






有了符号型的基础,数值型就快多了。
数值型与符号型的不同点就是数值并不是有限集合,某个数值精确落到某个点上的概率基本为零,但是落到某个区间的概率就可以计算了。比如要在某个学校里面找到一位身高为170.0的同学的概率为0,但是要找到一位身高在169-171之间的同学的概率就不是零了。
- 概率密度函数
p
(
x
)
p(x)
p(x)
p ( x ) p(x) p(x)= p d x \frac{p}{dx} dxp
其中 p p p为概率, d x dx dx为区间长度,很显然移过去积个分概率就算出来了,由于我们的目的是比较大小,所以完全没有必要算出来这个 p p p,只需要算出 p ( x ) p(x) p(x),换句话说只要有每个属性的概率密度函数就行了。 - 正态分布
我们假设每个属性都服从正态分布,这样概率密度函数的求解就变简单了
正态分布函数:
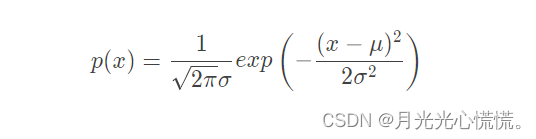
观察公式易得只用算出每个属性的期望与方差,这个属性的正态分度函数就可以写出来了。 - 最终的计算表达式:
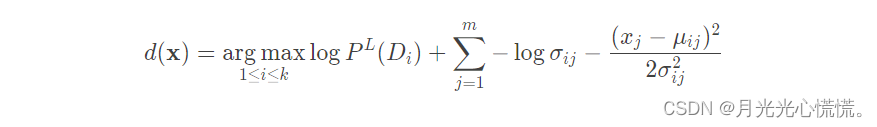
只需要在原来的代码上改一下就行了
public class NaiveBayesV2 {
/**
* ************************
* An inner class to store parameters.
* ************************
*/
private class GaussianParamters {
double mu;
double sigma;
public GaussianParamters(double paraMu, double paraSigma) {
mu = paraMu;
sigma = paraSigma;
}// Of the constructor
public String toString() {
return "(" + mu + ", " + sigma + ")";
}// Of toString
}// Of GaussianParamters
内部类作用就是记录一下每个属性的期望与方差
public void calculateGausssianParameters() {
gaussianParameters = new GaussianParamters[numClasses][numConditions];
double[] tempValuesArray = new double[numInstances];
int tempNumValues = 0;
double tempSum = 0;
for (int i = 0; i < numClasses; i++) {
for (int j = 0; j < numConditions; j++) {
tempSum = 0;
tempNumValues = 0;
for (int k = 0; k < numInstances; k++) {
if ((int) dataset.instance(k).classValue() != i) {
continue;
} // Of if
tempValuesArray[tempNumValues] = dataset.instance(k).value(j);
tempSum += tempValuesArray[tempNumValues];
tempNumValues++;
} // Of for k
double tempMu = tempSum / tempNumValues;
double tempSigma = 0;
for (int k = 0; k < tempNumValues; k++) {
tempSigma += (tempValuesArray[k] - tempMu) * (tempValuesArray[k] - tempMu);
} // Of for k
tempSigma /= tempNumValues;
tempSigma = Math.sqrt(tempSigma);
gaussianParameters[i][j] = new GaussianParamters(tempMu, tempSigma);
} // Of for j
} // Of for i
这个是今天的核心代码,也是唯一改变的地方
if ((int) dataset.instance(k).classValue() != i) 只有是当前类别的才能继续,否则continue,过滤数据。
tempValuesArray[tempNumValues] = dataset.instance(k).value(j)把当前对象的当前属性的数据值存放到数组中
然后按部就班算平均值,算方差
gaussianParameters[i][j] = new GaussianParamters(tempMu, tempSigma);
这个二维数组里面存放的是内部类对象,下标i,j一个表示类别,一个表示属性。
public int classifyNumerical(Instance paraInstance) {
double tempBiggest = -10000;
int resultBestIndex = 0;
for (int i = 0; i < numClasses; i++) {
double tempPseudoProbability = Math.log(classDistributionLaplacian[i]);
for (int j = 0; j < numConditions; j++) {
double tempAttributeValue = paraInstance.value(j);
double tempSigma = gaussianParameters[i][j].sigma;
double tempMu = gaussianParameters[i][j].mu;
tempPseudoProbability += -Math.log(tempSigma)
- (tempAttributeValue - tempMu) * (tempAttributeValue - tempMu) / (2 * tempSigma * tempSigma);
} // Of for j
if (tempBiggest < tempPseudoProbability) {
tempBiggest = tempPseudoProbability;
resultBestIndex = i;
} // Of if
} // Of for i
return resultBestIndex;
}// Of classifyNumerical
这段代码就是找到概率最大的那个类别,套公式算就行了。基本的流程与符号型的一致。
运行结果:

总结:数值型的Naive Bayes与符号型的大体流程是一样的,只是数值型在求后半部分的概率时不能像符号型那么简单,需要用到一点概率论的知识来处理,然后就是计算的时候没有必要真的把公式里的每一个给算出来,只要最终结果的大小关系保持一致就可以

















 1030
1030

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









