






1 第一种情况 导包导不进去,手动导包
1.1 情况介绍:
导包导不进去,pom文件中 依赖直接是红色
有的时候明明本地仓库下载了,可还是项目中出现令人厌倦的下红线
1.2 案发地图片
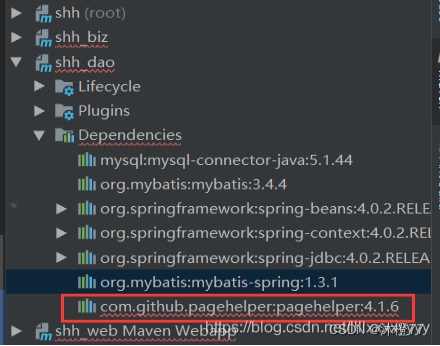
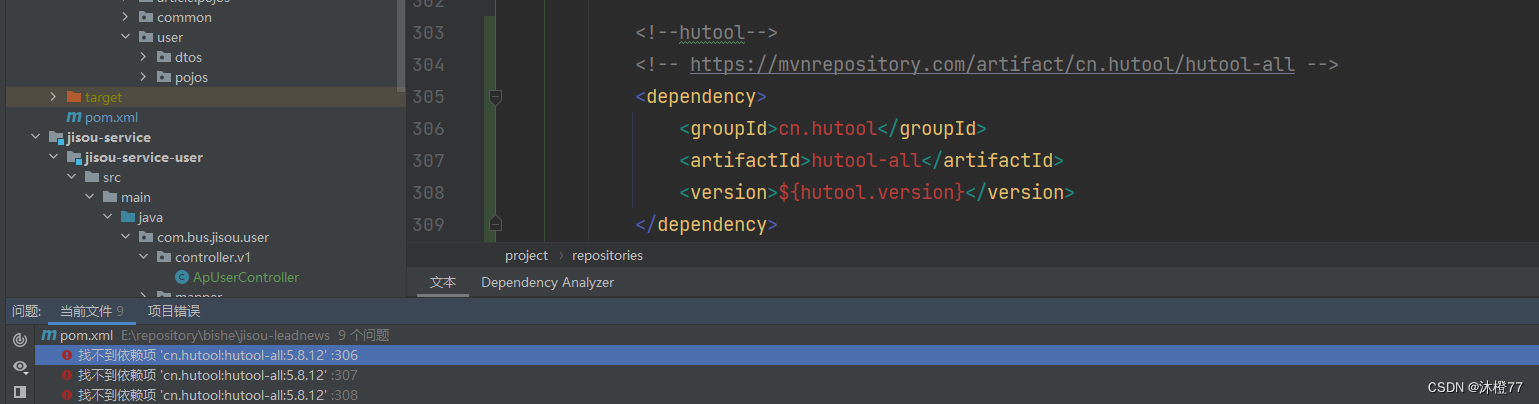
1.3 原因分析
上边com.github.pagehelper:pagehelper:4.1.6出现问题,查看本地仓库发现有,删除本地仓库再次reimport maven发现依旧是上边所述情况
据我猜测:可能是maven设置的此远程中央仓库没有
所以我们需要到maven的官方中央仓库手动下载了,再手动导入
1.4 解决办法
1.打开mvn仓库
我们先看我们需要下载哪个jar包,比如上边 cn.hutool.hutool-all ,那么我们打开mvn仓库,然后搜索cn.hutool.hutool-all
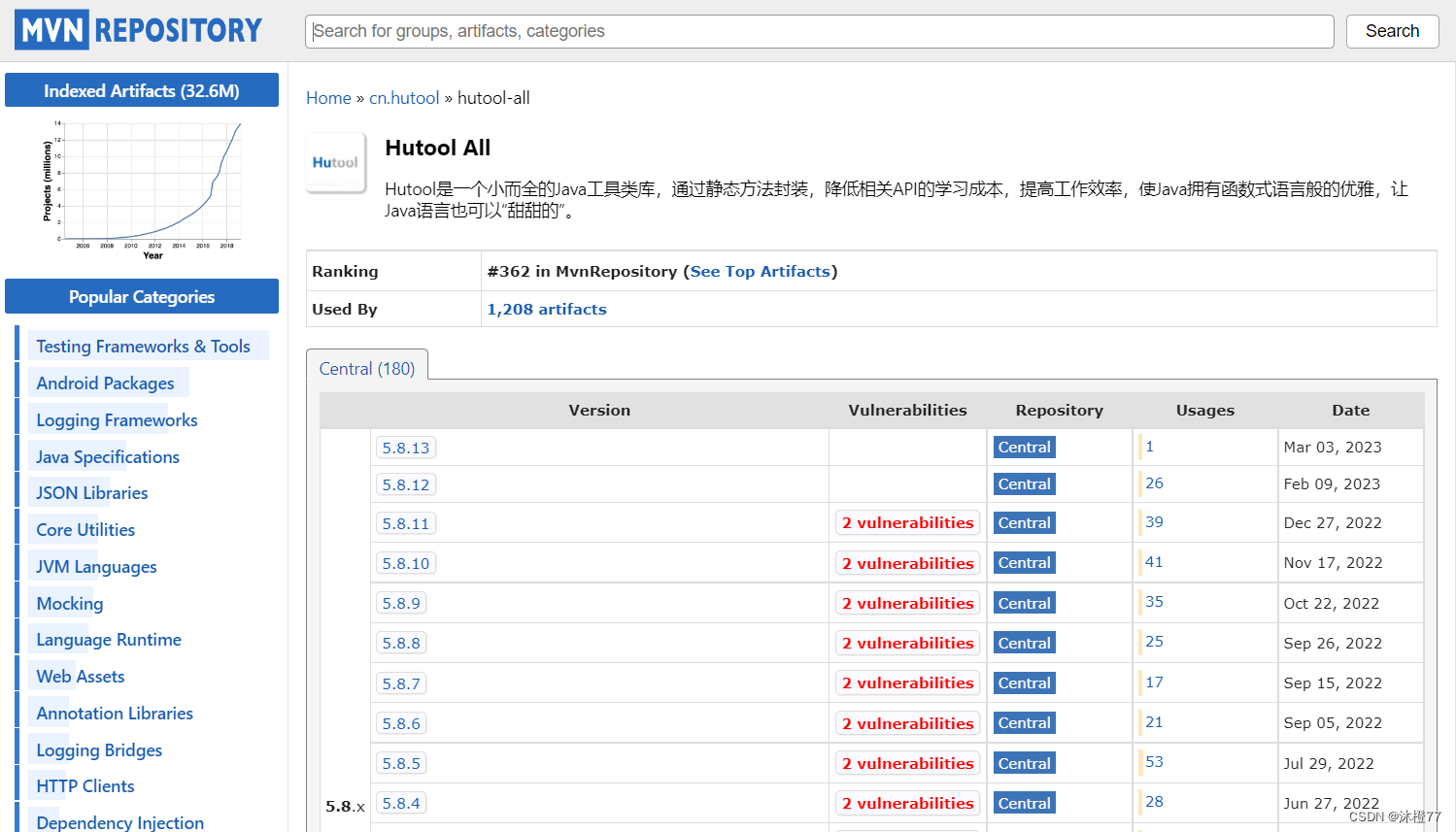
2.选择版本
进去之后我们会发现有很多版本,选择自己需要的版本,点击下载就好了,这里我们下载jar包模式
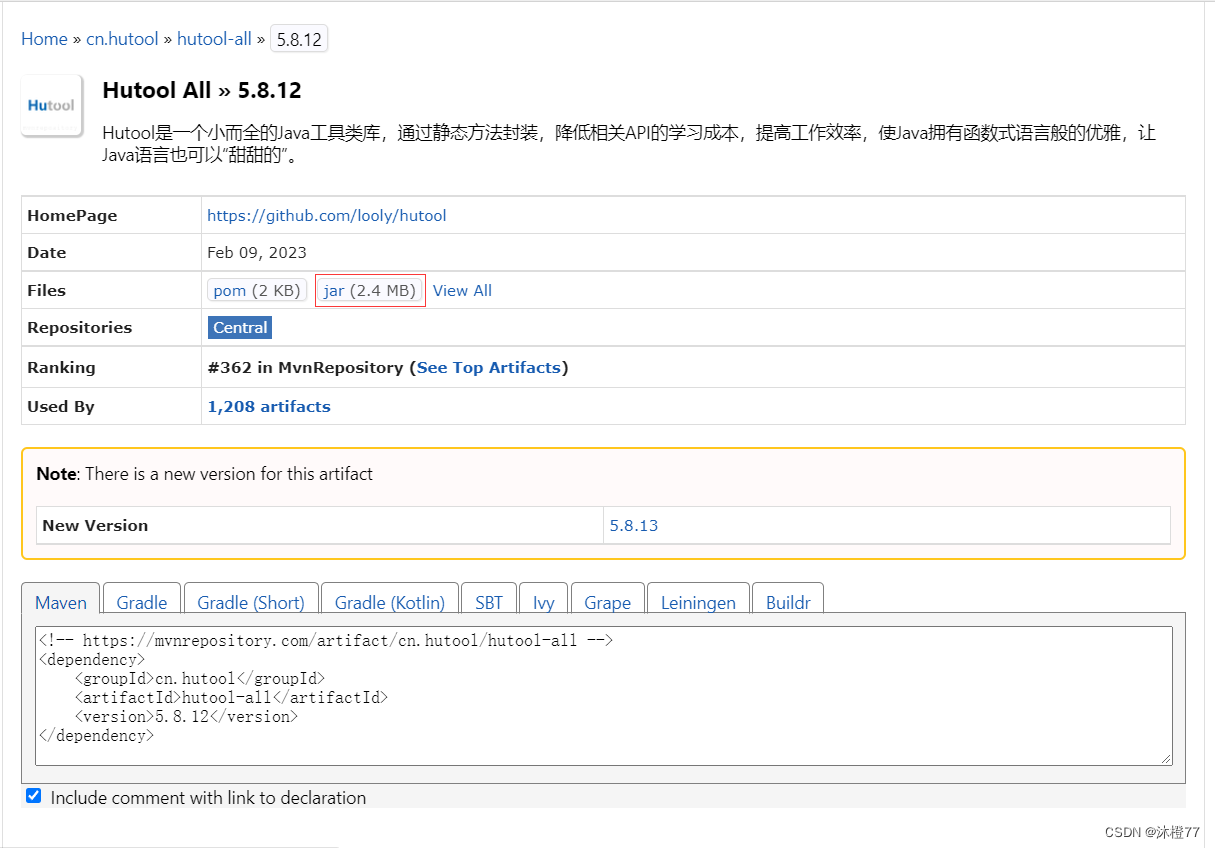
3.导包命令
下载之后,cmd(win+R 输入cmd)格式进入该jar包目录下
运行mvn install:install-file -Dfile=jar包的路径(使用绝对路径/相对路径) -DgroupId=gruopId中的内容 -DartifactId=actifactId的内容 -Dversion=version的内容 -Dpackaging=jar
mvn install:install-file -Dfile=hutool-all-5.8.12.jar -DgroupId=cn.hutool -DartifactId=hutool-all -Dversion=5.8.12 -Dpackaging=jar
4.查看
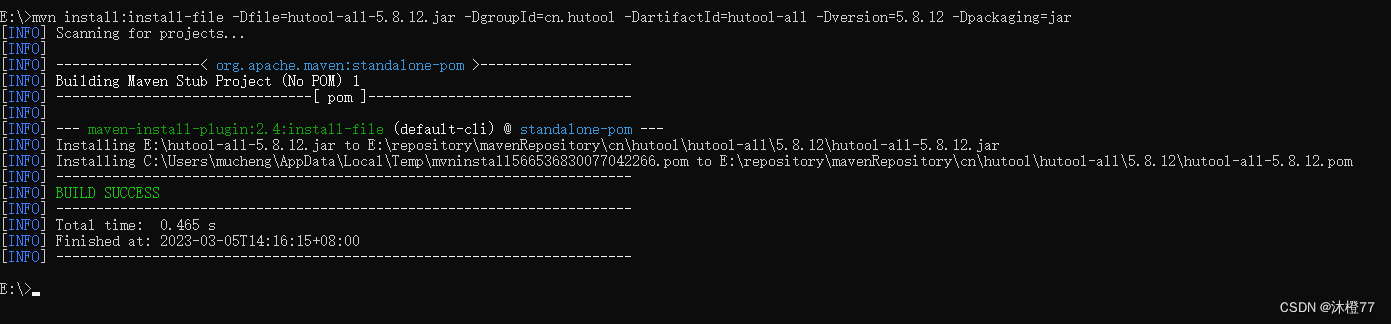
至此,我们已经把jar包添加到maven本地仓库了
下面我们将maven本地仓库引入到项目中,依旧可以通过pom.xml中引入该依赖,我们发现项目不报红了。
2 第二种情况 代码编译没错但运行报错: “程序包xxx不存在“的问题
1.1 情况介绍:
idea非得报错,我本地仓库中有此下载的包
甚至idea中可以在外部库中找到,maven编译和install都没报错,可运行此相关方法报错了
1.2 案发地图片
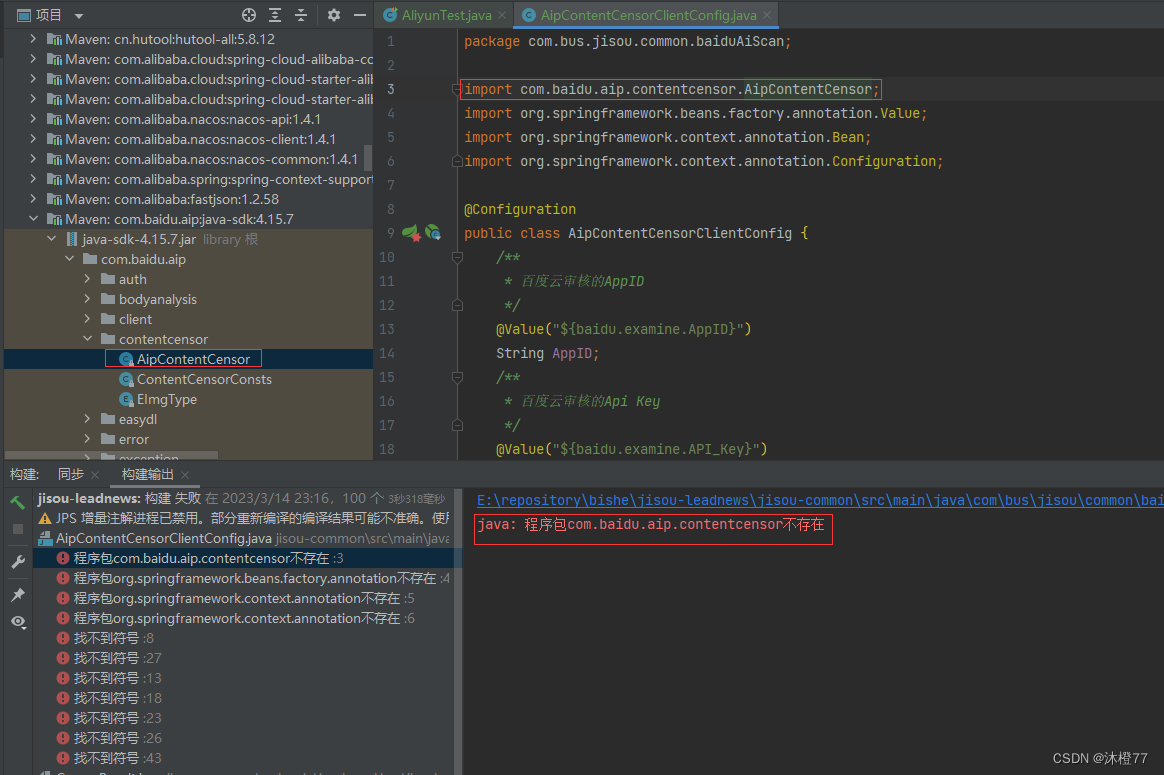
1.3 原因分析
1.首先我们得知道我们是在哪里出现的问题,是在IDE编译的时候,还是在maven编译的时候。因为idea编译跟maven编译不是一回事。
2.idea中有个设置是 Delegate ide build/run actions to maven,意思就是将ide构建/运行操作委托给maven。
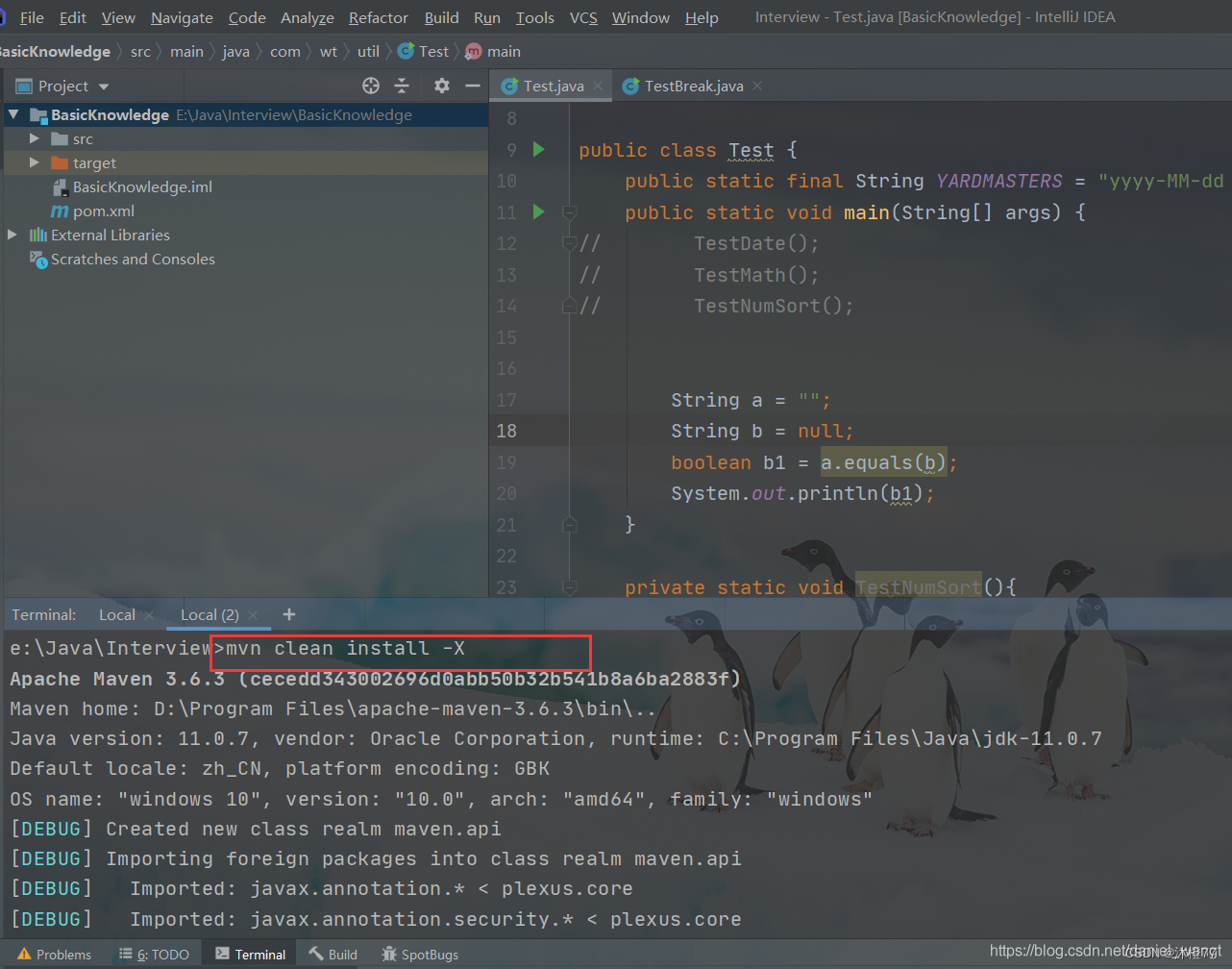
3.所以当你用命令行 mvn clean install -X的时候报错的时候,那是maven编译报错。这个时候就得从maven依赖项着手处理了。
4.当你用命令行mvn clean install -X构建正常的情况下,idea运行方法或者Build module的时候报错,那就说明是IDE编译报错。
1.4 解决办法
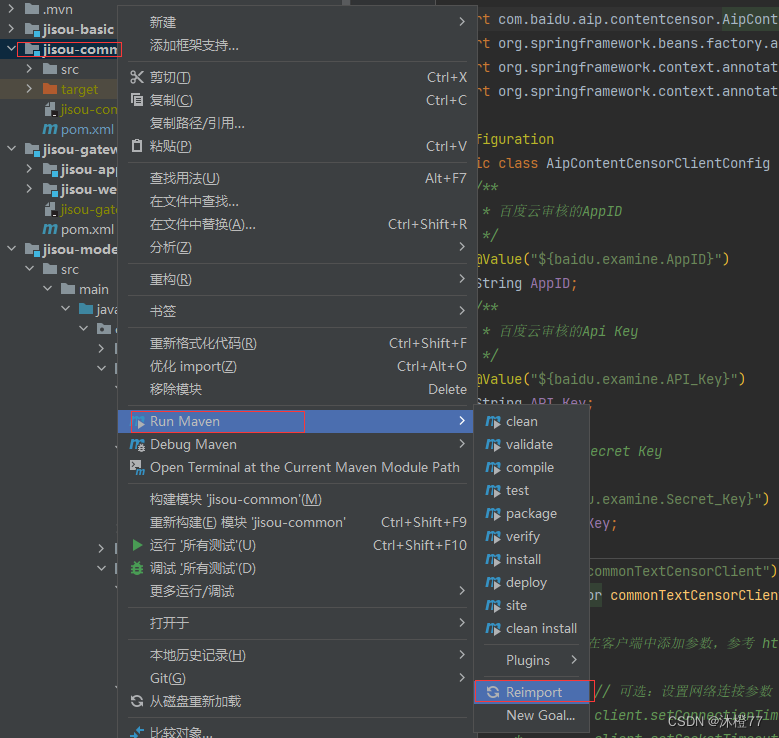
1.重新导入jar包
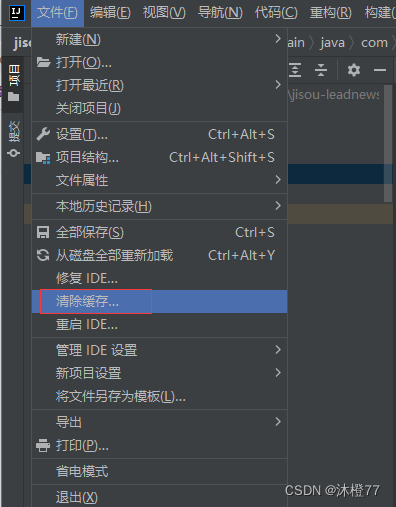
2.清除idea缓存
3.删除iml文件,然后在当前工程目录下执行mvn idea:module重新生成iml文件
4.重新编译构建项目:mvn clean install -X -X是为了打印构建的日志
5.将ide构建或者运行操作委托给maven
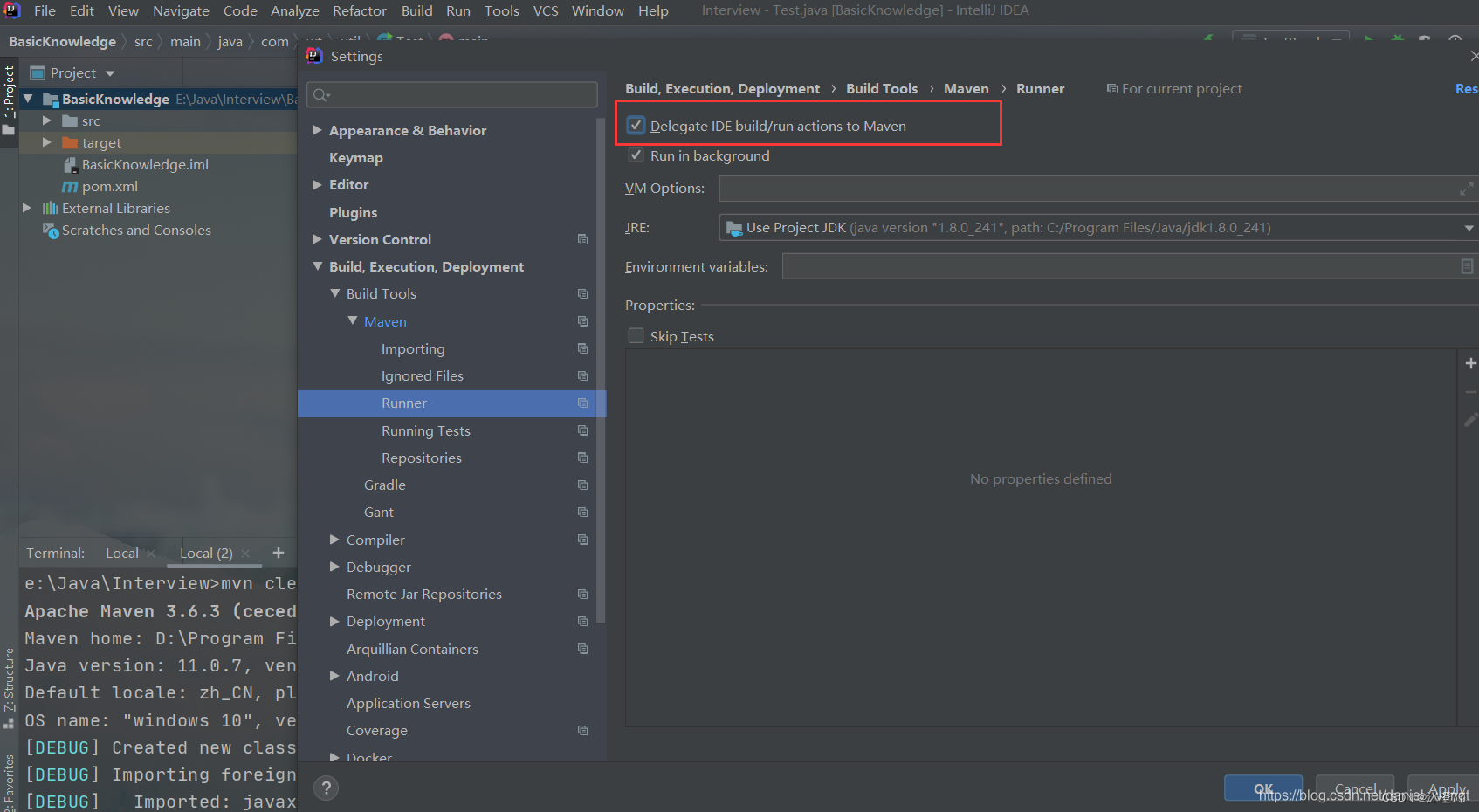
意思是将IDE构建/运行操作委托给Maven,确实能运行了,但是每次run或debug之前都要build。
还有别的解决办法:在idea的终端 mvn idea:idea。
两种办法,都能解决,但我不能每次改了代码,都运行一遍吧,这个缓存的问题真的头疼!!!
因为这破问题,耽误了我半天时间,有空要了解一下。
别的解决办法:在idea的终端 mvn idea:idea。
两种办法,都能解决,但我不能每次改了代码,都运行一遍吧,这个缓存的问题真的头疼!!!
因为这破问题,耽误了我半天时间,有空要了解一下。



















 1948
1948

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









