







 本文以二分类为例,详细介绍了深度学习模型的评估指标,包括准确度Accuracy、精确度Precision、召回率Recall,并讨论了多分类情况下的混淆矩阵及其计算方法。此外,还探讨了ROC曲线的含义及其关键点,帮助理解模型在不同阈值下的性能。
本文以二分类为例,详细介绍了深度学习模型的评估指标,包括准确度Accuracy、精确度Precision、召回率Recall,并讨论了多分类情况下的混淆矩阵及其计算方法。此外,还探讨了ROC曲线的含义及其关键点,帮助理解模型在不同阈值下的性能。
深度学习模型评估指标 Accuracy,Precision,Recall,ROC曲线
以二分类为例,进行说明:

注:
- 判别是否为正例只需要设一个概率阈值T,预测概率大于阈值T的为正类,小于阈值T的为负类,默认就是0.5。
- 如果减小阀值T,更多的样本会被识别为正类,这样可以提高正类的召回率,但同时也会带来更多的负类被错分为正类;
- 如果增加阈值T,则正类的召回率降低,精度增加。如果是多类,比如ImageNet1000分类比赛中的1000类,预测类别就是预测概率最大的那一类。
常用的几种评估指标:
1. 准确度: Accuracy = (TP + TN) / (TP + FN + FP + TN)
注:Top_1 Accuracy和Top_5 Accuracy,Top_1 Accuracy就是计算的Accuracy。而Top_5 Accuracy是给出概率最大的5个预测类别,只要包含了真实的类别,则判定预测正确。
2. 精确度:Precision = TP / (TP + FP)
3. 召回率:Recall = TP / (TP + FN)
多分类情况
4. 混淆矩阵
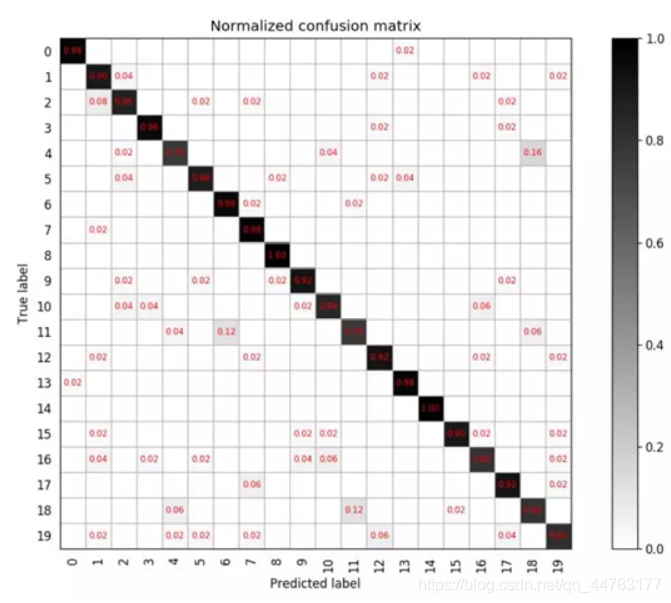
如果对于每一类,若想知道类别之间相互误分的情况,查看是否有特定的类别之间相互混淆,就可以用混淆矩阵画出分类的详细预测结果。对于包含多个类别的任务,混淆矩阵很清晰的反映出各类别之间的错分概率,如下图:
注: 横坐标表示预测分类,纵坐标表示标签分类,其中(i,j)表示第i类目标被分为第j类的概率,对角线的值越大越好。
代码实现:
实际图片的标签值labels, 预测的分类值predicted,二者转换为具体的标签值(而不是onehot值),矩阵具体的大小为:[number_total_pictures, 1], 然后将二者拼接为[number_total_pictures*2, 1], 得到的这个矩阵的每一行都代表一个(i,j)值,然后进行统计即可。代码如下:
def Confusion_mxtrix(labels, predicted, num_classes):
"""
混淆矩阵的函数定义
Args:
labels: [number_total_pictures,1]
predicted: [number_total_pictures,1]
num_classes: 分类数目
Returns: Confusion_matrix
"""
Cmatrixs = torch.zeros((num_classes,num_classes))
stacked = torch.stack((labels, predicted), dim=1)
for s in stacked:
a, b = s.tolist()
Cmatrixs[a, b] = Cmatrixs[a, b] + 1
return Cmatrixs
def plot_confusion_matrix(cm, savename, title='Confusion Matrix'):
classes = ('airplane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
plt.figure(figsize=(12, 8), dpi=100)
np.set_printoptions(precision=2)
# 在混淆矩阵中每格的概率值
ind_array = np.arange(len(classes))
x, y = np.meshgrid(ind_array, ind_array)
for x_val, y_val in zip(x.flatten(), y.flatten()):
c = cm[y_val][x_val]
if c > 0.001:
plt.text(x_val, y_val, "%0.2f" % (c,), color='red', fontsize=15, va='center', ha='center')
plt.imshow(cm, interpolation='nearest', cmap=plt.cm.binary)
plt.title(title)
plt.colorbar()
xlocations = np.array(range(len(classes)))
plt.xticks(xlocations, classes, rotation 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









