







 本文介绍了Python中的推导式,包括列表推导式、集合和字典推导式,以及它们与高阶函数的对比。接着,详细探讨了生成器的定义和特性,包括如何通过表达式和函数定义生成器,以及send函数的使用。此外,还讨论了多线程交叉执行和greenlet完成多任务,并阐述了迭代器的概念,包括可迭代对象、迭代器和生成器之间的关系。
本文介绍了Python中的推导式,包括列表推导式、集合和字典推导式,以及它们与高阶函数的对比。接着,详细探讨了生成器的定义和特性,包括如何通过表达式和函数定义生成器,以及send函数的使用。此外,还讨论了多线程交叉执行和greenlet完成多任务,并阐述了迭代器的概念,包括可迭代对象、迭代器和生成器之间的关系。
Python推导式&迭代器
推导式
列表推导式
- 列表生成式(推导式)即List Comprehensions,是Python内置的非常简单却强大的可以用来创建list的生成式。
- 列表表达式可以是任意的,意思是你可以在列表中放入任意类型的对象。返回结果将是一个新的列表,在这个以if和for语句为上下文的表达式运行完成之后产生。
- 列表推导式:格式:[表达式 fo r变量 in 旧列表]或者[表达式 for 变量 in 旧列表 if条件]
#过滤掉长度小于或者等于3的人名
names = ['tom','lily', 'abc','jack','steven','bob','ha']
result = [name for name in names if len (name) > 3]
result = [name.capitalize() for name in names if len (name) > 3]
#capitalize()单词首字母大写
#100以内可以被3和5整除的数
newlist = [i for i in range(1, 101) if i%3 == O and i%5 == 0]
print (newlist)
#[(偶数,奇数),(), (), ()] [(0,1), (0,3),(0,5),(0, 7),(0,9),(2, 1),(2, 3)...]
newlist=[(x,y)for x in range(5) if x%2 == 0 for y in range(10) if y%2 != 0]
print (newlist)
# listl =[[1,2,3],[4,5,6],[7,8,9],[1,3,5]] --->[3, 6, 9, 5]
listl = [[1, 2, 3],[4, 5,6],[7,8, 9],[1, 3, 5]]
newlist = [i[-1] for i in list1]
#if薪资大于5000加200,低于等于5000加500
dictl = {'name' :'tom','salary': 5000}
dict2 = {'name' :'lucy','salary': 8000}
dict3 = {'name';'jack','salary' : 4500}
dict4 = {' name' :'lily','salary' : 3000}
list1 = [dict1, dict2, dict3, dict4]
newlist = [employte['salary'] + 200 if employee[' salary' ] > 5000 else employee[' salary'] + 500 for employee in list1]
案例解析
#接收变量k,a,b
s = '51 5000 10000'
li2=[int(item) for item in s.split()]
#生成一个列表,列表元素分别为[1**1,2**2,3**3,4**4...n*n]
li1 = [i**i for i in range(1,8)]
# 找出1~8中的偶数的平方
li = [i ** 2 for i in range(1, 8) if i % 2 == 0]
# s1='ABC' s2='123'(for嵌套循环)
# 生成'A1', 'A2', 'A3', 'B1', 'B2', 'B3', 'C1', 'C2', 'C3'
[i + j for i in 'ABC' for j in '123']
#将3x3的矩阵转换成一堆数组
#[[1,2,3],[4,5,6],[7,8,9]]---->[1,2,3,4,5,6,7,8,9]
[j for i in li for j in i]
将列表中所有内容都变成小写
li = ['dasdaFSDFSFDSF','dadDSADSAsdaDASsadas']
[i.lower() for i in li]
#找出1~10之间所有偶数, 并且返回一个列表,(包含以这个偶数为半径的圆的面积)
import math ##导入数学模块
[math.pi * r * r for r in range(2, 11, 2)]
集合&字典推导式
集合推导式
集合推导式和列表推导式类似,不同之处在于:
- 外面的括号换成大括号
- 不能存在相同的元素
listl = [1, 2,1,3,5,2, 1,8,9,8,1]
setl = {x+1 for x in listl}
print (set1)
字典推导式
如果存在键值相同的情况,后出现的键值会覆盖之前相同的键值
#将键和值进行调换
dict1 = {'a' : 'A', 'b' : 'B','c' : 'C', 'd' : 'C' }
newdict = {value:key for key, value in dict1.items()}
print(newdict)
# 用字典定义20个学生名字,成绩
stuInfo = {'westos'+ str(i):random.randint(60,100) for i in range(20)}
#大小写key值合并,统一以小写输出
d = dict(a=2, b=1, c=2, B=9, A=10)
{k.lower(): d.get(k.lower(), 0) + d.get(k.upper(), 0) for k in d}
列表生成式和高阶函数的对比
实例1:把一个列表中所有的字符串转换成小写,非字符串元素原样保留
# 用列表生成式实现
L = ['TOM', 'Peter', 10, 'Jerry']
list1 = [x.lower() if isinstance(x, str) else x for x in L]
# 用map()函数实现
list2 = list(map(lambda x: x.lower() if isinstance(x, str) else x, L))
实例2:把一个列表中所有的字符串转换成小写,非字符串元素移除
L = ['TOM', 'Peter', 10, 'Jerry']
# 用列表生成式实现
list3 = [x.lower() for x in L if isinstance(x, str)]
# 用map()和filter()函数实现
list4 = list(map(lambda x: x.lower(), filter(lambda x: isinstance(x, str), L)))
对于大部分需求来讲,使用列表生成式和使用高阶函数都能实现。但是map()和filter()等一些高阶函数在Python3中的返回值类型变成了Iteraotr(迭代器)对象(在Python2中的返回值类型为list),这对于那些元素数量很大或无限的可迭代对象来说显然是更合适的,因为可以避免不必要的内存空间浪费。关于迭代器的概念,下面会单独进行说明。

生成器
- 通过列表生成式(列表推导式),我们可以直接创建一个列表。但是,受到内存限制,列表容量肯定是有限的。
- 而且,创建一个包含100万个元素的列表,不仅占用很大的存储空间,如果我们仅仅需要访问前面几个元素,那后面绝大多数元素占用的空间都白白浪费了。
- 所以,如果列表元素可以按照某种算法推算出来,那我们是否可以在循环的过程中不断推算出后续的元素呢?
- 这样就不必创建完整的list,从而节省大量的空间。在Python中, 这种边循环边计算的机制,称为生成器:generator。
生成器的特性
- 只有在调用时才会生成相应的数据
- 只记录当前的位置
- 只能next,不能prev
定义生成器方式一:表达式
newlist = [x*3 for x in range(20)]
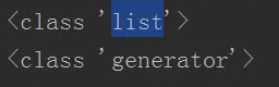
print (type (newlist))
#得到生成器
g =(x*3 for X in range(20))
print(type(g)) #senerator
由于生成器中的值都是边调用边生成的,所以只能一次一次的调用,调用方式有两种
#方式1:通过调用_next__()方式得到元素
print(g.__next__())
#方式2:next()
print(next(g))
#StopItertion生成器本来就可以产生10个.得到了10个东调用netlea, 抛出异常
如果调用的个数超出生成器的范围会出现StopItertion类型的报错
g =(x*3 for x in range(10))
while True:
try:
e = next
e = next(g)
print(e)
except:
print('没有更多元素啦!')
break
定义生成器的方式二:借助函数完成
步骤:
- 定义一个函数,函数中使用yield关键字
- 调用函数,接收调用的结果
- 得到的结果就是生成器
- 借助于next() ,__ next__()得到元素
#只要函数中出现了yield关键字,说明函数就不是函数啦,变成生成器啦
#菲波那切数列
def func() :
n=0
while True:
n+=1
yield n
func()
g = func()
print(g)
print(next(g))
...
2.创建生成器的方法2(定义一个函数,让这个函数变成生成器)
"""
如果在调用函数的时候,发现这个函数中有yeild
那么此时,也就不是调用函数了,而是创建了一个生成器对象
"""
def creat_num(all_num):
print('~~~~~~~~~~~1~~~~~~~~~~~~~~~~~')
a,b=0,1
current_num = 0
while current_num < all_num:
print('~~~~~~~~~2~~~~~~~~~~~~~~~~~')
yield a # 相当于暂停了程序
#print(a)
print('~~~~~~~~~~~~~~3~~~~~~~~~~~~')
a,b = b,b+a
current_num += 1
print('~~~~~~~~~~~4~~~~~~~~~~~~~~~~')
obj = creat_num(5) ##调用函数,但没有执行函数,只是产生一个生成器
res=next(obj) ##执行函数到yield a,返回一个a的值后暂停
print(res) ##打印出返回的a的值
案例解析
def fib(length) :
a,b = 0,1
n=0
while n < length:
print(b)
yield b
a,b = b,a+b
n+=1
g=fib(8)
send函数
#生成器方法:
#__next_ (): 获取下一个元素
#send(value):向每次生成器调用中传值
def gen():
i=0
while i < 5:
temp=yield i #return1+暂停
print( 'temp:',temp)
for i in range(temp) :
print(' -------->’、i)
print ( **************** )
i+=1
return '没有更多的数据'
g= gen()
# g.__ next__()
print(g.send(None))
n1=g.send('呵呵')
print( n1:'n1')
n2 = g.send('哈哈')
print ('n2':n2)
#使用send唤醒程序
#使用send()函数来唤醒程序执行,使用send()函数的好处是
#可以在唤醒的同时向断点中传入一个附加的数据
"""
def create_num(all_num):
a,b = 0,1
current_num = 0
while current_num < all_num:
ret = yield a
print('>>>>>>>>ret>>>>>>>',ret)
a,b = b,a+b
current_num += 1
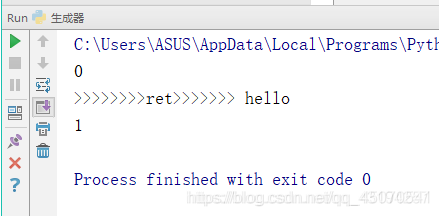
obj = create_num(100)
red = obj.send(None) ##调用函数到ret = yield a,并将a的值返回给red,同时将None赋值给ret
print(red)
red1 = obj.send('hello')
print(red1)
next和send的区异同
- next和send得到的都是yield后面的值 不
- 同的是send传递值而next不传递值
注意:
- 不能把send放在第一个,因为send只能将值传给上一个yield所在位置 第一次执行程序是从开始执行 并没有值来接收send,如果你非要把send放在第一个,那么传递的值应该是None
多线程交叉执行
def task1():
for i in range(n) :
print("正在搬第{}块砖!".format(i))
yield None
def task2(n) :
for i in range(n) :
print("正在听第{}首歌!” . format(i))
yield None
g1= task1(10)
g2 =task2 (5)
while True:
try :
g1.__next__ ()
g2.__next__ ()
except:
pass
单线程并发
import time
def consumer(name):
print('%s 准备学习了~' %(name))
while True:
lesson = yield
print('开始[%s]了,[%s]老师来讲课了~' %(lesson,name))
def producer(name):
c1 = consumer('A')
c2 = consumer('B')
c1.__next__() ##先调用c1使后面的send能够传值
c2.__next__() ##先调用c2使后面的send能够传值
print('同学们开始上课了~')
for i in range(10):
time.sleep(1)
print('到了两个同学')
c1.send(i)
c2.send(i)
producer('westos')
#利用了关键字yield一次性返回一个结果,阻塞,重新开始
#send 唤醒
greenlet完成多任务
安装
#在terminal中进行安装
pip install greenlet
案例解析
#使用greenlet完成多任务
#为了更好的使用协程来完成多任务,python中的greeblet模块
#对其进行的封装
from greenlet import greenlet
import time
def test1():
while True:
print('---A----')
gr2.switch()
time.sleep(0.5)
def test2():
while True:
print('----B----')
gr1.switch()
time.sleep(0.5)
#greenlet这个类对yield进行的封装
gr1= greenlet(test1)
gr2 = greenlet(test2)
#相当于开关,开启后两个函数之间能够相互切换执行
gr1.switch()

迭代器
可迭代对象
可迭代的对象:
- 生成器
- 集合数据类型:如list、tuple、dict、set、str等
#如何判断一个对象是否是可迭代?
from collections import Iterable
listl=[1,4,7,8,8]
f = isinstance(listl, Iterable)
print (f) #True
f = isinstance('abc',Iterable)
print (f) #True
f = isinstance(100, Iterable)
print (f) #Fale
迭代器
- 可以被next()函数调用并不断返回下一个值的对象称为迭代器:Iterator。
- 迭代是访问集合元素的一种方式。迭代器是一个可以记住遍历的位置的对象。
- 迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。
- 迭代器只能往常不会后退。
- 可以被next(函数调用并不断返回下一个值的对象称为迭代器: Iterator。
list转换成迭代器
g =(x+1 for x in range(10))
f = isinstance(g,Iterable)
print (f)
可迭代的是不是肯定就是 迭代器?
listl=[1,2,3,4,5]
print(next(list1))
print(next(list1))
Iterable、Iterator与Generator之间的关系
-
生成器对象既是可迭代对象,也是迭代器: 我们已经知道,生成器不但可以作用与for循环,还可以被next()函数不断调用并返回下一个值,直到最后抛出StopIteration错误表示无法继续返回下一个值了。也就是说,生成器同时满足可迭代对象和迭代器的定义;
-
迭代器对象一定是可迭代对象,反之则不一定: 例如list、dict、str等集合数据类型是可迭代对象,但不是迭代器,但是它们可以通过iter()函数生成一个迭代器对象。
-
也就是说:迭代器、生成器和可迭代对象都可以用for循环去迭代,生成器和迭代器还可以被next()方函数调用并返回下一个值。

















 1136
1136

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









