






2023年8月,通过xianling哥的讲解,终于大彻大悟分布式系统了!
分布式出现的思想:为了用廉价的、普通的机器完成昂贵的大型主机无法完成的计算、存储任务。其目的是利用更多的机器,处理更多的数据。
一、其实你早就接触了什么是分布式、什么是中间件
但凡有两台服务器不在一起,就是分布式系统。
分布式不是近几年出现的技术,在2000年初期,阿里的业务一个服务器就放不下了,那时候就在研究分布式了。
单体架构 VS 分布式架构
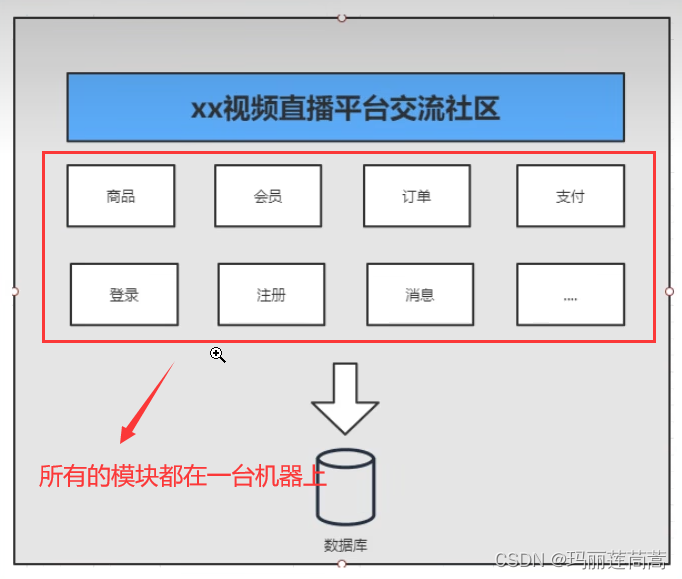
缺点:
-
但凡是一个标点符号写错了,都要整个系统重新编译发布,维护成本太高
-
一个系统的所有功能必须使用同一种语言开发,如果想要换语言,就要全部推翻重来。但是分布式系统的不同功能模块可以用不同的语言开发(比如商品模块用Java,订单模块用go语言),因为消息中间件可以屏蔽语言之间的差异。
二、理解分布式计算和分布式存储
二者区别
分布式计算:
- 应用服务器的解耦。比如阿里巴巴以前只用一台服务器做用户注册、订单、支付、售后等所有的服务。现在拆分成用户注册服务器、订单提交服务器、支付服务器等。
- 以前不注重服务的可用性的时候,订单系统可能只部署一个。但是我们现在考虑万一这个宕掉了怎么办? 所以同一个服务至少要部署两个(这里服务的意思就是整个project,部署的时候不是以接口为单位,而是以project为单位。当然部署了多个project,那么一个接口也就有多个咯),当然这两个可以在同一台机器上,也可以在不同的机器上。一般是在不同的机器上,因为万一机器宕掉了,两个在同一台机器上的话不就都完蛋了吗
分布式存储:就是mysql集群。数据量太大了,单机mysql放不了了,就把数据分库分表放到10台mysql服务器上,每台服务器各存1/10的数据。
三、CAP和BASE理论

四、分布式系统进程间通信(分布式系统的核心)
分布式的核心内容是IPC进程间通信,注意是服务器和服务器之间的通信,有如下几种方式:
-
RPC 远程过程调用:屏蔽底层细节,调用远程方法就像调用本地方法一样(同步)
-
client stub 和 server stub
-
RMC 远程方法调用(同步)
-
MOM 消息中间件(不要求双方在线,异步)
-
HTTP(spring cloud NetFlix就是用HTTP通信)
既然是两台机器之间的通信,为什么不直接用TCP/IP?
首先,不是不用TCP/IP,而是把TCP/IP作为通信的底层,在TCP/IP之上构建RPC、RMC、和MOM的框架。因为TCP/IP的字段不能满足进程间的需求,我们要新增一些字段,所以就要在TCP/IP协议的基础上构造中间件自己的协议。换句话说,消息中间件的底层协议还是TCP/IP协议
其实可以用HTTP请求,但是我们不用,道理很简单,比如出门防晒你其实可以把塑料袋套头上,但是哪有戴帽子合适呀!不用HTTP实现两个机器的通信是因为,HTTP一般用于客户端对服务器的一次性请求,建立短链接。但是分布式系统的进程间通信不是客户端和服务器的通信,而是多个服务器之间的通信。比如有一个订单业务服务器,一个会员业务服务器,二者之间如何交互,这是一个长期通信的过程,需要建立长链接。

我们需要在TCP/IP基础上自己重新构建一种通信框架,也就是RPC、RMC和MOM。
MOM分类
-
分布式消息中间件
-
ActiveMQ
-
不用了
-
RabbitMQ
-
开源
-
和spring是一家开发出来的,和spring的适配性最高
-
美团、滴滴都在用
-
Kafka
-
性能最好,但不支持事务
-
京东的JMQ就是在kafaka外面套了一个壳
-
RocketMQ
-
阿里和滴滴自研的
消息中间件MOM理解
RPC和RMC通信的缺点
-
要求client和server同时在线
-
client会被阻塞,什么都不能干(这是同步的一种特点,异步的话就是两个线程各干各的,谁也不需要等谁)
MOM的优点
-
不要求client和server同时在线
-
延迟隐藏。client请求完了以后,直接去做下一件的任务,感受不到client的阻塞
MOM 都有哪些协议?
MOM如何实现的异步?
借助消息队列。
MOM工作流程
不同消息格式的转换,
client订购消息,server推送消息
五、分布式系统下如何生成UUID
林哥给出的生成UUID唯一的方法:
- 法一:MYSQL层校验
- 法二:在service层生成UUID,去MySQL校验是否存在,存在再重新生成(for循环
首先要明确一下,一提到UUID本身指的就是分布式系统下的唯一ID

在单体系统中,我们可以用时间戳,也就是当前时间距离1970年1月1日零点的毫秒数的方式实现ID,但是也会存在同一毫秒内产生两个实体的情况,所以我们采用毫秒数+随机数(浪潮就是这么实现的),但是这样做缺少了验证这一步,虽然99.9999%是唯一的,但是还是不能保证百分之百哦,所以林哥才会反复提到“MySQL层校验”。
生成分布式UUID的常见方案:
- 借助数据库主键
- redis
- 算法,就是想个办法拼凑出来全局唯一的ID
- java原生的UUID(不推荐使用,但是jd也在用)
- 改进java原生的UUID:
java 原生的UUID为36位 or 32位,太长. 这里提供一个位数较短的UUID. * UUID生成规则,当前时间减去'零时'的毫秒数 + N位随机数,转变成62进制的String类型. * 当前配置可满足30年内每毫秒10^9分之一的碰撞. * 实测现在长度为13位,想要更短的话可以调整下方的几个参数
- Twitter开源的雪花算法,没有两篇雪花是相同的。用时间戳,机房ID,机器ID,每台机器上的自增数合成
- 美团开源的落叶算法,同样,“没有两片相同的落叶”
- car-fence用的糊涂工具包hutool
法(一)数据库主键自增
如何让数据库主键自增呢?就要每次索要UUID的时候向表里插入一条数据,当然这条数据本身没有任何意义,只是为了推动主键自增,然后把生成的主键返回给java程序
CREATE TABLE `sequence_id` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
`stub` char(10) NOT NULL DEFAULT '',
PRIMARY KEY (`id`),
UNIQUE KEY `stub` (`stub`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
优点:实现简单,仅此而已
缺点:
- 每次获取UUID都要访问数据库,访问数据库可比访问redis缓存慢多了,由此可见这种实现方式比不上接下来要将的借助redis实现。
- ID没有业务含义,通过主键看不出这是个啥
- 可以通过主键的差值判断一天产生了多少订单量,这可是商业机密呀
- 淘宝用户有上亿个,每个用户都有UUID,一个表肯定放不下,那么就要分库分表,分库分表也挺累的。
法(二)数据库号段(其实这个我没看懂哈)
批量获取,然后存在在内存里面,需要用到的时候,直接从内存里面拿就舒服了,主要是减少了访问数据库的次数。
数据库的号段模式也是目前比较主流的一种分布式 ID 生成方式。像滴滴开源的Tinyidopen in new window 就是基于这种方式来做的。不过,TinyId 使用了双号段缓存、增加多 db 支持等方式来进一步优化
1. 创建一个数据库表。
CREATE TABLE `sequence_id_generator` (
`id` int(10) NOT NULL,
`current_max_id` bigint(20) NOT NULL COMMENT '当前最大id',
`step` int(10) NOT NULL COMMENT '号段的长度',
`version` int(20) NOT NULL COMMENT '版本号',
`biz_type` int(20) NOT NULL COMMENT '业务类型',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
一次获取step长度的id,获取的批量 id 为:current_max_id ~ current_max_id+step,version 字段主要用于解决并发问题(乐观锁)
2. 先插入一行数据
INSERT INTO `sequence_id_generator` (`id`, `current_max_id`, `step`, `version`, `biz_type`)
VALUES
(1, 0, 100, 0, 101);
3. 通过 SELECT 获取指定业务下的批量唯一 ID
业务和业务之间的UUID是独立的,可以重复。可能后续会把biz_type字段拼到UUID里
SELECT `current_max_id`, `step`,`version` FROM `sequence_id_generator` where `biz_type` = 101
4. 不够用的话,更新之后重新 SELECT 即可。
UPDATE sequence_id_generator SET current_max_id = 0+100, version=version+1 WHERE version = 0 AND `biz_type` = 101
SELECT `current_max_id`, `step`,`version` FROM `sequence_id_generator` where `biz_type` = 101
优点:相比于上一个方法,减少了访问数据库的次数
缺点: 就是上一个方法的另外3个缺点
- ID没有业务含义,通过主键看不出这是个啥
- 可以通过主键的差值判断一天产生了多少订单量,这可是商业机密呀
- 淘宝用户有上亿个,每个用户都有UUID,一个表肯定放不下,那么就要分库分表,分库分表也挺累的。
法(三)redis的incr自增
incr UUID 法(四) 算法们
上面也都说过了
六、分布式锁
先来看一个用Redis实现分布式锁的完整代码:
public List<Node> getDataByRedisLock(){
List<Node> nodeList = null;
//===================加锁
String uuid = UUID.randomUUID().toString();
Boolean lock = redisTemplate.opsForValue().setIfAbsent("redis-lock", uuid,100,TimeUnit.SECONDS);
if (lock){
try {
nodeList = getNodesByMysql();
}finally {
//===================解锁
//lua脚本
String script = "if redis.call(\"get\",KEYS[1]) == ARGV[1] then return redis.call(\"del\",KEYS[1]) else return 0 end";
redisTemplate.execute(
new DefaultRedisScript<Long>(script,Long.class),
Arrays.asList("redis-lock"),
uuid
);
}
}else { //注意,如果是用synchronize这种本地锁的话,
//没获取到锁的时候会自动阻塞,然后尝试下一次加锁,
//这是synchronize底层帮我们写好了的;但是这里redis得靠我们手动实现
try {
System.out.println("没有获取锁重试");
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
//重试
getDataByRedisLock();
}
return nodeList;
}是不是很简单? 虽然接下来我们要讲一大堆分布式锁的原理,但是实际使用起来,只有两行代码而已,当然咯简单是因为底层封装的好,我们当然要去看一下底层。
分布式锁的实现有很多形式,只不过这里选择了用Redis的setIfAbsent方法实现分布式锁,底层其实是retranlock,是一个悲观锁。
6.1 为什么要有分布式锁?或者说,分布式锁和本地锁的区别在于?
其独特性在于分布式系统中,相同的服务被部署在不同的机器上。单体系统下,对多线程加锁,生成的这个锁放在JVM运行时数据区里,因为所有线程都在同一台机器上,所以大家都能访问到。但是分布式系统下,我在一台机器上生成一个锁,其他机器是访问不到的呀。所以分布式锁必须放在多台机器都能访问到的地方,比如Redis,数据库这种所有机器都能访问到的公共存储区。
6.2 分布式锁的实现方式
常见分布式锁实现方案如下:
- 借助关系型数据库比如 MySQL 实现分布式锁(×,一般是依托于mysql的唯一索引或排它锁去实现,性能太差)
- 借助分布式协调服务 ZooKeeper 实现分布式锁(√)
- 借助分布式键值存储系统比如 Redis 实现分布式锁(√)
6.3 我们今天主要讲的是用Redis实现分布式锁
(1)保证上锁的原子性
可以自己先想一下如何实现。
肯定不是用watch命令哈,watch命令实现的是Redis级别的乐观锁,但是我们现在要实现的java程序级别的分布式锁。
加锁就是“占坑”,告诉别人我已经开始用这个资源了,并且加锁之前还要判断别人有没有这个锁,是不是想起来了setnx命令?因为setnx命令就是在set之前要判断一下这个key是否已经存在了。但是还有一个问题,为了避免还没解锁前服务就宕掉了导致这个资源被一直锁着,所以我们必须在加锁的同时给这个锁设定过期时间,也就是说我们的① set一个键值对,② 判断是否已经存在,③设置过期时间 这3个操作不能被打断,也就说必须放在同一个原子操作里,而我们又知道由于Redis是单线程的,所以Redis的一条命令就是一个原子操作,那么我们就需要一条命令同时去做上面的事情。setex可以实现吗?No

好了不绕弯子了,Redis命令是这样实现的:
set 锁的key 锁的value nx ex 50对应到java里,Redistemplate帮我们封装了这样一个方法:
redisTemplate.opsForValue().setIfAbsent(key, value, releaseTime, TimeUnit.SECONDS);我们又会想,给键值对设置过期时间,万一被锁的资源没用完呢,键值对就过期了怎么办?会出现两个问题:
问题①:这个时候线程2跑来尝试加锁,发现居然加上了,那么此时线程1和线程2同时操作资源,会出问题的呀
问题②:而且就算同时操作资源这一步没出问题,此时只有一把锁,但是线程1和2都还没执行删锁操作,线程1会把线程2的锁给删掉!
没关系,还有续约操作~ PS: 有的系统不注重性能,可能会把过期时间设置的特别大,这样它就不用考虑续约了。
(2)看门狗续约
续约操作也很复杂,所以直接写了一个第三方包。
对于 Java 开发的小伙伴来说,已经有了现成的解决方案:Redissonopen in new window 。其他语言的解决方案,可以在 Redis 官方文档中找到,地址:https://redis.io/docs/manual/patterns/distributed-locks/
jar包:
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson-spring-boot-starter</artifactId>
<version>3.15.6</version>
</dependency>配置bean:
@Configuration
public class RedissonConfig {
@Bean
public RedissonClient redissonClient(){
Config config = new Config();
config.setTransportMode(TransportMode.NIO);
SingleServerConfig singleServerConfig = config.useSingleServer();
//可以用"rediss://"来启用SSL连接
singleServerConfig.setAddress("redis://linux100:6379");
RedissonClient redisson = Redisson.create(config);
return redisson;
}
}redisson使用起来就跟本地锁一样:
@RestController
public class UserController {
@Autowired
private RedissonClient redissonClient;
@GetMapping("/test")
public String test() {
RLock lock = redissonClient.getLock("test-lock");
try {
System.out.println("加锁成功!!!");
Thread.sleep(10000);
} catch (Exception e) {
e.printStackTrace();
}finally {
System.out.println("释放锁成功!!!");
lock.unlock();
}
return "success";
}
}如果我们不就是不想导入redisson,不采用续约的操作呢?那就会出现上述两个问题

而下面保证删锁原子性的操作只能解决第二个问题,还是存在第一种问题的隐患!
(3)保证删锁的原子性(如果采用看门狗的话,那么直接删就行了,完全不用设置UUID)
理想情况下(java线程顺序执行的情况下)肯定是用完资源以后,用redis的del命令删掉这个锁,然后第二个线程继续上锁。但是存在这样一种情况,线程1加锁用资源的时候,超出了过期时间还没用完,因为没采用看门狗续约此时锁过期了,线程2尝试加锁发现加上了!因为锁是同名的,所以线程1最后在finally里执行删锁操作的时候把线程2加的锁给删掉了。
解决方法有两个:
法(一):对过期时间进行续约,这样就不会出现线程1的锁过期,线程2来加锁的情况了,这是从源头解决问题
法(二):给每个锁配备一个UUID作为value,删锁之前用UUID判断一下是不是自己设置的锁
对于法(二),实现如下
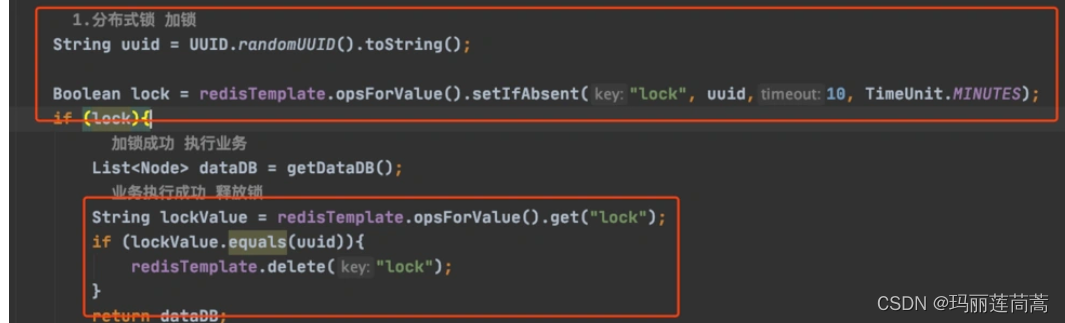
还会有一个问题(我靠这个太难想到了,但是操作系统里举过这个例子),因为判断UUID和删锁的操作是分两步实现的:
- 判断UUID
- 删锁
如果线程1判断完UUID确实是自己的,可以开始删了!这个时候刚好线程1被CPU切换走了,刚好线程1的锁过期了,另一台机器上的线程2刚好尝试来加锁发现加上了,然后CPU调度回线程1的时候线程1直接第二步执行删锁操作,又出错了!解决方法只有一个就是让判断UUID和删锁的操作不要分成两步,而是作为一个原子性操作,java实在无能为力了,只能借用Lua脚本。
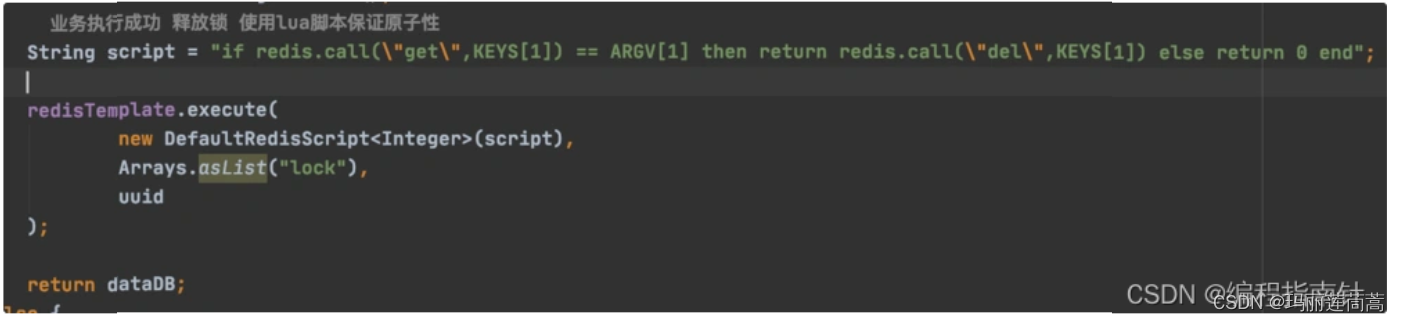

















 749
749

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









