







 这篇博客讲述了编译原理的学习过程,主要涵盖词法分析、语法分析、语义分析与中间代码生成等阶段。通过类比自然语言翻译,解释了编译程序如何将高级语言转化为计算机可执行的代码,并提到了编译程序的结构,包括编译前端与后端的区分。
这篇博客讲述了编译原理的学习过程,主要涵盖词法分析、语法分析、语义分析与中间代码生成等阶段。通过类比自然语言翻译,解释了编译程序如何将高级语言转化为计算机可执行的代码,并提到了编译程序的结构,包括编译前端与后端的区分。
上一篇:每天两小时学习编译原理——一个学期的第二天,希望能坚持长久✨
下一篇:每天两小时学习编译原理——一个学期的第四天,希望能坚持长久✨
在了解乐基本概念和学习意义之后,我们接下来对编译程序做一个概要介绍。其实包含编译程序的基本工作过程,结构还有常用的生成方法。

编译程序过程
首先咱们看一下编译程序的基本过程。
那其实,编译程序的过程与我们进行自然语言的翻译过程很是相似,那最适合的一个栗子就是翻译的过程,我们讲一个英文句子翻译成中文。

我来给大家读一下啊,
则 抗排雷儿 砍 穿丝雷塔 饿 脯肉格瑞姆 腐乳昂木 缫丝 兰桂芝 吐 他给儿他 兰桂芝。
那真正的翻译成中文就是右边的那句话。
那我们其实就是经过下面的过程阶段才一步一步的将英语翻译成了中文。
那其实我们编译程序的工作过程也经过了5个阶段。
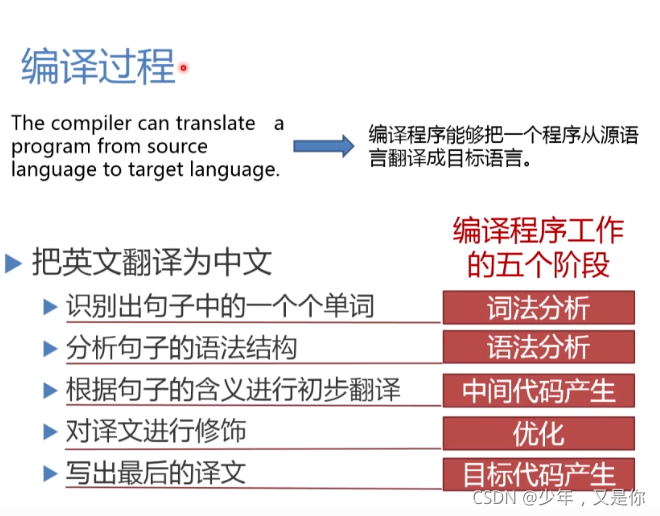
词法分析
接下来我们一个一个进行分析,首先来了解词法分析阶段。
 我们在进行词法分析的时候呢,依循的规则是词法规则,就是上面的构词规则。比如,我们在学习某个程序设计语言时,首先改语言的单词构成规则。例如,一般的程序设计语言会要求用标识符定义变量名,而标识符是明确规定的以字母开头的字符串。那在一些程序设计语言中还允许用户自定义整形常量,要求整形常量是有数字字符构成的字符串就是整形常量。那这些就是词法规则。编译程序就是根据这些规则对源程序的字符串进行扫描,识别出哪些字符串构成了标识符,常数。那前面的这些词法规则其实还都是用自然语言去描述的,那要是想让计算机理解这些规则,那就要有一个形式化的方法来描述,这是我们就可以利用有限自动机。那有限自动机这个知识点我们后面会接触到。
我们在进行词法分析的时候呢,依循的规则是词法规则,就是上面的构词规则。比如,我们在学习某个程序设计语言时,首先改语言的单词构成规则。例如,一般的程序设计语言会要求用标识符定义变量名,而标识符是明确规定的以字母开头的字符串。那在一些程序设计语言中还允许用户自定义整形常量,要求整形常量是有数字字符构成的字符串就是整形常量。那这些就是词法规则。编译程序就是根据这些规则对源程序的字符串进行扫描,识别出哪些字符串构成了标识符,常数。那前面的这些词法规则其实还都是用自然语言去描述的,那要是想让计算机理解这些规则,那就要有一个形式化的方法来描述,这是我们就可以利用有限自动机。那有限自动机这个知识点我们后面会接触到。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











