







一、简介
支持向量机(Support Vector Machines, SVM)试图在特征空间中找到最优的分割平面(或线)来分开两类样本,适用于分类和回归问题。
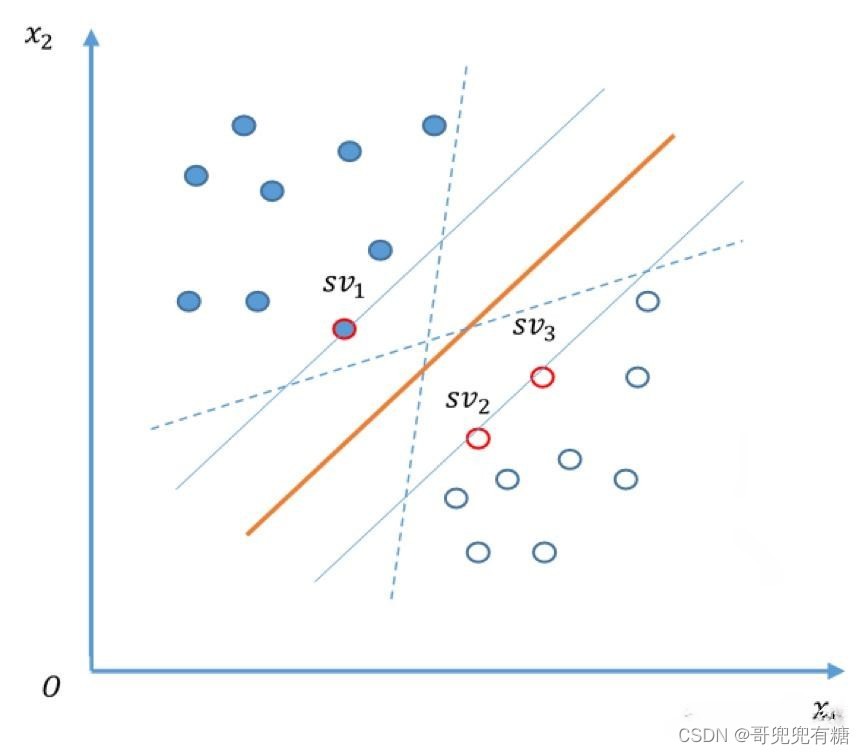
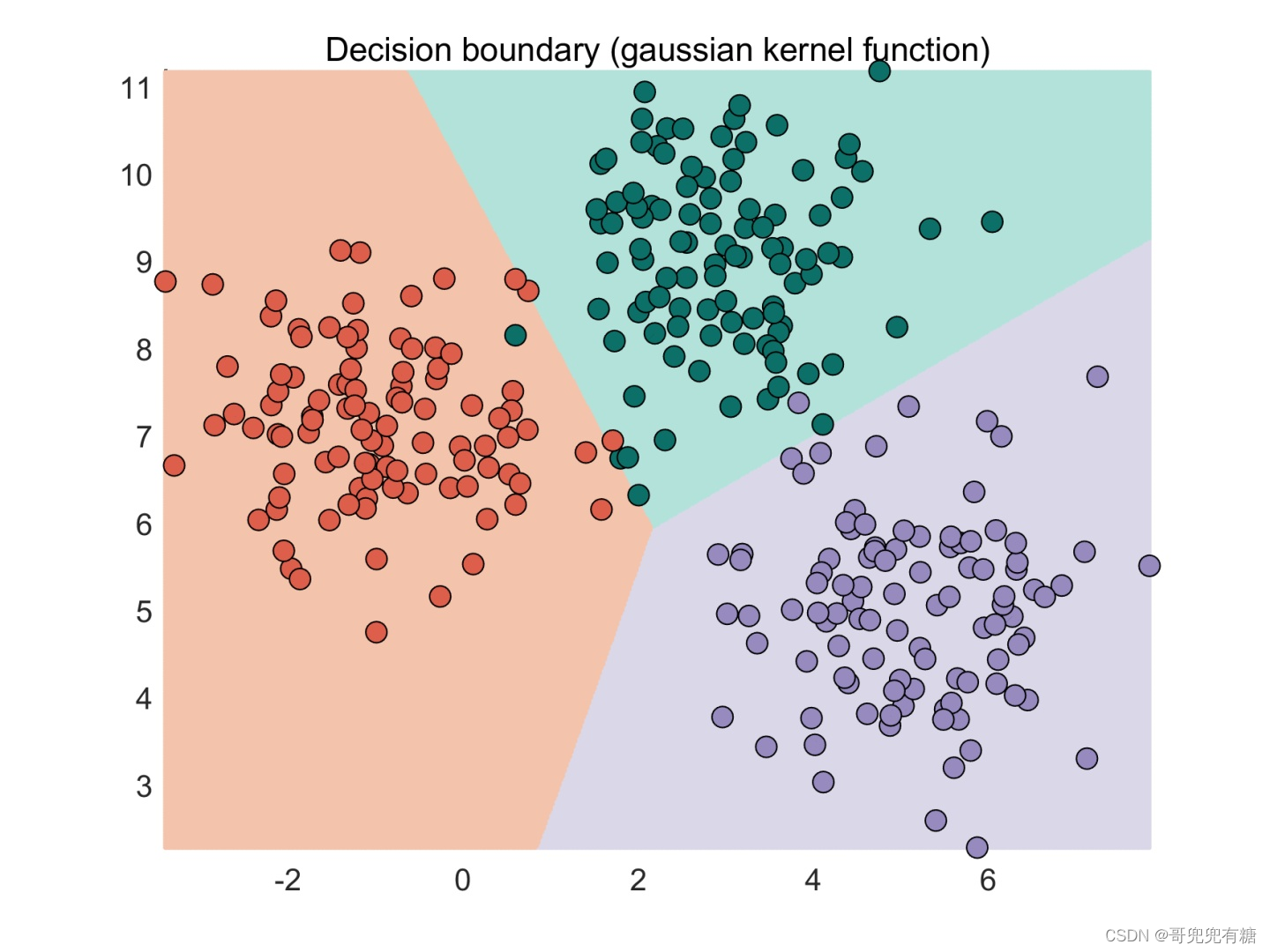
SVM是一种强大的分类算法,通过在数据点之间寻找最大间隔的决策边界来区分不同的类别。它使用支持向量,即距离边界最近的点,来确定这个边界。SVM通过核技巧处理非线性问题,将数据映射到高维空间以找到线性分隔面。常见的核函数包括线性核、多项式核和径向基函数核。SVM的训练是一个凸优化问题,旨在最大化间隔同时最小化误差。它对异常值和噪声具有鲁棒性,因为只有支持向量影响最终的决策边界。
二、代码实现
使用支持向量机SVM算法对鸢尾花数据集(iris)进行分类。
鸢尾花数据集(iris dataset)是一组用于机器学习的经典数据集之一。这个数据集由英国统计学家和生物学家Ronald Fisher在1936年收集和整理。
鸢尾花数据集包含了150个样本,每个样本包含了鸢尾花的四个特征:花萼长度(sepal length)、花萼宽度(sepal width)、花瓣长度(petal length)和花瓣宽度(petal width)。每个样本也有一个类标签,鸢尾花数据集包含三种类别:山鸢尾(Setosa)、变色鸢尾(Versicolor)和维吉尼亚鸢尾(Virginica)。

首先将数据集分割成训练集和测试集,然后创建一个SVM模型进行训练,并使用训练好的模型对测试集进行预测,最后计算预测准确率。
实现如下:
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
# 加载数据集
iris = datasets.load_iris()
X = iris.data
y = iris.target
# 将数据集分割成训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# 创建一个SVM模型并进行训练
svm = SVC()
svm.fit(X_train, y_train)
# 使用训练好的模型对测试集进行预测
y_pred = svm.predict(X_test)
# 计算预测准确率
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











