









 本文介绍如何运用bs4库结合requests及正则表达式进行HTML内容遍历与编码,通过实例演示爬取中国大学排名,涵盖HTML遍历方法、格式化及信息提取技巧。
本文介绍如何运用bs4库结合requests及正则表达式进行HTML内容遍历与编码,通过实例演示爬取中国大学排名,涵盖HTML遍历方法、格式化及信息提取技巧。
我们前面提到过bs4及其一些基本用法,但是并没有涉及到真正爬取一个网页我们具体应该如何编写其代码,以及我们如何实现一个真正的例子
我们这篇就作为补充内容(涉及到与requests以及正则表达式的共同使用)
主要内容为基于bs4来进行HTML内容的遍历与编码
参考视频中国大学生慕课网-北京理工大学–python网络爬虫与信息提取视频
HTML遍历方法
HTML基本格式(HTML标签树如下所示)
我们需要遍历其中的结点或所有结点,有如下几种遍历方式
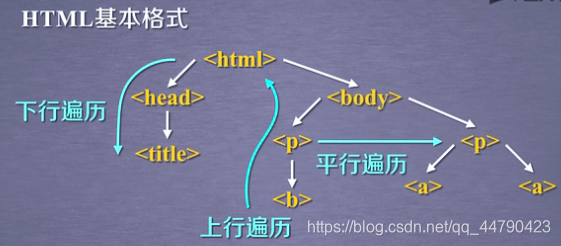
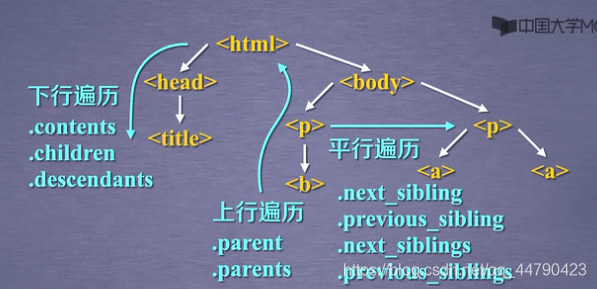
下行遍历
| 属性 | 说明 |
|---|---|
| .contents | 子节点的列表,将tag标签所有的儿子结点存入列表 |
| .children | 子节点的迭代类型,与.contents类似,用于循环遍历儿子结点 |
| .descendants | 子孙结点的迭代类型,包含所有的子孙结点,用于循环遍历 |
e.g.
soup = Beautifulsoup(demo, "html.parser")
for parent in soup.a.parents:
if parent is None:
print(parent)
else:
print(parent.name)
上行遍历
| 属性 | 说明 |
|---|---|
| .parent | 节点的父亲标签 |
| .parents | 节点先辈标签的迭代类型,用于循环遍历i鲜卑结点 |
平行遍历
| 属性 | 说明 |
|---|---|
| .next_sibling | 返回按照HTML文本顺序的下一个平行节点标签 |
| .previous_sibling | 返回按照HTML文本顺序的上一个平行节点标签 |
| .next_siblings | 迭代类型,返回按照HTML文本顺序的后续所有平行结点标签 |
| .previous_siblings | 迭代类型,返回按照HTML文本顺序的前续所有平行结点标签 |
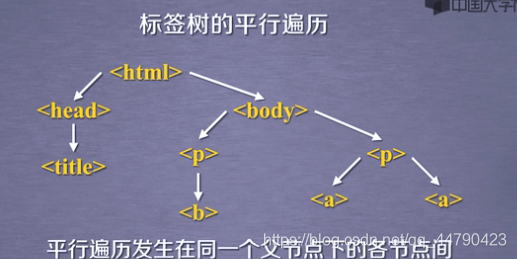
需要遍历所有的利用for循环
e.g.
for sibling in soup.a.next_siblings:
print(sibling)
下图是所有的遍历操作的概括图:
HTML格式化
根据前面我们编写的很多例子,我们可以知道我们打印出来的HTML内容都是比较混乱的,我们很难知道它的结构以及我们河南找到我们期望的内容和标签,故我们需要让HTML有好的显示
即要使用我们的prettify()
e.g.
from bs4 import Beautifulsoup
soup = BeautifulSoup(demo, "html.parser")
print(soup.prettify())
我们可以很清晰的看到HTML标签树的结构
爬取中国大学排名
我们再来一个例子进一步的了解一下bs4的使用
- 下述为一个基本框架:
import requests
from bs4 import BeautifulSoup
import bs4
#获取我们的页面的文本内容
def getHTMLText(url):
return ""
#提取我们期望的信息
def fillUnivList(ulist, html):
return ""
#以一定的形式打印出来
def printUnivList(ulist, num):
print("")
#主函数部分,调用我们的函数即可,得到我们的网址
def main():
uinfo = []
url = "http://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html"
html = getHTMLText(url)
fillUnivList(uinfo, html)
printUnivList(uinfo, 20)
main()
- 获取网页内容模块(这一部分我们在前面经常涉及到,故不再阐述)
def getHTMLText(url):
try:
r = requests.get(url, timeout = 30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
- 提取信息
先在原网站 – 右键查看原网页 — CTRL+F查找清华大学
得到如下界面
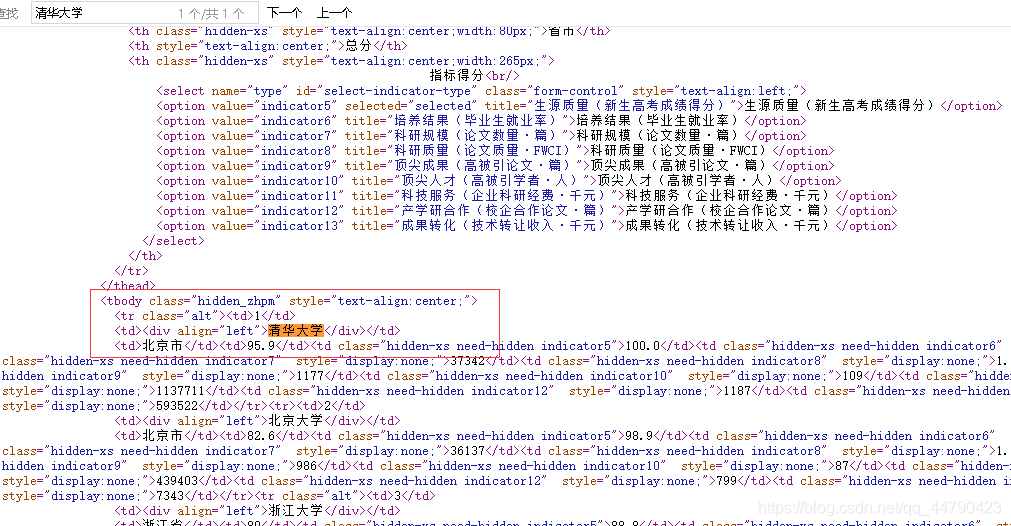
由于我们在原网页中找到我们期望的排名对应的标签,发现是在tbody 中,且由tr包裹,最后每一项又是由td承接,故我们的for循环如下:
首先找到tbody标签,在其内部进行循环,isdistance用来查找与其邻近的tr标签,然后将其三个信息存储在列表中
def fillUnivList(ulist, html):
soup = BeautifulSoup(html, "html.parser")
for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag):
tds = tr('td')
ulist.append([tds[0].string, tds[1].string, tds[2].string])
- 打印模块
def printUnivList(ulist, num):
tplt = "{0:^10}\t{1:{3}^10}\t{2:^10}"
print(tplt.format("排名", "学校", "总分", chr(12288)))
for i in range(num):
u = ulist[i]
print(tplt.format(u[0], u[1], u[2], chr(12288)))
由于我们打印是中文字符,故最后显示的时候会导致一些不规整,不美观,故我们设置了tplt其正则表达式形式,以及chr(12288)来表示中文显示,使其能居中对齐
效果如下:(由于我们在主函数中只选择20项,故只打印前20的排名)
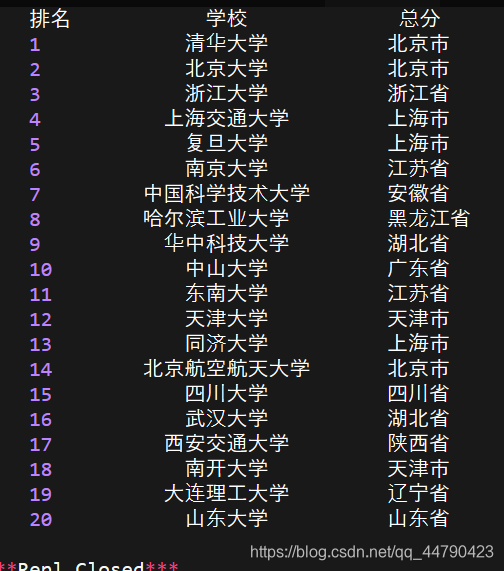
关于我们的bs4的内容补充的学习就到此结束啦!

















 428
428

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









