阵, 那么网络将没有学习的能力
无监督训练:出了一种只需调整一个超参数的无监督学习算法—稀疏滤波 (sparse filtering) .稀疏滤波只优化一个简单的代价函数—L2范数稀疏约束特征。
特点:样本分布稀疏性、高分散性、存在稀疏
具体操作:先用稀疏滤波训练得到一个单层的归一化特征, 然后将它们作为第2层的输入来训练第2层, 依此类推.
显性训练:传统的神经网络训练方法,
特点:训练过程中有一部分样本不参与CNN的误差反向传播过程, 将该部分样本称为校验集。在显性训练过程中, 为了防止发生过拟合现象, 每隔一定时间就用当前分类模型测试校验样本, 这也表明了校验集中样本选取的好坏会影响最终分类模型的性能.
在CNN分类模型中, 为了增加训练样本数, 可采用“平移起始点”和“加躁”这两种技术。 只要对类别的最终判断没有影响, 也可通过加躁处理或者对原始数据做某种扭曲变换从而达到增加训练样本的目的.
隐性训练:
和显性的区别:怎样检验当前的分类模型.
特点:从整个训练集中取出一小部分样本用于校验:用于校验的这部分样本不做加躁处理, 并且对于每一个样本都截取起始点固定的子段.
Caffe、Torch 及Theano

四.实际应用
图像分类:ReLU+dropout(AlexNet)、GoogLeNet、VGG模型、SPP-net
人脸识别:DeepFace、DeepID2+、DeepID3、FaceNet
音频检索:结合隐马尔科夫建立CNN模型
ECGECG-CNN、导联卷积神经网络 (Lead Convolutional Neural Network, LCNN) 、

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









