







 针对多阶段制造过程中的小样本质量预测难题,提出一种对比解码器生成器(CDG),利用对比学习生成阶段和任务的先验知识,并设计特定实例解码器生成器实现质量预测。
针对多阶段制造过程中的小样本质量预测难题,提出一种对比解码器生成器(CDG),利用对比学习生成阶段和任务的先验知识,并设计特定实例解码器生成器实现质量预测。
用于产品质量预测中小样本学习的对比解码器生成器
摘要
质量预测致力于预测与质量相关的关键变量,以获得过程控制的实时反馈信息。为了实现在复杂和不确定的制造过程中处理的产品的鲁棒和可转移的质量预测,已经开发了深度学习方法。然而,深度学习方法的训练过程需要大量的标注数据来避免过拟合,而质量相关变量的标记过程往往耗时耗力。因此,多阶段制造过程中的小样本质量预测被形式化,以解决缺少注释数据的问题,并在无需额外训练过程的情况下处理以前未发现的任务。此外,提出了一种新的对比解码器生成器(CDG)来实现小样本质量预测,该生成器由机器特征编码器、对比阶段和任务特征生成器以及特定于实例的解码器生成器组成。 在从实际生产线收集的公共质量预测数据集上进行实验。CDG在该数据集上实现了用于小样本质量预测设置的最新结果,这证明了CDG的有效性。此外,还通过详细的实验来评估CDG中不同模块的作用。
I 简介
为了实现生产线的智能化,提高产品质量,在生产过程中经常采用过程控制。基本上,过程控制依赖于过程运行数据的精确测量,尤其是与质量相关的关键变量[1]。然而,由于可行性、成本和时滞限制,大多数质量相关变量难以在线测量[2]。为了获得用于过程控制的实时反馈信息,许多研究人员已经研究了质量预测方法。准确的质量预测方法可以降低测量成本,提高产品质量。然而,由于实际制造过程的复杂性和不确定性,仍然难以实现准确的质量预测。
随着物联网(IoT)的发展,在制造过程中配置了诸如智能设备和智能传感器的IoT设备。基于这些物联网设备收集的数据,数据驱动的质量预测方法得到了越来越多的研究者的关注。通过人工智能(AI),用于质量预测的数据驱动方法深入挖掘从生产机器和智能子系统收集的信息,这有可能成为AI增强的自动化系统的子组件。
目前,数据驱动的质量预测方法主要分为两类:传统的机器学习方法[3]和[4]深度学习方法。 传统的机器学习方法首先利用特征工程来处理数据,然后部署传统的机器学习模型来预测质量相关变量。在此过程中,方法的性能由特征工程控制,这需要相当大的人工工作量,并降低了方法的鲁棒性和可移植性[5]。针对这一问题,深度学习方法被开发出来,实现端到端的质量预测,成为近年来的研究热点。
然而,深度学习方法的训练过程需要大量的数据来辅助表征学习[5]。质量相关变量的标注过程耗时耗力,往往难以获得大量标注数据。为解决上述问题,现有的研究主要集中在三条主线上。1)半监督(Semi-supervised)学习方法利用标记和未标记数据来解决标记样本不足所引起的问题。2)迁移学习(Transfer learning)方法将知识从源任务转移到目标任务,以提高目标任务绩效。3) 多任务学习(Multi-task learning)方法利用多个任务,例如刀具磨损状况预测和表面质量预测,从任务中获得更容易注释的补充信息。
尽管如此,仍有一种策略可以解决质量预测领域中尚未研究的标注数据不足的问题,即小样本学习。小样本学习方法旨在通过使用先验知识快速推广到仅包含少量具有监督信息的样本的新任务。 与其他三种方法相比,小样本学习方法有能力处理之前看不见的任务,这些任务没有被训练实例覆盖[10]。此外,这些方法已被证明在许多领域有效。
在多阶段制造过程中,产品通过不同的阶段和机器加工,从而输出不同类型的质量相关变量。 这反映了不同阶段和质量相关变量的独特性。此外,制造企业中不同阶段加工的产品和产生不同种类质量相关变量的机器是共用的,这说明了不同阶段和质量相关变量之间的相关性[11]。因此,本文引入小样本学习方法挖掘不同阶段和质量相关变量之间的相关性,进一步推断不同阶段和质量相关变量的唯一性。这样,基于由传感器从不同机器收集的特征,可以在没有注释数据的情况下获得关于阶段和质量相关变量的先验知识。然后,先验知识可以帮助模型快速调整以适应要预测的新的质量相关变量。
然而,现有的小样本学习方法大多集中于分类问题,应用前景有限。为了解决这一问题,Loo等人[12]提出了一种基于基函数的小样本学习模型,该模型针对的是小样本回归任务。此外,他们使用稀疏基函数进一步改进模型[13]。任务标签需要监督信号发生器模块的方法来指导前一代的任务知识,如高斯分布的平均值和标准偏差值。然而,这些信号在实际应用中很少获得。另外,他们的方法中的权重生成器模块为所有实例生成相同的权重参数,并且不考虑偏差参数,这降低了方法的性能。
在这项工作中,在多阶段制造过程中引入了小样本质量预测,以解决缺乏注释数据的问题,并在没有额外训练过程的情况下处理以前未知的任务。此外,提出了一种新的对比解码器生成器(CDG)来处理多阶段制造过程中的小样本质量预测。CDG集中于在解码器中生成参数(权重参数和偏置参数),而不是样本的概率。它属于文献[9]中定义的生成模型类型,其中推理网络参数的生成包含在生成模型中。借助对比学习[14],[15],提出了CDG中的对比阶段和任务特征生成器,以在没有监督信号的情况下生成阶段和任务的先验知识。这里使用对比学习,因为它可以使具有相同阶段或任务的实例的表示相似性更高,而具有不同阶段或任务实例的表示类似性更低,其中实例的表示可以被视为任务和阶段的先验知识。此外,设计了一个特定于实例的解码器生成器,以结合不同支持实例的重要性,并将权重生成扩展到层生成。此外,该方法在公共工业数据集上获得了最优的小样本质量预测结果,证明了该方法的有效性。我们的代码将在 https://github.com/Donghao-Zhang/quality_prediction
现将我们工作的贡献概述如下:
- 在我们的工作中引入了多阶段制造过程中的小样本质量预测并将其形式化,该方法能够解决标注数据的缺乏问题,并且在没有额外训练过程的情况下处理先前未见过的任务。 据我们所知,这是首次尝试将小样本学习引入质量预测任务。
- 提出了一种新的CDG来解决多阶段制造过程中的小样本质量预测,其重点是在解码器中生成参数。 具体地,CDG中的对比阶段和任务特征生成器被设计为以自我监督的方式生成包含关于任务和阶段的先验知识的两个向量。此外,设计了一个实例特定解码器生成器,根据查询实例和支持实例之间的相关性生成一层参数,包括权重参数和偏差参数。
- 该方法的有效性在从真实的多级连续流程制造过程中收集的公共质量预测数据集上得到了验证。此外,还进行了详细的实验,实验结果证明了所提出方法中每个模块的重要性。
本文件的其余部分安排如下。在第二节中,形式化了多阶段制造过程中的几次质量预测任务。第三节详细介绍了拟议方法。在第四节中,分析了在实际工业案例中进行的实验。结论和未来扩展见第五节。
II 多阶段制造过程的小样本质量预测
为了能够在多阶段制造过程中进行质量预测,我们遵循[16]中的定义。具体来说,此任务的输入是来自不同机器的特征,输出是来自不同阶段的测量或标签。形式上,来自第m台机器的特征被表示为 x m ∈ R d f m x_m \in \mathbb R^{d_{fm}} xm∈Rdfm,其中 d f m d_{fm} dfm 是该机器的输入特征的维度。之后,来自所有机器的特征可以表示为 x = [ x 1 , . . . , x ∣ M ∣ ] \mathbf x =[x_1,...,x_{|\mathcal M|}] x=[x1,...,x∣M∣],其中 x ∈ R d x \mathbf x ∈ R^{d_x} x∈Rdx, d x d_x dx 是所有机器的特征维数,并且 ∣ M ∣ |\mathcal M| ∣M∣ 是计算机的总数。此外,第 j j j 阶段包含 d s j d_{s_j} dsj 个测量(或任务),这些测量是需要预测的变量,可以形式化为 y s j ∈ R d s j y_{s_j} \in \mathbb R^{d_{s_j}} ysj∈Rdsj。然后,所有阶段的测量值可以表示为 y = [ y 1 , … , y ∣ S ∣ ] y=[y_1,…,y_{|\mathcal S|}] y=[y1,…,y∣S∣],其中 ∣ S ∣ |\mathcal S| ∣S∣ 是阶段的总数。此外,还根据[16]构造了机器依赖图 G \mathcal G G,其第 i i i 个实例的邻接矩阵为 A i ∈ R ∣ M i ∣ × ∣ M i ∣ A_i \in \mathbb R^{|\mathcal M_i|×|\mathcal M_i|} Ai∈R∣Mi∣×∣Mi∣。最终目标基于来自所有机器 x \mathbf x x 和机器依赖图 G \mathcal G G 的特征预测多个阶段 y \mathbf y y 中的所有任务(测量或标签)。由于小样本质量预测是本工作的重点,因此在[16]中可以找到多阶段制造过程中质量预测的更详细定义。
根据小样本学习的定义[17],我们将多阶段制造过程(FSQP)中的小样本质量预测定义如下。FSQP任务中给出了一个非常小的K支持集(例如100、50、20、10,甚至0),标记为实例 S ( s , t ) = { ( x 1 , G 1 , y 1 ( s , t ) ) , . . . , ( x K , G K , y K ( s , t ) ) } S^{(s,t)}=\{(\mathbf x_1,\mathcal G_1,y_1^{(s,t)}),...,(\mathbf x_K,\mathcal G_K,y_K^{(s,t)})\} S(s,t)={(x1,G1,y1(s,t)),...,(xK,GK,yK(s,t))} ,其中 y i ( s , t ) y_i^{(s,t)} yi(s,t) 表示第 s 阶段和第 t 任务(位于yss中的第t项)的注释标签。此外,对应于第s阶段和第t任务的具有未标记实例的查询集合 Q ( s , t ) = { ( x 1 , G 1 ) , . . . , ( x N q , G N q ) } Q^{(s,t)}=\{(\mathbf x_1,\mathcal G_1),...,(\mathbf x_{N_q},\mathcal G_{N_q})\} Q(s,t)={(x1,G1),...,(xNq,GNq)} 用作预测模型的输入,其中 N q N_q Nq是查询实例的数目。之后,FSQP任务的目标是基于支持集 S ( s , t ) S^{(s, t)} S(s,t) 中的非常少的K个标记实例来预测查询集 Y ~ ( s , t ) = { y ~ 1 ( s , t ) , . . . , y ~ N q ( s , t ) } \tilde{Y}^{(s,t)}=\{\tilde{y}_1^{(s,t)},...,\tilde{y}_{N_q}^{(s,t)}\} Y~(s,t)={y~1(s,t),...,y~Nq(s,t)} 中的实例的结果。
通常,质量预测数据集通常被划分为多个集合:训练集、验证集和测试集,它们分别用于模型的训练、验证和测试。在FSQP中,包含在不同集合中的任务(不同阶段的测量)是互斥的。此外,测试集中具有相同任务的注释实例很少。考虑到来自不同集合的实例属于不同的任务,并且测试集合中具有相同任务的实例非常少,因此很难构建高质量的深度学习方法来实现测试集合中的质量预测。因此,在大多数情况下,允许训练集包含基于先前测量收集的足够实例和任务[17],这也符合制造过程中数据集的特征。在多阶段生产过程中,不同质量相关变量的测量难度不同[19]。例如,在第IV-A节的实验中使用的公共数据集中,在不同任务的实例中,最大实例数是最小实例数的21.4倍。因此,我们假设在训练集中有足够的样本和任务。然后,在小样本学习方法的帮助下,这些易于测量的任务可以被用来生成先验知识,并帮助实现对测试集中的实例从看不见的任务的质量预测。
形式上,在训练集、验证集和测试集中分别存在来自 S \mathcal S S 中不同阶段的 N t r a i n N_{train} Ntrain、 N v a l i d N_{valid} Nvalid和 N N N 个任务,其中 S \mathcal S S 表示阶段集合。此外,还对训练集和验证集中的实例进行了注释。对于训练集中的实例,在每一步训练中,我们往往随机抽取训练集中的N个任务和K个实例作为支持集,再从抽取的任务中抽取另一批实例作为查询集。这形成了 N-way K-shot 质量预测任务的输入数据集,将在第III-E1节中详细描述。对于验证集中的注释实例,K个实例被采样作为验证集的支持集,其余的实例作为查询集。此外,对于测试集中的实例,测试集中有K个注释实例作为支持集,其中K非常小。FSQP的目标是基于测试集中的K个标注实例以及从训练集和验证集中提取的先验知识,实现测试集中未标注实例的质量预测。
III 对比解码器发生器
A. 总体框架
CDG主要由三个模块组成:机器特征编码器(MFE)、对比级和任务特征生成器(CFG)以及实例特定解码器生成器(IDG)。首先,引入MFE来编码来自各种机器的特征,考虑它们在制造过程中的依赖关系,这将在第III-B节中详细描述。第二,CFG采用对比学习方法来生成关于包含在来自MFE的输出隐藏表示中的阶段和任务的先验知识,如我们将在第III-C节中解释的。最后,在第III-D节中给出的IDG被设计成在解码器中生成参数并实现质量预测。我们方法的总体框架如图1所示。
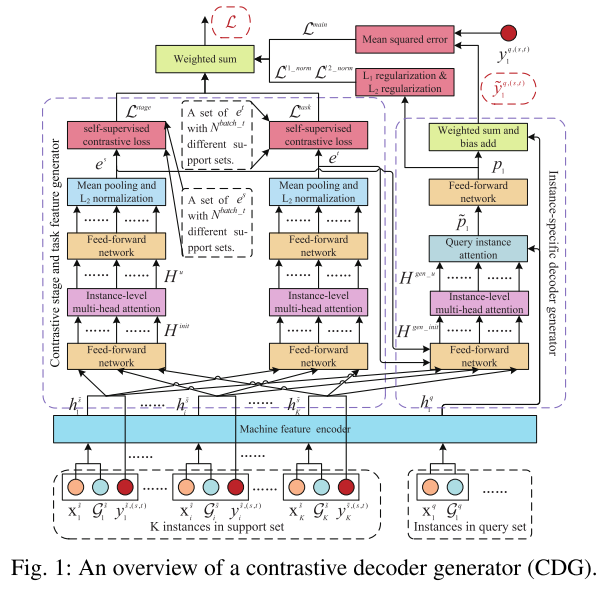
II B. 机器特征编码器(MFE)
MFE考虑到制造过程中不同机器的依赖关系,对来自不同机器的特征进行编码。为此,来自不同机器的特征需要被投影到相同的向量空间,机器依赖图必须被编码,并且来自不同机器的表示需要被合并。然后,可以获得由隐藏的质量相关特征组成的每个实例的向量。需要注意的是,本文的主要贡献在于基于阶段和任务特征生成单层前馈网络(FFN)的参数,实现小样本质量预测,MFE不是本文的重点。
形式上,MFE可以表示为如下的计算单元。对于某个实例,
h
=
M
F
E
(
x
,
G
)
h = MFE(\mathbf x, \mathcal G)
h=MFE(x,G),其中
x
\mathbf x
x 是按机器分组的输入特性,
G
\mathcal G
G 是当前实例的机器依赖图
,
h
∈
R
d
h
h \in \mathbb R^{d_h}
h∈Rdh是当前实例的输出隐藏表示。此外,
M
F
E
(
⋅
)
MFE(·)
MFE(⋅)代表了[16]中以下模块的计算过程:机器嵌入池、路径增强双向图注意网络和目标特定注意解码器。
MFE服务于支持集和查询集中的每个实例,可以形式化如下。
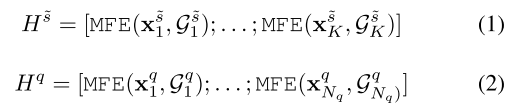
其中
H
S
~
∈
R
K
×
d
h
H^{\tilde S} \in \mathbb R^{K \times d_h}
HS~∈RK×dh 和
H
q
~
∈
R
N
q
×
d
h
H^{\tilde q} \in \mathbb R^{N_q \times d_h}
Hq~∈RNq×dh 分别是支持集和查询集中所有实例的输出隐藏表示。
[
⋅
;
.
.
.
]
[·; ...]
[⋅;...] 表示向量之间的连接。
x
i
S
~
∈
R
d
x
\mathbf x^{\tilde S}_i \in \mathbb R^{d_x}
xiS~∈Rdx 和
x
i
q
~
∈
R
d
x
\mathbf x^{\tilde q}_i \in \mathbb R^{d_x}
xiq~∈Rdx 分别是支持集和查询集中某个实例的所有计算机的功能。此外,
G
i
S
~
\mathcal G^{\tilde S}_i
GiS~ 和
G
i
q
~
\mathcal G^{\tilde q}_i
Giq~ 分别是支持集和查询集中某个实例的机器依赖图。
C. 对比阶段和任务特征生成器(Contrastive Stage and Task Feature Generator)
CFG被设计为基于支持集中所有实例的隐藏表示来生成阶段和任务特征。这里的阶段和任务特征包含相应阶段和任务的先验知识,其可以用作质量预测的补充知识。CFG的输入是隐藏表示 H S ~ H^{\tilde S} HS~ 和支持集中所有实例的注释标记 Y q ~ , ( s , t ) = [ y 1 s ~ , ( s , t ) ; . . . ; y K s ~ , ( s , t ) ] Y^{\tilde q, (s,t)}= [y_1^{\tilde s,(s,t)};...;y_K^{\tilde s,(s,t)}] Yq~,(s,t)=[y1s~,(s,t);...;yKs~,(s,t)],输出是阶段表示 e s ∈ R d s e^s \in \mathbb R^{d_s} es∈Rds 和 任务表示 e t ∈ R d t e^t \in \mathbb R^{d_t} et∈Rdt。注意, Y s ~ , ( s , t ) Y^{\tilde s, (s,t)} Ys~,(s,t)上标中的 s s s 表示支持实例的标签, s s s 表示当前任务的第 s 个阶段, e s e^s es上标中的 s s s 表示第s个阶段。
为了计算阶段表示
e
s
e^s
es,隐藏表示
H
s
~
H^{\tilde s}
Hs~ 和注释标记
Y
q
~
,
(
s
,
t
)
Y^{\tilde q, (s,t)}
Yq~,(s,t) 被连接起来,并由单层FFN处理,这形成了支持实例的初始表示
H
i
n
i
t
∈
R
K
×
d
i
n
i
t
H^{init} \in \mathbb R^{K \times d_{init}}
Hinit∈RK×dinit
H
i
n
i
t
=
F
F
N
(
[
H
s
~
;
Y
s
~
,
(
s
,
t
)
]
)
(3)
H^{init} = FFN([H^{\tilde s};Y^{\tilde s,(s,t)}]) \tag3
Hinit=FFN([Hs~;Ys~,(s,t)])(3)
FFN(·)代表一个单层FFN,它是用来将输入向量映射到一个特定的维度,提高模型的拟合能力。它可以形式化如下。
x
o
u
t
=
F
F
N
(
x
i
n
)
=
f
(
W
F
x
i
n
+
b
F
)
(4)
x_{out} = FFN(x_{in}) = f(W^Fx_{in} + b^F) \tag4
xout=FFN(xin)=f(WFxin+bF)(4)
在公式4中,
W
F
∈
R
d
i
n
×
d
o
u
t
W^F \in \mathbb R^{d_{in} \times d_{out}}
WF∈Rdin×dout 和
b
F
∈
R
d
o
u
t
b^F \in \mathbb R^{d_{out}}
bF∈Rdout 是单层FFN的可学习参数,其中
d
i
n
d_{in}
din 和
d
o
u
t
d_{out}
dout 分别是输入向量
x
i
n
x_{in}
xin 和输出向量
x
o
u
t
x_out
xout 的维度。此外,f(·)表示激活函数,例如线性校正函数。
随后,为了评估支持集合中各种实例的重要性,基于 Instance-level attention 利用 Multi-head attention [20]。形式上,支持实例的 Instance-level attention 可以计算如下(这里以 One-head attention 为例)。
α
i
,
j
=
e
x
p
(
(
h
i
i
n
i
t
W
q
)
(
h
j
i
n
i
t
W
k
)
/
d
i
n
i
t
)
∑
m
=
1
K
e
x
p
(
(
h
i
i
n
i
t
W
q
)
(
h
j
i
n
i
t
W
k
)
/
d
i
n
i
t
)
(5)
\alpha_{i,j} = \frac{exp((h^{init}_iW^q)(h^{init}_jW^k)/\sqrt{d_{init}})}{\sum^K_{m=1}exp((h^{init}_iW^q)(h^{init}_jW^k)/\sqrt{d_{init}})} \tag5
αi,j=∑m=1Kexp((hiinitWq)(hjinitWk)/dinit)exp((hiinitWq)(hjinitWk)/dinit)(5)
h i u = ( ∑ j = 1 K α i , j ⋅ ( h j i n i t W v ) ) W o (6) h^u_i = \left ( \sum_{j=1}^{K} \alpha_{i,j}\cdot(h^{init}_jW^v) \right ) W^o \tag6 hiu=(j=1∑Kαi,j⋅(hjinitWv))Wo(6)
其中
h
i
i
n
i
t
∈
R
d
i
n
i
t
h^{init}_i \in \mathbb R^{d_{init}}
hiinit∈Rdinit表示来自
H
i
n
i
t
H^{init}
Hinit 的支持集中某个实例的初始表示。
h
i
u
h^u_i
hiu表示第i个支持实例的更新表示。
W
q
,
W
k
,
W
v
和
W
o
W^q, W^k, W^v和W^o
Wq,Wk,Wv和Wo是可学习的参数。
α
i
,
j
\alpha_{i,j}
αi,j评估第 j 个实例对第 i 个实例的重要性。此外,关于 Multi-head attention 的更多细节可以在[20]中找到。此外,
h
i
u
h^u_i
hiu 由一层FFN处理,并且来自所有支持实例的处理后的表示的平均向量用作归一化前的阶段表示
e
~
s
\tilde e^s
e~s。
e
~
s
=
1
K
∑
K
i
=
1
F
F
N
(
h
i
u
)
(7)
\tilde e^s = \frac{1}{K} \sum_{K}^{i=1}FFN(h^u_i) \tag7
e~s=K1K∑i=1FFN(hiu)(7)
最后,使用
L
2
L_2
L2 归一化来防止
e
~
s
\tilde e^s
e~s 中的值太大,这输出最终阶段表示
e
s
∈
R
d
s
e^s \in \mathbb R ^{d_s}
es∈Rds。形式上,
e
s
=
e
~
s
∥
e
~
s
∥
2
e^s = \frac{\tilde e^s}{{\parallel \tilde e^s\parallel}_2}
es=∥e~s∥2e~s,其中
∥
⋅
∥
2
{\parallel \cdot \parallel}_2
∥⋅∥2是
L
2
L_2
L2范数。
此外,任务表示 e t ∈ R d t e^t \in \mathbb R^{d_t} et∈Rdt 的计算与阶段表征 e s e^s es 的计算相同,但使用不同的参数。
然而,上述阶段表示
e
s
e^s
es 和任务表示
e
t
e^t
et 不合并包含在阶段和任务中的先验知识。在[12]和[13]中,真实的任务标签,例如高斯分布的均值和标准偏差值,用作监督信号以获得包含在任务中的先验知识。然而,最优监督信号几乎没有注释。为了解决这个问题,一个假设:设置阶段和任务形式是独立的,这意味着相似性阶段或任务可以获得独立。随后,引入了自监督对比学习[14],并对其进行调整以实现先验知识挖掘。具体地,在训练过程中加入一个自我监督的对比损失(SCL),使得具有相同阶段或任务的实例的表征相似度较高,而具有不同阶段或任务的实例的表征相似度较低。它可以形式化如下。
L
s
t
a
g
e
=
−
∑
i
∈
A
s
∑
j
∈
N
s
(
i
)
l
o
g
e
x
p
(
e
i
s
e
j
s
/
τ
)
∑
m
∈
A
s
(
i
)
e
x
p
(
e
i
s
e
m
s
/
τ
)
(8)
\mathcal L^{stage} = -\sum_{i\in \mathcal A_s}\sum_{j\in \mathcal N_s(i)}log\frac{exp(e^s_ie^s_j/\tau)}{{\textstyle \sum_{m\in \mathcal A_s(i)}}exp(e^s_ie^s_m/\tau)} \tag8
Lstage=−i∈As∑j∈Ns(i)∑log∑m∈As(i)exp(eisems/τ)exp(eisejs/τ)(8)
L
t
a
s
k
=
−
∑
i
∈
A
t
∑
j
∈
N
t
(
i
)
l
o
g
e
x
p
(
e
i
t
e
j
t
/
τ
)
∑
m
∈
A
t
(
i
)
e
x
p
(
e
i
t
e
m
t
/
τ
)
(9)
\mathcal L^{task} = -\sum_{i\in \mathcal A_t}\sum_{j\in \mathcal N_t(i)}log\frac{exp(e^t_ie^t_j/\tau)}{{\textstyle \sum_{m\in \mathcal A_t(i)}}exp(e^t_ie^t_m/\tau)} \tag9
Ltask=−i∈At∑j∈Nt(i)∑log∑m∈At(i)exp(eitemt/τ)exp(eitejt/τ)(9)
其中
e
i
s
e^s_i
eis和
e
i
t
e^t_i
eit分别是来自批处理中的采样支持集的阶段和任务表示。
A
s
\mathcal A_s
As和
A
t
\mathcal A_t
At分别表示包含在一批训练数据中的所有阶段和任务集的支持集。另外,
A
s
(
i
)
\mathcal A_s(i)
As(i)和
A
t
(
i
)
\mathcal A_t(i)
At(i)分别表示与第 i 个支持集相比具有不同阶段和任务的支持集。
τ
∈
R
+
\tau \in \mathbb R^+
τ∈R+是一个超参数。此外,
L
s
t
a
g
e
\mathcal L^stage
Lstage和
L
t
a
s
k
\mathcal L^task
Ltask分别是阶段特征和任务特征的SCL。它们倾向于使同一阶段和任务的实例的表征相似性较高,而使不同阶段和任务的实例的表征相似性较低。
D. 特定实例解码器生成器(Instance-Specific Decoder Generator )
IDG的目标是生成解码器中包含的适当权重和偏差,以实现对特定查询实例的质量预测。这个模块的输入一定的隐藏表示查询实例输出的MFE h i q ∈ H q h^q_i \in H^q hiq∈Hq,对应于查询实例 H s ~ H^{\tilde s} Hs~ 的支持集中实例的隐藏表示,注释标签对应于支持集 Y s ~ , ( s , t ) Y^{\tilde s,(s,t)} Ys~,(s,t) 中的实例,由支持集计算的阶段表示 e s e^s es和任务表示 e t e^t et。此外,输出是解码器中生成的参数和查询实例的预测结果。
具体地说,隐藏表示
H
s
~
H^{\tilde s}
Hs~,注释标注
Y
s
~
,
(
s
,
t
)
Y^{\tilde s,(s,t)}
Ys~,(s,t),阶段表示
e
s
e^s
es和任务表示
e
t
e^t
et由一层FFN连接和处理,形成IDG的初始表示
H
g
e
n
_
i
n
i
t
∈
R
K
×
d
g
e
n
_
i
n
i
t
H^{gen\_init} \in \mathbb R^{K \times d_{gen\_init}}
Hgen_init∈RK×dgen_init。
H
g
e
n
_
i
n
i
t
=
F
F
N
(
[
H
s
~
;
Y
s
~
,
(
s
,
t
)
;
e
s
;
e
t
]
)
(10)
H^{gen\_init} = FFN([H^{\tilde s};Y^{\tilde s,(s,t)};e^s;e^t]) \tag{10}
Hgen_init=FFN([Hs~;Ys~,(s,t);es;et])(10)
其中
e
s
(
e
t
)
e^s(e^t)
es(et) 重复K次以形成
e
s
∈
R
K
×
d
s
(
e
t
∈
R
K
×
d
t
)
e^s \in \mathbb R^{K \times d_s}(e^t \in \mathbb R^{K \times d_t})
es∈RK×ds(et∈RK×dt)
然后,在 H g e n _ i n i t H^{gen\_init} Hgen_init 上部署实例级 Multi-head attention,评估各个支持实例的重要性。此过程类似于等式5和6,在此将不详细描述。经过实例级 Multi-head attention 处理后,可以得到每个支撑实例的更新表示 h i g e n _ u ∈ R d g e n _ i n i t h^{gen\_u}_i ∈ \mathbb R^{d_{gen\_init}} higen_u∈Rdgen_init。
随后,为了引入查询实例和支持实例之间的相关性,设计了实例特定解码器。具体地,利用查询实例
h
i
q
∈
H
q
h^q_i ∈ H^q
hiq∈Hq 的隐藏表示和对应于查询实例
H
s
~
H^{\tilde s}
Hs~ 的支持实例的隐藏表示来计算支持集中每个实例的重要性。此外,重要性被视为每个支持实例的权重,以在解码器中生成参数。 这个过程被称为查询实例关注(QIA),可以如下形式化。
α
i
,
j
=
e
x
p
(
(
h
i
q
W
g
e
n
,
q
)
(
h
j
s
~
W
g
e
n
,
k
)
/
d
h
)
∑
h
m
s
~
∈
H
s
~
e
x
p
(
(
h
i
q
W
g
e
n
,
q
)
(
h
m
s
~
W
g
e
n
,
k
)
/
d
h
)
(11)
\alpha_{i,j} = \frac{exp((h^{q}_iW^{gen,q})(h^{\tilde s}_jW^{gen,k})/\sqrt{d_{h}})}{\sum_{h^{\tilde s}_m \in H^{\tilde s}}exp((h^{q}_iW^{gen,q})(h^{\tilde s}_mW^{gen,k})/\sqrt{d_{h}})} \tag{11}
αi,j=∑hms~∈Hs~exp((hiqWgen,q)(hms~Wgen,k)/dh)exp((hiqWgen,q)(hjs~Wgen,k)/dh)(11)
p
~
i
=
(
∑
j
=
1
K
α
i
,
j
⋅
(
h
j
g
e
n
_
u
W
g
e
n
,
v
)
)
W
g
e
n
,
o
(12)
\tilde p_i=\left ( \sum_{j=1}^{K}\alpha_{i,j}\cdot(h^{gen\_u}_jW^{gen,v})\right )W^{gen,o} \tag{12}
p~i=(j=1∑Kαi,j⋅(hjgen_uWgen,v))Wgen,o(12)
其中 h i q h^{q}_i hiq 和 h j s ~ h^{\tilde s}_j hjs~ 分别是 H q H^q Hq 和 H s ~ H^{\tilde s} Hs~ 中查询实例和支持实例的隐藏表示。 h i g e n _ u h^{gen\_u}_i higen_u 是上一段的更新表示。 W g e n , q , W g e n , k W g e n , v 和 W g e n , o W^{gen,q},W^{gen,k}W^{gen,v}和W^{gen,o} Wgen,q,Wgen,kWgen,v和Wgen,o 是可学习的参数。 p ~ i \tilde p_i p~i 是投影前生成的参数,将由一层FFN处理。形式上, p i = F F N ( p ~ i ) p_i = FFN(\tilde p_i) pi=FFN(p~i) ,其中 p i ∈ R d h + 1 p_i \in \mathbb R^{d_h+1} pi∈Rdh+1 是查询集中第 i 个实例的最终生成参数。 p i p_i pi 中的前 d h d_h dh 个元素是权值,最后一个元素是偏置。
此外,基于生成的参数
p
i
p_i
pi 和查询实例
h
i
q
h^q_i
hiq 的隐藏表示,可以如下获得预测结果。
y
~
i
(
s
,
t
)
=
p
i
[
:
d
h
+
1
]
h
i
q
+
p
i
[
d
h
+
1
]
(13)
\tilde y_i^{(s,t)} = p_i^{[:d_h+1]}h^q_i + p_i^{[d_h+1]} \tag{13}
y~i(s,t)=pi[:dh+1]hiq+pi[dh+1](13)
其中 p i [ : d h + 1 ] h i q p_i^{[:d_h+1]}h^q_i pi[:dh+1]hiq 表示 p i p_i pi 中的第 d h d_h dh 元素, p i [ d h + 1 ] p_i^{[d_h+1]} pi[dh+1] 是其中的最后一个元素。 y ~ i ( s , t ) ∈ R \tilde y_i^{(s,t)} \in \mathbb R y~i(s,t)∈R 表示查询集中第i个实例的预测结果。此外, s s s 和 t t t 在这里表示当前查询实例的阶段和任务。
此外,当权重过大时,很容易导致过拟合问题[21]。因此,在训练过程期间对
p
i
[
:
d
h
+
1
]
h
i
q
p_i^{[:d_h+1]}h^q_i
pi[:dh+1]hiq(RegP)部署L1正则化和L2正则化,这可以通过计算以下两个损失函数来实现。
L
l
1
_
n
o
r
m
=
∥
p
i
[
:
d
h
+
1
]
∥
1
,
L
l
2
_
n
o
r
m
=
∥
p
i
[
:
d
h
+
1
]
∥
2
(14)
\mathcal L^{l1\_norm} = \parallel p_i^{[:d_h+1]}\parallel_1, \mathcal L^{l2\_norm}=\parallel p_i^{[:d_h+1]}\parallel_2 \tag{14}
Ll1_norm=∥pi[:dh+1]∥1,Ll2_norm=∥pi[:dh+1]∥2(14)
E. 训练和测试
1)Training Phase:在训练阶段,选择均方误差(MSE)作为主要损失函数,以统一训练目标和预测目标,其形式化如下。
L
m
a
i
n
=
1
Z
∑
s
=
1
N
t
r
a
i
n
s
∑
t
=
1
N
t
r
a
i
n
t
∑
i
=
1
N
t
r
a
i
n
(
s
,
t
)
(
y
i
(
s
,
t
)
−
y
~
i
(
s
,
t
)
)
2
(15)
\mathcal L^{main} = \frac{1}{Z}\sum_{s=1}^{N^s_{train}}\sum_{t=1}^{N^t_{train}}\sum_{i=1}^{N^{(s,t)}_{train}}(y_i^{(s,t)}-\tilde y_i^{(s,t)})^2 \tag{15}
Lmain=Z1s=1∑Ntrainst=1∑Ntrainti=1∑Ntrain(s,t)(yi(s,t)−y~i(s,t))2(15)
其中
N
t
r
a
i
n
s
N^s_{train}
Ntrains和
N
t
r
a
i
n
t
N^t_{train}
Ntraint 分别是当前批训练数据中的阶段数和任务数。
N
t
r
a
i
n
(
s
,
t
)
N^{(s,t)}_{train}
Ntrain(s,t) 是第s阶段和第t任务中的实例数。Z是当前批处理中的实例总数,可计算为
Z
=
∑
s
=
1
N
t
r
a
i
n
s
∑
t
=
1
N
t
r
a
i
n
t
∑
i
=
1
N
t
r
a
i
n
(
s
,
t
)
1
Z = {\textstyle \sum^{N^s_{train}}_{s=1} \sum^{N^t_{train}}_{t=1} \sum^{N^{(s,t)}_{train}}_{i=1}}1
Z=∑s=1Ntrains∑t=1Ntraint∑i=1Ntrain(s,t)1。
总的来说,用于优化所提出的模型中的参数的损失函数如下。
L
=
L
m
a
i
n
+
α
s
L
s
t
a
g
e
+
α
t
L
t
a
s
k
+
α
l
1
L
l
1
_
n
o
r
m
+
α
l
2
L
l
2
_
n
o
r
m
(16)
\mathcal L = \mathcal L^{main} + \alpha^s\mathcal L^{stage} + \alpha^t\mathcal L^{task} +\alpha^{l1}\mathcal L^{l1\_norm} + \alpha^{l2}\mathcal L^{l2\_norm} \tag{16}
L=Lmain+αsLstage+αtLtask+αl1Ll1_norm+αl2Ll2_norm(16)
其中
α
s
,
α
t
,
α
l
1
,
α
l
2
\alpha^s, \alpha^t, \alpha^{l1}, \alpha^{l2}
αs,αt,αl1,αl2是超参数。
此外,算法1中总结了详细的训练阶段。首先,对于一个时期中的每个训练步骤,我们对一批查询实例进行采样
D
i
q
∈
R
N
b
a
t
c
h
_
t
×
N
b
a
t
c
h
_
i
×
d
x
\mathcal D^q_i \in \mathbb R^{N^{batch\_t} \times N^{batch\_i} \times d_x}
Diq∈RNbatch_t×Nbatch_i×dx 和查询实例
D
i
s
~
∈
R
N
b
a
t
c
h
_
t
×
K
×
N
b
a
t
c
h
_
i
×
d
x
\mathcal D^{\tilde s}_i \in \mathbb R^{N^{batch\_t} \times K \times N^{batch\_i} \times d_x}
Dis~∈RNbatch_t×K×Nbatch_i×dx作为 算法1中第3-6行 中的训练实例,其中
N
b
a
t
c
h
_
t
N^{batch\_t}
Nbatch_t 和
N
b
a
t
c
h
_
i
N^{batch\_i}
Nbatch_i 分别表示任务和实例的批处理大小。注意,在上述采样过程中,从训练集中采样一批任务和实例,其中第 s 阶段的任务分布
p
(
T
s
)
p(\mathcal T^s)
p(Ts)可以是均匀分布。然后,通过CDG如第7行中的等式16评估总损耗。最后,在第8行,采用反向传播(BP)算法来更新CDG中包含的参数。

2)Testing Phase: 对于来自一个阶段的新任务,所提出的模型的预测过程有两个阶段,即,离线推理和在线测试,分别在算法2和算法3中详细描述。
Offline inferring(离线推理) 的目的是在测试集中推理出训练集中没有的新任务的先验知识。该阶段的详细过程如算法2所示。此阶段可以离线执行,以提高查询实例的预测速度。具体地,从第3行中的测试集中的新任务中选择用于第s阶段和第t任务的支持 D n e w s ~ , ( s , t ) ∈ R K × d x \mathcal D^{\tilde s,(s,t)}_{new} \in \mathbb R^{K \times d_x} Dnews~,(s,t)∈RK×dx。随后,可以获得每个支持实例的更新后的表示 h i g e n _ u ∈ R d g e n _ i n i t h_i^{gen\_u} \in \mathbb R^{d_{gen\_init}} higen_u∈Rdgen_init,并将其离线保存在第4行中,这为在线测试做好了准备。
通过 Online testing(在线测试) ,从支持实例中选择与同一任务的某个查询实例相关的先验知识,在不经过训练的情况下实现对新任务的质量预测。算法3描述了该阶段的详细信息。该阶段可以在线进行,以实现实时质量预测。具体地,对于第s阶段和第t任务中的查询实例,我们在第3-4行中索引对应支持实例的更新表示。然后,可以通过第5行中的等式11-13来计算所选择的查询实例的预测结果。


F. 计算复杂性讨论
CDG的时间复杂度分析如下。根据图1中CDG的结构,CDG的时间复杂度主要由三部分组成,即:MFE、CFG和IDG。首先,该算法的时间复杂度为 O ( ∣ P ∣ l m a x ( P ) + ∣ M ∣ + l G A T n h ( ∣ M ∣ + ∣ ε ∣ ) ) O(\mid P\mid l_{max(P)} + \mid \mathcal M \mid + l_{GAT}n_h(\mid \mathcal{M} \mid + \mid \varepsilon \mid)) O(∣P∣lmax(P)+∣M∣+lGATnh(∣M∣+∣ε∣)) 其中 ∣ P ∣ , l m a x ( P ) , l G A T , n h , ∣ ε ∣ \mid P\mid, l_{max(P)},l_{GAT}, n_h, \mid \varepsilon \mid ∣P∣,lmax(P),lGAT,nh,∣ε∣分别表示依赖图 G \mathcal G G 中路径的个数、路径的最大长度、图注意网络(GAT)的层数、图注意网络的头数和依赖图的边数。其次,CFG的时间复杂度为 O ( K 2 + K ) O(K^2 + K) O(K2+K)。最后,IDG的时间复杂度为 O ( K ) O(K) O(K)。因此,CDG的时间复杂度为 O ( ( K + 1 ) ( ∣ P ∣ l m a x ( P ) + ∣ M ∣ + l G A T n h ( ∣ M ∣ + ∣ ε ∣ + K 2 + K ) ) ) O((K+1)(\mid P\mid l_{max(P)} + \mid \mathcal M \mid + l_{GAT}n_h(\mid \mathcal{M} \mid + \mid \varepsilon \mid + K^2 + K))) O((K+1)(∣P∣lmax(P)+∣M∣+lGATnh(∣M∣+∣ε∣+K2+K))) 。类似地,BFL和SBFL的时间复杂度与CDG大致相同,即 O ( ( K + 1 ) ( ∣ P ∣ l m a x ( P ) + ∣ M ∣ + l G A T n h ( ∣ M ∣ + ∣ ε ∣ + K 2 + K ) ) ) O((K+1)(\mid P\mid l_{max(P)} + \mid \mathcal M \mid + l_{GAT}n_h(\mid \mathcal{M} \mid + \mid \varepsilon \mid + K^2 + K))) O((K+1)(∣P∣lmax(P)+∣M∣+lGATnh(∣M∣+∣ε∣+K2+K))) 。
然而,在第III-E2节中设计的离线推断阶段和在线测试阶段的分离可以优化CDG的时间复杂度。在这两个阶段分离之后,CDG的时间复杂度降低到 O ( ∣ P ∣ l m a x ( P ) + ∣ M ∣ + l G A T n h ( ∣ M ∣ + ∣ ε ∣ ) + K ) O(\mid P\mid l_{max(P)} + \mid \mathcal M \mid + l_{GAT}n_h(\mid \mathcal{M} \mid + \mid \varepsilon \mid) + K) O(∣P∣lmax(P)+∣M∣+lGATnh(∣M∣+∣ε∣)+K),其远小于BFL和SBFL。然而,这两个相的分离需要额外的存储空间 h i g e n _ u h^{gen\_u}_i higen_u,可以用空间复杂度来表示 O ( K N T ) O(KN^T) O(KNT)。 N T N^T NT 表示测试集中的任务数。
四.案例研究:实验和分析
A. 数据集描述
B. 实验设置
C. 实验结果
D. 分析与讨论
V. 结论
在本文中,我们形式化了多阶段制造过程中的小样本质量预测,以解决缺乏注释数据的问题,并在没有额外训练过程的情况下处理以前看不见的任务。此外,本文还设计了一种新的CDG来实现小样本质量预测。拟议的CDG由三个模块组成,即:MFE、CFG和IDG。特别是,MFE被设置为编码来自不同机器的特征。CFG被设计成基于支持实例生成关于阶段和任务的先验知识。IDG用于生成解码器中的参数,实现查询实例的质量预测。最后,利用实际生产线上收集的公共质量预测数据集验证了CDG的有效性。实验结果表明,CDG算法在多种支持集大小下均能达到SOTA结果。此外,还通过实验分析了CDG中关键模块的作用。
未来,我们将尝试通过不同的方法,例如生成多层参数和从小样本学习引入高级方法,来提高所提出的模型在小样本质量预测任务上的性能[22]。此外,CDG依赖于许多手工设计的神经网络,并且这些神经网络的次优组合可能损害模型的性能。因此,将探索神经结构搜索(NAS)算法[30],以自动识别质量预测的最佳神经结构。而且,随着物联网设备的不断记录,获取的数据逐渐增多。这有利于CDG在大规模数据集上的应用,也是一个很有前途的方向。

















 4080
4080

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









