









5.爬虫数据存储
学习目的:从网站中能够正确读取资源并存储,包括——Excel的存储,Mysql的存储,本地文件的存储;
拓展:
①了解输入流和输出流的差别
②缓冲流的作用是什么
③字节和字符的差别
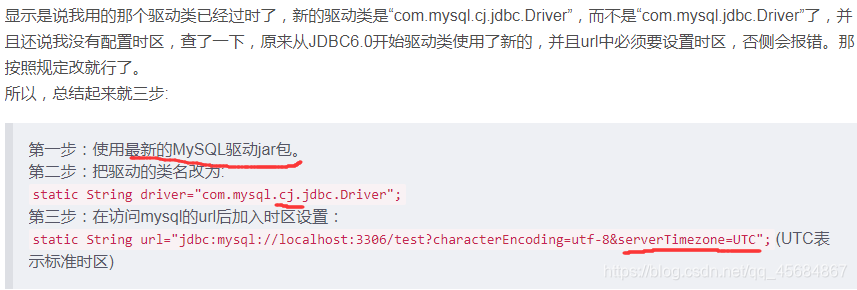
个人遇错集
Mysql 数据存储
mysql驱动jar包 版本5.1.32(太低)
文章目录
5.1 输入流、输出流
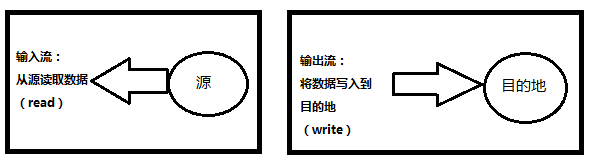
5.1.1 简介
输入流:读取一个字节序列对象。(理解成读到内存)
输出流:写入一个字节序列对象。(理解成写入到磁盘)
5.1.2 File类
介绍:File类主要用来获取文件自身的属性信息——例如:文件所在目录,文件名,文件的长度等等。(不涉及文件具体–读写操作)
一、创建File对象方法
创建File对象方法
| 方法 | 说明 |
|---|---|
| File(String pathname) | 路径>创建File对象 |
| File(String parent,String child) | 目录和子文件>创建File对象 |
| File(File parent,String child) | 父File对象和子文件>创建File对象 |
创建实例:
//路径>创建File对象
File file3 = new File("data/1.txt");
// 目录和子文件>创建File对象
File file1 = new File("data","1.txt");
//父File对象和子文件>创建File对象
File file2 = new File(new File("data"),"1.txt");
二、File类基本操作方法
File类基本操作方法
| 方法 | 说明 |
|---|---|
| String getName() | 获取文件名 |
| String getParent() | 获取文件的父目录 |
| File getParentFile() | 获取文件的父目录,返回File对象 |
| String getPath() | 获取文件路径 |
| boolean isAbsolute() | 是否为绝对路径 |
| String getAbsolute() | 获取绝对路径 |
| boolean canRead() | 文件是否可读 |
| boolean exists() | 文件是否存在 |
| boolean isDirectory() | 路径是否为一个目录 |
| boolean isFile() | 是否为文件,而非目录 |
| long length() | 获取文件长度 |
| String[ ] list() | 用字符串形式返回目录下的所有文件 |
| File[ ] listFiles() | 用File 对象返回目录下的所有文件 |
| String[ ] list(FilenameFilter filter) | 用字符串形式返回目录下指定类型的文件 |
5.1.3 文件字节流
介绍:文件字节流主要作用于:读写字节。
适用范围: 图片、PDF、压缩和音频等文件。
!适用范围: Unicode字符,包含汉字的文件会出现乱码。
一、InputStream、OutputStream
只能读写单独的字节或字节数组,所以有子类额外实现功能
子类:
InputStream类中有关 读字节、关闭流的方法
| 方法 | 说明 |
|---|---|
| abstract int read() | 按顺序读入一字节,并返回改字节。若到达源末尾则返回 -1 |
| int read(byte b[ ]) | 读入一字节数组,返回读入的字节数。若到达源末尾则返回 -1 |
| int read(byte b[ ],int off,int len) | 读入一字节数组,返回读入的字节数。off 表示首字节在数组b中的偏移量,len表示读入字节的最大数量。若到达源末尾则返回 -1 |
| void close() | 关闭输入流 |
OutputStream类中有关 写字节、关闭流的方法
| 方法 | 说明 |
|---|---|
| abstract void write(int b) | 写入一字节 |
| void write(byte b[ ]) | 写入一字节数组 |
| void write(byte b[ ],int off,int len) | 从给定字节数组中off 处,写len字节到文件 |
| void close() | 关闭输出流 |
二、FileInputStream、FileOutputStream(简单IO流)
FileInputStream类中创建对象的方法
| 方法 | 说明 |
|---|---|
| FileInputStream(String name) | 文件名》创建FileInputStream对象 |
| FileInputStream(File file) | File对象》创建FileInputStream对象 |
FileOutputStream类中创建对象的方法
| 方法 | 说明 |
|---|---|
| FileOutputStream(String name) | 文件名》创建FileOutputStream对象 |
| FileOutputStream(File file) | File对象》创建FileOutputStream对象 |
操作实例:
package com.xp.climb.climb05.file;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
public class StreamTest1 {
public static void main(String[] args) throws IOException {
//-------FileInputStream的两种构造方法
//FileInputStream inputStream = new FileInputStream("data/1.txt");
FileInputStream inputStream = new FileInputStream(new File("D:\\IdeaWork\\爬虫\\data\\1.txt"));
//-------FileOutputStream的两种构造方法
FileOutputStream outputStream = new FileOutputStream("D:\\IdeaWork\\爬虫\\data\\out1.txt");
// FileOutputStream outputStream = new FileOutputStream(new File("data/out.txt"));
int temp;
while ((temp = inputStream.read()) != -1) {
System.out.print((char)temp);
outputStream.write(temp);
}
outputStream.close();
inputStream.close();
}
}
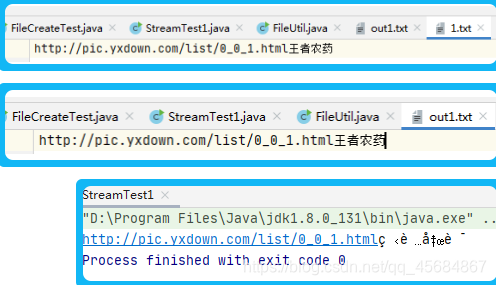
结果:out1正确写入1的内容,但是控制台的中文出现乱码
5.1.4 文件字符流
介绍:文件字符流主要作用于:读写字符。
一、Reader、Writer
子类:
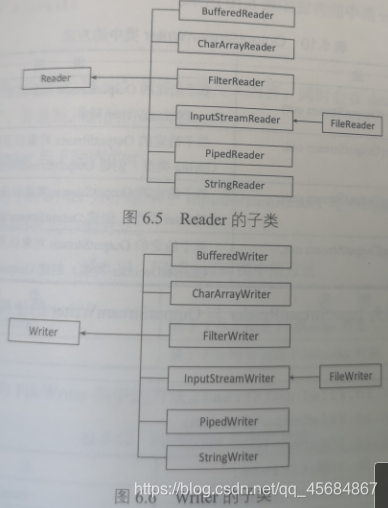
Reader类中的方法
| 方法 | 说明 |
|---|---|
| int read() | 读取一字符,返回Unicode字符值(0~65335的整数),若到达源尾 返回-1 |
| int read(char cbuf[ ]) | 最多读取b.length字符到数组中,若到达源尾 返回-1 |
| int read(char cbuf[ ],int off,int len) | 读取len字符并存在到数组中,off为首字符的数组中的位置,返回实际读取字符的数目,若到达源尾 返回-1 |
| int read(java.nio.CharBuffer target) | 将字符先添加到缓冲区,然后读取 |
| void close() | 关闭流 |
Writer类中的方法
| 方法 | 说明 |
|---|---|
| void write(int c) | 向文件写入一字符 |
| void write(char cbuf[ ]) | 向文件写入一字符数组 |
| void write(char cbuf[ ],int off,int len) | 从给定字节数组中off 处开始,读取len字符到文件 |
| void write(String str) | 向文件写入字符串 |
| void write(String str,int off,int len) | 从字符串中off 处开始,读取len字符到文件 |
| Writer append(char c) | 向文件添加单字符 |
| Writer append(CharSequence csq) | 向文件添加字符序列 |
| Writer append(CharSequence csq,int start,int end) | 从字符序列中off处开始,读取len字符到文件 |
| void close() | 关闭流 |
二、InputStreamReader、OutputStreamWriter
介绍:
InputStreamReader(Reader子类):字节流通向字符流 的桥梁
OutputStreamWriter(Writer子类):字符流通向字节流 的桥梁
InputStreamReader类中的方法
| 方法 | 说明 |
|---|---|
| InputStreamReader(InputStream in) | 基于给定的InputStream对象创建InputStreamReader对象 |
| InputStreamReader(InputStream in,String charsetName) | 基于给定的InputStream对象以及指定的编码方式-------(String类型)创建InputStreamReader对象 |
| InputStreamReader(InputStream in,Charset cs) | 基于给定的InputStream对象以及指定的编码方式-------(Charset 类型)创建InputStreamReader对象 |
| InputStreamReader(InputStream in,CharsetDecoder des) | 基于给定的InputStream对象以及指定的编码方式-------(CharsetDecoder 类型)创建InputStreamReader对象 |
此处省略OutputStreamWriter的,因为类方法类似于InputStreamReader的,参考即可。例如:OutputStreamWriter(OutputStream in)
操作实例
package com.xp.climb.climb05.charstream.test;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
public class IrOwTest {
public static void main(String[] args) throws IOException {
//读取文件的数据
InputStream in = new FileInputStream("D:\\IdeaWork\\爬虫\\data\\3.txt");
//将字节流向字符流的转换
InputStreamReader isr = new InputStreamReader(in);
//写入新文件
FileOutputStream fos = new FileOutputStream("D:\\IdeaWork\\爬虫\\data\\3osw.txt");
OutputStreamWriter osw = new OutputStreamWriter(fos,"utf-8");
int temp;
//读取与写入操作
while((temp = isr.read()) != -1){
System.out.print((char)temp);
osw.write(temp);
}
osw.write("\njava网络爬虫");
osw.append("\n很有意思");
//流的关闭
osw.close();
isr.close();
}
}
结果:3正确写入3osw,而且控制台的中文没有乱码(字符流)
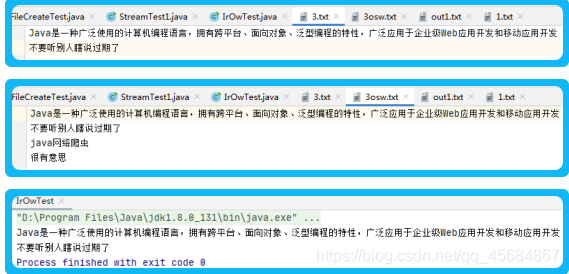
三、FileReader、FileWriter
介绍:
FileReader(InputStreamReader子类)
FileWriter(OutputStreamWriter子类)
FileReader类中创建对象的方法
| 方法 | 说明 |
|---|---|
| FileReader(String fileName) | 文件名》创建FileReader对象 |
| FileReader(File file) | File对象》创建FileReader对象 |
FileWriter类中创建对象的方法
| 方法 | 说明 |
|---|---|
| FileWriter(String fileName) | 文件名》创建FileWriter对象 |
| FileWriter(File file) | File对象》创建FileWriter对象 |
| FileWriter(String fileName,boolean append) | 文件名》创建FileWriter对象,append–true表示追加,false(默认)为覆盖 |
| FileWriter(File file,boolean append) | File对象》创建FileWriter对象,append–true表示追加,false(默认)为覆盖 |
操作实例
package com.xp.climb.climb05.charstream.test;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
public class FrFWTest {
public static void main(String[] args) throws IOException {
//两种文件字符输入流创建方式
FileReader fileReader = new FileReader("D:\\IdeaWork\\爬虫\\data/3.txt");
//FileReader fileReader = new FileReader(new File("data/1.txt"));
//两种文件字符输出流创建方式
FileWriter fileWriter = new FileWriter("D:\\IdeaWork\\爬虫\\data\\outtest.txt");
//FileWriter fileWriter = new FileWriter(new File("data/outtest.txt",ture));
int temp;
while ((temp = fileReader.read()) != -1) {
System.out.print((char)temp);
fileWriter.write((char)temp);
}
fileWriter.write("我爱网络爬虫", 2, 3);
//StringBuilder实现了CharSequence
fileWriter.append(new StringBuilder("\n轻松学习java"));
fileWriter.close();
fileReader.close();
}
}
结果:3正确写入outtest;
fileWriter.write(“我爱网络爬虫”, 2, 3);//从2开始读3个字符到 目的地
fileWriter.append(new StringBuilder("\n轻松学习java"));//添加,详细看Writer类
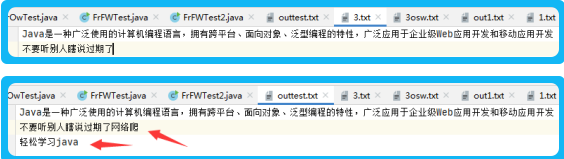
若再使用:FileWriter fileWriter = new FileWriter(new File(“data/outtest.txt”,ture));
true,表示追加。即:原本不变,新入读的追加到后面。

5.1.5 缓冲流
介绍:
普通字节、字符流都是无缓冲的输入输出流,每次读写都设计对磁盘的操作,效率低。为了增强文件的读写能力,java.io包提供更高级的流——缓冲流。
一、BufferedInputStream 和 BufferedOutputStream
介绍:
BufferedInputStream(FilterInputStream子类) 和 BufferedOutputStream(FilterOutputStream子类)是缓冲流中的字节流。
适用范围:网络爬虫在采集图片、PDF、视频和压缩文件时
BufferedInputStream 类中的方法
| 方法 | 说明 |
|---|---|
| BufferedInputStream(InputStream in) | 创建默认大小缓冲区的缓冲字节输入流 |
| BufferedInputStream(InputStream in,int size) | 创建指定大小缓冲区的缓冲字节输入流 |
BufferedOutputStream类中的方法
| 方法 | 说明 |
|---|---|
| BufferedOutputStream(InputStream in) | 创建默认大小缓冲区的缓冲字节输出流 |
| BufferedOutputStream(InputStream in,int size) | 创建指定大小缓冲区的缓冲字节输出流 |
操作案例:
package com.xp.climb.climb05.buffer.test;
import java.io.BufferedInputStream;
import java.io.BufferedOutputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
public class BisBos {
public static void main(String[] args) throws IOException {
//创建File对象
File file = new File("D:\\IdeaWork\\爬虫\\data\\1.txt");
//创建BufferedInputStream对象
BufferedInputStream bin = new BufferedInputStream(
new FileInputStream(file), 512);
//创建BufferedOutputStream对象
BufferedOutputStream bos = new BufferedOutputStream(
new FileOutputStream("D:\\IdeaWork\\爬虫\\data\\1bos.txt"));
byte[] b=new byte[5]; //代表一次最多读取5个字节的内容
int length = 0; //代表实际读取的字节数
while( (length = bin.read( b ) )!= -1 ){ //每次读5个字节
System.out.println(new String(b));
//写入指定文件
bos.write(b, 0, length);
bos.write("\n".getBytes()); //写上换行符
}
//关闭流
bos.close();
bin.close();
}
}
结果:每次读5个字节,一个中文占2个字节,读取不当造成乱码
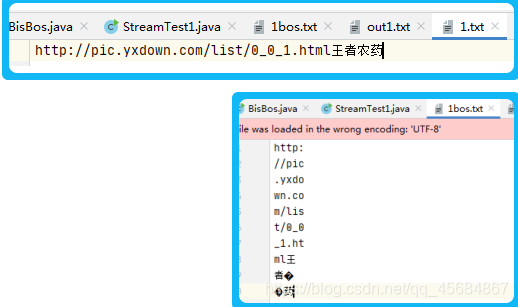
二、BufferedReader和 BufferedWriter
介绍:
BufferedReader(Reader子类):提供了按行读取字符串的方法,用来处理文本非常方便。
适用范围:文本数据的处理。
BufferedReader类中的方法
| 方法 | 说明 |
|---|---|
| BufferedReader(Reader in) | 创建默认大小缓冲区的缓冲字符输入流 |
| BufferedReader(Reader in,int sz) | 创建指定大小缓冲区的缓冲字符输入流 |
BufferedWriter类中的方法
| 方法 | 说明 |
|---|---|
| BufferedWriter(Reader in) | 创建默认大小缓冲区的缓冲字符输出流 |
| BufferedWriter(Reader in,int sz) | 创建指定大小缓冲区的缓冲字符输出流 |
操作案例:
package com.xp.climb.climb05.buffer.test;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.FileReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.util.HashMap;
import java.util.Map;
public class BufferedTest {
public static void main(String[] args) throws IOException {
/****** 文件读取第一种方式 ******/
File file = new File("D:\\IdeaWork\\爬虫\\data\\3.txt");
//FileReader读取文件
FileReader fileReader = new FileReader(file);
//根据FileReader创建缓冲流
BufferedReader bufferedReader = new BufferedReader(fileReader);
String s = null;
//按行读取
while ((s = bufferedReader.readLine())!=null) {
System.out.println(s);
}
//流关闭
bufferedReader.close();
fileReader.close();
/****** 文件读取第二种方式 ******/
//这里简写了,已成了一行。可以添加字符编码
BufferedReader reader = new BufferedReader( new InputStreamReader(
new FileInputStream(
new File( "D:\\IdeaWork\\爬虫\\data\\3.txt")),"utf-8"));
String s1=null;
while ((s1 = reader.readLine())!=null) {
System.out.println(s1);
}
//流关闭
reader.close();
/****** 文件写入第一种方式 ******/
/*File file1 = new File("data/bufferedout.txt","gbk");
FileOutputStream fileOutputStream = new FileOutputStream(file1);
OutputStreamWriter outputStreamWriter = new OutputStreamWriter(fileOutputStream);
BufferedWriter bufferedWriter1 = new BufferedWriter(outputStreamWriter);*/
/****** 文件写入快捷方式******/
BufferedWriter writer = new BufferedWriter( new OutputStreamWriter
( new FileOutputStream(
new File("D:\\IdeaWork\\爬虫\\data\\bufferedout.txt")),"gbk"));
Map<Integer,String> map = new HashMap<Integer,String>();
map.put(0, "http://pic.yxdown.com/list/2_0_2.html");
map.put(1, "http://pic.yxdown.com/list/2_0_3.html");
map.put(2, "http://pic.yxdown.com/list/2_0_4.html");
//map遍历数据
for( Integer key : map.keySet() ){
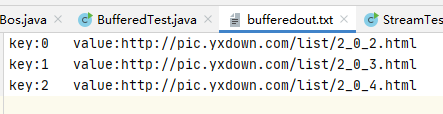
writer.append("key:"+key+"\tvalue:"+map.get(key));
writer.newLine(); //写入换行操作
}
//流关闭
writer.close();
}
}
结果:
5.1.6 下载图片实战
package com.xp.climb.climb05.crawler;
import java.io.BufferedInputStream;
import java.io.BufferedOutputStream;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import org.apache.http.HttpEntity;
import org.apache.http.HttpResponse;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.HttpClient;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class CrawPicture {
private static HttpClient httpClient = HttpClients.custom().build();
public static void main(String[] args) throws IOException{
String url = "http://pic.yxdown.com/list/2_0_4.html";
HttpEntity entity = getEntityByHttpGetMethod(url);
//获取所有图片链接
String html = EntityUtils.toString(entity);
Elements elements = Jsoup.parse(html).select("div.cbmiddle > a.proimg > img");
for (Element ele : elements) {
String pictureUrl = ele.attr("src");
//此处pictureUrl.split("/")[7]代表,获取7个/之后的字符串
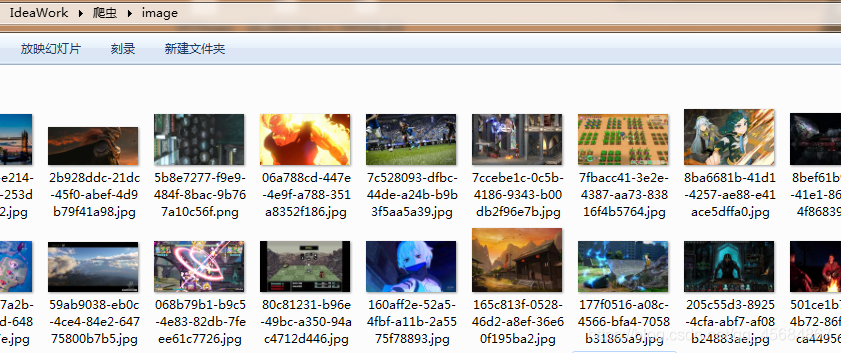
saveImage(pictureUrl,"../爬虫/image/" + pictureUrl.split("/")[7] );
}
//测试程序
saveImage1("http://i-4.yxdown.com/2018/6/11/KDE5Mngp/ae0c2d4d-04fb-4066-872c-a8c7a7c4ea4f.jpg","../爬虫/image/1.jpg");
}
//请求某一个URL,获得请求到的内容
public static HttpEntity getEntityByHttpGetMethod(String url){
HttpGet httpGet = new HttpGet(url);
//获取结果
HttpResponse httpResponse = null;
try {
httpResponse = httpClient.execute(httpGet);
} catch (IOException e) {
e.printStackTrace();
}
HttpEntity entity = httpResponse.getEntity();
return entity;
}
//任意输入地址便可以下载图片
static void saveImage(String url, String savePath) throws IOException{
//图片下载保存地址
File file=new File(savePath);
//如果文件存在则删除
if(file.exists()){
file.delete();
}
//缓冲流
BufferedOutputStream bw = new BufferedOutputStream(
new FileOutputStream(savePath));
//请求图片数据
try {
HttpEntity entity = getEntityByHttpGetMethod(url);
//以字节的方式写入
byte[] byt= EntityUtils.toByteArray(entity);
bw.write(byt);
System.out.println("图片下载成功!");
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
//关闭缓冲流
bw.close();
}
//另外,一种操作方式
static void saveImage1(String url, String savePath)
throws UnsupportedOperationException, IOException {
//获取图片信息,作为输入流
InputStream in = getEntityByHttpGetMethod(url).getContent();
//每次最多读取1KB的内容
byte[] buffer = new byte[1024];
BufferedInputStream bufferedIn = new BufferedInputStream(in);
int len = 0;
//创建缓冲流
FileOutputStream fileOutStream = new FileOutputStream(new File(savePath));
BufferedOutputStream bufferedOut = new BufferedOutputStream(fileOutStream);
//图片写入
while ((len = bufferedIn.read(buffer, 0, 1024)) != -1) {
bufferedOut.write(buffer, 0, len);
}
//缓冲流释放与关闭
bufferedOut.flush();
bufferedOut.close();
}
}
结果:目的地 多出了很多图片。
我们换一个网站再尝试:(只有main方法改动)
public static void main(String[] args) throws IOException{
String url = "https://www.vecteezy.com/free-vector/macbook?page=2";
HttpEntity entity = getEntityByHttpGetMethod(url);
//获取所有图片链接
String html = EntityUtils.toString(entity);
Elements elements = Jsoup.parse(html).select("img");
for (Element ele : elements) {
String pictureUrl = ele.attr("src");
System.out.println(pictureUrl);
//此处使用try——catch的原因,因为图片地址有些是10个‘/’有些是7个
try{
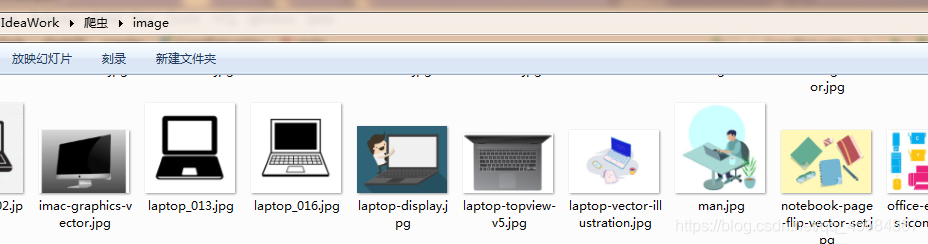
saveImage(pictureUrl,"../爬虫/image/" + pictureUrl.split("/")[10]);
}catch (Exception e){
saveImage(pictureUrl,"../爬虫/image/" + pictureUrl.split("/")[7]);
}
}
//测试程序
saveImage1("https://static.vecteezy.com/system/resources/thumbnails"
+ "/000/498/574/small/Education_31-60_1054.jpg","../爬虫/image/1.jpg");
}
结果:
5.1.7 下载文本实战
package com.xp.climb.climb05.crawler;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStreamWriter;
import java.util.ArrayList;
import java.util.List;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class CrawlerTest {
public static void main(String[] args) throws IOException {
//待爬URL列表
List<String> urlList = new ArrayList<String>();
urlList.add("http://baa.bitauto.com/cs55/index-all-all-1-0.html");
urlList.add("http://baa.bitauto.com/cs55/index-all-all-2-0.html");
urlList.add("http://baa.bitauto.com/cs55/index-all-all-3-0.html");
//缓冲流的创建,以utf-8写入文本
BufferedWriter writer = new BufferedWriter(
new OutputStreamWriter(
new FileOutputStream(
new File("../爬虫/crawldata/1.txt")),"utf-8"));
for (int i = 0; i < urlList.size(); i++) {
List<PostModel> data = crawerData(urlList.get(i));
System.out.println(data);
for (PostModel model : data) {
//所爬数据写入文本
writer.write(model.getPost_id() + "\t" + model.getPost_title() + "\r\n");
}
}
//流的关闭
writer.close();
}
static List<PostModel> crawerData(String url) throws IOException{
//所爬数据封装于集合中
List<PostModel> datalist = new ArrayList<PostModel>();
//获取URL对应的HTML内容
Document doc = Jsoup.connect(url).timeout(30000).get();
//定位需要采集的每个帖子
Elements elements = doc.select("div[class=col-panel]");
//遍历每一个帖子
for (Element ele : elements) {
//解析数据
String post_title = ele.select("span[class=title]").text();
String post_id = ele.select("div[data-uid]").attr("data-uid");
//创建对象和封装数据
PostModel model = new PostModel();
model.setPost_id(post_id);
model.setPost_title(post_title);
datalist.add(model);
}
return datalist;
}
}
结果:(发现节点选取很重要)

5.2 Excel存储(Jxl、POI)
5.2.1 Jxl的使用
介绍:定位——Java中操作Excel的API
适用范围:只对xls有效,!2007版本以上的Excel(xlsx)很难处理。
因为Jxl局限性太大,没有跟上潮流。我们这里就不介绍Jxl了。
5.2.2 POI的使用
介绍:定位——开源跨平台的Excel处理工具,功能比Jx1更强大。
适用范围:Word、PowerPoint、Visio等格式文档;并且Excel中 xls、xlsx都能处理
一、jar包导入
<!-- 文档操作工具 -->
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi</artifactId>
<version>3.17</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.poi/poi-ooxml -->
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>3.17</version>
</dependency>
二、相关类的介绍
1.处理xls常用的类
| 类 | 说明 |
|---|---|
| HSSFWorkbook | Excel工作簿Workbook |
| HSSFSheet | Excel工作表Sheet |
| HSSFRow | Excel行 |
| HSSFCell | Excel单元格 |
2.处理xlsx常用的类
| 类 | 说明 |
|---|---|
| XSSFWorkbook | Excel工作簿Workbook |
| XSSFSheet | Excel工作表Sheet |
| XSSFRow | Excel行 |
| XSSFCell | Excel单元格 |
3.实现的接口
| 类 | 实现的接口 |
|---|---|
| XSSFWorkbook和HSSFWorkbook | Workbook接口 |
| XSSFSheet和HSSFSheet | Sheet接口 |
| XSSFRow和HSSFRow | Row接口 |
| XSSFCell和HSSFCell | Cell接口 |
操作实例——创建Excel
package com.xp.climb.climb05.Excel01.file;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStream;
import org.apache.poi.hssf.usermodel.HSSFWorkbook;
import org.apache.poi.ss.usermodel.Row;
import org.apache.poi.ss.usermodel.Sheet;
import org.apache.poi.ss.usermodel.Workbook;
import org.apache.poi.xssf.usermodel.XSSFWorkbook;
public class PoiExceWritelProcess {
public static void main(String[] args) throws IOException {
//文件名称
File file = new File("../爬虫/data/a.xlsx");
//File file = new File("data/c.xlsx");
OutputStream outputStream = new FileOutputStream(file);
Workbook workbook = getWorkBook(file);
Sheet sheet = workbook.createSheet("Sheet1");
//添加表头
Row row = sheet.createRow(0); //常见某行
row.createCell(0).setCellValue("post_id");
row.createCell(1).setCellValue("post_title");
//添加内容
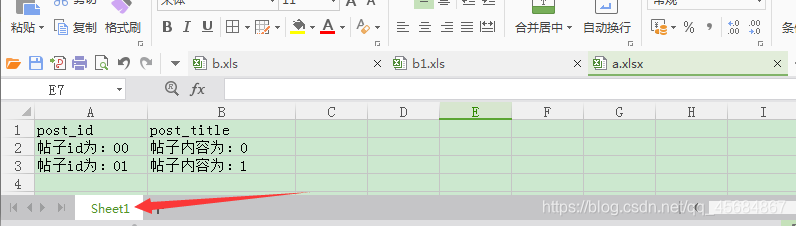
for(int i = 0; i < 2; i++){
Row everyRow = sheet.createRow(i + 1);
everyRow.createCell(0).setCellValue("帖子id为:0" + i);
everyRow.createCell(1).setCellValue("帖子内容为:" + i);
}
workbook.write(outputStream);
//释放资源
workbook.close();
outputStream.close();
}
/**
* 判断Excel的版本,初始化不同的Workbook
* @param filename
* @return
* @throws IOException
*/
public static Workbook getWorkBook(File file) throws IOException{
Workbook workbook = null;
//Excel 2003
if(file.getName().endsWith("xls")){
workbook = new HSSFWorkbook();
// Excel 2007以上版本
}else if(file.getName().endsWith("xlsx")){
workbook = new XSSFWorkbook();
}
return workbook;
}
}
结果:注意Excel中的行和单元格都是1开始,对应代码中的0
操作实例—读取Excel
package com.xp.climb.climb05.Excel01.file;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import org.apache.poi.hssf.usermodel.HSSFWorkbook;
import org.apache.poi.ss.usermodel.Row;
import org.apache.poi.ss.usermodel.Sheet;
import org.apache.poi.ss.usermodel.Workbook;
import org.apache.poi.xssf.usermodel.XSSFWorkbook;
public class PoiExcelRead {
public static void main(String[] args) throws IOException {
//文件名称
File file = new File("../爬虫/data/a.xlsx");
// File file = new File("data/c.xlsx");
//根据文件名称获取操作工作簿
Workbook workbook = getWorkBook(file);
//获取读取的工作表,这里有两种方式
Sheet sheet = workbook.getSheet("Sheet1");
// Sheet sheet=workbook.getSheetAt(0);
int allRow = sheet.getLastRowNum();//获取行数
//按行读取数据
for (int i = 0; i <= allRow; i++) {
Row row = sheet.getRow(i);
//获取列数
short lastCellNum = row.getLastCellNum();
for (int j = 0; j < lastCellNum; j++) {
String cellValue = row.getCell(j).getStringCellValue();//某行的某个单元格的值
System.out.print(cellValue + "\t");
}
System.out.println();
}
workbook.close();
}
/**
* 判断Excel的版本,初始化不同的Workbook
* @param in
* @param filename
* @return
* @throws IOException
*/
public static Workbook getWorkBook(File file) throws IOException{
//输入流
InputStream in = new FileInputStream(file);
Workbook workbook = null;
//Excel 2003
if(file.getName().endsWith("xls")){
workbook = new HSSFWorkbook(in);
// Excel 2007以上版本
}else if(file.getName().endsWith("xlsx")){
workbook = new XSSFWorkbook(in);
}
in.close();
return workbook;
}
}
5.2.3 爬虫案例
介绍:此处展示将网络爬虫获取的数据保存到Excel中。
主类:
package com.xp.climb.climb05.Excel01.crawler;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import jxl.write.WriteException;
import jxl.write.biff.RowsExceededException;
public class CrawlerTest {
public static void main(String[] args)
throws IOException, RowsExceededException, WriteException {
//待爬URL列表
List<String> urlList = new ArrayList<String>();
urlList.add("http://baa.bitauto.com/cs55/index-all-all-1-0.html");
urlList.add("http://baa.bitauto.com/cs55/index-all-all-2-0.html");
urlList.add("http://baa.bitauto.com/cs55/index-all-all-3-0.html");
List<PostModel> datalist = new ArrayList<PostModel>();
//获取数据
for (int i = 0; i < urlList.size(); i++) {
// datalist.addAll(crawerData("https://baa.yiche.com/cs55/"));
//注意此处每次添加的不止一个PostModel对象
datalist.addAll(crawerData(urlList.get(i)));
// System.out.println(datalist.get(1));
}
//存储数据
// DataToExcelByJxl.writeInfoListToExcel("../爬虫/data/post.xls","sheet1",datalist);
DataToExcelByPoi.writeInfoListToExcel("../爬虫/data/post1.xlsx","sheet1",datalist);
}
//解析数据
static List<PostModel> crawerData(String url) throws IOException{
//所爬数据封装于集合中
List<PostModel> datalist = new ArrayList<PostModel>();
//获取URL对应的HTML内容
Document doc = Jsoup.connect(url).timeout(30000).get();
//定位需要采集的每个帖子
Elements elements = doc.select("div[class=col-panel]");
//遍历每一个帖子
for (Element ele : elements) {
//解析数据
String post_title = ele.select("span[class=title]").text();
String post_id = ele.select("div[data-uid]").attr("data-uid");
//创建对象和封装数据
PostModel model = new PostModel();
model.setPost_id(post_id);
model.setPost_title(post_title);
datalist.add(model);
}
return datalist;
}
}
DataToExcelByPoi类
package com.xp.climb.climb05.Excel01.crawler;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStream;
import java.util.List;
import org.apache.poi.hssf.usermodel.HSSFWorkbook;
import org.apache.poi.ss.usermodel.Row;
import org.apache.poi.ss.usermodel.Sheet;
import org.apache.poi.ss.usermodel.Workbook;
import org.apache.poi.xssf.usermodel.XSSFWorkbook;
public class DataToExcelByPoi {
public static void writeInfoListToExcel(String filePath,
String sheetName,List<PostModel> datalist) throws IOException {
//文件名称
File file = new File(filePath);
OutputStream outputStream = new FileOutputStream(file);
Workbook workbook = getWorkBook(file);
Sheet sheet = workbook.createSheet(sheetName);
//添加表头
Row row = sheet.createRow(0); //常见某行
row.createCell(0).setCellValue("post_id");
row.createCell(1).setCellValue("post_title");
//添加内容
for(int i = 0; i < datalist.size(); i++){
System.out.println(datalist.get(i));
Row everyRow = sheet.createRow(i + 1);
everyRow.createCell(0).setCellValue(datalist.get(i).getPost_id());
everyRow.createCell(1).setCellValue(datalist.get(i).getPost_title());
}
workbook.write(outputStream);
//释放资源
workbook.close();
outputStream.close();
System.out.println(">>>>>>>>>数据写入完成!<<<<<<<<<<<<<");
}
/**
* 判断Excel的版本,初始化不同的Workbook
* @param filename
* @return
* @throws IOException
*/
public static Workbook getWorkBook(File file) throws IOException{
Workbook workbook = null;
//Excel 2003
if(file.getName().endsWith("xls")){
workbook = new HSSFWorkbook();
// Excel 2007以上版本
}else if(file.getName().endsWith("xlsx")){
workbook = new XSSFWorkbook();
}
return workbook;
}
}
封装的PostModel类:
private String post_id; //帖子id
private String post_title; //帖子标题
public String getPost_id() {
return post_id;
}
public void setPost_id(String post_id) {
this.post_id = post_id;
}
public String getPost_title() {
return post_title;
}
public void setPost_title(String post_title) {
this.post_title = post_title;
}
@Override
public String toString() {
return “PostModel{” +
“post_id=’” + post_id + ‘’’ +
“, post_title=’” + post_title + ‘’’ +
‘}’;
结果:
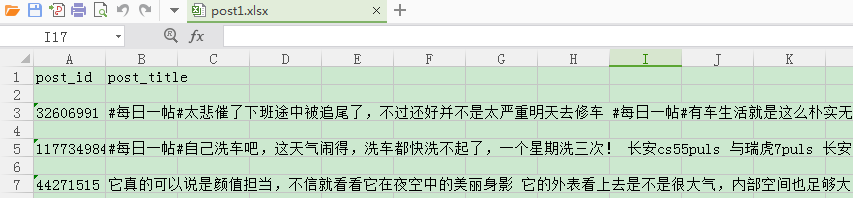
5.3 Mysql 数据存储
介绍:针对较大规模数据可以用数据库进行存储。
此处省略数据库基本概念、数据库基础语句。
Java操作数据库的一般流程:
①加载JDBC驱动(需导入JDBC驱动——mysql-connector-java)
②基于数据库地址、用户名、密码,建立连接
③创建Statement对象
④执行SQL语句
⑤关闭连接,释放资源
5.3.1 基础连接操作实例:
Statement类执行SQL的相关方法:
ResultSet executeQuery(String sql) throws SQLException;//获取结果集
int executeUpdate(String sql) throws SQLException;//执行更新操作
boolean execute(String sql) throws SQLException;//执行sql语句
//用于批处理,和executeBatch()方法前后使用
void addBatch(String sql) throws SQLException;//添加批处理
int[ ] executeBatch() throws SQLException;//批处理
package com.xp.climb.climb05.mysql;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
public class MySQLConnections {
private String driver = "";
private String dbURL = "";
private String user = "";
private String password = "";
private static MySQLConnections connection = null;
private MySQLConnections() throws Exception {
driver = "com.mysql.cj.jdbc.Driver"; //数据库驱动
dbURL = "jdbc:mysql://127.0.0.1:3306/crawler?characterEncoding=utf-8&serverTimezone=UTC"; //JDBC的URL
user = "root"; //数据库用户名
password = "xiaopan"; //数据库密码
System.out.println("dbURL:" + dbURL);
}
public static Connection getConnection() {
Connection conn = null;
if (connection == null) {
try {
connection = new MySQLConnections(); //初始化连接
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
try {
Class.forName(connection.driver); //调用Class.forName()方法加载驱动程序
conn = DriverManager.getConnection(connection.dbURL,
connection.user, connection.password); //建立数据库连接
} catch (Exception e) {
e.printStackTrace();
}
return conn;
}
public static void main(String[] args) throws SQLException {
Connection con = getConnection();
Statement stmt = null;
try {
stmt = con.createStatement();//创建Statement对象
} catch (SQLException e1) {
e1.printStackTrace();
}
System.out.println("成功连接到数据库!");
//防止数据库中有数据,先删除表中数据
stmt.execute("delete from carsales");
//执行数据插入操作,忽略主键重复
stmt.execute("insert ignore into carsales(month, sales) values ('2017-09-01', '500')");
stmt.execute("insert ignore into carsales(month, sales) values ('2017-10-01', '100')");
String sql = "select * from carsales"; //要执行的SQL
//查询操作
ResultSet rs = stmt.executeQuery(sql);
//结果集
while (rs.next()){
//输出1,2两列
System.out.print(rs.getString(1) + "\t");
System.out.print(rs.getString(2) + "\t");
System.out.println();
}
stmt.addBatch("update carsales set sales = '1000' where month = '2017-10-01' ");
stmt.addBatch("update carsales set sales = '20' where month = '2017-09-01'");
int number[] = stmt.executeBatch(); //批处理
System.out.println("执行的sql语句数目为:" + number.length);
ResultSet rs1 = stmt.executeQuery("select * from carsales");
System.out.println("更新后的而结果为:");
while (rs1.next()){
//输出1,2两列
System.out.print(rs1.getString(1) + "\t");
System.out.print(rs1.getString(2) + "\t");
System.out.println();
}
con.close(); //关闭连接
}
}
5.3.2 XML略过
5.3.3 QueryRunner连接
介绍:数据库操作类
优势:JDBC编程更加方便快捷,线程操作安全
一、jar包
<!-- QueryRunner相关依赖-->
<dependency>
<groupId>commons-dbutils</groupId>
<artifactId>commons-dbutils</artifactId>
<version>1.7</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-dbcp2</artifactId>
</dependency>
二、操作
package com.xp.climb.climb05.mysql;
import java.sql.SQLException;
import java.util.List;
import javax.sql.DataSource;
import org.apache.commons.dbcp2.BasicDataSource;
import org.apache.commons.dbutils.QueryRunner;
import org.apache.commons.dbutils.handlers.BeanListHandler;
import org.apache.commons.dbutils.handlers.ColumnListHandler;
import com.xp.climb.climb05.mysql.model.CarSaleModel;
public class QueryRunnerTest {
//获取数据库信息
static DataSource ds = getDataSource("jdbc:mysql://127.0.0.1:3306/crawler?characterEncoding=utf-8&serverTimezone=UTC");
//使用QueryRunner库,操作数据库
static QueryRunner qr = new QueryRunner(ds);
public static DataSource getDataSource(String connectURI){
BasicDataSource ds = new BasicDataSource();
//MySQL的jdbc驱动
ds.setDriverClassName("com.mysql.cj.jdbc.Driver");
ds.setUsername("root"); //所要连接的数据库名
ds.setPassword("xiaopan"); //MySQL的登陆密码
ds.setUrl(connectURI);
return ds;
}
//第一类方法
public void executeUpdate(String sql){
try {
qr.update(sql);
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
//按照SQL查询多个结果,这里需要构建Bean对象
public <T> List<T> getListInfoBySQL (String sql, Class<T> type ){
List<T> list = null;
try {
list = qr.query(sql,new BeanListHandler<T>(type));
} catch (SQLException e) {
e.printStackTrace();
}
return list;
}
//查询一列
@SuppressWarnings({ "unchecked", "rawtypes" })
public List<Object> getListOneBySQL (String sql,String id){
List<Object> list=null;
try {
list = (List<Object>) qr.query(sql, new ColumnListHandler(id));
} catch (SQLException e) {
e.printStackTrace();
}
return list;
}
//将所爬数据插入数据库
public static void insertData ( List<CarSaleModel> datalist ) {
Object[][] params = new Object[datalist.size()][2];
for ( int i = 0; i < datalist.size(); i++ ){
//需要存储的字段
params[i][0] = datalist.get(i).getMonth();
params[i][1] = datalist.get(i).getSales();
}
QueryRunner qr = new QueryRunner(ds);
try {
//执行批处理语句
qr.batch("INSERT INTO carsales(month,sales) VALUES (?,?)", params);
} catch (SQLException e) {
System.out.println(e);
}
System.out.println("新闻数据入库完毕");
}
public static void main(String[] args) {
QueryRunnerTest QueryRunnerTest = new QueryRunnerTest();
//查询多列
List<CarSaleModel> mutllistdata = QueryRunnerTest.getListInfoBySQL("select month,"
+ "sales from carsales", CarSaleModel.class);
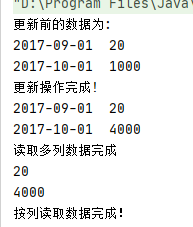
System.out.println("更新前的数据为:");
for (CarSaleModel model : mutllistdata) {
System.out.println(model.getMonth() + "\t" +model.getSales());
}
//执行更新操作
QueryRunnerTest.executeUpdate("update carsales set sales = '4000' "
+ "where month = '2017-10-01'"); //执行更新操作
System.out.println("更新操作完成!");
//查询多列
List<CarSaleModel> mutllistdataupdate = QueryRunnerTest.getListInfoBySQL("select "
+ "month,sales from carsales", CarSaleModel.class);
for (CarSaleModel model : mutllistdataupdate) {
System.out.println(model.getMonth() + "\t" +model.getSales());
}
System.out.println("读取多列数据完成");
//查询单列
List<Object> listdata = QueryRunnerTest.getListOneBySQL("select sales from "
+ "carsales", "sales");
for (int i = 0; i < listdata.size(); i++) {
System.out.println(listdata.get(i).toString());
}
System.out.println("按列读取数据完成!");
}
}
Bean类:
public class CarSaleModel {
private String month;
private String sales;
public String getMonth() {
return month;
}
public void setMonth(String month) {
this.month = month;
}
public String getSales() {
return sales;
}
public void setSales(String sales) {
this.sales = sales;
}
}
结果:
5.3.4 爬虫案例
此处导入了QueryRunner实例类
package com.xp.climb.climb05.mysql;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import com.xp.climb.climb05.mysql.QueryRunnerTest;
import com.xp.climb.climb05.mysql.model.CarSaleModel;
public class CrawlerToDatabaseTest {
public static void main(String[] args) throws IOException {
//获取URL对应的XML内容
Document doc = Jsoup.connect("http://db.auto.sohu.com/cxdata/xml/sales/model/model1001sales.xml")
.timeout(5000).get();
//数据存储到集合中
List<CarSaleModel> datalist = new ArrayList<CarSaleModel>();
//Jsoup选择器解析
Elements sales_ele = doc.select("sales");
for (Element elem:sales_ele) {
String salesnum=elem.attr("salesnum");
String date = elem.attr("date");
//封装对象
CarSaleModel model = new CarSaleModel();
model.setMonth(date);
model.setSales(salesnum);
//添加到集合中
datalist.add(model);
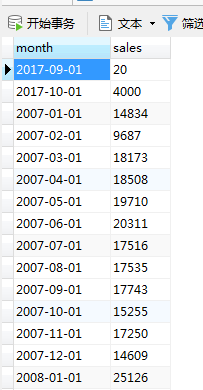
System.out.println("月份:" + date + "\t销量:" + salesnum);
}
//将所爬数据插入数据库
QueryRunnerTest.insertData(datalist);
}
}
结果:
5.4 Mysql—>Excel
package com.xp.climb.climb05.change;
import org.apache.poi.hssf.usermodel.HSSFWorkbook;
import org.apache.poi.ss.usermodel.Row;
import org.apache.poi.ss.usermodel.Sheet;
import org.apache.poi.ss.usermodel.Workbook;
import org.apache.poi.xssf.usermodel.XSSFWorkbook;
import java.io.*;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import static com.xp.climb.climb05.change.MySQLConnections.getConnection;
public class Mysql_excel {
public static void main(String[] args) throws SQLException, IOException {
Connection con = getConnection();
Statement stmt = null;
try {
stmt = con.createStatement();//创建Statement对象
} catch (SQLException e1) {
e1.printStackTrace();
}
//文件名称
File file = new File("../爬虫/data/carsales.xlsx");
//File file = new File("data/c.xlsx");
OutputStream outputStream = new FileOutputStream(file);
Workbook workbook = getWorkBook(file);
Sheet sheet = workbook.createSheet("Sheet1");
//查询表的列名
ResultSet rscl = stmt.executeQuery(
"SELECT COLUMN_NAME FROM information_schema.COLUMNS WHERE TABLE_NAME='carsales'");
//添加表头
int i=0;
Row head = sheet.createRow(0);
while (rscl.next()){
head.createCell(i).setCellValue(rscl.getString(1));
i++;
}
//查询表的内容
ResultSet rs1 = stmt.executeQuery("select month,sales from carsales");
//添加内容
int i1=1;
while (rs1.next()){
Row everyRow = sheet.createRow(i1);
everyRow.createCell(0).setCellValue(rs1.getString(1));
everyRow.createCell(1).setCellValue(rs1.getString(2));
i1++;
}
workbook.write(outputStream);
//释放资源
workbook.close();
outputStream.close();
con.close(); //关闭sql连接
}
/**
* 判断Excel的版本,初始化不同的Workbook
* @param filename
* @return
* @throws IOException
*/
public static Workbook getWorkBook(File file) throws IOException{
Workbook workbook = null;
//Excel 2003
if(file.getName().endsWith("xls")){
workbook = new HSSFWorkbook();
// Excel 2007以上版本
}else if(file.getName().endsWith("xlsx")){
workbook = new XSSFWorkbook();
}
return workbook;
}
}

















 392
392

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









