







 本文介绍了使用JetBrains的DataGrip工具进行数据库操作,并详细讲解了SQL中的DML(数据库操作语言)和DQL(数据查询语言),包括如何在DataGrip中连接MySQL数据库,以及DML的insert into、update和delete操作,DQL的基本查询、条件查询、聚合查询、分组查询、排序查询和分页查询的用法。
本文介绍了使用JetBrains的DataGrip工具进行数据库操作,并详细讲解了SQL中的DML(数据库操作语言)和DQL(数据查询语言),包括如何在DataGrip中连接MySQL数据库,以及DML的insert into、update和delete操作,DQL的基本查询、条件查询、聚合查询、分组查询、排序查询和分页查询的用法。
文章目录
DataGrip图形化界面工具
为了更方便地操作数据库,我们需要使用图形化界面工具DataGrip来代替命令行的操作
安装并使用DataGrip
-
DataGrip,点击此链接即可进入官网下载。
-
安装并使用DataGrip
(1)初次使用需要按照如下操作进行数据库的连接,选中Data Source -> MySQL
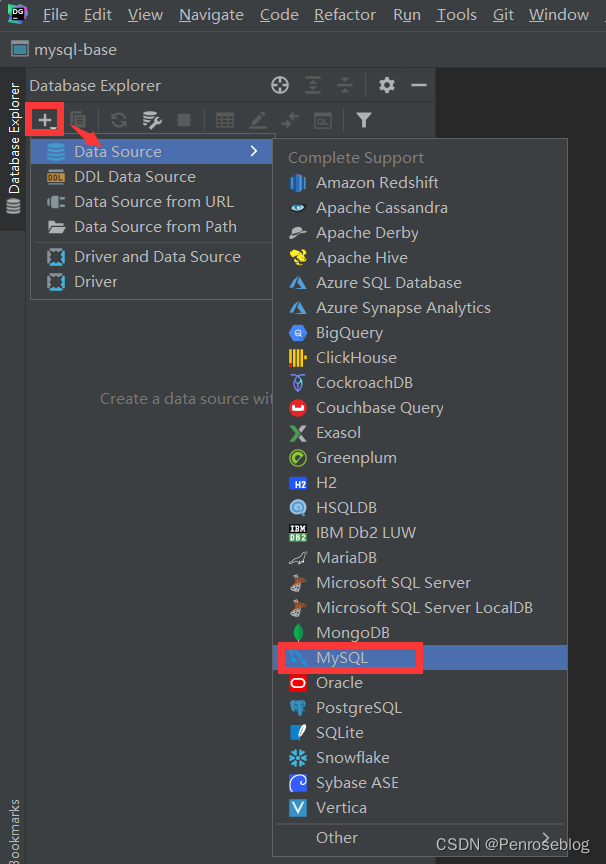
(2)输入之前安装MySQL设置的数据库的账号和密码并点击“DownLoad”下载驱动
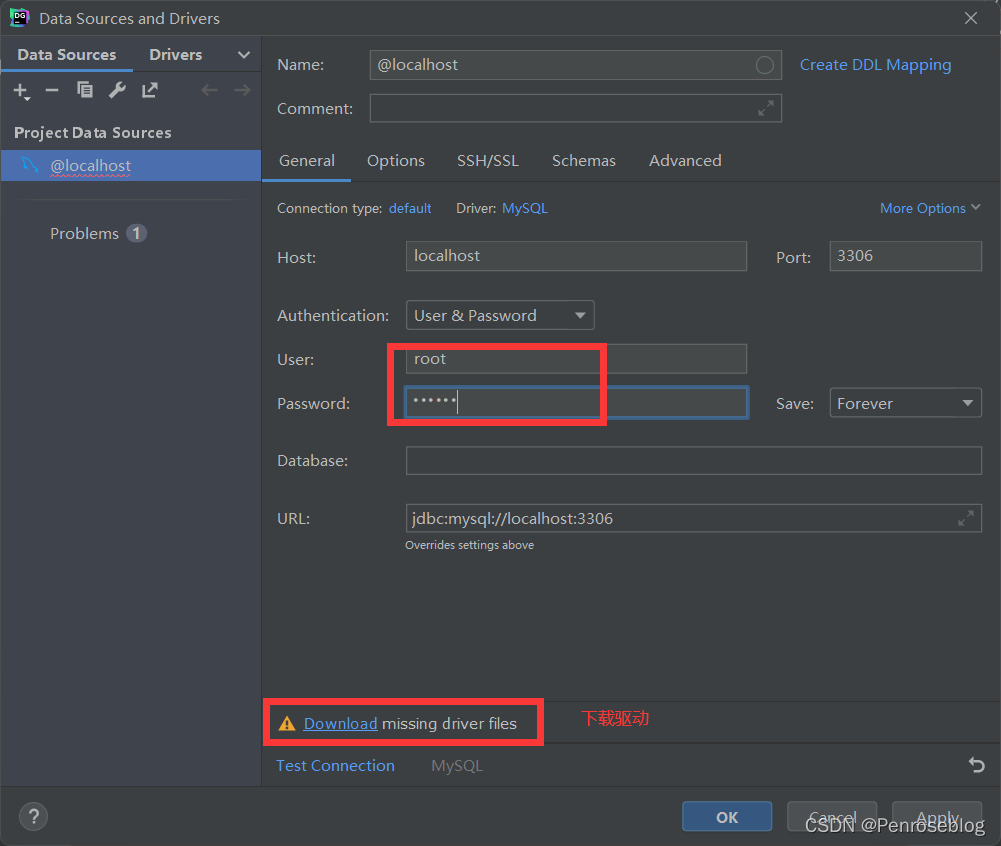
(3)下载完驱动后,点击“Test Connection”,如果出现Succeeded,则表明数据库连接成功
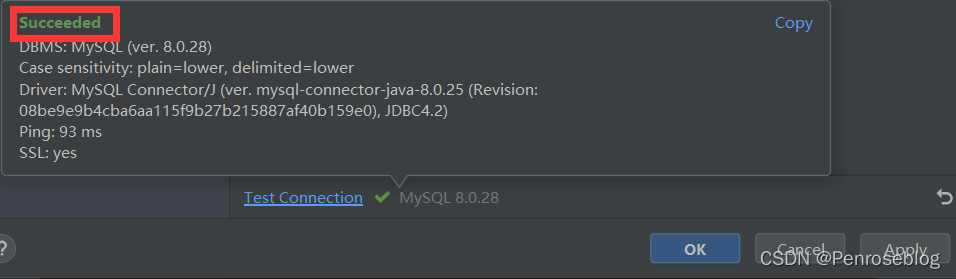
(4)连接成功后,将“All schemas”选中,显示MySQL中自带的系统库
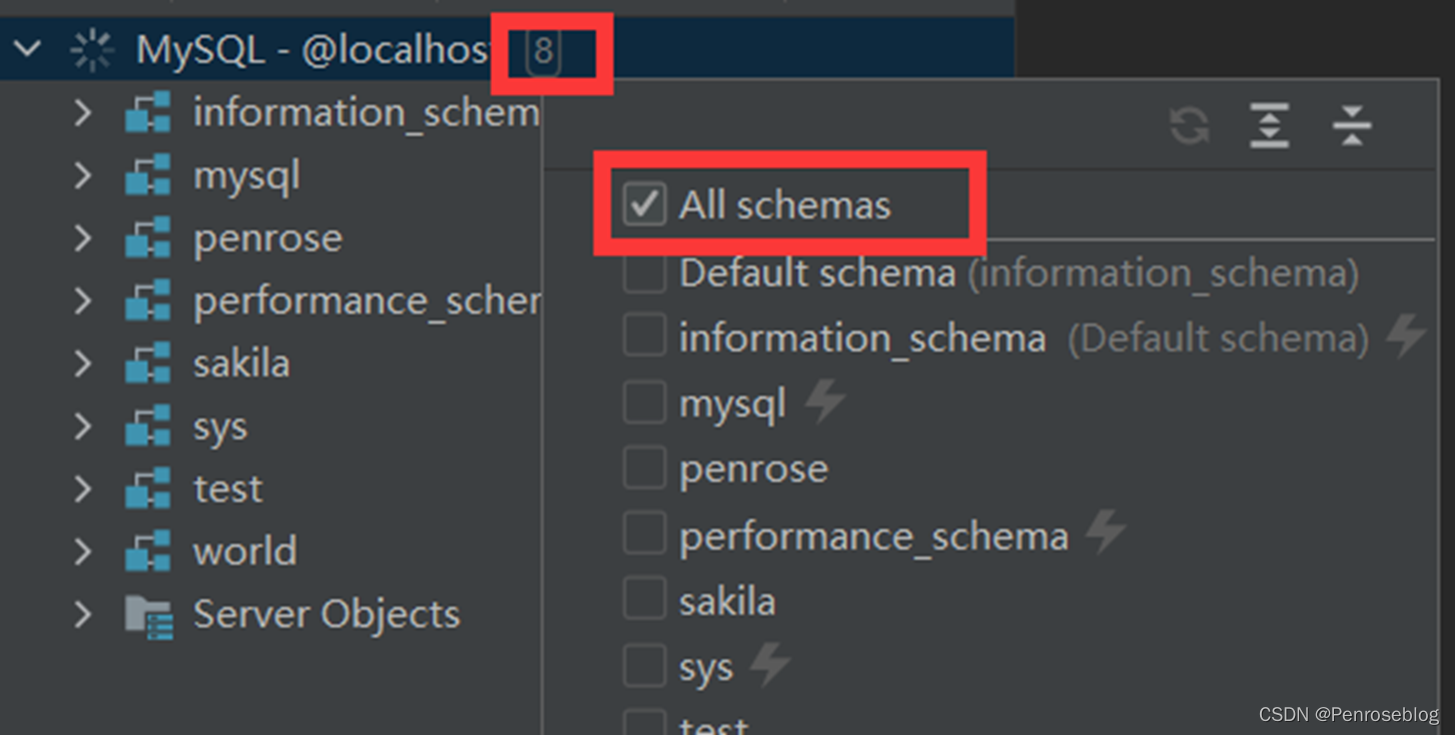
注:此处的schema就相当于database,即在创建数据库时,我们也可以使用create schema,它与create database效果相同。
(5)在某一数据库上右击,即可完成数据库/表格的相关工作()。在某一表格上右击,即可完成表格的相关操作。并且工具还会自动生成相应的SQL语言
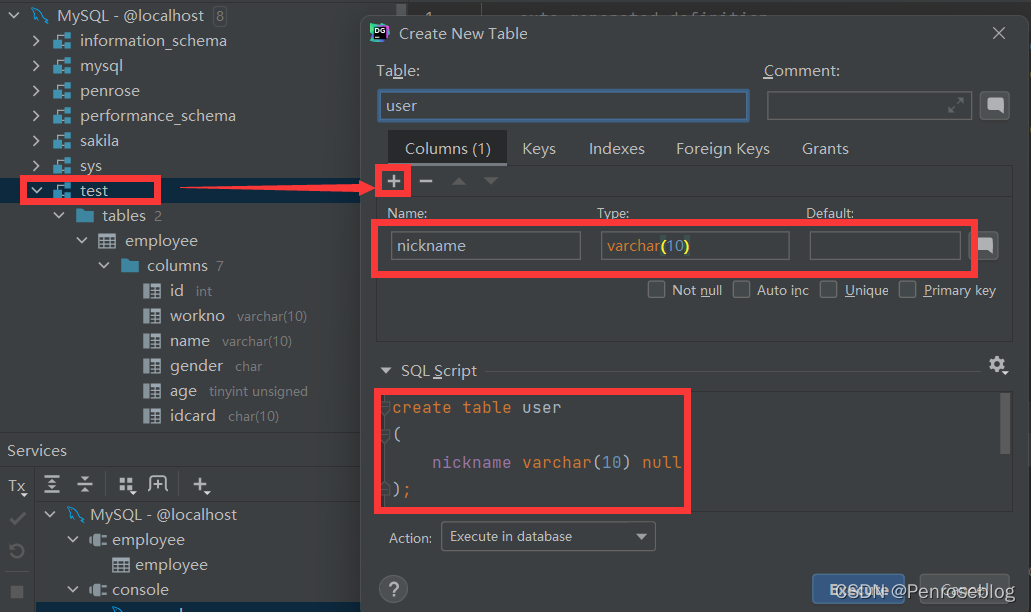
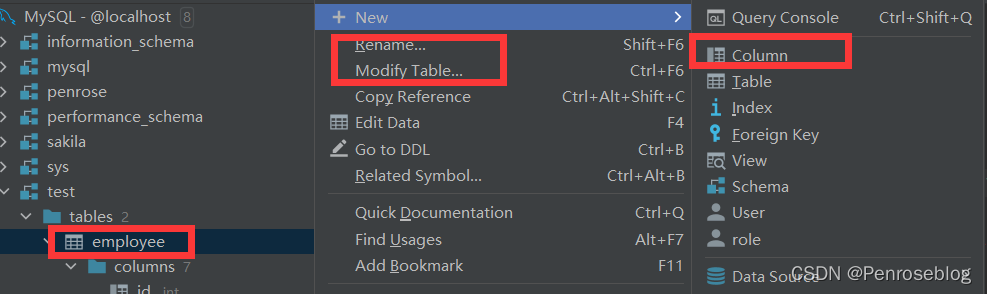
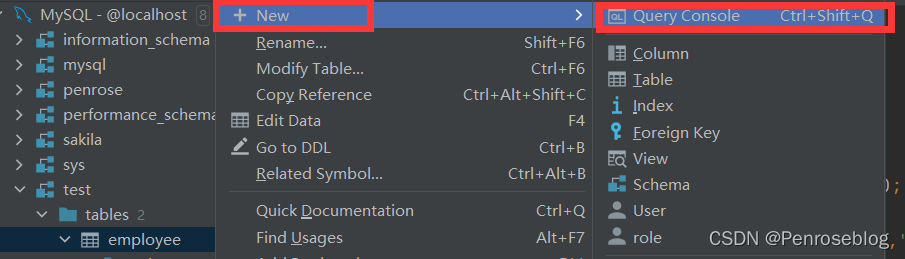
(6)如果想要在工具中使用SQL语言,我们可以打开“Query Console”页面
注:编写完一条SQL语句时,一定要选中这条语句,然后再去执行
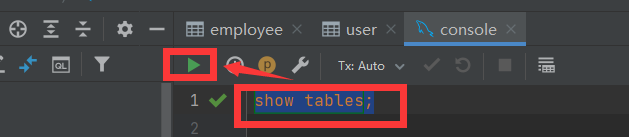
SQL
DML-数据库操作语言
DML主要是用来对数据库中的表进行增删改操作
添加数据insert into
# 向指定字段插入数据,插入时字段名和值是一一对应的
# **多个字段间用逗号隔开**
# 如果插入的值为字符串或日期,需要用单引号将其包围
insert into 表名 (字段名1,字段名2) values(值1,值2);
# 为全部字段插入数据,字段名称可以省略不写
insert into 表名 [字段名1,字段名2] values(值1,值2);
# 批量插入数据,**不同组数据间用逗号隔开**
insert into 表名 (字段名1,字段名2) values(值1,值2);
insert into 表名 values(值1,值2),(值1,值2),(值1,值2);
# 实例
insert into user values (001,'penrose',18,'男','341202xxxxxxxxxxxx'),(002,'cp',18,'男','341212xxxxxxxxxxxx');
修改数据update
# 修改数据时,条件可加可不加。如果不加条件,则默认会修改表中的**全部数据**
# **多个字段间用逗号隔开**
update 表名 set 字段名1 = 值1,字段名2 = 值2 [where 条件];
# 实例 将user表中姓名为"penrose"的性别修改为女
update user set gender = '女' where name = 'penrose';
删除数据
# 删除表格的条件可有可无,如果没有条件,则默认删除整张表中的数据
# 此语句只能删除某一个完整的对象的值,不能删除某一单独的属性(字段)的值
# 删除某一字段的值,就需要使用update,然后将其值设置为''或null
delete from 表名 [where 条件]
#实例 删除user表中姓名为cxf的数据
delete from user where name = 'cxf';
注:drop是操作表的结构/模型,delete from是操作表的数据
DQL-数据查询语言
DQL用来查询数据库中表的记录
基本查询
# 别名可有可无
select 字段名1 [as] [ 别名],字段名2 [as 别名] from 表名;
#查询所有字段数据
# 在想查询所有字段时,最好不要写*。第一,不直观;第二,效率不高。所有在查询时最好补全所有的字段。但在学习时为了方便,可使用*
select * from 表名
#查询结果中不包含重复的数据
select distinct 字段名1 [as 别名],字段名2 [as 别名] from 表名;
条件查询
select 字段名 from 表名 where 条件;
#实例
# 查询年龄为88的员工信息
select * from employee where age = 88;
#查询年龄小于28的员工信息
select * from employee where age < 28;
#查询年龄小于等于20的员工信息
select * from employee where age <= 20;
#查询没有身份证的员工信息
select * from employee where idcard is null;
#查询有身份证的员工信息
select * from employee where idcard is not null;
#查询年龄不等于88的员工信息
select * from employee where age != 88;
#查询年龄在15-20间的员工信息
select * from employee where age between 15 and 20;
#查询性别为女且年龄小于25的员工信息
select * from employee where gender = '女' and age < 25;
#查询年龄为18,20,40的员工信息
select * from employee where age = 18 or age = 20 or age = 40;
select * from employee where age in(18,20,40);
#查询姓名为两个字的员工信息
select * from employee where name like '__';
#查询身份证号最后一位为X的员工信息
select * from employee where idcard like '%X';

between and 中的数包含的关系是小于等于和大于等于
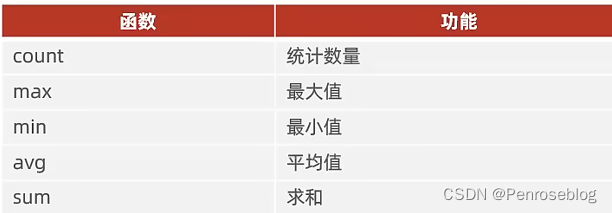
聚合查询
将一列数据聚合在一起,然后进行纵向计算。
纵向计算由聚合函数来完成
NULL值不参与聚合运算
select 聚合函数(字段列表) from 表名;
#实例
#统计员工总人数
select count(*) from employee;
#统计员工平均年龄
select avg(age) from employee;
#统计员工最大年龄
select max(age) from employee;
#统计员工最小年龄
select min(age) from employee;
#统计员工年龄之和
select sum(age) from employee;
分组查询
select 字段名 from 表名 [where 条件] group by 分组字段名 [having 分组后的过滤条件];
#实例
#根据性别分组,统计男性员工女性员工的数量
#写上gender字段是为了区分性别的数量
select gender,count(*) from employee group by gender;
#根据性别分组,统计男性员工和女性员工的平均年龄
select gender,avg(age) from employee group by gender;
#查询年龄小于15的员工,并根据工作地址分组,获取员工数量大于等于3的地址
select workaddress,COUNT(*) 'address_count' from employee where age < 15 group by workaddress having address_count > 3;
注:
where与having的区别:
(1)执行时机不同:where是分组前过滤,having是分组后过滤
(2)判断条件不同:where不能对聚合函数进行判断,但having可以执行顺序:where>聚合函数>having
分组之后查询的字段一般为聚合函数和分组字段,查询其他的没有意义
排序查询
#SQL中支持多字段排序
#排序默认为asc升序排列,desc为降序排列
select 字段名 from 表名order by 字段名 asc/desc
#实例
#根据年龄对公司员工进行升序排序
select * from employee order by age;
#根据入职日期对员工进行降序排序
select * from employee order by entrydate desc;
#根据年龄对员工进行排序,如果年龄相同,则根据入职日期降序排序
select * from employee order by age,entrydate desc;
分页查询
select 字段名 from 表名 limit 起始索引,查询记录数;
#实例
#查询第1页员工数据,每页展示10条记录
#查询第一页数据,起始索引可省略
select * from employee limit 0,10;
select * from employee limit 10;
#查询第2页员工数据,每页展示10条记录 (页码-1)*一页的记录数
select * from employee limit 10,10;
#查询性别为男且年龄在20-40岁之间的前五个员工信息,按照年龄和入职时间的升序排序
select * from employee where gender = '男' and (age between 20 and 40) order by age,entrydate limit 5;
注:
(1)起始索引从0开始,起始索引=(页码-1)*每页记录数
(2)分页查询是MySQL中独有的功能,是它自己的方言,不同的数据库有不同的实现
(3)如果查询条件过多,则可以将条件用括号包围起来

















 8168
8168

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









