







 这篇博客回顾了编译原理的学习过程,重点介绍了正规表达式、正规集和有限自动机。讲解了正规式的等价性和性质,并通过实例解释了确定有限自动机(DFA)和非确定有限自动机(NFA)的区别。内容涵盖了词法分析器的自动生成方法和理论基础。
这篇博客回顾了编译原理的学习过程,重点介绍了正规表达式、正规集和有限自动机。讲解了正规式的等价性和性质,并通过实例解释了确定有限自动机(DFA)和非确定有限自动机(NFA)的区别。内容涵盖了词法分析器的自动生成方法和理论基础。
上一篇链接:每天两小时学习编译原理——一个学期的第六天,希望能坚持长久✨
词法分析后续
回顾
学习是一个循序渐进的过程,所以在之后的学习中每一次,都会将编译程序的总体框架复述一遍,来加深印象,明白我们这门学科的目的所在,如何去编写程序,其中的阶段有哪些。
如果感觉前面掌握的还可以的可直接跳转到正规表达式与有限自动机学习。
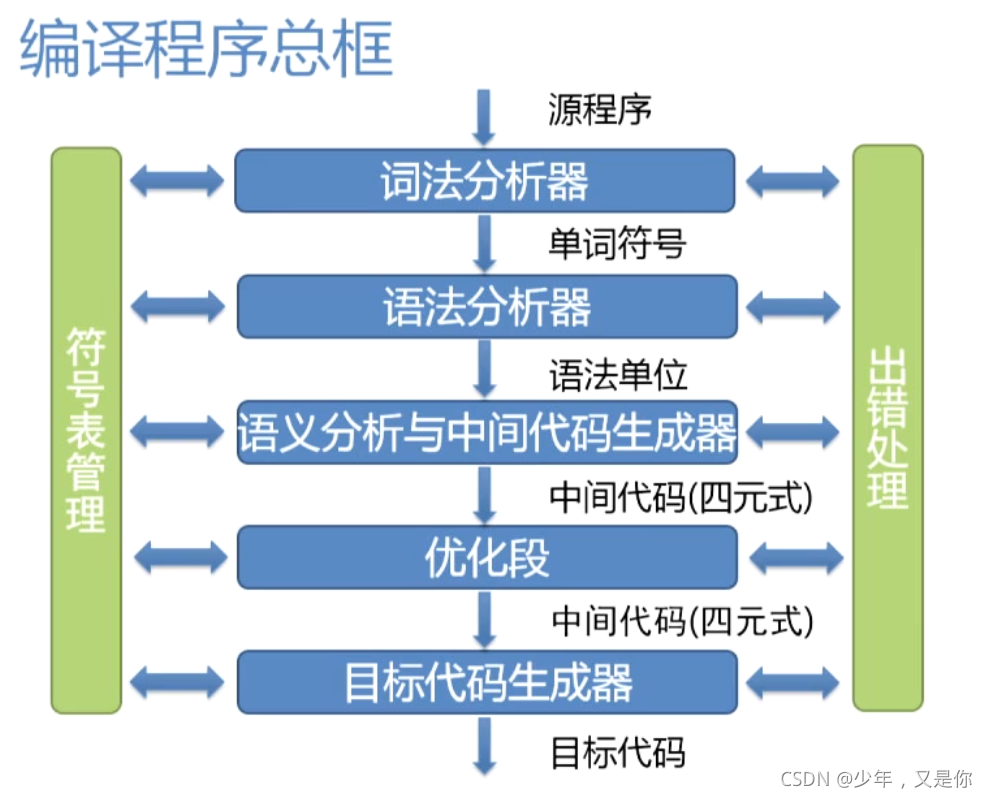
编译过程包括5个阶段,那每个阶段都由各个模块实现。编译程序的第一个阶段就是词法分析,完成词法分析的程序模块实现就是词法分析器,高级语言源程序首先经过词法分析器进行扫描,识别出单词符号,然后将单词符号输入到语法分析器以及后续的编译模块完成语法分析,语义分析,中间代码生成,优化,最后生成目标代码。
那上一问讲到,词法分析器的手工设计,编程实现词法分析器,其设计:

上一篇讲到将状态图代码一般化,由此产生一个想法:是否有自动的方法产生词法分析程序?
这个答案是肯定的,接下来我们就探讨自动产生词法分析程序的方法。
正规表达式与有限自动机
正规表达式与有限自动机理论是词法分析器自动生成方法的基础,从接下来这一节的学习中可以看到词法分析器的自动生成是计算机科学中经典理论和先进技术的完美结合的典范。正是有了正规表达式与有限自动机理论,在我们设计词法分析器时就不需要手工编写大量程序,可以自动生成词法分析器。下面,我们先学习对词法规则形式化描述的几
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











