







像Kafka等第三方数据源,Alink目前还没有可以直接在pom文件里面导入的依赖,需要用Alink提供的插件下载器,将插件下载到本地,然后导入到项目中,才可以完成连接
官方文档
https://www.yuque.com/pinshu/alink_guide/plugin_downloader
package source_sink;
import com.alibaba.alink.common.AlinkGlobalConfiguration;
import com.alibaba.alink.common.io.plugin.PluginDownloader;
import java.util.List;
public class PluginDemo {
public static void main(String[] args) throws Exception {
// 插件下载位置
String downloadPath = "plugins\\";
// 设置插件下载的位置,当路径不存在时会自行创建路径
AlinkGlobalConfiguration.setPluginDir(downloadPath);
// 获得Alink插件下载器
PluginDownloader pluginDownloader = AlinkGlobalConfiguration.getPluginDownloader();
// 从远程加载插件的配置项
pluginDownloader.loadConfig();
// 展示所有可用的插件名称
List<String> plugins = pluginDownloader.listAvailablePlugins();
System.out.println("----------------------");
System.out.println("alink中所有的插件:" + plugins);
// 显示第0个插件的所有版本
String pluginName = plugins.get(4); // kafka
List<String> availableVersions = pluginDownloader.listAvailablePluginVersions(pluginName);
System.out.println("----------------------");
System.out.println(pluginName);
System.out.println(availableVersions);
// 下载某个插件的特定版本
//String pluginVersion = availableVersions.get(4);
//pluginDownloader.downloadPlugin(pluginName, pluginVersion);
// 运行结束后,插件会被下载到"/Users/xxx/alink_plugins/"目录中
// 下载某个插件的默认版本
pluginDownloader.downloadPlugin(pluginName);
// 运行结束后,插件会被下载到"/Users/xxx/alink_plugins/"目录中
}
}
这里的插件下载位置,是idea项目中的相对路径
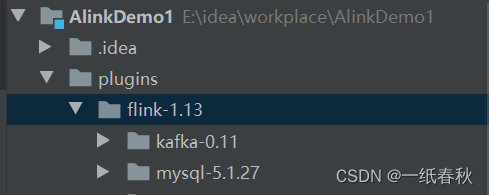
String downloadPath = “plugins\”; 下载的插件就会保存在plugins文件夹下面的flink-1.13里面
首先查看Alink支持下载的全部插件
alink中所有的插件:[datahub, derby, hadoop, hive, kafka, mysql, odps, onnx_predictor, oss, parquet, redis,
s3-hadoop, s3-presto, sqlite, tf_predictor_linux, tf_predictor_macosx, tf_predictor_windows, torch_predictor, xgboost, base_cased_ckpt, base_cased_saved_model, base_cased_vocab, base_chinese_ckpt,
base_chinese_saved_model, base_chinese_vocab, base_multilingual_cased_ckpt, base_multilingual_cased_saved_model, base_multilingual_cased_vocab, base_uncased_ckpt, base_uncased_saved_model, base_uncased_vocab,
libtorch_linux, libtorch_macosx, libtorch_windows, tf115_python_env_linux, tf115_python_env_macosx, tf115_python_env_windows, tf231_python_env_linux, tf231_python_env_macosx, tf231_python_env_windows]
在上面这一大堆插件中找到自己要下载的插件,这里以kafka为例,从左往右,第一个插件位置为0,则kafka位于第4的位置
通过 String pluginName = plugins.get(4); 看到kafka插件的全部版本
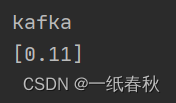
然后利用 pluginDownloader.downloadPlugin(pluginName); 直接下载kafka插件的默认版本
下载完成后,在下载路径下面找到插件
注意:Alink 的新版本中使用了更先进的插件机制:当使用了需要插件的组件、并且能正常访问外网时,会自动下载插件,不需要再使用下文介绍的 PluginDownloader 手动下载了。通常情况下,只需根据需要设置插件下载路径 AlinkGlobalConfiguration.setPluginDir 就可以了。
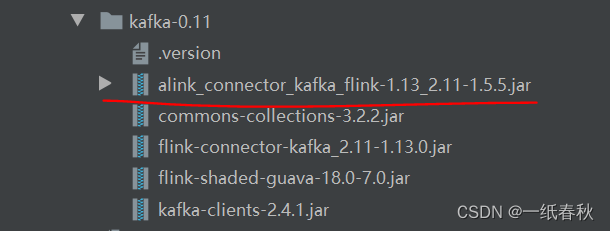
上图是我下载完成的kafka组件,此时只是下载完成,还没有导入项目,运行代码依旧是会报错的
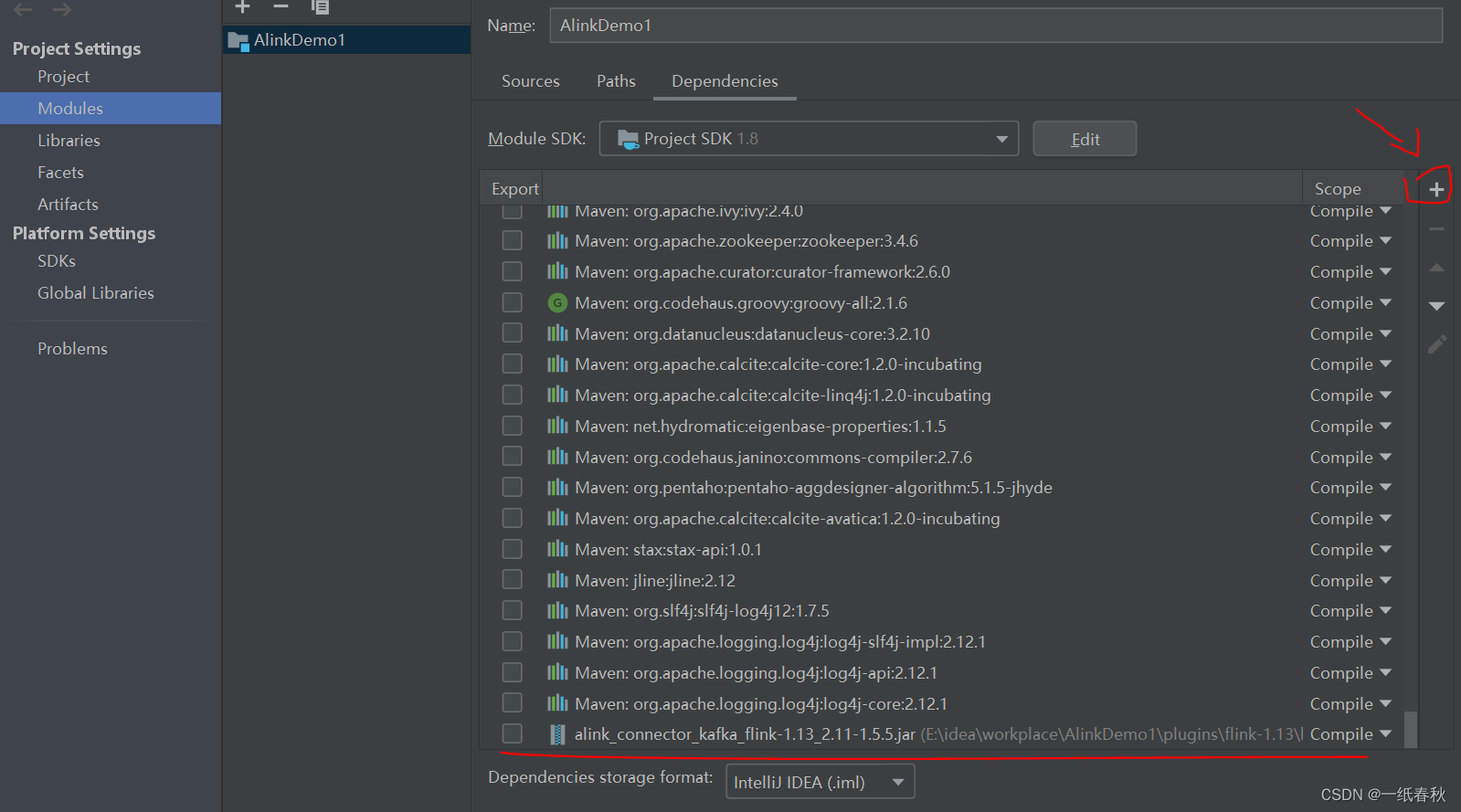
在这里将我划红线标注的Jar包导入项目
之后再运行如下代码
#创建topic
kafka-topics.sh --create --zookeeper master:2181 --replication-factor 1 --partitions 3 --topic iris
package source_sink;
import com.alibaba.alink.common.AlinkGlobalConfiguration;
import com.alibaba.alink.operator.stream.StreamOperator;
import com.alibaba.alink.operator.stream.dataproc.JsonValueStreamOp;
import com.alibaba.alink.operator.stream.sink.KafkaSinkStreamOp;
import com.alibaba.alink.operator.stream.source.CsvSourceStreamOp;
import com.alibaba.alink.operator.stream.source.KafkaSourceStreamOp;
public class demo3 {
public static void main(String[] args) throws Exception {
// 设置本地csv文件路径以及各字段的名字、类型
String filePath = "D:\\data\\iris.csv";
String schema = "s1 double,s2 double,p1 double,p2 double";
// 利用CsvSourceStreamOp读取本地csv文件
//由于 CSV 文件中数据有限,当读取完最后一条时,流式任务会结束
CsvSourceStreamOp csvSource = new CsvSourceStreamOp()
.setFilePath(filePath)
.setSchemaStr(schema)
.setFieldDelimiter(",");
//验证是否读取成功
csvSource.filter("s1 < 4.5").print();
StreamOperator.execute();
// 利用KafkaSinkStreamOp将上面csvSource读取的数据写入kafka中
KafkaSinkStreamOp kafkaSink = new KafkaSinkStreamOp()
.setBootstrapServers("master:9092")
.setDataFormat("json")
.setTopic("iris");
// 通过link串联起两个组件
csvSource.link(kafkaSink);
StreamOperator.execute();
}
}
在kafka中查看数据

写入成功
下面利用Alink读取kafka中的数据
package source_sink;
import com.alibaba.alink.common.AlinkGlobalConfiguration;
import com.alibaba.alink.operator.stream.StreamOperator;
import com.alibaba.alink.operator.stream.dataproc.JsonValueStreamOp;
import com.alibaba.alink.operator.stream.sink.KafkaSinkStreamOp;
import com.alibaba.alink.operator.stream.source.CsvSourceStreamOp;
import com.alibaba.alink.operator.stream.source.KafkaSourceStreamOp;
public class demo3 {
public static void main(String[] args) throws Exception {
// 使用KafkaSourceStreamOp从kafka中获取数据
KafkaSourceStreamOp kafkaSourceStream = new KafkaSourceStreamOp()
.setBootstrapServers("master:9092") // 地址
.setTopic("iris") // 要读取的topic
.setStartupMode("earliest") //从头读取数据,也可以设置为latest,有偏移量则从偏移量处开始消费,没有则从最新处开始消费
.setGroupId("iris1"); // 消费者组id
// 利用上面这种方式获取的每条数据都是 Json 格式的字符串,利用下面这种方式对Json字符串进行格式化
StreamOperator data = kafkaSourceStream
.link(
new JsonValueStreamOp()
.setSelectedCol("message")
.setReservedCols(new String[]{})
.setOutputCols("s1", "s2", "p1", "p2")
.setJsonPath("$.s1", "$.s2", "$.p1", "$.p2")
)
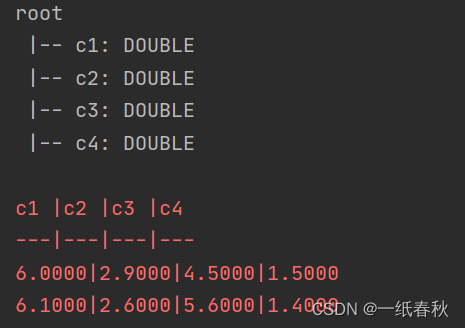
.select("cast(s1 as double) as c1, cast(s2 as double) as c2, cast(p1 as double) as c3, cast(p2 as double) as c4");
// 打印表结构,数据
System.out.println(data.getSchema());
data.print();
StreamOperator.execute();
}
}
JsonValueStreamOp
| 名称 | 中文名称 | 描述 | 类型 | 是否必须? | 默认值 |
|---|---|---|---|---|---|
| jsonPath | Json 路径数组 | 用来指定 Json 抽取的内容。 | String[] | ✓ | |
| skipFailed | 是否跳过错误 | 当遇到抽取值为null 时是否跳过 | boolean | false | |
| selectedCol | 选中的列名 | 计算列对应的列名 | String | ✓ | |
| reservedCols | 算法保留列名 | 算法保留列 | String[] | null | |
| outputCols | 输出结果列列名数组 | 输出结果列列名数组,必选 | String[] | ✓ |
结果为


















 3303
3303

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











