






DML 插入数据 修改数据 删除数据
学习
insert into(表字段插入数据)
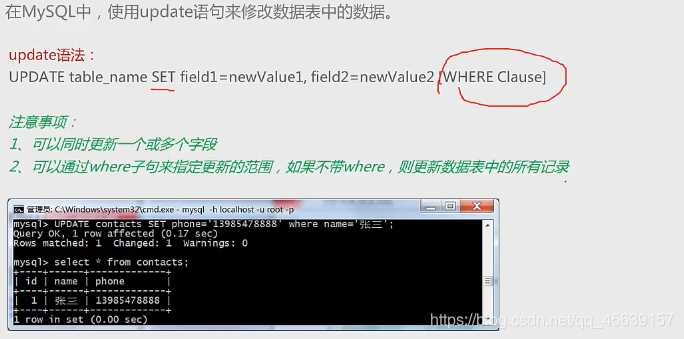
update(表字段更新数据)
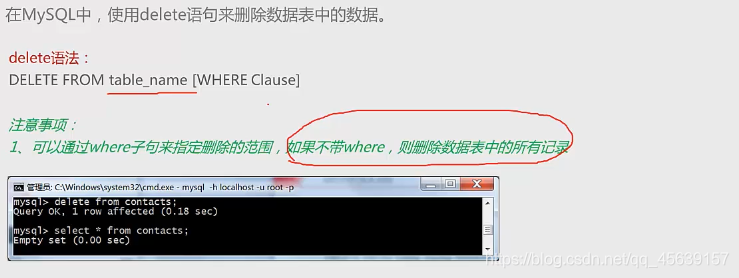
delete(删除表字段数据)
①插入单条数据:哪个表+哪个字段+是什么值[vlue和field一一对应]
②插入多条数据 插入多组值
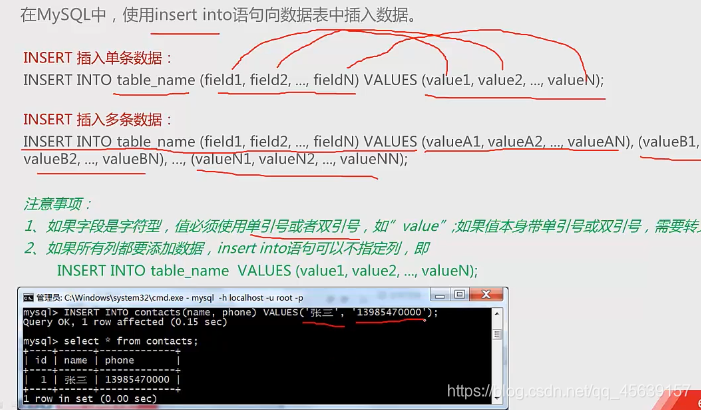
实例1
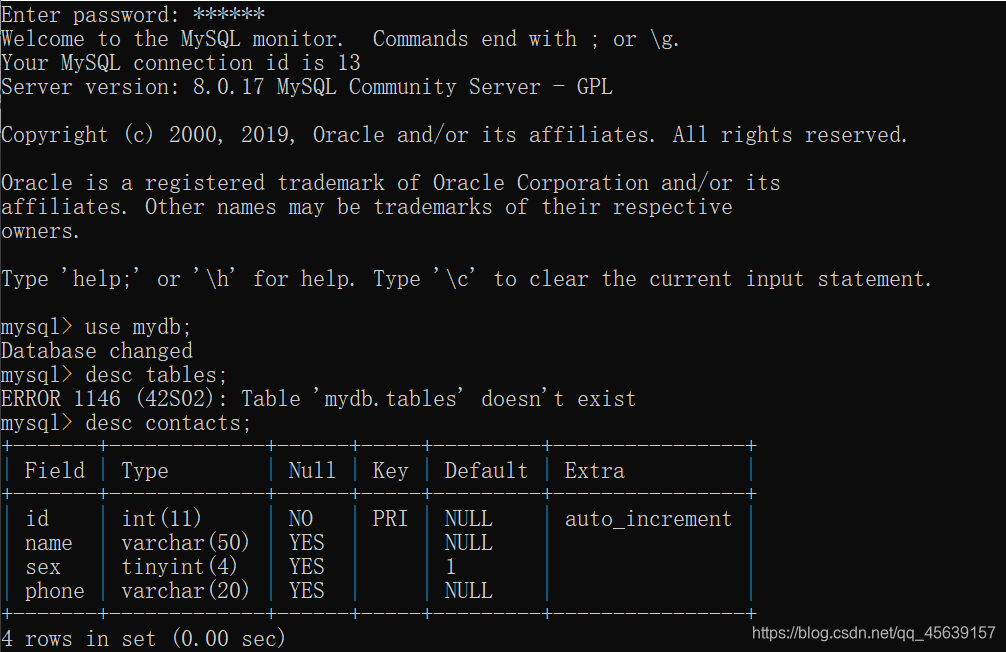
查看contacts数据表格式 == id存在主键==
插入数据
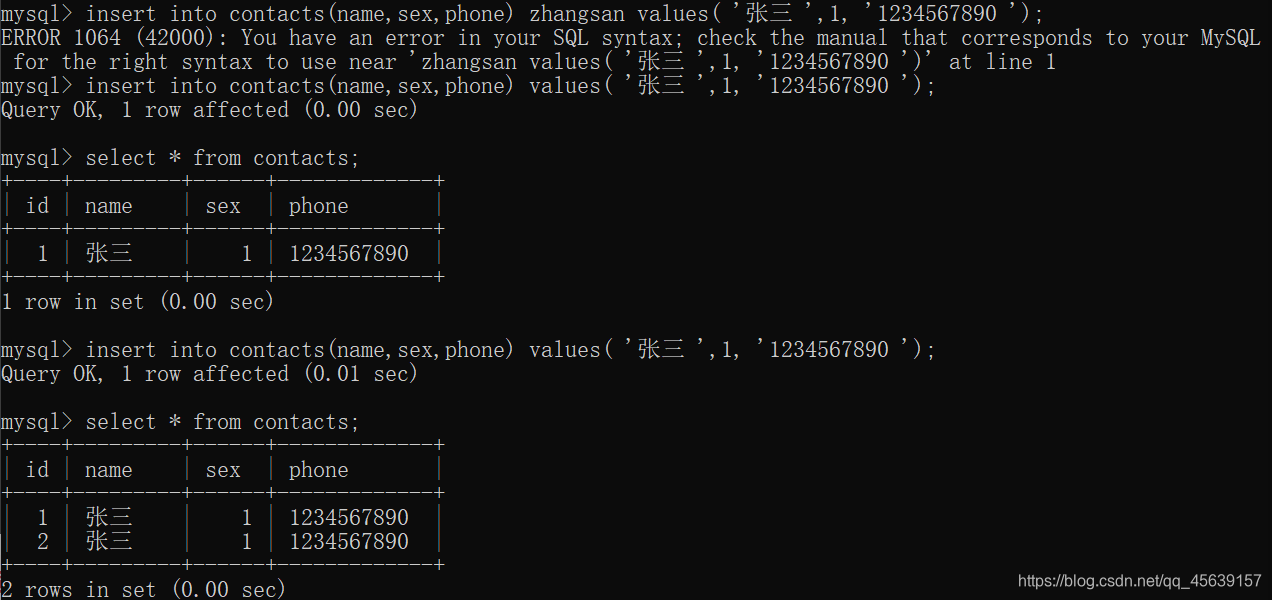
查询数据表
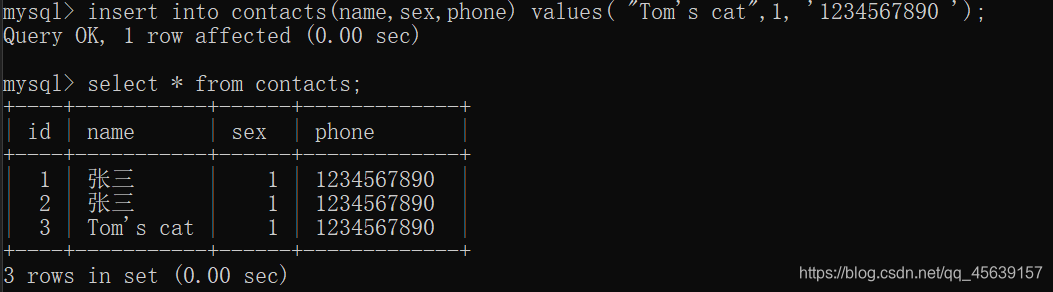
带引号格式的插入
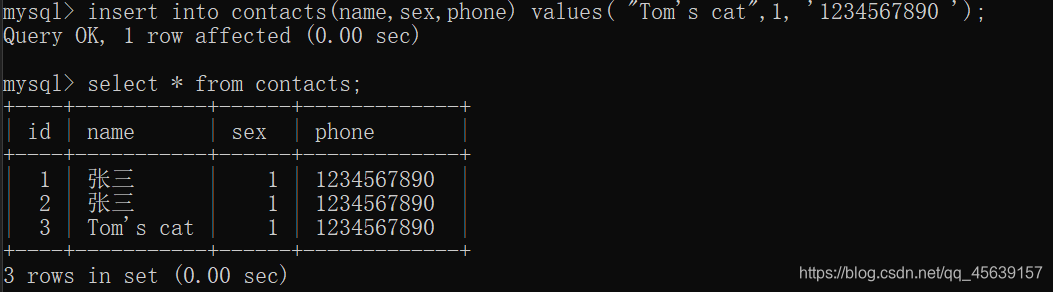
多组数据插入

default的间接使用

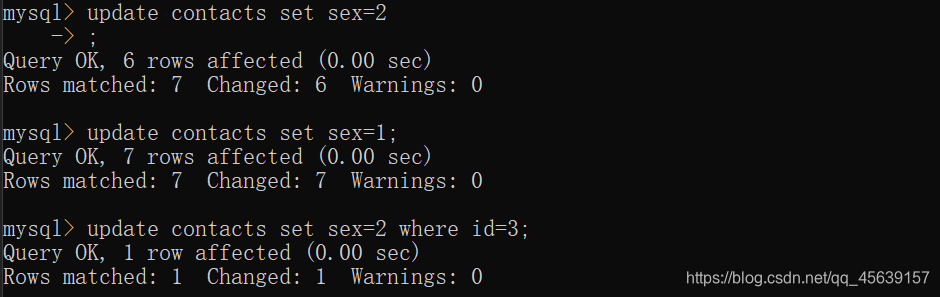
更新该表
通过主键删除


MySQL输入错误SQL语句使用 ’ ; 回车就可以退出 或者输入; 回车
“劫路”知识
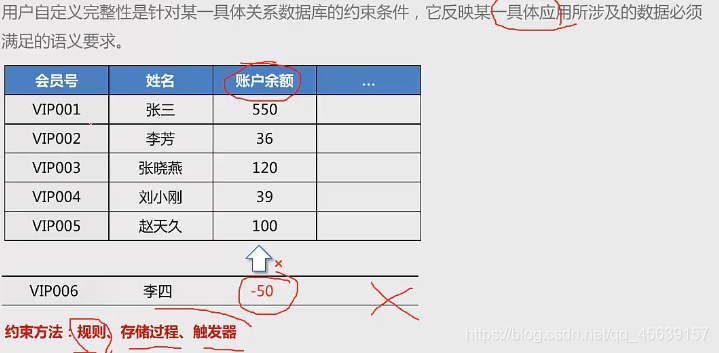
数据的完整性
数据本身不准确 有问题 系统功能再强大无济于事
比如身份证号 银行卡余额等
数据完整性:存储在数据库中的数据 应该保证一致性和可靠性
关系模型中允许定义三类数据约束,实体完整性、参照完整性以及用户定义的完整性约束,前两种由关系型数据库系统自动支持
实现数据完整性的一个博客
实体完整性:
RDBMS中的一行代表一个实体 实体完整性就是保证每一个实体都能被区别(人 用身份证号区别 车用车牌号区别 比如系统数据库中有两个人的车牌号是一样的 证明肯定有一个套牌车)
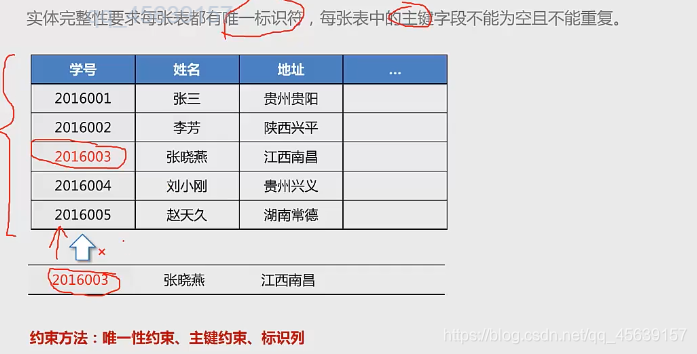
实例2:
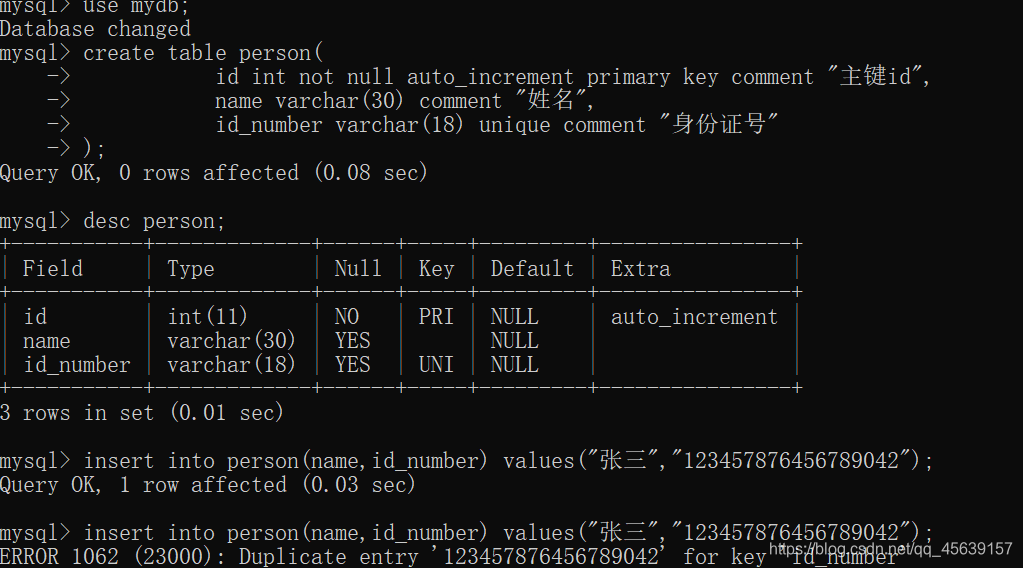
通过唯一性约束设置实体完整性 创建一个表 身份证号使用unique关键字限制为唯一性约束 进行插入数据
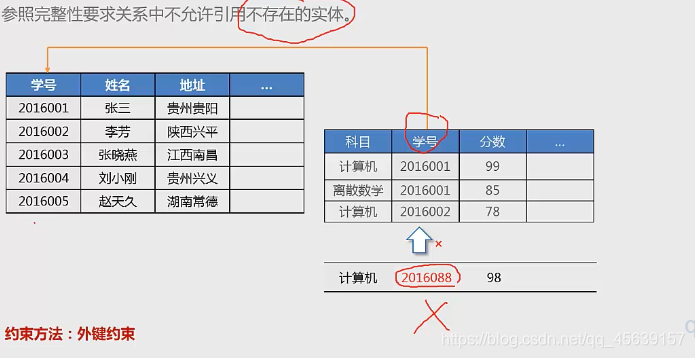
参照完整性:
主要是指表与表之间的关系,使用外键(比如说一个学生的成绩表 存学生学号 学生成绩等 在学生表里面找不到这个学生成绩表的学号对应学生 这样就不具有参照完整性了 )
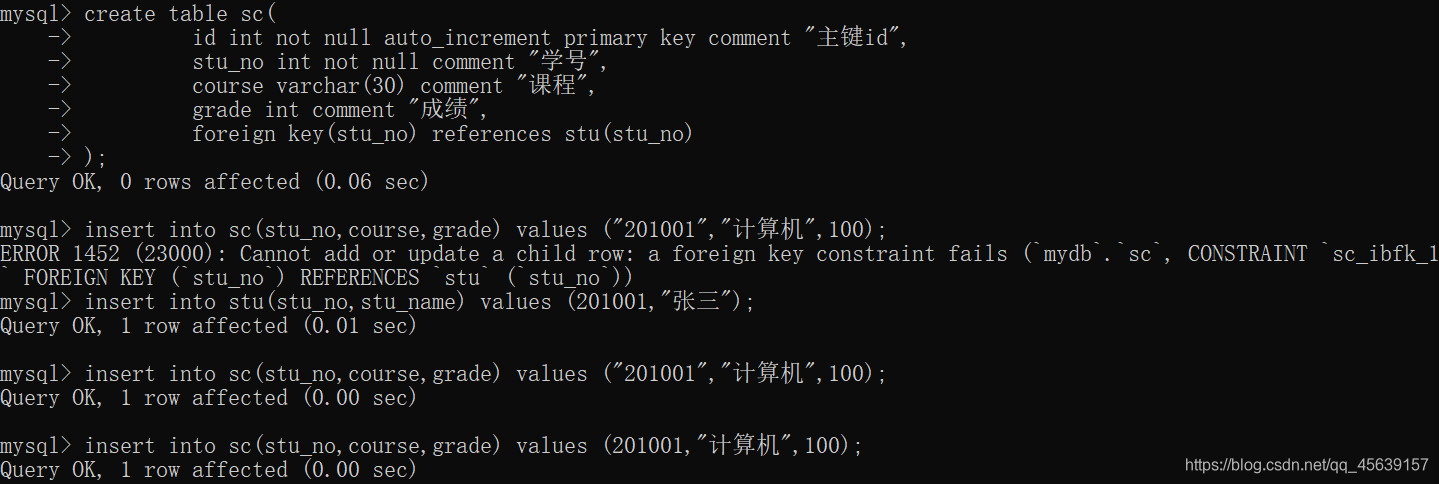
通过外键==(其他表的主键)==约束 在插入数据时候必须先向主表(stu学生表)插入 再向从表(sc成绩表)插入 删除数据正好相反



用户定义的完整性约束:
借助存储过程和触发器实现
还没有实例
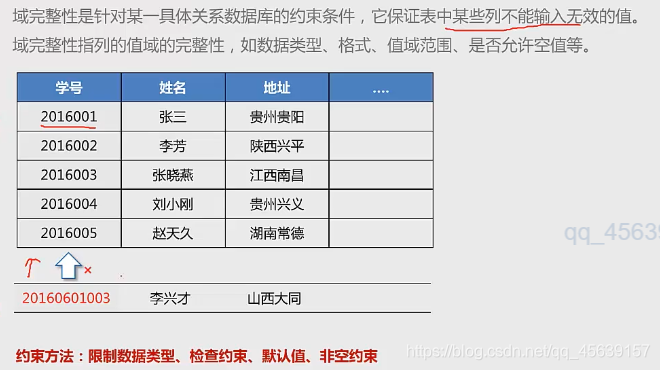
域完整性:
对列的输入有要求 限制列的数据类型、格式或值的范围来实现
还没有实例
DQL
学习:
select(查询)
使用select查询数据 通过MySQL官网查询即可
主要讲解以下七行方法.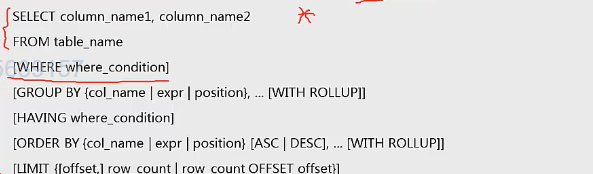
①单条件查询

②多条件查询

实例3:
存在一个这样的表
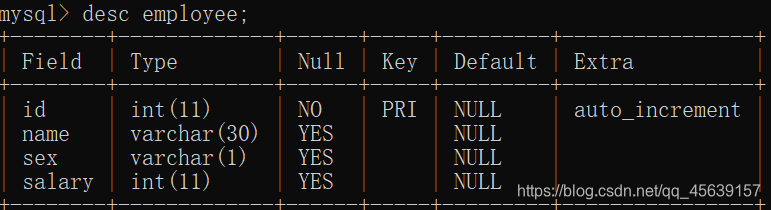
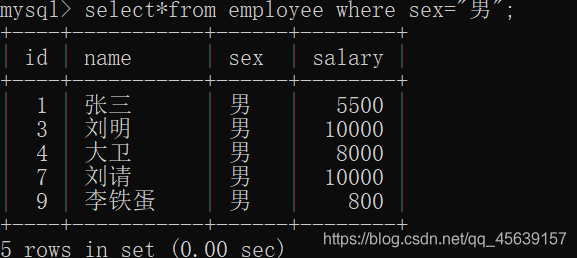
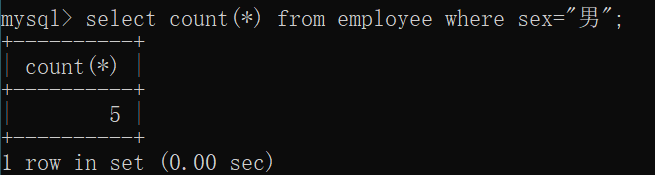
查找性别为男
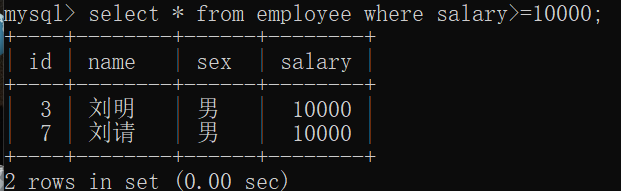
查找工资>=10000
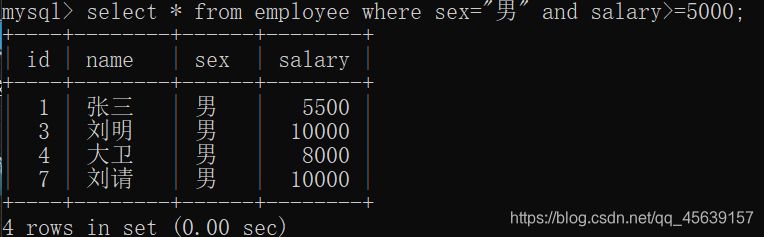
 查找是男 工资大于5000
查找是男 工资大于5000
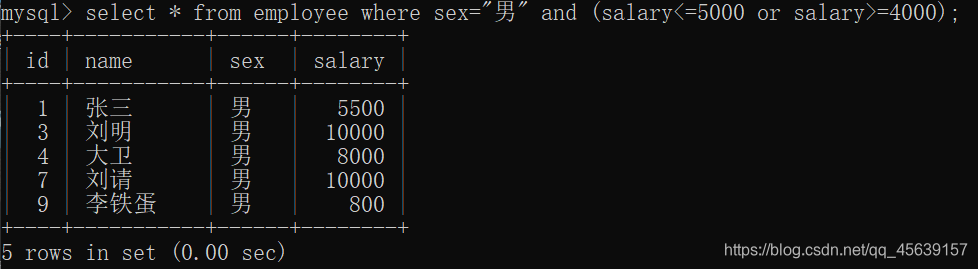
查找是男 并且工资<=5000 或 >=4000 注意括号的使用
③in like运算符


实例4:
有这样一张表
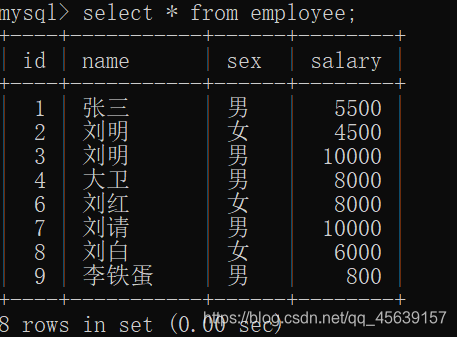
查找id为1 2 3的

使用like进行正则匹配
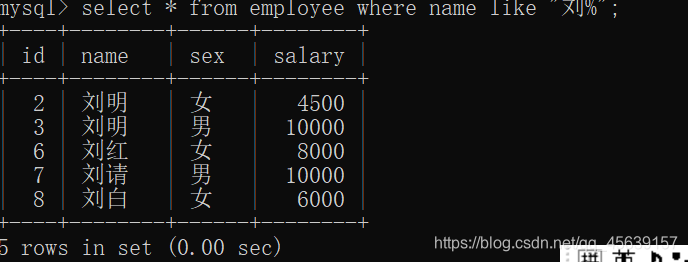
使用like正则匹配
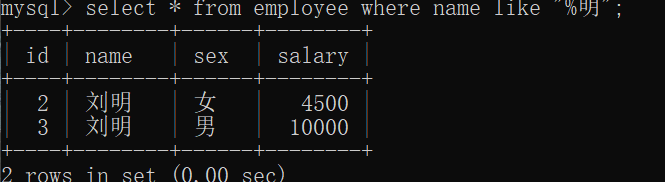
使用_进行正则匹配

④MySQL内置函数
主要学习红色部分
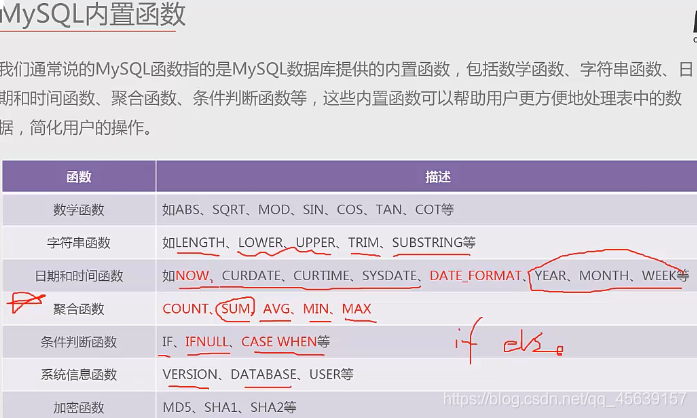
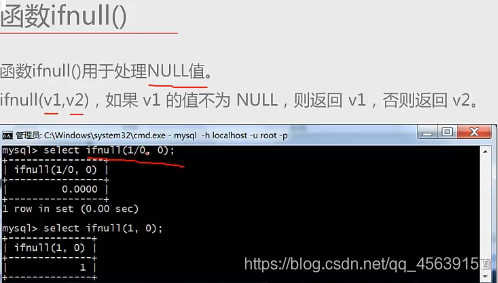
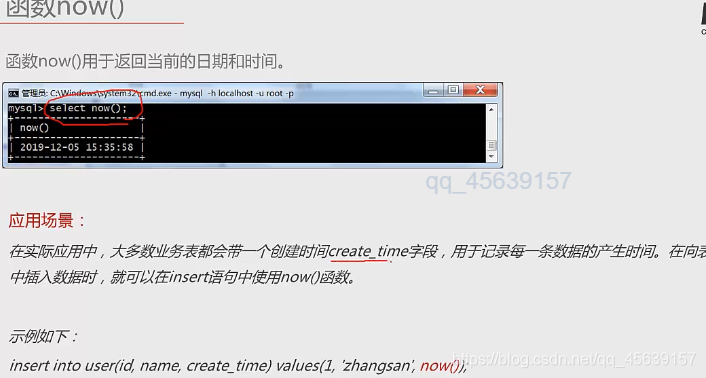
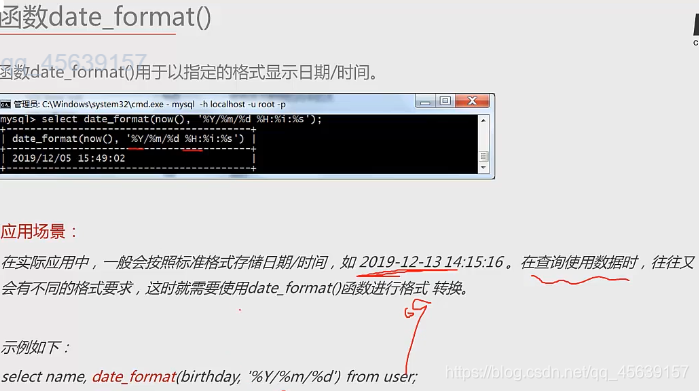
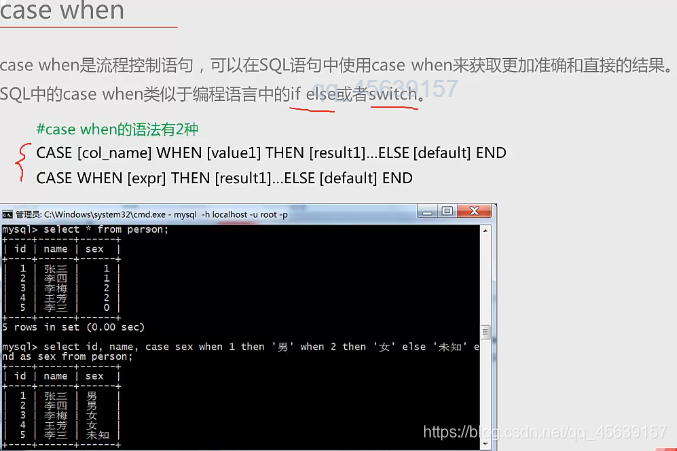
实例五
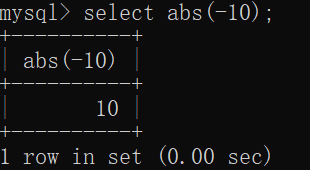
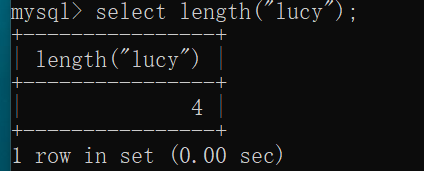
简单函数
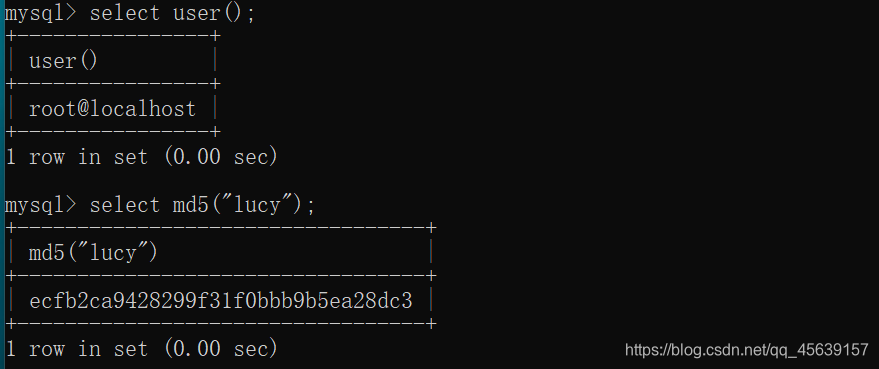
连接的是本机数据库
对字符串进行加密
存在以下数据表(注意编号)
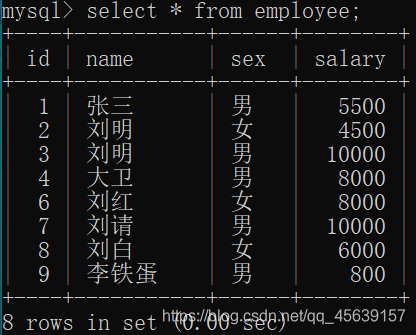
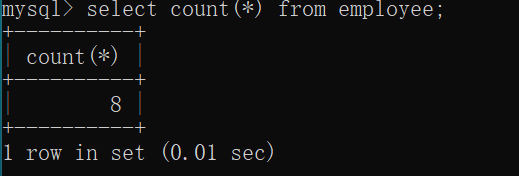
统计有多少行数据
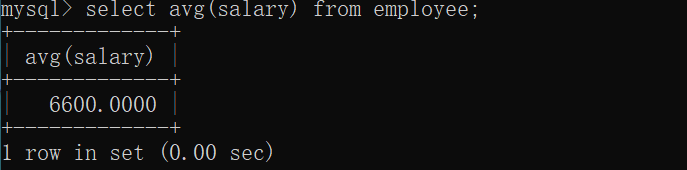
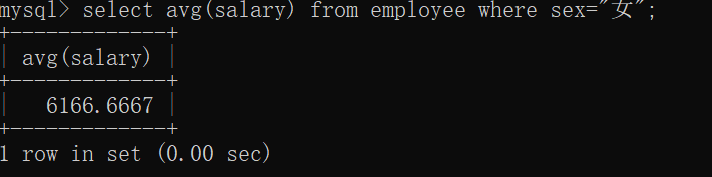
统计平均薪资(salary列平均)
统计总薪资(salary列)
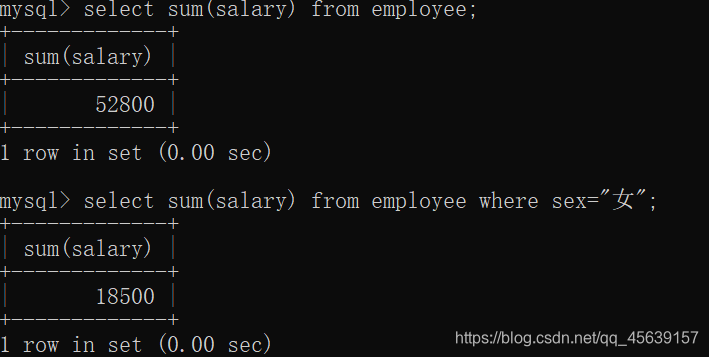
case when选择用法(注意end as 表示选择出来的表以哪一列结束)
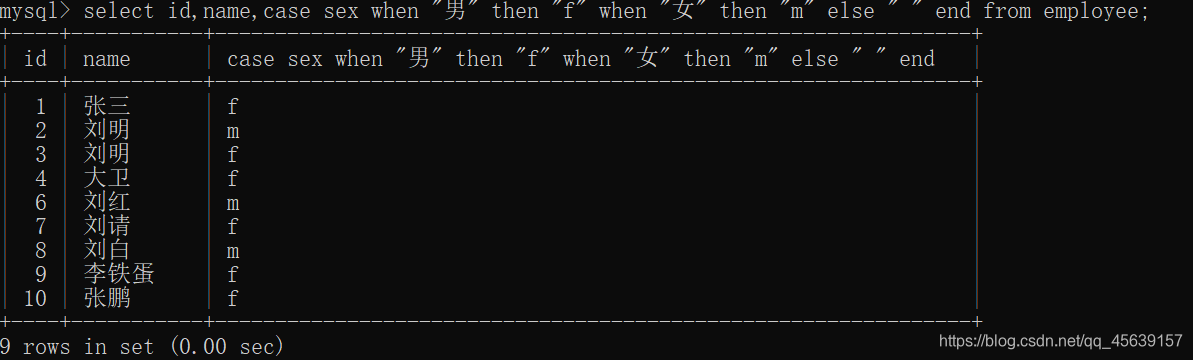
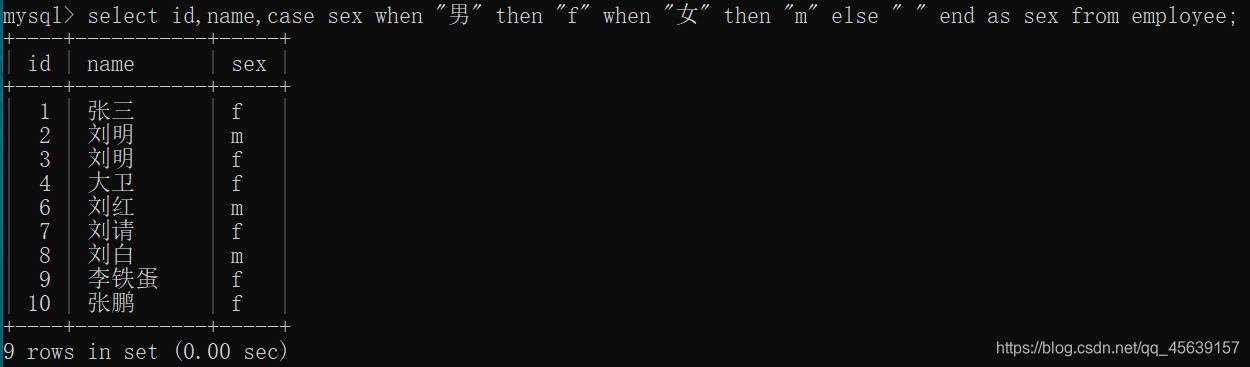
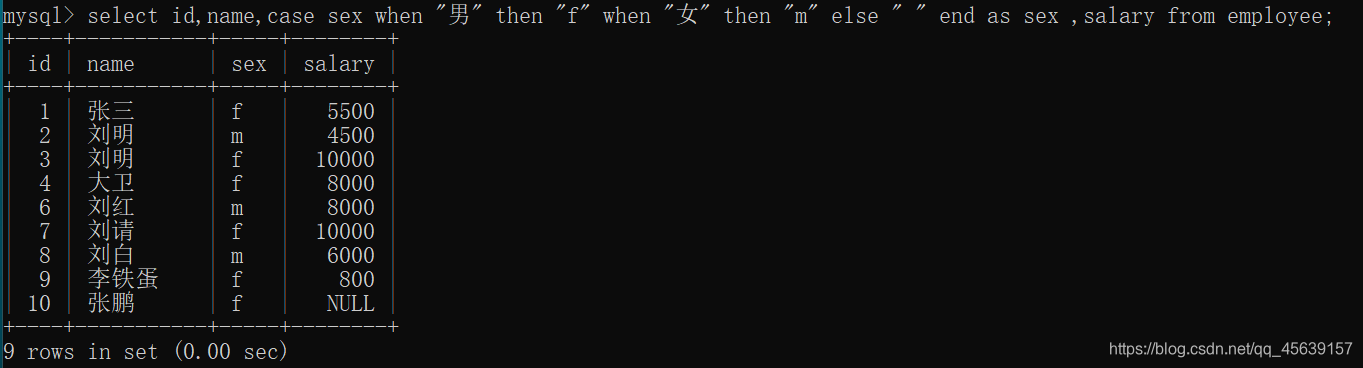
显示出来的表以salary列结束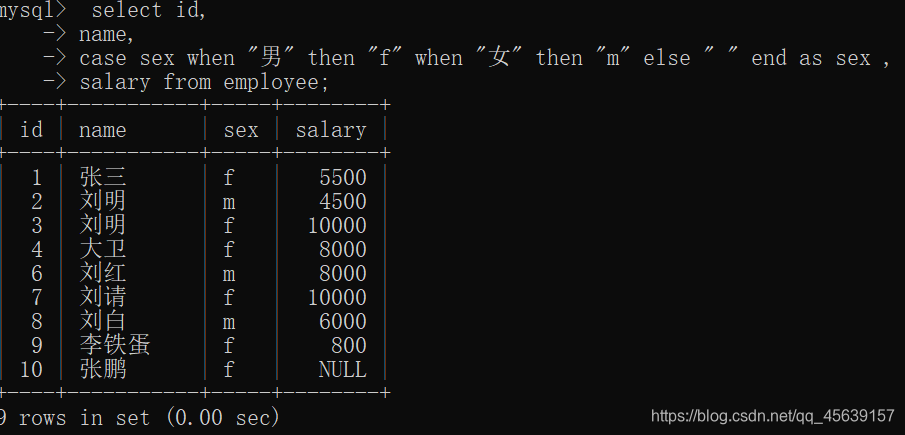
⑤查询结果排序与分类
已经学过了按select语句进行单条件 多条件查询 in like使用
需求:查询的学生按身高由高到低进行排序 双十一某商城的商品交易量 博客中文章浏览次数的多少
这时候需要使用
order by 可以按照一列或多列进行排序

limit 可以约束限制要返回的记录数 实现分页
注意这个偏移量 比如一页有20行数据 我们获得第一页数据的话,offset指定为1(相当于第一条),row_count指定为20
我们获得第二条数据的话,offset指定为20(相当于第21条数据),row_count指定为20
实例六
有这样一张表
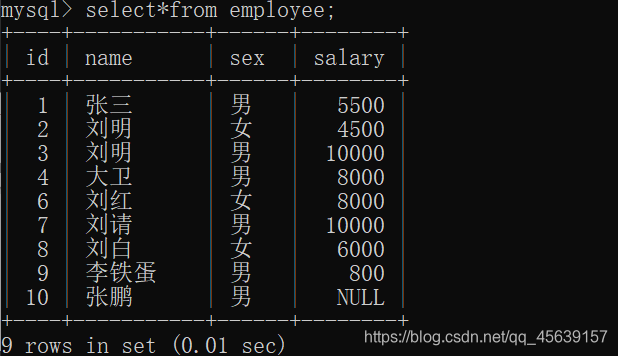
可以考虑需求:把员工按照薪资,性别等进行排序并进行显示,把员工表各数据进行分页。
分析可知:使用order by和limit比较合适
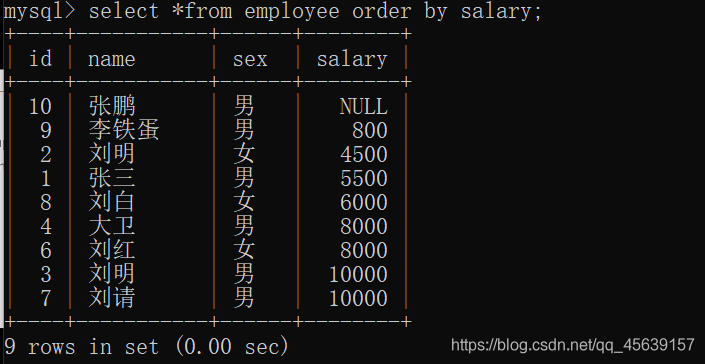
按照薪资进行排序
按照sex性别进行排序
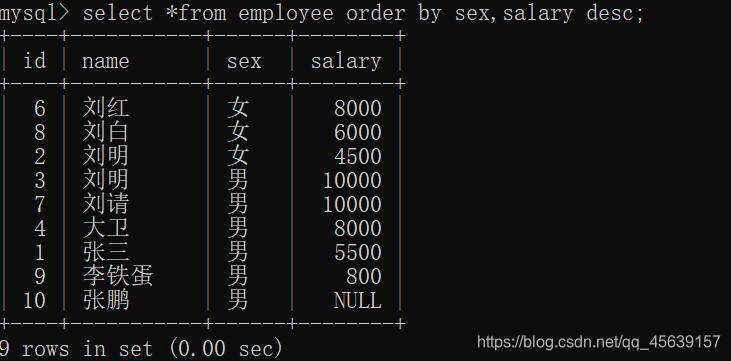
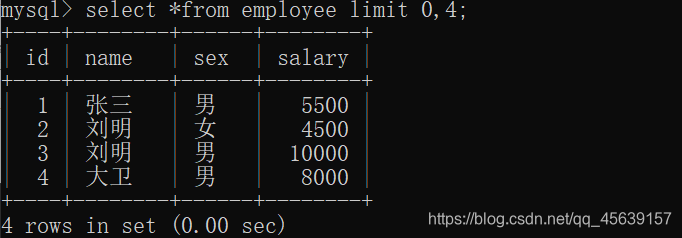
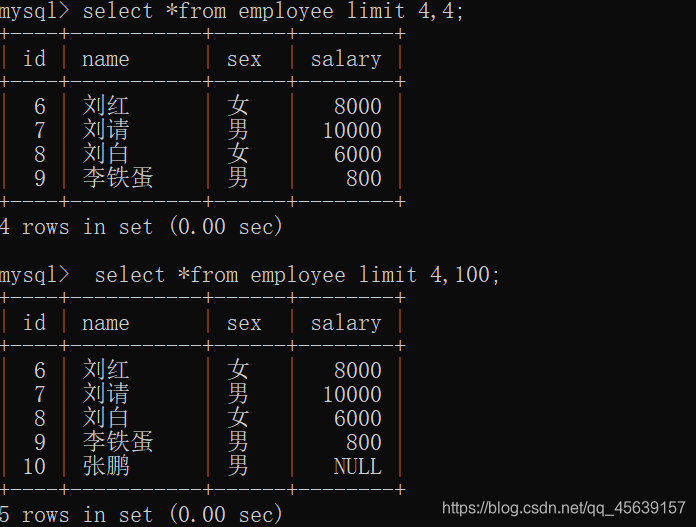
进行分页,每页4行数据
如何对于中文汉字进行排序 但是8.0中文好像是已经有默认字符集编码了
group by我感觉是尽量配合聚合函数使用,否则就没意义了;
where不能配合聚合函数+group by使用,是因为这个博客写的 理解一下
having尽量(一般都是)是配合聚合函数+group by一起使用的,其实是为了弥补where不能配合聚合函数+group by使用的不足;其目的是通过聚合函数对group by分组后的结果集的统计数据进一步筛选。这个博客写的 理解一下
⑥group by,having
需求:公司想知道每个部门有多少员工,班主任统计各科目第一名的成绩,门店掌握男、女会员用户的平均年龄
都是对数据进行了分组
group by子句进行分组 必须配合聚合函数进行实现

having子句可以对分组后的各组数据进行分组

实例七:
有这样一张表
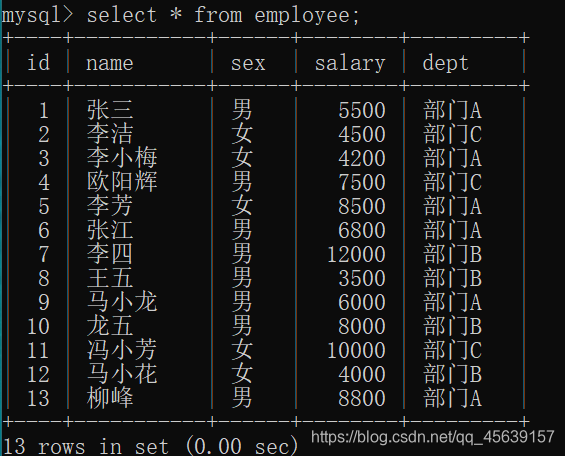
可以考虑需求:我们把员工按部门进行分组,并且显示出每组的总人数;我们把员工按照部门进行分组,并且显示每组各个人的最小薪资;我们把员工按照部门进行分组,并且显示出总人数小于5的组;
分析可以看出:使用group by+having比较合适
例子截屏如下:
按部门进行分组
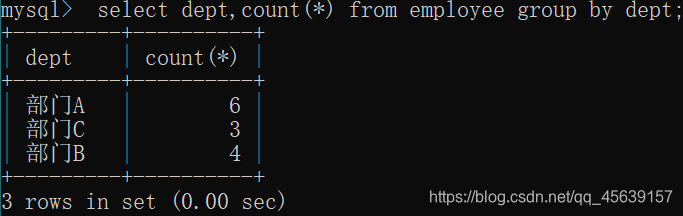
按性别进行分组
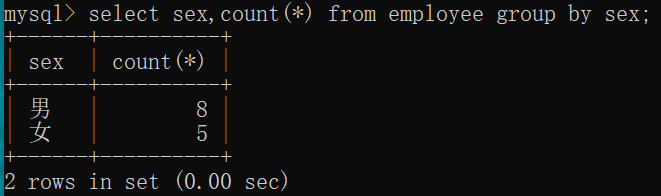
按部门进行分组
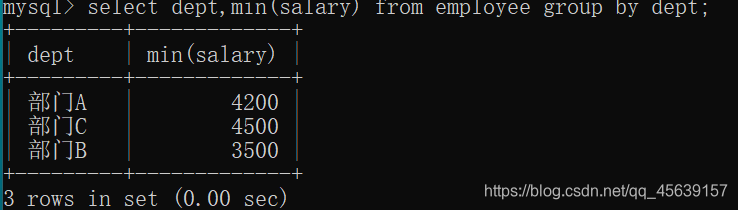
按部门进行分组,并且显示出部门总人数小于5的部门

按部门进行分组,并且显示出部门中各个人薪资最大值大于10000的部门
⑦group_concat的应用场景
需求:将员工按部门进行分组,想知道每个部门中的具体员工列表
配合group by进行使用,将某一列的值按指定的分隔符进行拼接

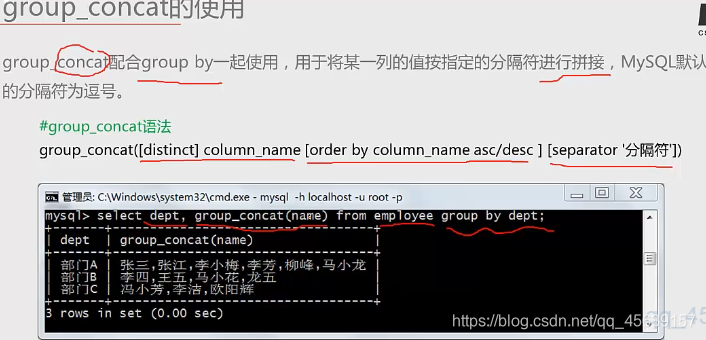 有这样一张表
有这样一张表
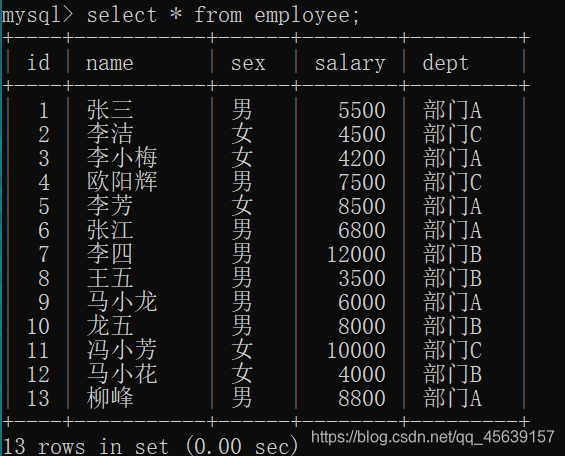
可以考虑需求:把员工按部门进行分组,并显示出每个部门中各个员工的名字;把员工按部门进行分组,部门中员工名字按名字进行排序,并显示出每个部门中各个员工的名字;把员工按部门进行分组,部门中员工名字按名字进行排序,并显示出每个部门中各个员工的名字,以;分隔
例子截屏如下



⑧distinct的应用场景
需求:用于去重,比如一张足迹表(这地方后面再看就行),肯定会有重复人的名字,但我们想去重的进行名字显示。
distinct必须再select后面第一个,distinct作用于后面每一列的数据
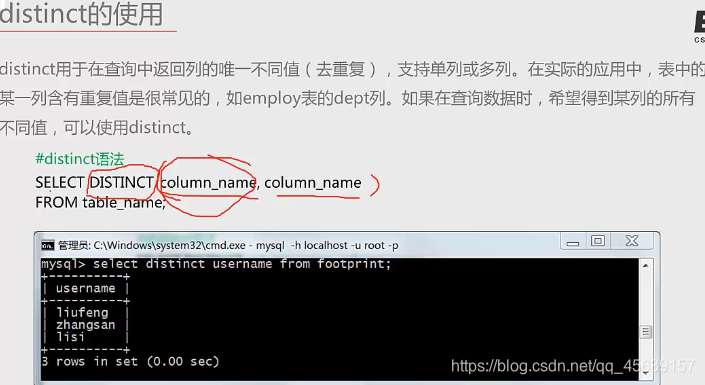
实例八:
有这样一张表
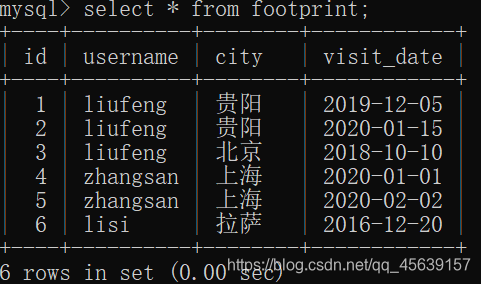
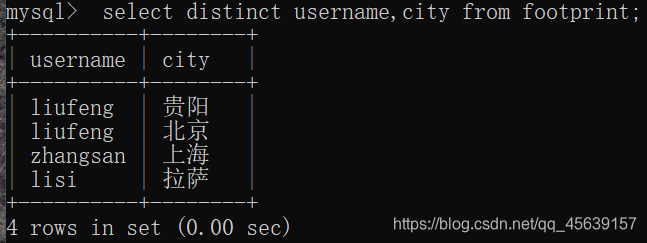
存在这样的需求:去重得显示足迹表中各个人的名字;去重得显示足迹表中各个人的名字以及他们去过的地方(distinct作用两个列:username+city)
分析可知:使用distinct比较合适
例子截屏如下
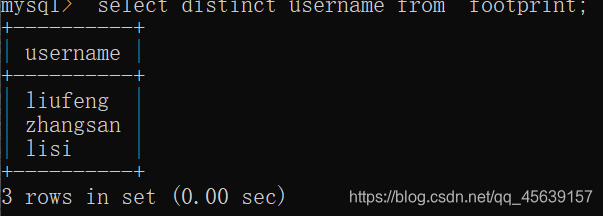
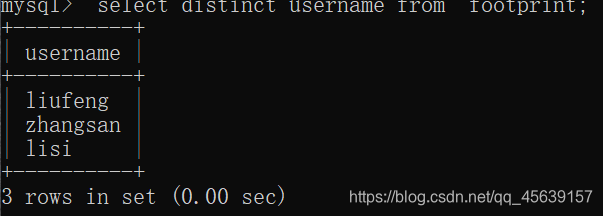
作用于两个列:
⑨表连接(连接内连接、外连接、自连接)
需求:比如我们在京东购买商品,其中商品的各项信息很可能不是来自于同一个表,所以这就涉及到多张表进行连接,连接成一张表之类的进行显示。连接肯定会涉及主键、外键之类的
什么是表连接:
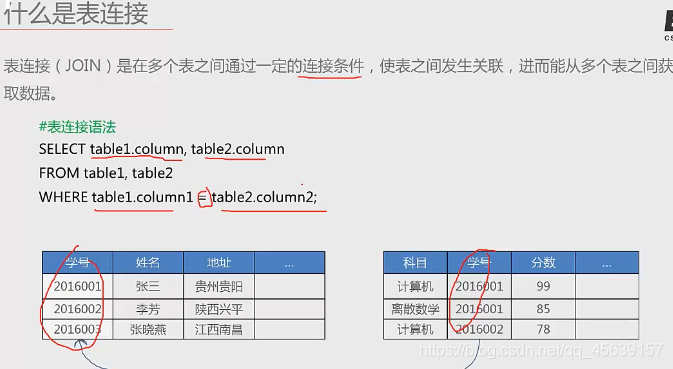
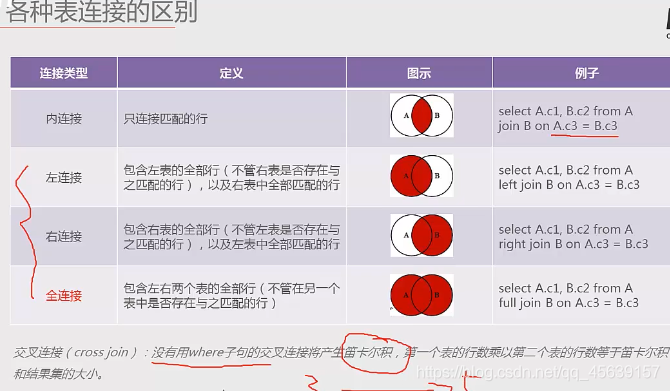
说明:mysql不支持全连接,左连接和右连接其实是类似的,本节课讲解内连接+左连接+自连接
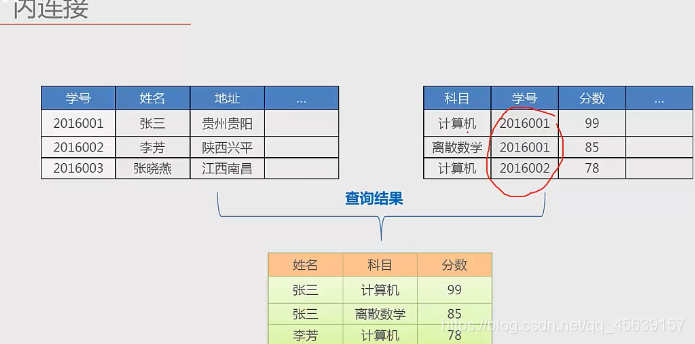
内连接应该是得通过主键与外键将两个表进行连接(关联起来),类似这样。通过学号得连接将两个表连接起来进行信息的显示。(两个表)
 左连接也是通过学号关联起来,但是左边表跟右边表没有关联的区域也能连接起来进行信息的显示。下图来说,左连接可以把那个没有成绩信息的张晓燕显示出来,即使他没有成绩(两个表)
左连接也是通过学号关联起来,但是左边表跟右边表没有关联的区域也能连接起来进行信息的显示。下图来说,左连接可以把那个没有成绩信息的张晓燕显示出来,即使他没有成绩(两个表)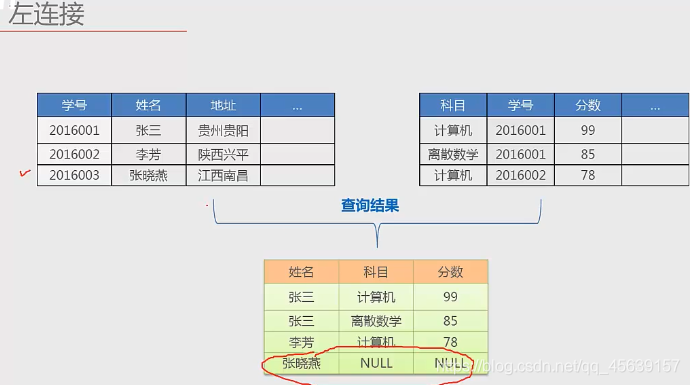
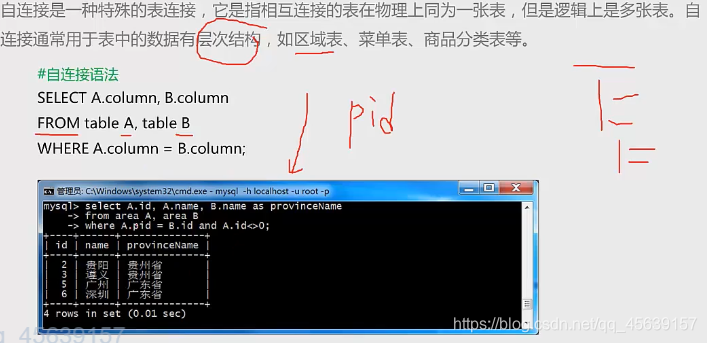
自连接相互连接的表在物理上同为一张表,但是逻辑上是多张表,自连接常用于数据有层次结构的。有一张存在市城市列和省名称的表。比如说下面那个例子,要得到市城市对应的省名称,就需要自连接 比如说菜单表,一级菜单下面有二级菜单、二级菜单下面有三级菜单。比如说商品分类,商品分为手机、家电、服装,服装由包括…(看不太懂 看下面自连接实例)
总结:所有表中具有有层次结构的,想要查询,可能会用到自连接
内连接+左连接 实例九:
有这样两张表
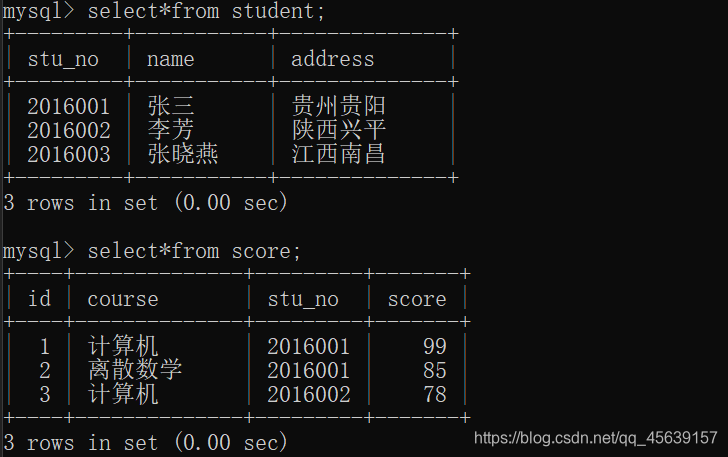
通过内连接(主键 外键)对两张表进行连接,有两种方法


通过左连接对两张表进行连接,这在对某学生没有成绩但是要显示他的信息情况下会使用

笛卡尔积演示
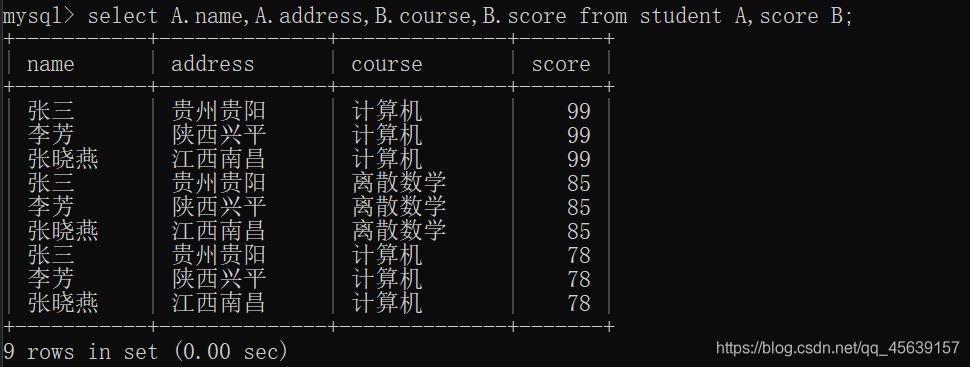
自连接 实例九:
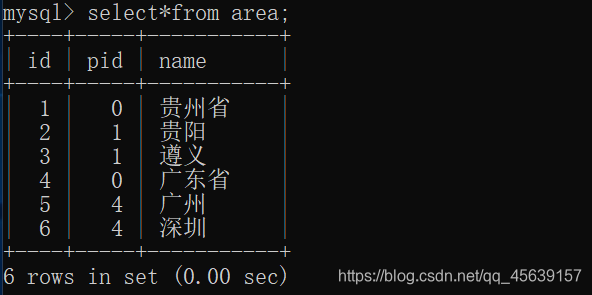
有这样一张表
可以发现:
①name字段为省份的 他的pid(逻辑上看作父id)为0,即证明他是省份。
②name字段为市城市的 同一省份的市城市pid为同一值,即证明它们属于同一个省份
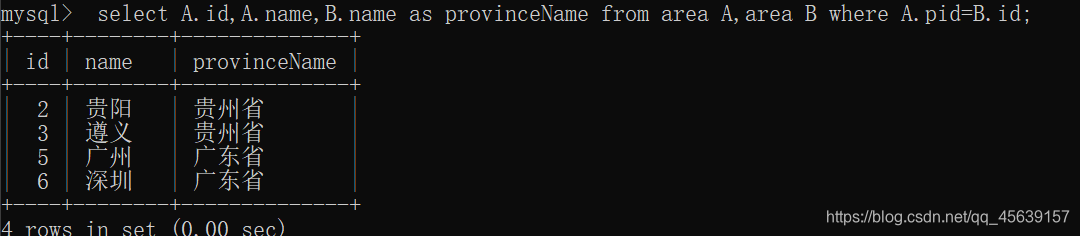
首先根据表的结构查询市城市有哪些

根据市城市父id 与 省份的关联关系进行连接
⑩子查询中的in exists
需求:算是基于表连接,我们希望选择所有选修了计算机课程的学生信息,也就是说筛选条件来自于另外一张表
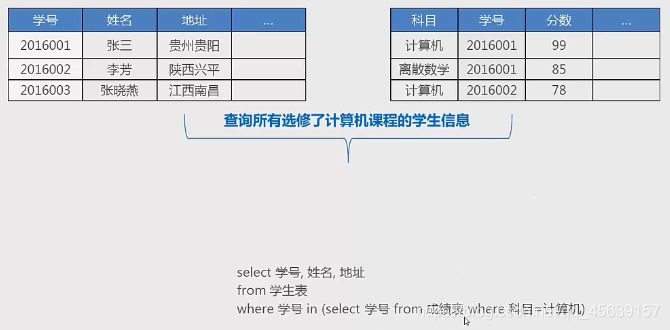
in运算符(之前已经接触过,通过配合where语句使用,筛选某张表中表信息)

exists运算符(in的用途他也可以实现 和in运算符熟悉掌握一个)
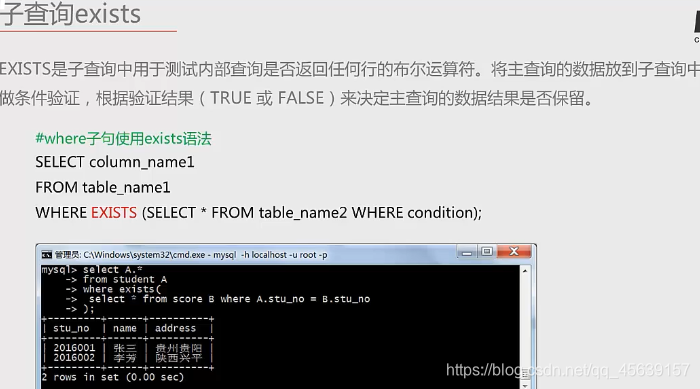
实例十
有这样两张表
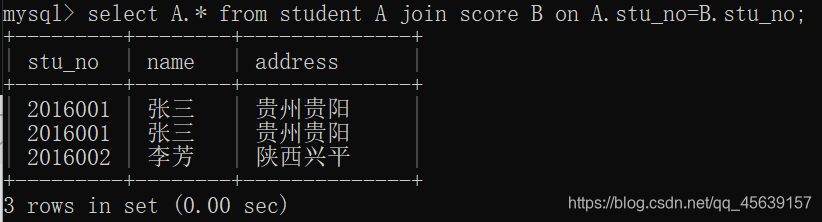
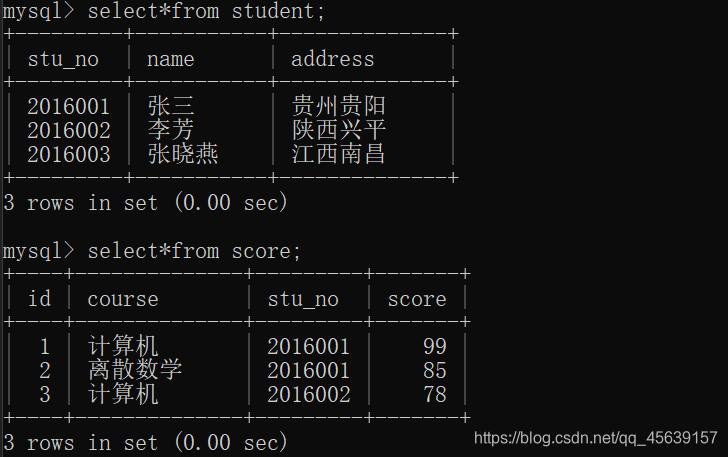 查询在成绩表中有成绩的学生信息(这用内连接也可以 只不过会造成重复数据)
查询在成绩表中有成绩的学生信息(这用内连接也可以 只不过会造成重复数据)

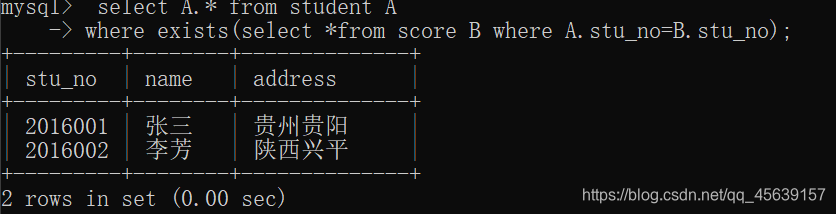
用exists,它返回的是一个布尔类型结果,in exists熟练掌握一个
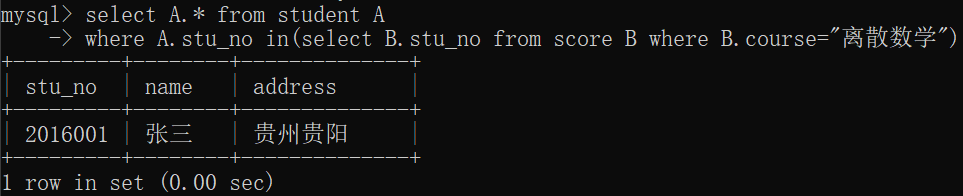
查询选修了离散数学的学生信息

















 929
929

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









