







 图注意力网络(GAT)引入了注意力机制,为每个节点分配不同权重,关注关键节点。其架构通过self-attention层解决图卷积问题,无需了解全图结构,在多个数据集上表现优秀。GAT包含图注意力层,计算注意力系数和加权求和,并采用multi-head attention机制。
图注意力网络(GAT)引入了注意力机制,为每个节点分配不同权重,关注关键节点。其架构通过self-attention层解决图卷积问题,无需了解全图结构,在多个数据集上表现优秀。GAT包含图注意力层,计算注意力系数和加权求和,并采用multi-head attention机制。
@TOC
一、INTRODUCTION
图注意力网络(GAT)Graph attention network缩写为GAT,若按照首字母大写,会与对抗生成网络GAN混淆。所以后面GAT即本文的图注意力网络。
论文地址 https://arxiv.org/abs/1710.10903
代码地址: https://github.com/Diego999/pyGAT
1.1 相关研究
- Semi-Supervised Classification with Graph Convolutional Networks,ICLR 2017,图卷积网络
- Graph Attention Networks,ICLR 2018. 图注意力网络
- Relational Graph Attention Networks ,ICLR2019 关联性图注意力网络,整合了GCN+Attention+Relational
1.2. attention 引入目的
- 为每个节点分配不同权重
- 关注那些作用比较大的节点,而忽视一些作用较小的节点
- 在处理局部信息的时候同时能够关注整体的信息,不是用来给参与计算的各个节点进行加权的,而是表示一个全局的信息并参与计算
2 GAT ARCHITECTURE
本文作者提出GATs方法,利用一个隐藏的self-attention层,来处理一些图卷积中的问题。不需要复杂的矩阵运算或者对图结构的事先了解,通过叠加self-attention层,在卷积过程中将不同的重要性分配给邻域内的不同节点,同时处理不同大小的邻域。作者分别设计了inductive setting和transductive setting的任务实验,GATs模型在基线数据集Cora、Citeseer、Pubmed citation和PPI数据集上取得了state-of-the-art的结果。
2.1 Graph Attentional Layer
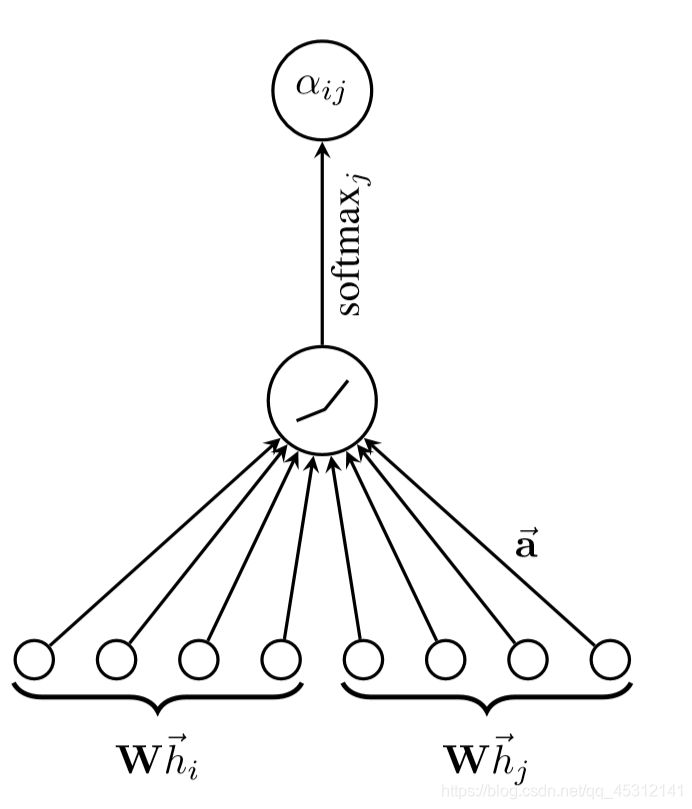
和所有的attention mechanism一样,GAT的计算也分为两步:计算注意力系数(attention coefficient)和加权求和(aggregate)

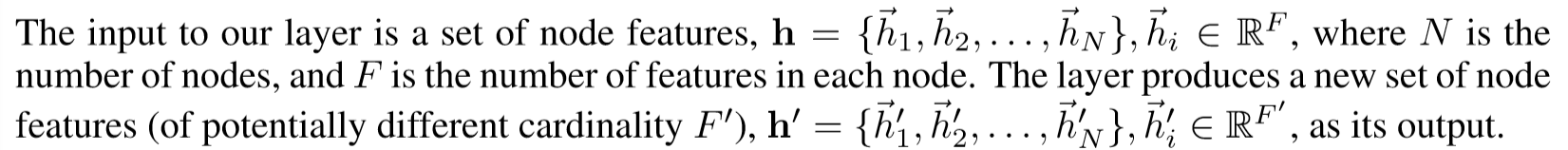
2.2. 计算相互关注



def forward(self, x):
# [B_batch,N_nodes,C_channels]
B, N, C = x.size()
# h = torch.bmm(x, self.W.expand(B, self.in_features, self.out_features)) # [B,N,C]
h = torch.matmul(x, self.W 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2717
2717

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









