





数据仓库的输入数据通常包括:业务数据、用户行为数据和爬虫数据等
业务数据:就是各行业在处理事务过程中产生的数据。比如用户在电商网站中登录、下单、支付等过程中,需要和网站后台数据库进行增删改查交互,产生的数据就是业务数据。业务数据通常存储在MySQL、Oracle等数据库中。
用户行为数据:用户在使用产品过程中,通过埋点收集与客户端产品交互过程中产生的数据,并发往日志服务器进行保存。比如页面浏览、点击、停留、评论、点赞、收藏等。用户行为数据通常存储在日志文件中
爬虫数据:通常事通过技术手段获取其他公司网站的数据。不建议同学们这样去做。
项目需求
1.用户行为数据采集平台搭建
2.业务数据采集搭建
3.数据仓库维度建模
4.分析、设备、会员、商品、地区、活动等电商核心主题,统计的报表指标近100个
5.采用即席查询工具,随时进行指标分析
6.采取集群性能进行监控、发生异常需要报警
7.元数据管理
8.质量监控
9.权限管理
用户行为数据
我们要收集和分析的数据主要包括页面数据、事件数据、曝光数据、启动数据和错误数据。
页面:页面数据主要记录一个页面的用户访问情况,包括访问时间、停留时间、页面路径等信息。
事件:事件数据主要记录应用内一个具体操作行为,包括操作类型、操作对象、操作对象描述等信息。
曝光:曝光数据主要记录页面所曝光的内容,包括曝光对象,曝光类型等信息。
启动:启动数据记录应用的启动信息。
错误:错误数据记录应用使用过程中的错误信息,包括错误编号及错误信息。
我们的日志结构大致可分为两类,一是普通页面埋点日志,二是启动日志。
普通页面每条日志包含了,当前页面的页面信息,所有事件(动作)、所有曝光信息以及错误信息。除此之外,还包含了一系列公共信息,包括设备信息,地理位置,应用信息等,即下边的common字段。
启动日志结构相对简单,主要包含公共信息,启动信息和错误信息。
开启数据均衡命令
节点间数据均衡
start-balancer.sh -threshold 10
对于参数10,代表的是集群中各个节点的磁盘空间利用率相差不超过10%,可根据实际情况进行调整。
注意:于HDFS需要启动单独的Rebalance Server来执行Rebalance操作,所以尽量不要在NameNode上执行start-balancer.sh,而是找一台比较空闲的机器。
磁盘间数据均衡
hdfs diskbalancer -plan hadoop103
hdfs diskbalancer -execute hadoop103.plan.json
hdfs diskbalancer -query hadoop103
hdfs diskbalancer -cancel hadoop103.plan.json
支持lzo压缩模式
lzo创建索引
LZO压缩文件的可切片特性依赖于其索引,故我们需要手动为LZO压缩文件创建索引。若无索引,则LZO文件的切片只有一个。
flume时间拦截器
由于Flume默认会用Linux系统时间,作为输出到HDFS路径的时间。如果数据是23:59分产生的。Flume消费Kafka里面的数据时,有可能已经是第二天了,那么这部门数据会被发往第二天的HDFS路径。我们希望的是根据日志里面的实际时间,发往HDFS的路径,所以下面拦截器作用是获取日志中的实际时间。
解决的思路:拦截json日志,通过fastjson框架解析json,获取实际时间ts。将获取的ts时间写入拦截器header头,header的key必须是timestamp,因为Flume框架会根据这个key的值识别为时间,写入到HDFS。
业务数据
以下为本电商数仓系统涉及到的业务数据表结构关系。这34个表以订单表、用户表、SKU商品表、活动表和优惠券表为中心,延伸出了优惠券领用表、支付流水表、活动订单表、订单详情表、订单状态表、商品评论表、编码字典表退单表、SPU商品表等,用户表提供用户的详细信息,支付流水表提供该订单的支付详情,订单详情表提供订单的商品数量等情况,商品表给订单详情表提供商品的详细信息。本次讲解以此34个表为例,实际项目中,业务数据库中表格远远不止这些。
同步策略


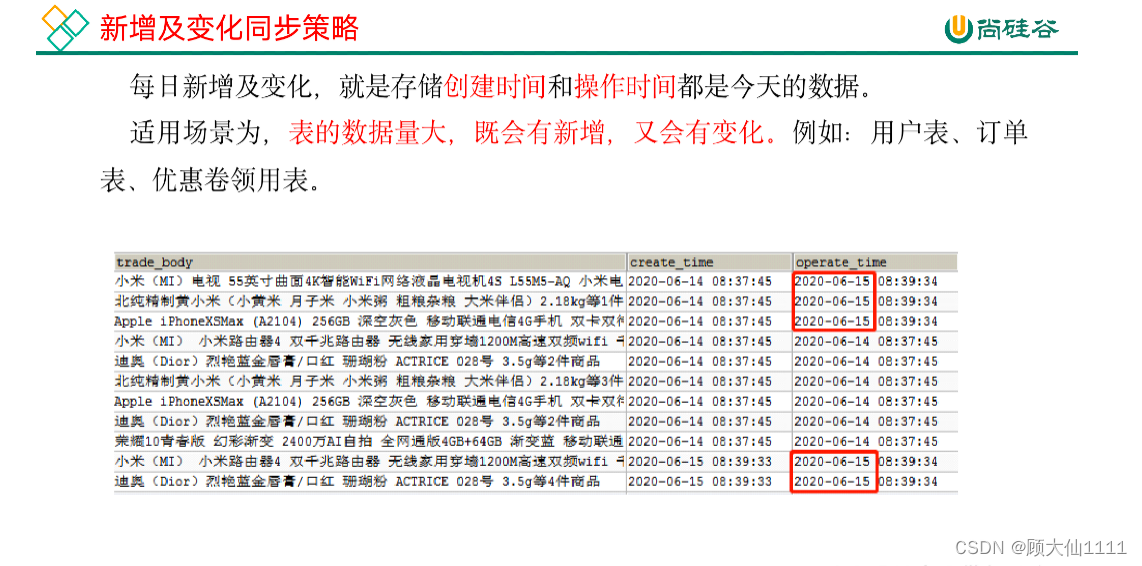
某些特殊的表,可不必遵循上述同步策略。例如某些不会发生变化的表(地区表,省份表,民族表)可以只存一份固定值。
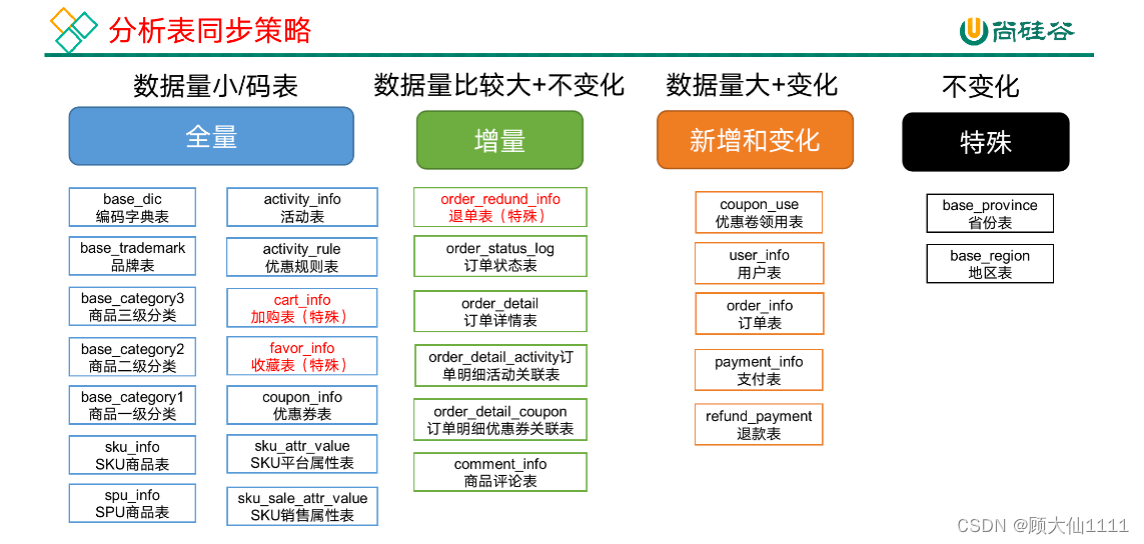
mysql to hdfs
Hive中的Null在底层是以“\N”来存储,而MySQL中的Null在底层就是Null,为了保证数据两端的一致性。在导出数据时采用--input-null-string和--input-null-non-string两个参数。导入数据时采用--null-string和--null-non-string。

关系建模和维度建模是两种数据仓库的建模技术。
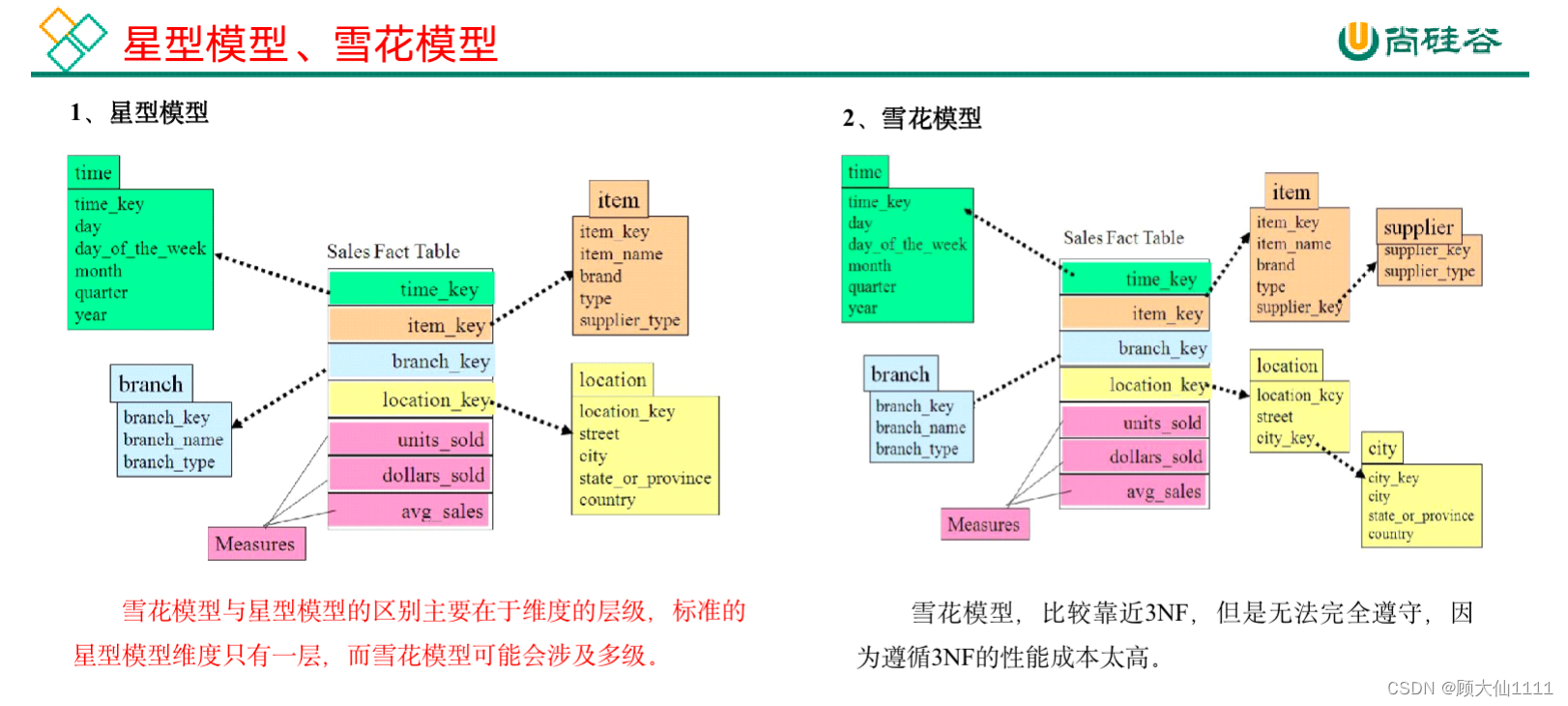
关系建模将复杂的数据抽象为两个概念——实体和关系,并使用规范化的方式表示出来。关系模型如图所示,从图中可以看出,较为松散、零碎,物理表数量多。
关系模型严格遵循第三范式(3NF),数据冗余程度低,数据的一致性容易得到保证。由于数据分布于众多的表中,查询会相对复杂,在大数据的场景下,查询效率相对较低。
维度模型如图所示,从图中可以看出,模型相对清晰、简洁。
维度模型以数据分析作为出发点,不遵循三范式,故数据存在一定的冗余。维度模型面向业务,将业务用事实表和维度表呈现出来。表结构简单,故查询简单,查询效率较高。



A完全依赖B 反过来 即 B决定A
维度表:一般是对事实的描述信息。每一张维表对应现实世界中的一个对象或者概念。 例如:用户、商品、日期、地区等。
维表的特征:
- 维表的范围很宽(具有多个属性、列比较多)
- 跟事实表相比,行数相对较小:通常< 10万条
- 内容相对固定:编码表
事实表中的每行数据代表一个业务事件(下单、支付、退款、评价等)。“事实”这个术语表示的是业务事件的度量值(可统计次数、个数、金额等),例如,2020年5月21日,宋宋老师在京东花了250块钱买了一瓶海狗人参丸。维度表:时间、用户、商品、商家。事实表:250块钱、一瓶
每一个事实表的行包括:具有可加性的数值型的度量值、与维表相连接的外键,通常具有两个和两个以上的外键。
事实表的特征:
- 非常的大
- 内容相对的窄:列数较少(主要是外键id和度量值)
- 经常发生变化,每天会新增加很多。
1)事务型事实表
以每个事务或事件为单位,例如一个销售订单记录,一笔支付记录等,作为事实表里的一行数据。一旦事务被提交,事实表数据被插入,数据就不再进行更改,其更新方式为增量更新。
2)周期型快照事实表
周期型快照事实表中不会保留所有数据,只保留固定时间间隔的数据,例如每天或者每月的销售额,或每月的账户余额等。
例如购物车,有加减商品,随时都有可能变化,但是我们更关心每天结束时这里面有多少商品,方便我们后期统计分析。
3)累积型快照事实表
累计快照事实表用于跟踪业务事实的变化。例如,数据仓库中可能需要累积或者存储订单从下订单开始,到订单商品被打包、运输、和签收的各个业务阶段的时间点数据来跟踪订单声明周期的进展情况。当这个业务过程进行时,事实表的记录也要不断更新。
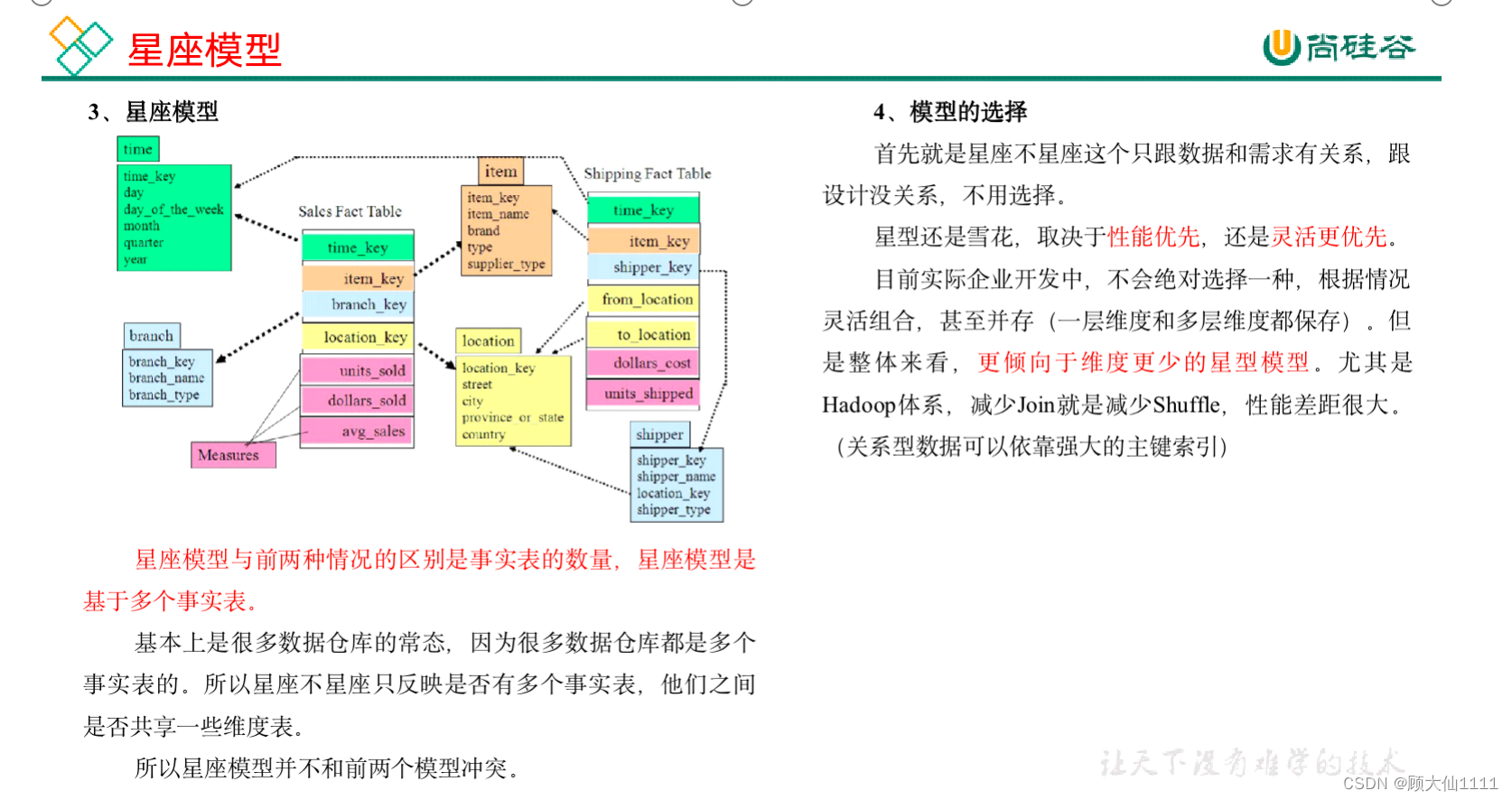
在维度建模的基础上又分为三种模型:星型模型、雪花模型、星座模型。
数仓分层
ods层(原始数据层):不需要建模,存放原始数据
针对HDFS上的用户行为数据和业务数据,我们如何规划处理?
(1)保持数据原貌不做任何修改,起到备份数据的作用。
(2)数据采用压缩,减少磁盘存储空间(例如:原始数据100G,可以压缩到10G左右)
(3)创建分区表,防止后续的全表扫描
dim和dwd层 数据明细层和维度层
DIM层DWD层需构建维度模型,一般采用星型模型,呈现的状态一般为星座模型。
维度建模一般按照以下四个步骤:
选择业务过程→声明粒度→确认维度→确认事实
声明粒度
数据粒度指数据仓库的数据中保存数据的细化程度或综合程度的级别。
声明粒度意味着精确定义事实表中的一行数据表示什么,应该尽可能选择最小粒度,以此来应各种各样的需求。
典型的粒度声明如下:
订单事实表中一行数据表示的是一个订单中的一个商品项。
支付事实表中一行数据表示的是一个支付记录。
确定维度
维度的主要作用是描述业务是事实,主要表示的是“谁,何处,何时”等信息。
确定维度的原则是:后续需求中是否要分析相关维度的指标。例如,需要统计,什么时间下的订单多,哪个地区下的订单多,哪个用户下的订单多。需要确定的维度就包括:时间维度、地区维度、用户维度。
确定事实
此处的“事实”一词,指的是业务中的度量值(次数、个数、件数、金额,可以进行累加),例如订单金额、下单次数等。
在DWD层,以业务过程为建模驱动,基于每个具体业务过程的特点,构建最细粒度的明细层事实表。事实表可做适当的宽表化处理。
DWS层与DWT层(基于业务需求,与维度建模无关)(数据服务层和数据主题层)
DWS层和DWT层统称宽表层,这两层的设计思想大致相同,通过以下案例进行阐述。
1)问题引出:两个需求,统计每个省份订单的个数、统计每个省份订单的总金额
2)处理办法:都是将省份表和订单表进行join,group by省份,然后计算。同样数据被计算了两次,实际上类似的场景还会更多。
那怎么设计能避免重复计算呢?
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1515
1515

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









