






object和component
常见的object
- item、seq、config都是object。
- reg_item、reg相关的都是object。
- uvm_phase是object
常见conponent
- driver、monitor、sequencer、scoreboard、reference model、agent、env等树结构,有parent
object的函数
- clone=new+copy
- copy
component的树形结构
通过例化conponent指定的parent实现父节点添加
通过维护m_children实现子节点添加
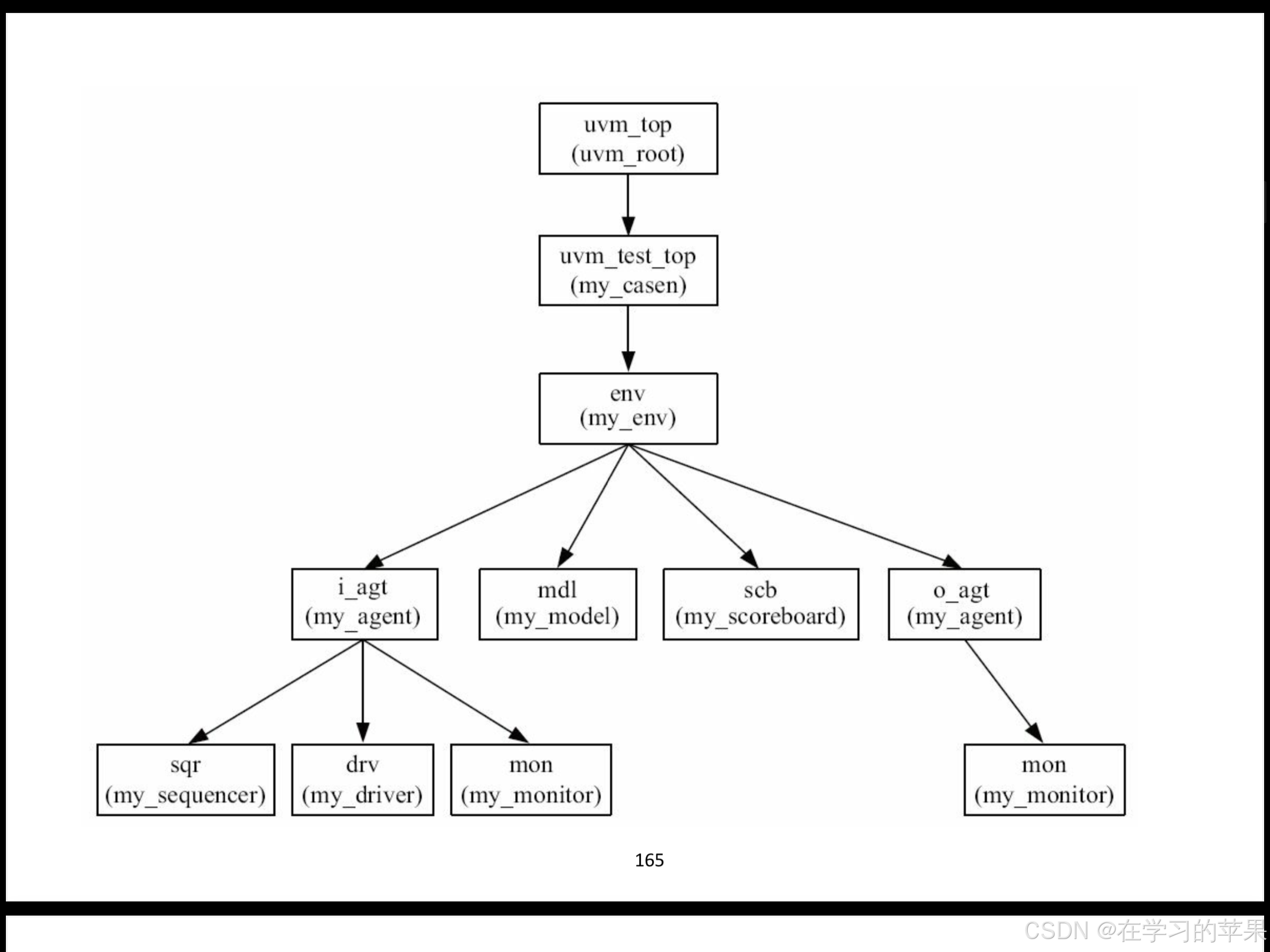
若指定parent为null,则默认指定为uvm_top,或者:uvm_root::get()
如何获取层次的关系?
get_parent、get_children获取所有
get_first_child、get_next_child
field automation
提供一下函数:copy、compare、pack_bytes、unpack_bytes
对于crc的error,为1直接使用随机值,否则使用真实计算值,如何利用此机制?
因为error是我们定义的,这个不需要packet打包发送,所以我们在加入field automation时
`uvm_field_int(crc_err, UVM_ALL_ON | UVM_NOPACK)即可不打包
ALL_ON表示打开copy、compare、print、record、pack功能
对于帧中分类型可有可无的字段怎么处理?

打印信息
typedef enum {
UVM_NONE = 0,
UVM_LOW = 100,
UVM_MEDIUM = 200,
UVM_HIGH = 300,
UVM_FULL = 400,
UVM_DEBUG = 500
} uvm_verbosity;
env.i_agt.drv.set_report_verbosity_level(UVM_HIGH);//设置优先级
应该在connect phase之后使用
env.i_agt.set_report_verbosity_level_hier(UVM_HIGH);//设置其及子类优先级
优先级的重载
env.i_agt.drv.set_report_severity_override(UVM_WARNING, UVM_ERROR);
把warning变成error
env.i_agt.drv.set_report_severity_id_override(UVM_WARNING, "my_driver", UVM_ERROR);
也可以针对某一component使用
优先级的计数
set_report_max_quit_count(5);
5个error退出
set_report_max_quit_count(5);
env.i_agt.drv.set_report_severity_action(UVM_WARNING, UVM_DISPLAY|UVM_COUNT);
可以把warning也加入计数
config db
用法:
- 传递virtual interface到环境中;
- 配置单一变量值,例如int、string、enum等;
- 传递配置对象(config_object)到环境;
uvm_config_db #(type)::get( //type类型可以是int、string等类型,也可以是接口interface、对象object等类型
uvm_component context, //组件中的目标,常设置为this(针对类),或者null(非类,如module模块)
string instance_name, //路径索引,相对于第一个参数的相对路径
string field_name,
inout T variable //2. **底层获取变量值,即variable = field_name,**如果不设置,变量保持原始值
);
uvm_config_db #(type)::set( //set()与get()中的类型type应该保持一致
uvm_component context, //组件中的目标,常设置为this(针对类),或者null(非类,如module模块)
string instance_name, //路径索引(set操作的目标组件实例名)
string field_name,
T value //1. **顶层设置变量值,即field_name = value**
);
- 在使用set()/get()方法时,传递的参数类型应当保持一致。对于uvm_object等实例的传递,如果get类型和set类型不一致,应当首先通过$cast()完成类型转换,再对类型转换后的对象进行操作。
- set()方法较高层组件的配置会覆盖较低层的配置;但是如果是同一层次组件对该变量进行配置时,应当遵循后面的配置覆盖前面的配置。(在树中的位置)
注意⚠️
- 接口传递应发生在run_test()之前。这保证了在进入build_phase之前,virtual interface已经被传递到uvm_config_db中。
- 用户应当把interface与virtual interface区分开来,在传递过程中的类型应当为virtual interface,即实际接口的句柄。
function void build_phase(uvm_phase phase);
if(!uvm_config_db #(virtual intf1)::get(this,"","vif",vif)) begin //**3. 获取配置接口vif = intf**
`uvm_error("GETVIF","no virtual interface is assigned")
end
`uvm_info("SETVAL",$sformatf("vif.enable is %b before set",vif.enable),UVM_LOW)
vif.enable = 1;
`uvm_info("SETVAL",$sformatf("vif.enable is %b after set",vif.enable),UVM_LOW)
endfunction
其中关于config object 对象传递
我们可以整合各个组件中的变量,将其放置在一个uvm_object中,再对中心化的配置对象进行传递,将有利于整体环境的修改维护,体改代码的复用性
class config1 extends uvm_object;
//**1. 创建一个配置类,将需要配置的变量放于其中**
`uvm_object_utils(config1)
int val1 = 1;
int str1 = "null";
...
endclass
class comp1 extends uvm_component; //组件
`uvm_component_utils(comp1)
config1 cfg ; //声明配置类句柄
...
function void build_phase(uvm_phase phase);
uvm_object tmp; //声明类句柄
uvm_config_db #(uvm_object)::get(this,"","cfg",tmp); //**3. 获取变量配置**
void`($cast(cfg,tmp)); //类型转韩,将传到tmp中的值赋给cfg
`uvm_info("SETVAL",$sformatf("cfg.val1 is %d after get",cfg.val1),UVM_LOW)
`uvm_info("SETVAL",$sformatf("cfg.str1 is %d after get",cfg.str1),UVM_LOW)
endfunction
endclass
class test1 extends uvm_test; //测试用例层, 启动配置
`uvm_component_utils(test1)
comp1 c1, c2;
config1 cfg1, cfg2;
...
function void build_phase(uvm_phase phase);
cfg1 = config1::type_id::create("cfg1");
cfg2 = config1::type_id::create("cfg2");
c1 = comp1::type_id::create("c1");
c2 = comp1::type_id::create("c2"); //创建对象
cfg1.val1 = 30;
cfg1.str1 = "c1";
cfg2.val1 = 50;
cfg2.str1 = "c2";
uvm_config_db #(uvm_object)::set(this,"c1","cfg",cfg1); //**2. 启动变量配置**
uvm_config_db #(uvm_object)::set(this,"c2","cfg",cfg2); //启动变量配置
endfunction
endclass
省略get语句
- 使用uvm_field注册的变量;
- 类必须用utils注册
- 并且在build_phase中调用super.build_phase();
可以省略get语句
检查config_db使用情况
check_config_usage();
一般在connect phase用,因为要在build之后
TLM
uvm_blocking_put_port#(T);
uvm_nonblocking_put_port#(T);
uvm_put_port#(T);
uvm_get_port#(T);
uvm_peek_port#(T);
uvm_get_peek_port#(T);//get加上peek
uvm_transport_port#(REQ, RSP);
优先级:port≥export≥import,高优先级调用低的
一般export、import放一块,然后内部连接,import相当于存储item
且作为被调用方要实现put函数。
一般有如下规律
blocking---put
nonblocking--try put + can put
put--三个都
get port ---按上述规律get
peek port ---按上述规律peek
blocking transport--transport
nonblocking transport--nbtransport
transport--都
nonblocking要定义函数、blocking定义task
端口连接规则
- port-port
- port-import
- export-import
- export-export:此时port可连接export1,然后export1连接export2,export2-import
analysis端口
- a_port、a_export对a_import为一对多
- 无阻塞概念--广播
- 仅需要实现write操作
一个imp接受多个ap怎么实现不同的write?
使用
`uvm_analysis_imp_decl(_monitor);
uvm_analysis_imp_monitor#(my_transaction, my_scoreboard) monitor_imp;
write_monitor(my_transaction tr);
即可实现不同的定义
如何让sb想get port一样主动接受?
uvm_analysis_fifo:充当桥梁。包含两个import,连接ap和get port
- 在sb中实现get_port
uvm_blocking_get_port #(my_transaction) exp_port;
uvm_blocking_get_port #(my_transaction) act_port;
- env中实现如下fifo并连接analysis_port---fifo.export--port
uvm_tlm_analysis_fifo #(my_transaction) agt_scb_fifo;
uvm_tlm_analysis_fifo #(my_transaction) agt_mdl_fifo;
uvm_tlm_analysis_fifo #(my_transaction) mdl_scb_fifo;
- 可以不实现write
fifo中的peek端口原理
复制一个item并发送
phase
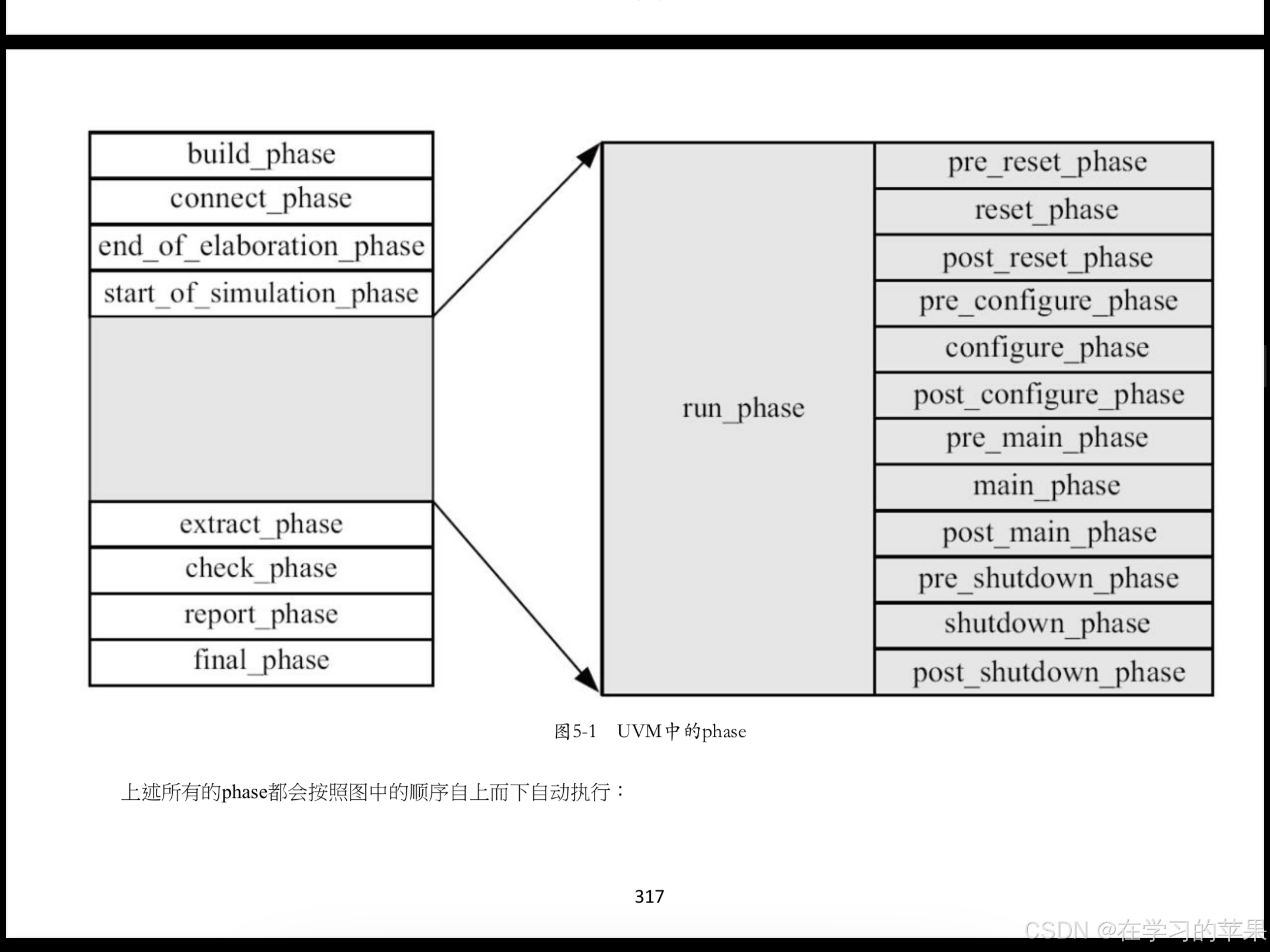
白色:function phase、灰色:task phase 消耗仿真时间
灰色的左右是两个线程,线程内顺序执行
phase执行顺序
build自上而下,connect等其他function phase自下而上
而task phase如下
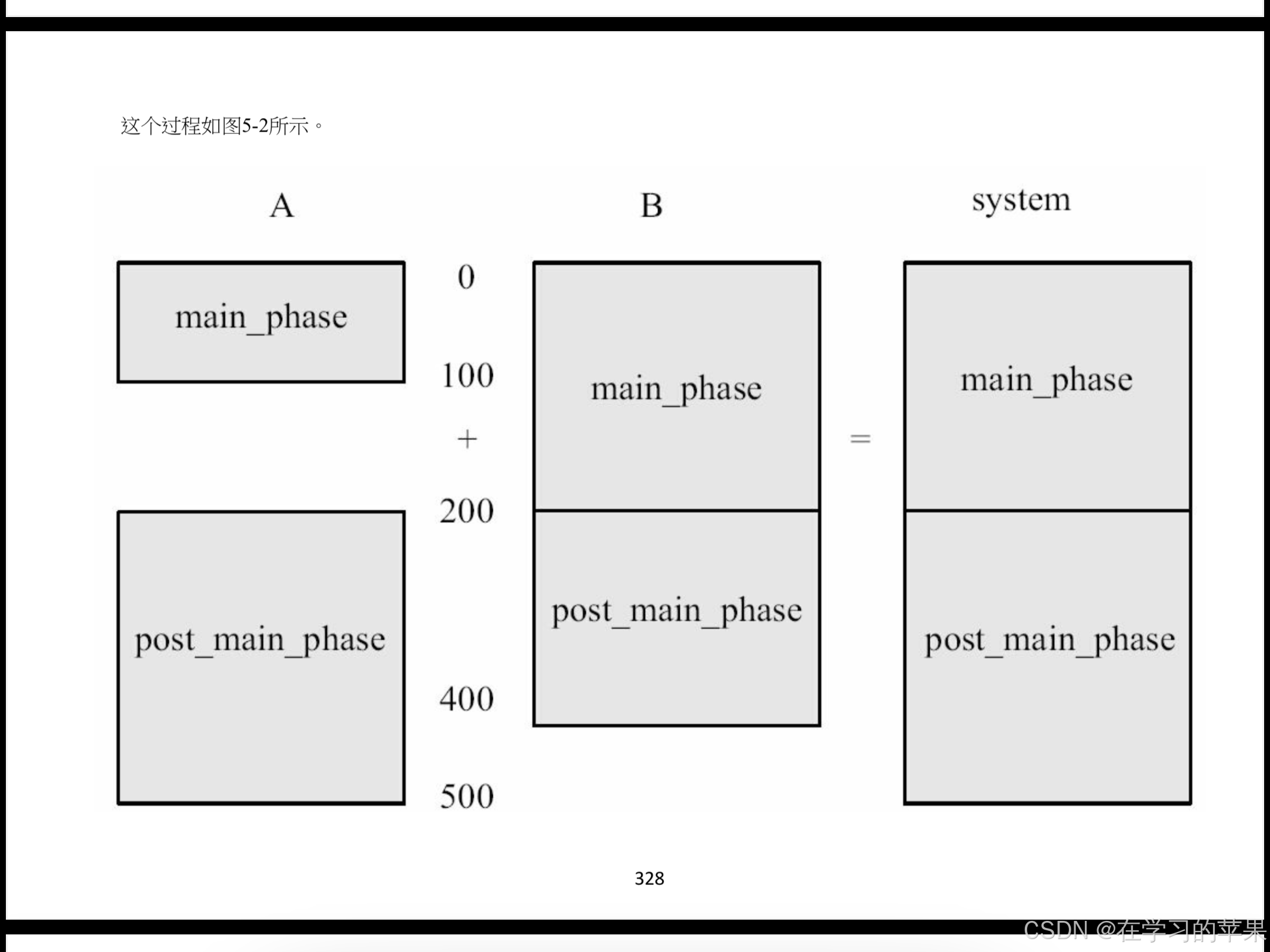
UVM中采用深度优先原则,对于scoreboard及driver的build_phase的执行顺序,i_agt实例化时名字为“i_agt”, 而scb为“scb”,那么i_agt的build_phase先执行,在执行完毕后,接下来执行driver、monitor及sequencer的build_phase。当全部执行完 毕后再执行scoreboard 的build_phase
如果i_agt实例化时是bbb,而scb为aaa,则会先执行scb的build_phase,再执行i_agt的build_phase,接下来是driver、 monitor及sequencer的build_phase。
super.phase
唯一作用就是build phase中省略get,其他phase都可以省略
phase如何跳转
如在main_phase中,监测到复位直接跳转到reset phase
@(negedge vif.rst_n);
phase.jump(uvm_reset_phase::get());在跳转前,scoreboard的expect_queue中的数据应该清空,同时要容忍跳转后 DUT 可能输出一些异常数据
objection
在右边任意phase raise objection后,左边都算启动。即使右边关闭也会启动左边。
phase.raise_objection(this);
是对phase操作,所以右边的所有phase在例化时都会传参task main_phase(uvm_phase phase);
在哪控制objection?
因为phase是可以操控uvm树的全局phase,一般情况下只在sequence中控制objection
在sequence中提起sequencer的objection,当sequence完成后,再撤销此objection
何为drain time
phase.phase_done.set_drain_time(this, 200);
domain
默认平台的component都在一个common_domain里面。加入DUT是两个独立的部分,分别配置。要用domain把两块时钟域隔开,之后两个时钟域内的各个动态运行(run_time)的phase就可以不必同步。
注意,这里domain只能 隔离run-time的phase,对于其他phase,其实还是同步的,即两个domain的run_phase依然是同步的,其他的function phase也是同步 的。
如何将component放到domain中?
- uvm_domain new_domain;定义新domain
- 例化new_domain = new("new_domain")-------构造函数中
- set_domain(new_domain,1);-------connect_phase。1表示吧子孙全加入new_domain
多domain的跳转
仅跳转当前domain
同步
在sv中,同步机制有event、semaphore、mailbox
SV复习(六)线程间通信_sv semaphore-优快云博客
sv事件
等待事件:@x(边沿敏感)。 wait(e.triggered)电平敏感
触发事件:->x
sv。semaphore
semaphore a = new(3);
a.get(1)
a.put(1)
tryget. tryput
mail box
可以看做一个FIFO
mailbox #(Transaction) a = new(4)或者new()「无限大」;
a.get(1)
a.put(1)
tryget. tryput
在uvm中同步还需要解决组件之间的线程同步
uvm event
通过trigger()触发,wait trigger()等待触发,reset()重置事件。
特点如下:
- 可以通过
trigger(T data=null)的可选参数传入数据对象、 - 可以通过
add_callback(uvm_event_callback cb,bit append=1)函数来添加回调函数。其中uvm_event_callback定义内部具有pre_trigger(uvm_event e, uvm_object data=null)和post_trigger(uvm_event e, uvm_object data=null)函数 - 可以通过
get_num_waiters()来获取等待它的进程数目 - e1 = uvm_event_pool::get_global("e1"); uvm_event_pool作为全局资源生成event分发给各个组件的句柄。
- 组件之间的常规数据流向是通过TLM通信方法实现的,比如sequence与driver之间,或者monitor与scoreboard之间。
- 有些时候,数据传输是偶然触发的,并且需要立即响应,这个时候需要uvm_event。
- uvm_event同时也解决了一个重要问题,那就是在一些uvm_object和uvm_component对象之间如果要发生同步,但是无法通过TLM完成数据传输,因为TLM传输必须是在组件和组件之间进行的。
- 如果要在sequence与sequence之间进行同步,或者sequence与driver之间进行同步,就可以使用uvm_event来实现。
uvm barrier
对多个组件进行同步协调,同时为了解决组件独立运作的封闭性需要,也定义了新的类uvm_barrier_pool来全局管理这些uvm_barrier对象。
uvm_barrier可以设置一定的等待阈值(threshold),当有不少于该阈值的进程在等待该对象时,才会触发该事件,同时激活所有正在等待的进程,使其可以继续进行。
- b1 = uvm_barrier_pool::get_global("b1");依旧是通过pool来管理
- 使用方法为在cmp的run phase 使用b1.wait_for();然后在env中设置时间b1.set_threshold(3);
uvm callback
如果通过类的继承来满足父类函数重载,又无法在该包环境中用新的子类替换原来的父类,那么此时可以使用UVM的覆盖机制。
但是覆盖override依旧需要重写函数,当我们不想重写整个函数,可以通过callback机制重写其中特定的n行代码。
我们只需要在n行代码前后添加cb函数
关于顺序和继承性的实现,UVM是通过两个相关类uvm_callback_iter和uvm_callbacks #(T,CB)来实现的
class edata extends uvm_object;
int data;
`uvm_object_utils(edata)
...
endclass
//
class cb1 extends uvm_callback;
`uvm_object_utils(cb1)
...
virtual function void do_trans(edata d);
d.data = 200;
`uvm_info("CB", $sformatf("cb1 executed with data %0d", d.data), UVM_LOW)
endfunction
endclass
//作为子类重载了父类的do trans
class cb2 extends cb1;
`uvm_object_utils(cb2)
...
function void do_trans(edata d);
d.data = 300;
`uvm_info("CB", $sformatf("cb2 executed with data %0d", d.data), UVM_LOW)
endfunction
endclass
//
class comp1 extends uvm_component;
`uvm_component_utils(comp1)
//注册关联cb类,作用是绑定cb1和cb2到组件,顺便绑定了子类
`uvm_register_cb(comp1, cb1)
...
task run_phase(uvm_phase phase);
edata d = new();
d.data = 100;
`uvm_info("RUN", $sformatf("proceeding data %0d", d.data), UVM_LOW)
//插入cb,以预留函数入口。即在此处可执行cb1的do trans**********
`uvm_do_callbacks(comp1, cb1, do_trans(d))
endtask
endclass
class env1 extends uvm_env;
comp1 c1;
cb1 m_cb1;
cb2 m_cb2;
`uvm_component_utils(env1)
function new(string name, uvm_component parent);
super.new(name, parent);
m_cb1 = new("m_cb1");
m_cb2 = new("m_cb2");
endfunction
function void build_phase(uvm_phase phase);
super.build_phase(phase);
c1 = comp1::type_id::create("c1", this);
//添加cb。作用是在组件的cb入口处添加要执行的cb函数
uvm_callbacks #(comp1)::add(c1, m_cb1);
uvm_callbacks #(comp1)::add(c1, m_cb2);
endfunction
endclass
uvm_callback可以通过继承的方式来满足更多的定制,例如上面的cb2继承于cb1。- 为了保证调用
uvm_callback的组件类型T与uvm_callback类型CB保持匹配,最好在T中声明T与CB的匹配,该声明可以通过宏'uvm_register_cb(T,CB)来实现。 uvm_callback建立了回调函数执行的层次性,通过宏'uvm_callbacks #(T,CB,METHOD)来实现。该宏最直观的作用在于会循环执行已经与该对象结对的uvm_callback类的方法。此外宏'uvm_do_callbacks_exit_on #(T,CB,METHOD,VAL)可以进一步控制执行回调函数的层次,简单来说,回调函数会保持执行直到返回值与给入的VAL值相同才会返回,这一点使得回调方法在执行顺序上面有了更多的可控性。- 有了
'uvm_do_callbacks宏还不够,在执行回调方法时,依赖的是已经例化的uvm_callback对象,所以最后一步需要例化uvm_callback对象,上面的例子中分别例化了cb1和cb2,通过“结对子”的方式,通过uvm_callbacks #(T,CB)类的静态方法add()来添加成对的uvm_object对象和uvm_callback对象。
继承uvm_callback并定义CB类 -> 使用uvm_register_cb以及uvm_do_callbacks来绑定和插入CB对于的方法 - > 在顶层例化组件和CB,add()添加CB
callback
提高复用性,如post_randomize中实现crc的校验。
所以我们需要在定义如driver的时候预留一个钩子函数,一般用一个其他类,如A.pre_do()来作为狗子函数。这样用户就不需要重载driver。
使用者只需要派生A,并重新定义pre_do即可。
作为driver需要一个A.pool获取A的派生情况。并调用pool中所有钩子函数
如何使用callback?
VIP开发者
1、实现A
class A extends uvm_callback;
virtual task pre_tran(my_driver drv, ref my_transaction tr);
endtask
endclass2、实现pool
typedef uvm_callbacks#(my_driver, A) A_pool;要指明被哪个类使用、cb是哪一个
3、在driver中调用注册cb
`uvm_register_cb(my_driver, A)4、在driver中调用cb
`uvm_do_callbacks(my_driver, A, pre_tran(this, req));
用户
1、派生A的子类B,并重载pre_trans
2、例化B,创建----------connect phase中执行
3、塞入A-pool
A_pool::add(env.i_agt.drv, my_cb);子类会不会继承父类的A_pool?
1、子类中关联父类`uvm_set_super_type(new_driver, my_driver)
2、直接使用父类的名字`uvm_do_callbacks(father_driver, A, pre_tran(this, req))即可
寄存器模型
在软件层面定义寄存器。field、reg、block、map来抽象寄存器。
层层声明、例化。
eg:在reg中声明field,并且为rand类型,可以加入constraint引入约束(一般可以randomize后使用update实现dut的更新),然后在reg中的build函数中creat、config。但是我们在block中的build需要creat reg,并且config指定后门访问路径。然后调用reg的build函数。还要creat map、add reg to map。最后lock
关于后门访问。在此声明,首先在C中定义hdl read函数,此函数实现vpi get value。然后在sv中import即可调用后门访问。sv中传入path、value即可。如此解决了DUT绝对路径到字符串的转化存储。
path传递this(block路径)、reg名。然后其他前缀地址在test中设置 rm.set_hdl_path_root("top_tb.my_dut");
设置完毕后使用write read(care reg是否only)或peek、poke(不care read only)
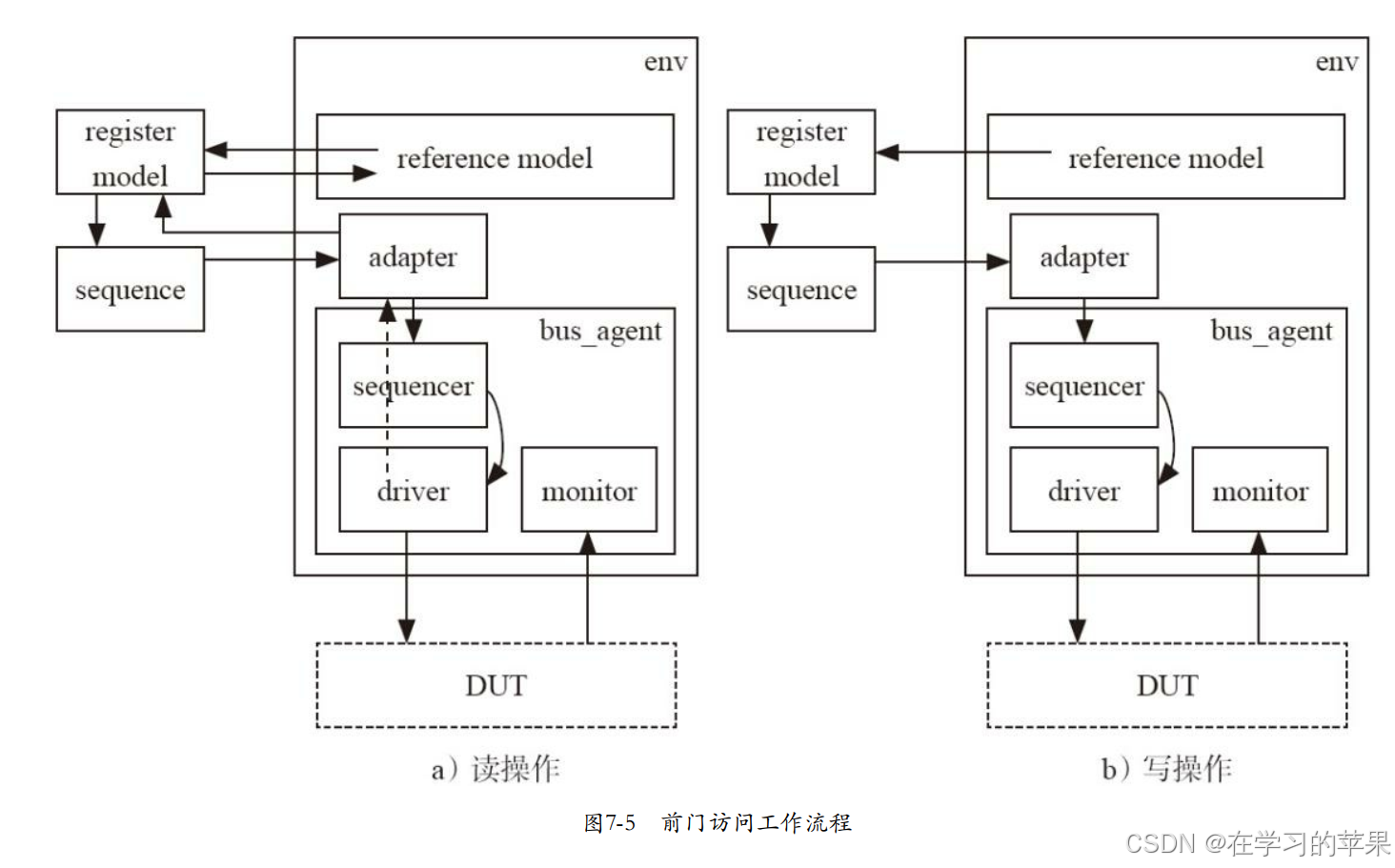
谈及adapter,起到bus reg item的转换作用。我们需要在自定义的adapter中重载两个to函数。其中reg to bus须返回item,另一个使用ref作为参数。adapter在test例化后赋给env的adapter
关于前门访问,是通过Map读写总线完成。因此在test的connect_phase中, 需要将adapter和bus_sequencer通过set_sequencer函数告知reg_model的default_map(三者连接), 并将default_map设置为auto predict状态。auto predict会利用寄存器的操作来自动记录每一次寄存器的读写数值,并在后台自动调用predict方法。还有一种predict为显示预测:通过将predictor集成到环境中,通过monitor监测物理总线,再将监测到的事务传递经adapter转换后传递给寄存器模型并更新信息到map中。
显示预测需要声明uvm_reg_predictor #(apb_transfer) predictor; //声明
然后例化、connect

1)自动预测:所有的后门访问均是自动预测,对于前门访问,需要在map中进行设置
map.set_auto_predict(1);
2)显示预测
自动预测有弊端,如果在系统中,一组寄存器除了可以总线驱动之外,也可以使用别的方式进行驱动,比如跳过寄存器模型,直接使用seq对reg进行操作或者其他总线来访问寄存器,这个时候自动预测是无法正确工作的,这个时候就需要使用显示预测。
那么uvm_reg_predictor是怎么实现mirror值更新的呢。我们知道RAL模型中实现预测功能的核心函数是uvm_reg::do_predictor(*);当monitor中的analysis_port调用write方法时,write方法内部会调用reg的do_predictor方法实现预测
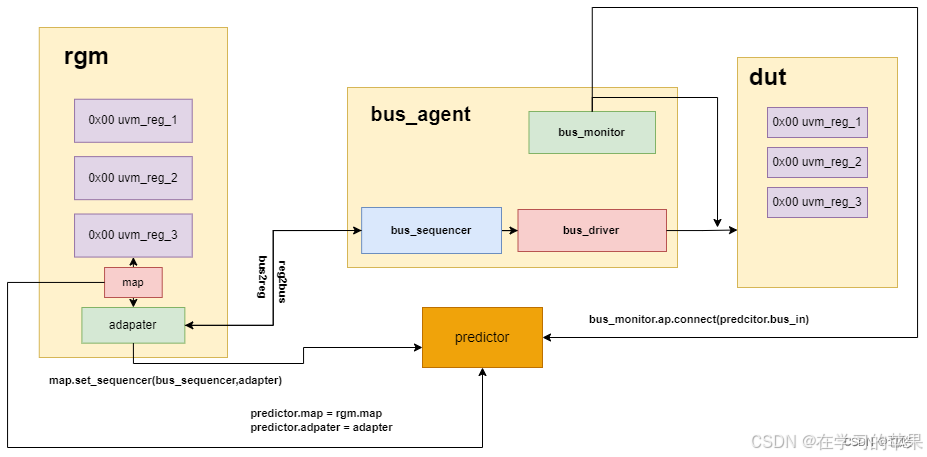
显示预测比较复杂,只能被前门访问使用,可以看见map到predictor到连线。给出了访问信息。至于回来的信息通过monitor接受,然后调用adapter传入rgm
注意:
前门访问无法访问修改和读取filed的值。因为通过map访问
reset() 、get_reset()、get()以及set()都只针对于寄存器模型而不是硬件一侧的值。
peek()是后门读 ,poke()则用于后门写。
对于前门访问的read()和write(),在总线事务完成后镜像值和期望值才会更新成与总线相同的值,而对于后门访问的peek()和poke()由于不经过总线,只能通过auto_predictor的方式,在调用方法后,期望值和镜像值也立即改变。
mirror()不会返回读回的值,但会将对应的镜像值修改,可以选择是否与原镜像值进行对比(UVM_CHECK)。
在sequence中使用寄存器模型, 通常通过p_sequencer的形式引用,需要首先在sequencer中有一个寄存器模型的指针
p_sequencer.p_rm.invert.write(status, 1, UVM_FRONTDOOR);
此时有谈到p_sequrencer. m_sequencer见sequence章节
前门读步骤
rgm产生sequence,通过adapter传递给driver,driver传递item后收到bus item,调用item done,在用adapter传递回去。更新、返回参考模型
sequence
启动方式
- my_seq.start(sequencer);直接启动
 使用config db将seq设置为default seq。其实直接传例化后的name也行。
使用config db将seq设置为default seq。其实直接传例化后的name也行。
八股
- seq启动后自动执行,prebody、body、postbody等函数
- default_sequence会调用start任务
- sqr只能产生一种item,兼容化可类型转换成uvmseq,然后cast
多个seq如何启用?
可以在fork块中使用start并行的启用
seq仲裁
在一个seq中的item可以通过uvm do pri设置优先级,然后在sqr设置仲裁算法。因为sqr默认是FIFO的,不care优先级。当设置后就可以以上述做法仲裁item。
还可以设置seq的优先级:seq0.start(env.i_agt.sqr, null, 100);本质还是设置item的优先级
还可以使用lock()函数和unlock()。类似PV锁。中间的seq会占据sqr的所有控制权
grab()也差不多,相当于升级版的lock
取消优先级-seq
在seq重载is_relevant函数即可控制seq是否参与仲裁

或者重载如下函数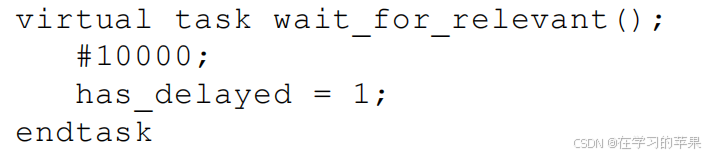
当sqr发现seq都无效时就会调用这个函数,然后这个函数就把is relevant打开。也就是说可以自己控制。一般他俩一块用
如何发送item?
- uvm do系列函数。
- `uvm_create(m_trans)(或者直接new)然后`uvm_send(m_trans)。比较灵活。发送的时候还可以用`uvm_rand_send(SEQ_OR_ITEM)进行随机化。类似do的with
- start、finish---底层
再往深挖就是如下方式实现
tr = new("tr");
start_item(tr);
predo()
######随机化等操作
postdo()
finish_item(tr);
item的pre post
在start的后面会predo,finish前postdo。注意我们只需要在seq中override 即可
嵌套
seq内可定义rand,然后在外层seq被randomize{}
p_seqr
在seq中操作sqr变量,可以用p_seqr引用。`uvm_declare_p_sequencer(my_sequencer)
如果使用m_seqr。可以在seq中通过cast转换将m_sequencer转换成sqr类型,并引用其中的变量。因为他是父类。
virtual sequence
用于实现seq的同步。test中实现vsqr,里面管理众多sqr
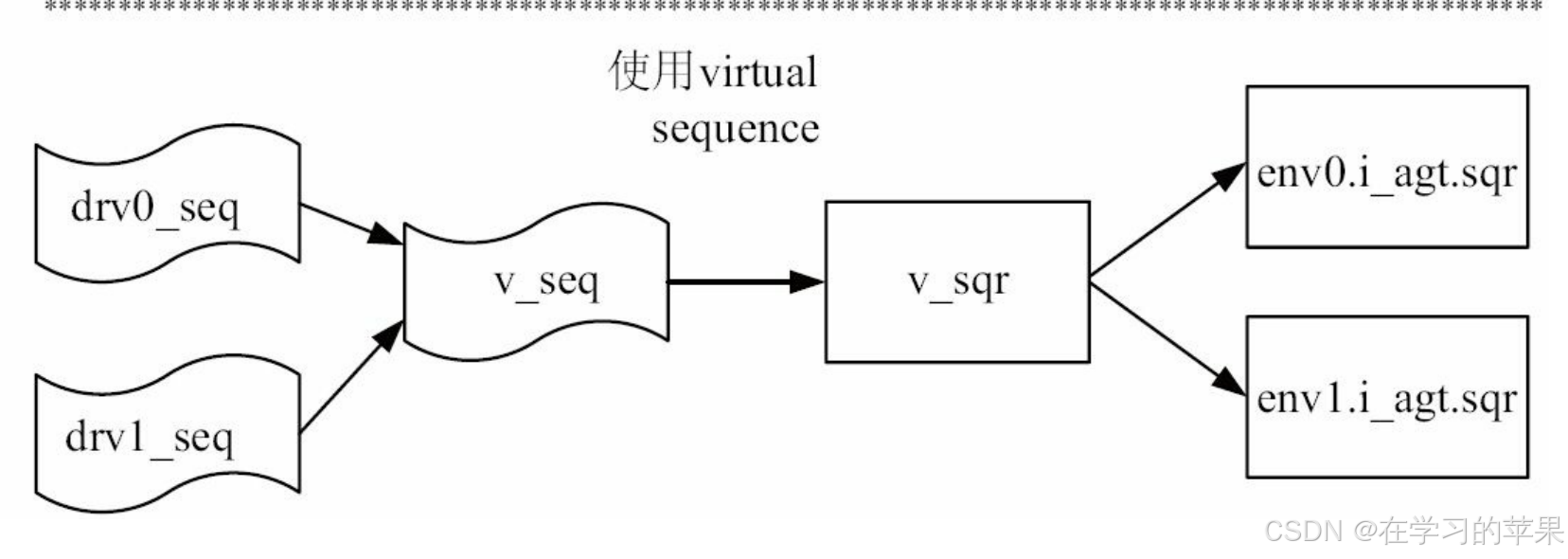
在vseq
中使用uvm do on :vsqr.sqr,即可实现virtual的管理。外界看来只有一个vseq、vsqr
如何实现同步?
virtual sequence的body是顺序执行,所以直接在vseq body干就行了。把我们想干的seq例化出来,然后do on!
objection
要么在scoreboard中控制objection,要么在sequence中控制
但是如果在seq中控制,需要设置其为default seq。不染不行,所以使用vseq即可解决此问题
如何在seq中用config db?
按理说不可以使用,因为seq是object。而config db需要component的路径。
当在seq使用get full name的时候,我们却可以得到sqr.seq的路径。
uvm_config_db#(int)::set(this, "env.i_agt.sqr.*", "count", 9);
如此即可成功使用。*是因为seq名字不确定,就用*
注意第一个参数在seq只能能使用null,因为第一个参数必须为conponent
在seq向component通过config db传参时,是在task phase。而component一般在build phase get 参数。如何解决?
使用
uvm_config_db#(bit)::wait_modified(null, get_full_name(), "send_en");
该函数会阻塞,直到第三个参数变化。所以我们可以在component中的mainphase使用,这样直接同步了。
而且可以在seq使用,和config db一样。
driver处理完seq的item,如何与seq同步?seq如何知道drver干完了一个item?
在driver干完后,把item的id通过rsp.set_id_info(item),保存到rsp,然后通过
- seq_item_port.item_done(rsp);塞回去 仅一个item可用,因为done只调用一次
- 「或者用seq_item_port.put_response(rsp);」。一群item还是用这个
- 这样seq就可以等待这个rsp()get_response(rsp);
response机制原理
driver推送给sqr中的队列【8】,超出了会溢出
driver需要长时间处理上一个req,但此时还需要获取写一个req怎么办?
需要获取的难点是:未处理完毕req时,seq会阻塞在get response。这时可以用response_handler
- 打开response_handler
virtual task pre_body(); use_response_handler(1); endtask - 重载response_handler
virtual function void response_handler(uvm_sequence_item response); if(!$cast(rsp, response)) `uvm_error("seq", "can't cast") else begin ` uvm_info("seq", "get one response", UVM_MEDIUM) rsp.print(); end endfunction - 如此实现发送req和处理rsp分开处理
req rsp类型不一样怎么办?
class my_driver extends uvm_driver#(my_transaction, your_transaction);
class my_sequencer extends uvm_sequencer #(my_transaction, your_transaction); class case0_sequence extends uvm_sequence #(my_transaction, your_transaction);
如何随机化测试seq?
uvm_sequence_library类
class simple_seq_library extends uvm_sequence_library#(my_transaction);
function new(string name= "simple_seq_library");
super.new(name);
init_sequence_library(); //初始化候选队列
endfunction
`uvm_object_utils(simple_seq_library);
`uvm_sequence_library_utils(simple_seq_library);
endclass然后在seq定义的时候写`uvm_add_to_seq_lib(seq0, simple_seq_library)添加进去。
然后将library作为default sequence即可
那么library如何仲裁?
uvm_config_db#(uvm_sequence_lib_mode)::set(this, "env.i_agt.sqr.main_phase",
"default_sequence.selection_mode", UVM_SEQ_LIB_RANDC);uvm_sequence_lib_mode
- UVM_SEQ_LIB_RAND:完全随机
- UVM_SEQ_LIB_RANDC:保证seq随机的执行一遍
- UVM_SEQ_LIB_ITEM:自己产生transaction
- UVM_SEQ_LIB_USER:用户自定义。需要在library重载select_sequence
virtual function int unsigned select_sequence(int unsigned max); static int unsigned index[$]; static bit inited; int value; if(!inited) begin for(int i = 0; i <= max; i++) begin if((sequences[i].get_type_name() == "seq0") index.push_back(i); end inited = 1; end value = $urandom_range(0, index.size() return index[value]; endfunction返回一个sequences队列的排序号
library执行次数如何控制?
使用
uvm_config_db#(int unsigned)::set(this,"env.i_agt.sqr.main_phase",
"default_sequence.min_random_count",5);
uvm_config_db#(int unsigned)::set(this,"env.i_agt.sqr.main_phase",
"default_sequence.max_random_count",5);设置上下限即可
也可以简化设置
uvm_sequence_library_cfg cfg;
cfg = new("cfg", UVM_SEQ_LIB_RANDC, 5, 20);
uvm_config_db#(int unsigned)::set(this,"env.i_agt.sqr.main_phase",
"default_sequence",simple_seq_library::type_id::get());
uvm_config_db#(int unsigned)::set(this,"env.i_agt.sqr.main_phase",
"default_sequence.config",cfg);seq_lib = new("seq_lib");
seq_lib.selection_mode = UVM_SEQ_LIB_RANDC;
seq_lib.min_random_count = 10;
seq_lib.max_random_count = 15;
uvm_config_db#(int unsigned)::set(this,"env.i_agt.sqr.main_phase",
"default_sequence",seq_lib);上述也可以
Factory
工厂注册
uvm_component_utils
uvm_component_param_utils:参数类
工厂创建类
- factory.create_component_by_name("my_transaction", get_full _name(), "scb", this);
- factory.create_component_by_type(my_transaction::get_type(), get_full_name(), "scb", this);
- factory.create_object_by_type(my_transaction::get_type())
- factory.create_object_by_name("my_transaction")
name需要写parent,一般只在component中使用
高级应用
interface可以加入一些信号处理逻辑,转换编码。利于调试和复用。
可以使用configdb配置tb参数,实现可变时钟
DPI-SV
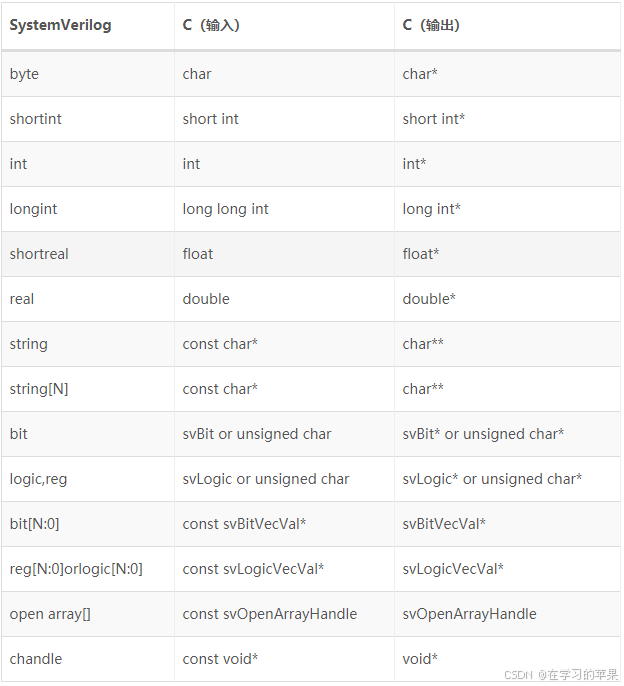
SV
数据类型
verilog的数据类型
四值变量reg、wire。32bit有符号integer、64bit无符号time、real(浮点)。都为静态变量,即仿真时都存在。
SV加了的数据类型
- logic:4值。单驱动。所以inout要定义为wire。
- bit:2值。无符号。
- byte、int、shortint、longint:带符号、2值。
2值变量最好不要连接到DUT,避免X、Z态。
4值缺省值为X。2值为0.
仿真器使用32bit一字边界。
数组
- bit 【packet】 arr 【unpacket】。packet是连续的一块区域
- 对unpacket赋值`{1,2,3}。
- a【0】一般表示unpacket的下标,再往后就是packet。packet是左到右的顺序。
- sum()、product()、and()、min、max、unique、find。可加with(item>2)操作
- reverse、sort、shuffle
动态数组
- a【】=new【5】。
- 可以和定宽数组组合定义 bit【7:0】 a【】=`{……}
- a【】【】。new的话先new左边。然后a【2】=new【】
队列
- 结合链表、数组特点。q【$】
- insert(i,data)、delete(i)、push_front、push_back、pop_front、pop_back
- 类似STL的双端队列
- 不用new【】
关联数组
- bit arr【int】=`{0:1,2:3}。实现mem
- first(min_addr)、next(addr)、delet(addr)、exists()
typedef struct
typerdef union {bit [] b; int i;} asdsad;
合并结构
struct packet{bit [7:0]a,b,c;}紧凑合并3BYTE
类型转换
静态:int`(19.2)
动态:cast
流操作
>>、<<、byte>>.打包成数据流。注意arr【3】是【0:3】的顺序
可以实现struct------byte【】的转换
枚举enum
要注意定义枚举变量a它缺省值是0.所以在枚举typedef enum xxx{A =1,B,C} or_e是不合法的
first、last、next、
字符串
不带结束标志符NULL。
get(i),toupper返回大写,tolower返回小写。putc(M,C),substr(start,end)
compare(string)
过程语句、子程序
函数任务
函数不可以消耗仿真时间,不可阻塞、延时、调用任务,但是SV可以调用任务(fork join none内)
function automatic void print (const ref bit [31:0] a [] = xx)
end functionautomatic代表子程序内部是自动存储。const ref可以不改变数组的值,ref可以不在堆栈开辟空间存储临时数组。
还可以使用缺省值。
函数在使用ref的时候最好把其他变量加上方向。
return 函数、任务都可以用
verilog变量都是静态的,不同线程使用一个task的变量会窜用。SV可以使用动态变量automatic
使用一般我们先声明变量,然后再赋值。
时间
time型:不能保存小数时延。64bit。舍入
realtime:不会舍入
$time. $realtime 和上述一样
interface
用于连接DUT
interface if(input bit clk);
logic grant
modport xxx (output request,rst,
input grant ,clk);
endintefacemodport可用于分组。 if.xxx. my_if即可声明使用
时钟块
不支持综合。可以被打包modport
支持@cb触发此时钟块。
clocking cb @(posed clk);
output request;
input grant;
endclocking
modport test (clocking cb,
output rat);仿真时序问题🌟
类
解除对象的分配
t=null;
类中的方法默认automatic。成员变量默认public外部皆可访问。
对象的复制
c=new b;这样创建一个和b一模一样的对象。而且b里面的对象是一个。
因为复制的对象id相同。
深拷贝
function tran copy();
copy = new();
copy.addr = add;
id=id++;
endfunction随机化
约束是并行求解的。但是 solve x before y。可以改变约束顺序。
rand和randc区别
randc不放回。周期型的随机
constraint中不能连续的约束:a《b〈c
约束可以为变量
typedef eunm {BYTE,WORD,LWRD} leng;
rand leng len;
bit [31:0] x=2,y=3,z=1;
constraint cos {
len dist{
BYTE:=x,
WORD:=y,
LWRD:=z
};
}约束的语句
:=
:\
inside{[lo:hi]} !(c inside{arr})
A->B A真,B必须真。A假,B随意
A<->B. A真,B必须真。A假,B必须假。
如何关约束?
class.con.constraint_mode(0).
外部约束定义
constraint classA::conname{}可以单独放一个文件方便管理。
如何随机化对象数组
先定义一个动态数组,然后随机化其大小。再在foreach上new
randcase构造决策树
randcase
2:do_A();
4:do_B();
endcase
task do_A();
randcase
2:do_C();
4:do_D();
endcase
endtask关于随机数生成,SV会对每个对象or线程产生一个独立的PRNG,把随机数算法独立
子PRNG由父PRNG产生
fork join none
有一种情况:fork-join_none块的语句不会执行,直到父进程遇到了一个阻塞语句或调度结束end出现。
即语句前有#,@或wait
例4
`timescale 1ns/1ns
module test();
initial begin
for (int j=0; j<3; j++) begin
fork
$display(j);
join_none
end
end
endmodule
display只会在for循环结束,再执行3个display。打印三个3.
上述代码出错的原因是打印的三个线程,只操作j。而最后j是3.
initial begin
for(int j =0;j<3;j++)
fork
automatic int k = j;
begin
$write(k);
end
join_none
#0 $display;
end这个时候最后输出的是k0、k1、k2.
线程等待
对于fork join_none产生的n个线程,可以在fork外面使用wait fork;阻塞
停止线程
使用disable 线程名;停止线程
停止制定块的所有进程
或者使用disable fork停止当前线程所有子线程。针对语句当前fork块中所有线程。
停止task
task A;如果使用disable A;那么所有的A都将停止。
覆盖率
覆盖率类型
代码覆盖率、功能覆盖率、漏洞率、断言覆盖率
功能覆盖率
- 先定义covergroup
- 在例化cg。
- cg.sample()采样
UVM中建议monitor通过ap讲trans发送到覆盖率组件收集
其他定义覆盖组方式
传参
covergroup cg (int para);
xx:coverpoint dst{
bins lo = {[0:para]}
};
endgroup外部定义覆盖组
covergroup CV with function sample(bit [2:0] 1st,bit hs);
end group事件触发覆盖组
covergroup AA @(event_a);
end group然后这个事件还可以使用断言触发
cover property
(@(posedge clk)ena==1)
-> event_a;
覆盖率采样原理
3bit的域是【0:7】。bin会分配8个
auto_bin_max指明的bin的最大值,默认64.超出的会平均分配。他可以给单个变量限制,还可以限制整个covergroup
对表达式采样
len16:coverpoint(a+b);
对bin命名
- len: coverpoint (a + b) { bins len【】 = {[0,23]}; } 对名为len 的coverpoint进行bin的大小控制
- coverpoint A{ bins hi[] = {[8:$]}; } 对单独的bin命名
- coverpoint B iff(!rst) ; 仅复位时收集B
- 还可以。Covergroup cg; cg.stop() cg.start() 进行是否收集的控制
- 翻转cover : coverpoint dst{ bins t = (0=>1) ,(0=>2);} 记录翻转状态是否覆盖
- wildcard bins odd = { 3'b??1}; wildcard可以创建多个状态
- ignore_bins x = {[6,7]}; 不关心
- illegal_bins hi = {[6,7]} 出现此数值会报错
交叉覆盖率
cross
covergroup Covport;
port: coverpoint tr.port{
bins port[] = {[0:$]};
type_option.weight = 0; //表示不覆盖,权重为0
}
kind: coverpoint tr.kind {
bins zero = {0};
bins lo = {[1:3]};
bins hi[] = {[8:$]};
bins misc = default;
}
cross kind, port {
ignore_bins hi = binsof(port)intersect{7};
ignore_bins md = binsof(port)intersect{0}&&binsof(kind)intersect{[9:11]};
ignore_bins lo = binsof(kind.lo);
bins a1b2 = binsof(a1)&&binsof(b2);
}
endgroup
intersect指定的是一个范围
type_option.weight = 0; //表示不覆盖,权重为0
覆盖率选项
- auto_bin_max
- type_option_weight
- option.per_instance= 1; 放在覆盖组中,用于查看单独报告
- type_option.comment = “啊啊啊” 添加注释
- option.at_least 用于设置覆盖bin命中次数
- option.cross_num_print_missing = 100;打印空bin
- option.goal = 90;设置覆盖率90%
总线
简历
验证VIP集成
SVT APB VIP_uvm apb vip使用-优快云博客
SOC验证printf
CPU仿真环境中的printf实现_cpu core printf-优快云博客
实现printf:
- 调用仿真C运行库
- 重定向fputc,将字符串ASCII码写入指定地址。将字符写入指定流stream
- 在仿真testbench/monitor中实现对指定地址写入的监测
- 将写入字符串用系统打印函数输出到终端或保存到log文件

















 5734
5734

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









