







 本文介绍了Python中KNN算法实现性别预测,通过数据标准化处理后,利用KNN进行分类。接着展示了决策树的构建过程,包括数据集划分、信息熵计算、最佳特征选择等步骤,用于判断是否进行活动。最后,使用朴素贝叶斯算法对异常账户进行检测,训练模型并预测新用户类型。
本文介绍了Python中KNN算法实现性别预测,通过数据标准化处理后,利用KNN进行分类。接着展示了决策树的构建过程,包括数据集划分、信息熵计算、最佳特征选择等步骤,用于判断是否进行活动。最后,使用朴素贝叶斯算法对异常账户进行检测,训练模型并预测新用户类型。
数据挖掘-数据分类 python实现
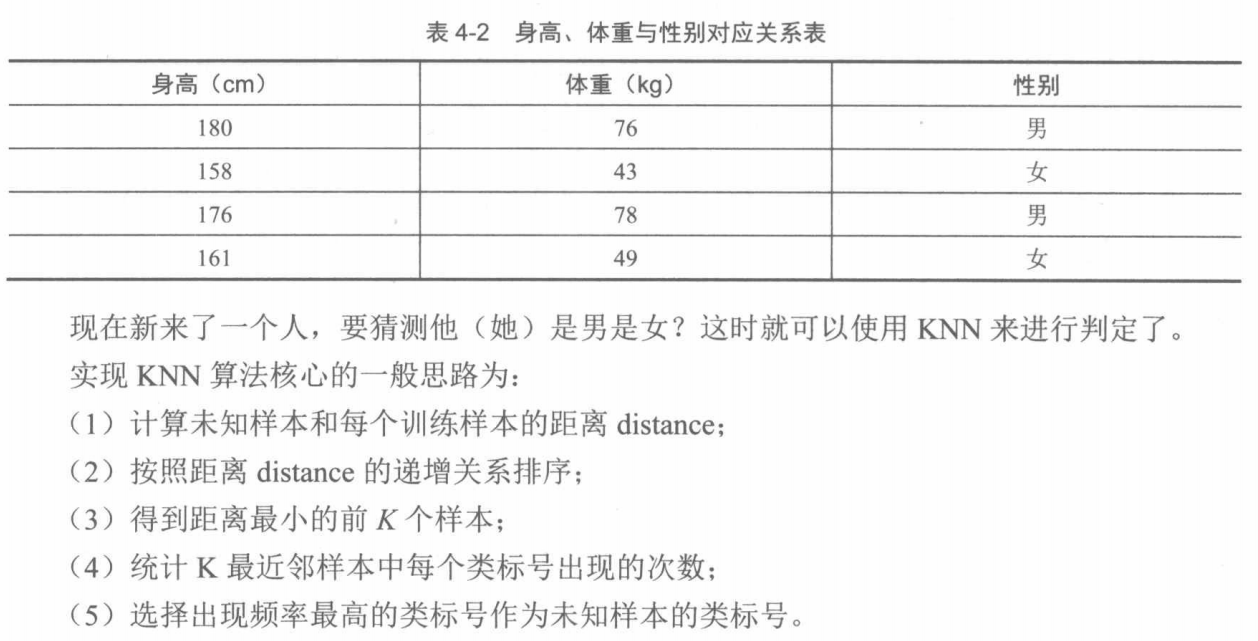
利用KNN实现性别判定
# -*-coding:utf-8-*-
"""
Author: Thinkgamer
Desc:
代码4-5 利用KNN算法实现性别预测
"""
import numpy as np
class KNN:
def __init__(self, k):
# k为最近邻个数
self.K = k
# 准备数据
def createData(self):
features = np.array([[180, 76], [158, 43], [176, 78], [161, 49]])
labels = ["男", "女", "男", "女"]
return features, labels
# 数据进行Min-Max标准化
def Normalization(self, data):
maxs = np.max(data, axis=0)
mins = np.min(data, axis=0)
new_data = (data - mins) / (maxs - mins)
return new_data, maxs, mins
# 计算k近邻
def classify(self, one, data, labels):
# 计算新样本与数据集中每个样本之间的距离,这里距离采用的欧式距离计算方法
differenceData = data - one
squareData = (differenceData ** 2).sum(axis=1)
distance = squareData ** 0.5
sortDistanceIndex = distance.argsort()
# 统计K近邻的label
labelCount = dict()
for i in range(self.K):
label = labels[sortDistanceIndex[i]]
labelCount.setdefault(label, 0)
labelCount[label] += 1
# 计算结果
sortLabelCount = sorted(labelCount.items(), key=lambda x: x[1], reverse=True)
print(sortLabelCount)
return sortLabelCount[0][0]
if __name__ == "__main__":
# 初始化类对象
knn = KNN(3)
# 创建数据集
features, labels = knn.createData()
# 数据集标准化
new_data, maxs, mins = knn.Normalization(features)
# 新数据的标准化
one = np.array([176, 76])
new_one = (one - mins) / (maxs - mins)
# 计算新数据的性别
result = knn.classify(new_one, new_data, labels)
print("数据 {} 的预测性别为 : {}".format(one, result))
结果
[('男', 2), ('女', 1)]
数据 [176 76] 的预测性别为 : 男
决策树
# -*-coding:utf-8-*-
"""
Author: Thinkgamer
Desc:
代码4-6 构建是否进行活动的决策树
"""
import operator
import math
class DecisionTree:
def __init__(self):
pass
# 加载数据集
def loadData(self):
# 天气晴(2),阴(1),雨(0);温度炎热(2),适中(1),寒冷(0);湿度高(1),正常(0)
# 风速强(1),弱(0);进行活动(yes),不进行活动(no)
# 创建数据集
data = [
[2, 2, 1, 0, "yes"],
[2, 2, 1, 1, "no"],
[1, 2, 1, 0, "yes"],
[0, 0, 0, 0, "yes"],
[0, 0, 0, 1, "no"],
[1, 0, 0, 1, "yes"],
[2, 1, 1, 0, "no"],
[2, 0, 0, 0, "yes"],
[0, 1, 0, 0, "yes"],
[2, 1, 0, 1, "yes"],
[1, 2, 0, 0, "no"],
[0, 1, 1, 1, "no"],
]
# 分类属性
features = ["天气", "温度", "湿度", "风速"]
return data, features
# 计算给定数据集的香农熵
def ShannonEnt(self, data):
numData = len(data) # 求长度
labelCounts = {}
for feature in data:
oneLabel = feature[-1] # 获得标签
# 如果标签不在新定义的字典里创建该标签值
labelCounts.setdefault(oneLabel, 0)
# 该类标签下含有数据的个数
labelCounts[oneLabel] += 1
shannonEnt = 0.0
for key in labelCounts:
# 同类标签出现的概率
prob = float(labelCounts[key]) / numData
# 以2为底求对数
shannonEnt -= prob * math.log2(prob)
return shannonEnt
# 划分数据集,三个参数为带划分的数据集,划分数据集的特征,特征的返回值
def splitData(self, data, axis, value):
retData = []
for feature in data:
if feature[axis] == value:
# 将相同数据集特征的抽取出来
reducedFeature = feature[:axis]
reducedFeature.extend(feature[axis + 1 :])
retData.append(reducedFeature)
return retData # 返回一个列表
# 选择最好的数据集划分方式
def chooseBestFeatureToSplit(self, data):
numFeature = len(data[0]) - 1
baseEntropy = self.ShannonEnt(data)
bestInfoGain = 0.0
bestFeature = -1
for i in range(numFeature):
# 获取第i个特征所有的可能取值
featureList = [result[i] for result in data]
# 从列表中创建集合,得到不重复的所有可能取值
uniqueFeatureList = set(featureList)
newEntropy = 0.0
for value in uniqueFeatureList:
# 以i为数据集特征,value为返回值,划分数据集
splitDataSet = self.splitData( data, i, value )
# 数据集特征为i的所占的比例
prob = len(splitDataSet) / float(len(data))
# 计算每种数据集的信息熵
newEntropy += prob * self.ShannonEnt(splitDataSet)
infoGain = baseEntropy - newEntropy
# 计算最好的信息增益,增益越大说明所占决策权越大
if infoGain > bestInfoGain:
bestInfoGain = infoGain
bestFeature = i
return bestFeature
# 递归构建决策树
def majorityCnt(self, labelsList):
labelsCount = {}
for vote in labelsList:
if vote not in labelsCount.keys():
labelsCount[vote] = 0
labelsCount[vote] += 1
sortedLabelsCount = sorted(
labelsCount.iteritems(), key=operator.itemgetter(1), reverse=True
) # 排序,True升序
# 返回出现次数最多的
print(sortedLabelsCount)
return sortedLabelsCount[0][0]
# 创建决策树
def createTree(self, data, features):
# 使用"="产生的新变量,实际上两者是一样的,避免后面del()函数对原变量值产生影响
features = list(features)
labelsList = [line[-1] for line in data]
# 类别完全相同则停止划分
if labelsList.count(labelsList[0]) == len(labelsList):
return labelsList[0]
# 遍历完所有特征值时返回出现次数最多的
if len(data[0]) == 1:
return self.majorityCnt(labelsList)
# 选择最好的数据集划分方式
bestFeature = self.chooseBestFeatureToSplit(data)
bestFeatLabel = features[bestFeature] # 得到对应的标签值
myTree = {bestFeatLabel: {}}
# 清空features[bestFeat],在下一次使用时清零
del (features[bestFeature])
featureValues = [example[bestFeature] for example in data]
uniqueFeatureValues = set(featureValues)
for value in uniqueFeatureValues:
subFeatures = features[:]
# 递归调用创建决策树函数
myTree[bestFeatLabel][value] = self.createTree(
self.splitData(data, bestFeature, value), subFeatures
)
return myTree
# 预测新数据特征下是否进行活动
def predict(self, tree, features, x):
for key1 in tree.keys():
secondDict = tree[key1]
# key是根节点代表的特征,featIndex是取根节点特征在特征列表的索引,方便后面对输入样本逐变量判断
featIndex = features.index(key1)
# 这里每一个key值对应的是根节点特征的不同取值
for key2 in secondDict.keys():
# 找到输入样本在决策树中的由根节点往下走的路径
if x[featIndex] == key2:
# 该分支产生了一个内部节点,则在决策树中继续同样的操作查找路径
if type(secondDict[key2]).__name__ == "dict":
classLabel = self.predict(secondDict[key2], features, x)
# 该分支产生是叶节点,直接取值就得到类别
else:
classLabel = secondDict[key2]
return classLabel
if __name__ == "__main__":
dtree = DecisionTree()
data, features = dtree.loadData()
myTree = dtree.createTree(data, features)
print(myTree)
label = dtree.predict(myTree, features, [1, 1, 1, 0])
print("新数据[1,1,1,0]对应的是否要进行活动为:{}".format(label))
结果
{'湿度': {0: {'温度': {0: {'天气': {0: {'风速': {0: 'yes', 1: 'no'}}, 1: 'yes', 2: 'yes'}}, 1: 'yes', 2: 'no'}}, 1: {'天气': {0: 'no', 1: 'yes', 2: {'温度': {1: 'no', 2: {'风速': {0: 'yes', 1: 'no'}}}}}}}}
新数据[1,1,1,0]对应的是否要进行活动为:yes
改进决策树,加入树状图
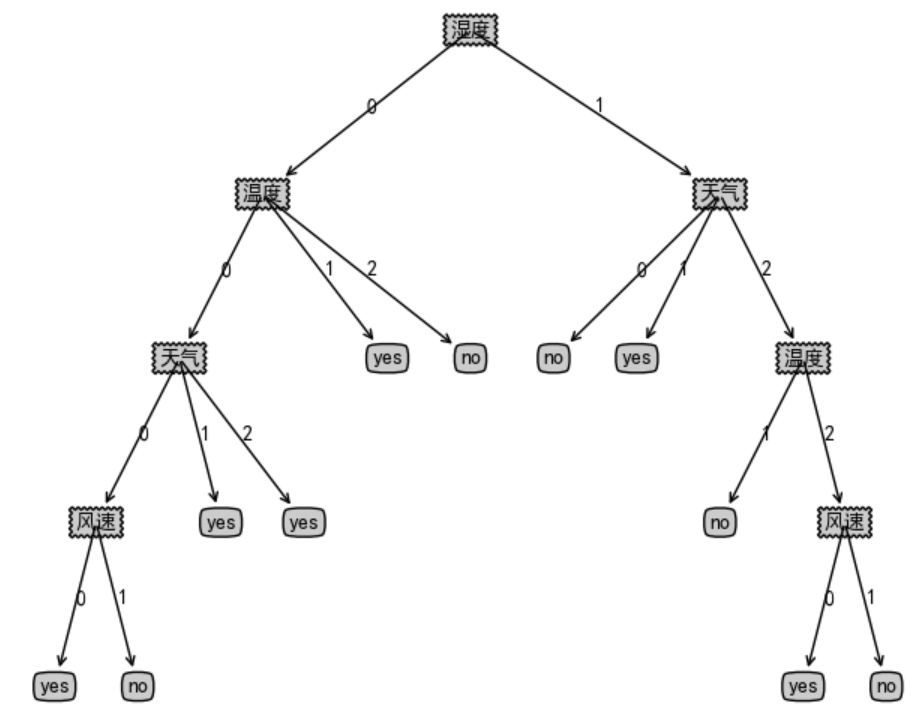
# -*-coding:utf-8-*-
"""
Author: Thinkgamer
Desc:
代码4-6 构建是否进行活动的决策树
"""
import operator
import math
import matplotlib.pyplot as plt
class DecisionTree:
def __init__(self):
pass
# 加载数据集
def loadData(self):
# 天气晴(2),阴(1),雨(0);温度炎热(2),适中(1),寒冷(0);湿度高(1),正常(0)
# 风速强(1),弱(0);进行活动(yes),不进行活动(no)
# 创建数据集
data = [
[2, 2, 1, 0, "yes"],
[2, 2, 1, 1, "no"],
[1, 2, 1, 0, "yes"],
[0, 0, 0, 0, "yes"],
[0, 0, 0, 1, "no"],
[1, 0, 0, 1, "yes"],
[2, 1, 1, 0, "no"],
[2, 0, 0, 0, "yes"],
[0, 1, 0, 0, "yes"],
[2, 1, 0, 1, "yes"],
[1, 2, 0, 0, "no"],
[0, 1, 1, 1, "no"],
]
# 分类属性
features = ["天气", "温度", "湿度", "风速"]
return data, features
# 计算给定数据集的香农熵
def ShannonEnt(self, data):
numData = len(data) # 求长度
labelCounts = {}
for feature in data:
oneLabel = feature[-1] # 获得标签
# 如果标签不在新定义的字典里创建该标签值
labelCounts.setdefault(oneLabel, 0)
# 该类标签下含有数据的个数
labelCounts[oneLabel] += 1
shannonEnt = 0.0
for key in labelCounts:
# 同类标签出现的概率
prob = float(labelCounts[key]) / numData
# 以2为底求对数
shannonEnt -= prob * math.log2(prob)
return shannonEnt
# 划分数据集,三个参数为带划分的数据集,划分数据集的特征,特征的返回值
def splitData(self, data, axis, value):
retData = []
for feature in data:
if feature[axis] == value:
# 将相同数据集特征的抽取出来
reducedFeature = feature[:axis]
reducedFeature.extend(feature[axis + 1 :])
retData.append(reducedFeature)
return retData # 返回一个列表
# 选择最好的数据集划分方式
def chooseBestFeatureToSplit(self, data):
numFeature = len(data[0]) - 1
baseEntropy = self.ShannonEnt(data)
bestInfoGain = 0.0
bestFeature = -1
for i in range(numFeature):
# 获取第i个特征所有的可能取值
featureList = [result[i] for result in data]
# 从列表中创建集合,得到不重复的所有可能取值
uniqueFeatureList = set(featureList)
newEntropy = 0.0
for value in uniqueFeatureList:
# 以i为数据集特征,value为返回值,划分数据集
splitDataSet = self.splitData( data, i, value )
# 数据集特征为i的所占的比例
prob = len(splitDataSet) / float(len(data))
# 计算每种数据集的信息熵
newEntropy += prob * self.ShannonEnt(splitDataSet)
infoGain = baseEntropy - newEntropy
# 计算最好的信息增益,增益越大说明所占决策权越大
if infoGain > bestInfoGain:
bestInfoGain = infoGain
bestFeature = i
return bestFeature
# 递归构建决策树
def majorityCnt(self, labelsList):
labelsCount = {}
for vote in labelsList:
if vote not in labelsCount.keys():
labelsCount[vote] = 0
labelsCount[vote] += 1
sortedLabelsCount = sorted(
labelsCount.iteritems(), key=operator.itemgetter(1), reverse=True
) # 排序,True升序
# 返回出现次数最多的
print(sortedLabelsCount)
return sortedLabelsCount[0][0]
# 创建决策树
def createTree(self, data, features):
# 使用"="产生的新变量,实际上两者是一样的,避免后面del()函数对原变量值产生影响
features = list(features)
labelsList = [line[-1] for line in data]
# 类别完全相同则停止划分
if labelsList.count(labelsList[0]) == len(labelsList):
return labelsList[0]
# 遍历完所有特征值时返回出现次数最多的
if len(data[0]) == 1:
return self.majorityCnt(labelsList)
# 选择最好的数据集划分方式
bestFeature = self.chooseBestFeatureToSplit(data)
bestFeatLabel = features[bestFeature] # 得到对应的标签值
myTree = {bestFeatLabel: {}}
# 清空features[bestFeat],在下一次使用时清零
del (features[bestFeature])
featureValues = [example[bestFeature] for example in data]
uniqueFeatureValues = set(featureValues)
for value in uniqueFeatureValues:
subFeatures = features[:]
# 递归调用创建决策树函数
myTree[bestFeatLabel][value] = self.createTree(
self.splitData(data, bestFeature, value), subFeatures
)
return myTree
# 预测新数据特征下是否进行活动
def predict(self, tree, features, x):
for key1 in tree.keys():
secondDict = tree[key1]
# key是根节点代表的特征,featIndex是取根节点特征在特征列表的索引,方便后面对输入样本逐变量判断
featIndex = features.index(key1)
# 这里每一个key值对应的是根节点特征的不同取值
for key2 in secondDict.keys():
# 找到输入样本在决策树中的由根节点往下走的路径
if x[featIndex] == key2:
# 该分支产生了一个内部节点,则在决策树中继续同样的操作查找路径
if type(secondDict[key2]).__name__ == "dict":
classLabel = self.predict(secondDict[key2], features, x)
# 该分支产生是叶节点,直接取值就得到类别
else:
classLabel = secondDict[key2]
return classLabel
def getNumLeaves(myTree):
numLeaves = 0
firstStr = list(myTree.keys())[0]
nextDict = myTree[firstStr]
for key in nextDict.keys():
if type(nextDict[key]).__name__ == 'dict':
numLeaves += getNumLeaves(nextDict[key])
else:
numLeaves += 1
return numLeaves
def getDepthTree(myTree):
depthTree = 0
firststr = list(myTree.keys())[0]
nextDict = myTree[firststr]
for key in nextDict.keys():
if type(nextDict[key]).__name__ == 'dict':
thisDepth = 1 + getDepthTree(nextDict[key])
else:
thisDepth = 1
if thisDepth > depthTree:
depthTree = thisDepth
return depthTree
def retrieveTrees():
listOfTrees = [{'no surfacing': {0: 'no', 1: {'flippers': {0: 'no', 1: 'yes'}}}}]
return listOfTrees[0]
decisionNode = dict(boxstyle="sawtooth", fc='0.8')
leafNode = dict(boxstyle="round4", fc='0.8')
arrow_args = dict(arrowstyle="<-")
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
def plotNode(nodeTxt, centrePt, parentPt, nodeType):
creatPlot.ax1.annotate(nodeTxt, xy=parentPt, xycoords="axes fraction", xytext=centrePt, textcoords='axes fraction',
va='center', ha='center', bbox=nodeType, arrowprops=arrow_args)
def plotMidText(cntrPt, parentPt, txtString):
xMid = (parentPt[0] - cntrPt[0]) / 2.0 + cntrPt[0]
yMid = (parentPt[1] - cntrPt[1]) / 2.0 + cntrPt[1]
creatPlot.ax1.text(xMid, yMid, txtString)
def plotTree(myTree, parentPt, nodeTxt):
numLeafs = getNumLeaves(myTree)
depth = getDepthTree(myTree)
firstStr = list(myTree.keys())[0]
cntrPt = (plotTree.xOff + (1.0 + float(numLeafs)) / 2.0 / plotTree.totalW, \
plotTree.yOff)
plotMidText(cntrPt, parentPt, nodeTxt)
plotNode(firstStr, cntrPt, parentPt, decisionNode)
secondDict = myTree[firstStr]
plotTree.yOff = plotTree.yOff - 1.0 / plotTree.totalD
for key in secondDict.keys():
if type(secondDict[key]).__name__ == 'dict':
plotTree(secondDict[key], cntrPt, str(key))
else:
plotTree.xOff = plotTree.xOff + 1.0 / plotTree.totalW
plotNode(secondDict[key], (plotTree.xOff, plotTree.yOff), \
cntrPt, leafNode)
plotMidText((plotTree.xOff, plotTree.yOff), cntrPt, str(key))
plotTree.yOff = plotTree.yOff + 1.0 / plotTree.totalD
def creatPlot(inTree):
fig = plt.figure(1, facecolor='white')
fig.clf()
axprops = dict(xticks=[], yticks=[])
creatPlot.ax1 = plt.subplot(111, frameon=False, **axprops)
plotTree.totalW = float(getNumLeaves(inTree))
plotTree.totalD = float(getDepthTree(inTree))
plotTree.xOff = -0.5 / plotTree.totalW
plotTree.yOff = 1.0
plotTree(inTree, (0.5, 1.0), '')
plt.show()
if __name__ == "__main__":
dtree = DecisionTree()
data, features = dtree.loadData()
myTree = dtree.createTree(data, features)
print(myTree)
depthTree = getDepthTree(myTree)
leafNum = getNumLeaves(myTree)
print("tree depth = %d, leaf num = %d" % (depthTree, leafNum))
creatPlot(myTree)
label = dtree.predict(myTree, features, [1, 1, 1, 0])
print("新数据[1,1,1,0]对应的是否要进行活动为:{}".format(label))
结果
{'湿度': {0: {'温度': {0: {'天气': {0: {'风速': {0: 'yes', 1: 'no'}}, 1: 'yes', 2: 'yes'}}, 1: 'yes', 2: 'no'}}, 1: {'天气': {0: 'no', 1: 'yes', 2: {'温度': {1: 'no', 2: {'风速': {0: 'yes', 1: 'no'}}}}}}}}
tree depth = 4, leaf num = 11
新数据[1,1,1,0]对应的是否要进行活动为:yes
朴素贝叶斯实现对异常账户检测
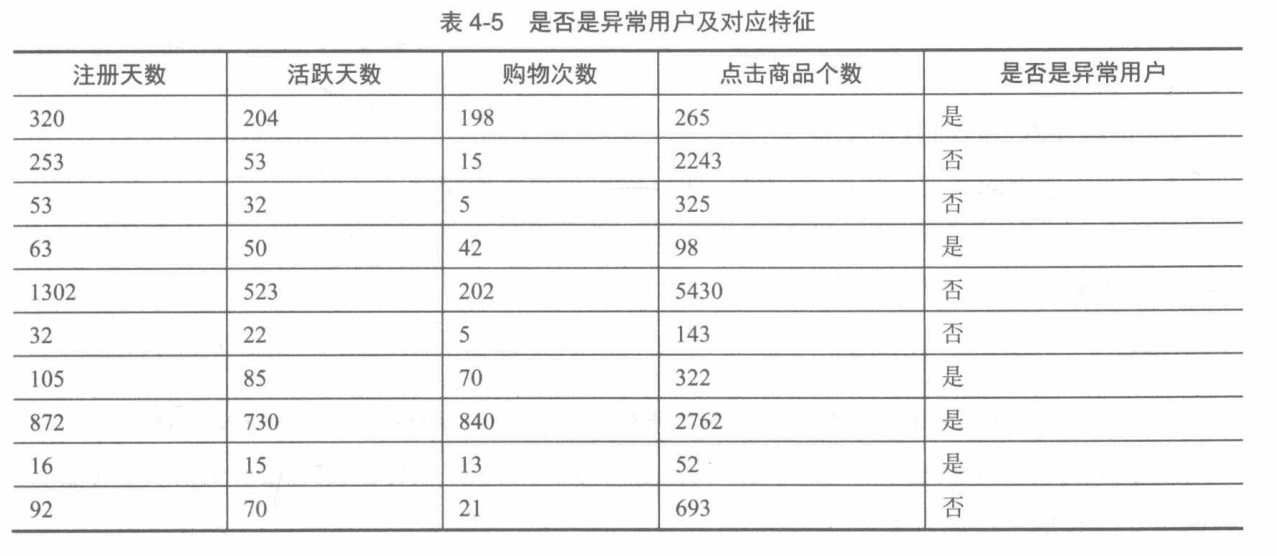
# -*-coding:utf-8-*-
"""
Author: Thinkgamer
Desc:
代码4-7 朴素贝叶斯实现对异常账户检测
"""
import numpy as np
class NaiveBayesian:
def __init__(self, alpha):
self.classP = dict()
self.classP_feature = dict()
self.alpha = alpha # 平滑值
# 加载数据集
def createData(self):
data = np.array(
[
[320, 204, 198, 265],
[253, 53, 15, 2243],
[53, 32, 5, 325],
[63, 50, 42, 98],
[1302, 523, 202, 5430],
[32, 22, 5, 143],
[105, 85, 70, 322],
[872, 730, 840, 2762],
[16, 15, 13, 52],
[92, 70, 21, 693],
]
)
labels = np.array([1, 0, 0, 1, 0, 0, 1, 1, 1, 0])
return data, labels
# 计算高斯分布函数值
def gaussian(self, mu, sigma, x):
return 1.0 / (sigma * np.sqrt(2 * np.pi)) * np.exp(-(x - mu) ** 2 / (2 * sigma ** 2))
# 计算某个特征列对应的均值和标准差
def calMuAndSigma(self, feature):
mu = np.mean(feature)
sigma = np.std(feature)
return (mu, sigma)
# 训练朴素贝叶斯算法模型
def train(self, data, labels):
numData = len(labels)
numFeaturs = len(data[0])
# 是异常用户的概率
self.classP[1] = (
(sum(labels) + self.alpha) * 1.0 / (numData + self.alpha * len(set(labels)))
)
# 不是异常用户的概率
self.classP[0] = 1 - self.classP[1]
# 用来存放每个label下每个特征标签下对应的高斯分布中的均值和方差
# { label1:{ feature1:{ mean:0.2, var:0.8 }, feature2:{} }, label2:{...} }
self.classP_feature = dict()
# 遍历每个特征标签
for c in set(labels):
self.classP_feature[c] = {}
for i in range(numFeaturs):
feature = data[np.equal(labels, c)][:, i]
self.classP_feature[c][i] = self.calMuAndSigma(feature)
# 预测新用户是否是异常用户
def predict(self, x):
label = -1 # 初始化类别
maxP = 0
# 遍历所有的label值
for key in self.classP.keys():
label_p = self.classP[key]
currentP = 1.0
feature_p = self.classP_feature[key]
j = 0
for fp in feature_p.keys():
currentP *= self.gaussian(feature_p[fp][0], feature_p[fp][1], x[j])
j += 1
# 如果计算出来的概率大于初始的最大概率,则进行最大概率赋值 和对应的类别记录
if currentP * label_p > maxP:
maxP = currentP * label_p
label = key
return label
if __name__ == "__main__":
nb = NaiveBayesian(1.0)
data, labels = nb.createData()
nb.train(data, labels)
label = nb.predict(np.array([134, 84, 235, 349]))
print("未知类型用户对应的行为数据为:[134,84,235,349],该用户的可能类型为:{}".format(label))
结果
未知类型用户对应的行为数据为:[134,84,235,349],该用户的可能类型为:1



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











