







Transformer
简单来说就是Sequence-to-Sequence
输入一个序列,输出一个结果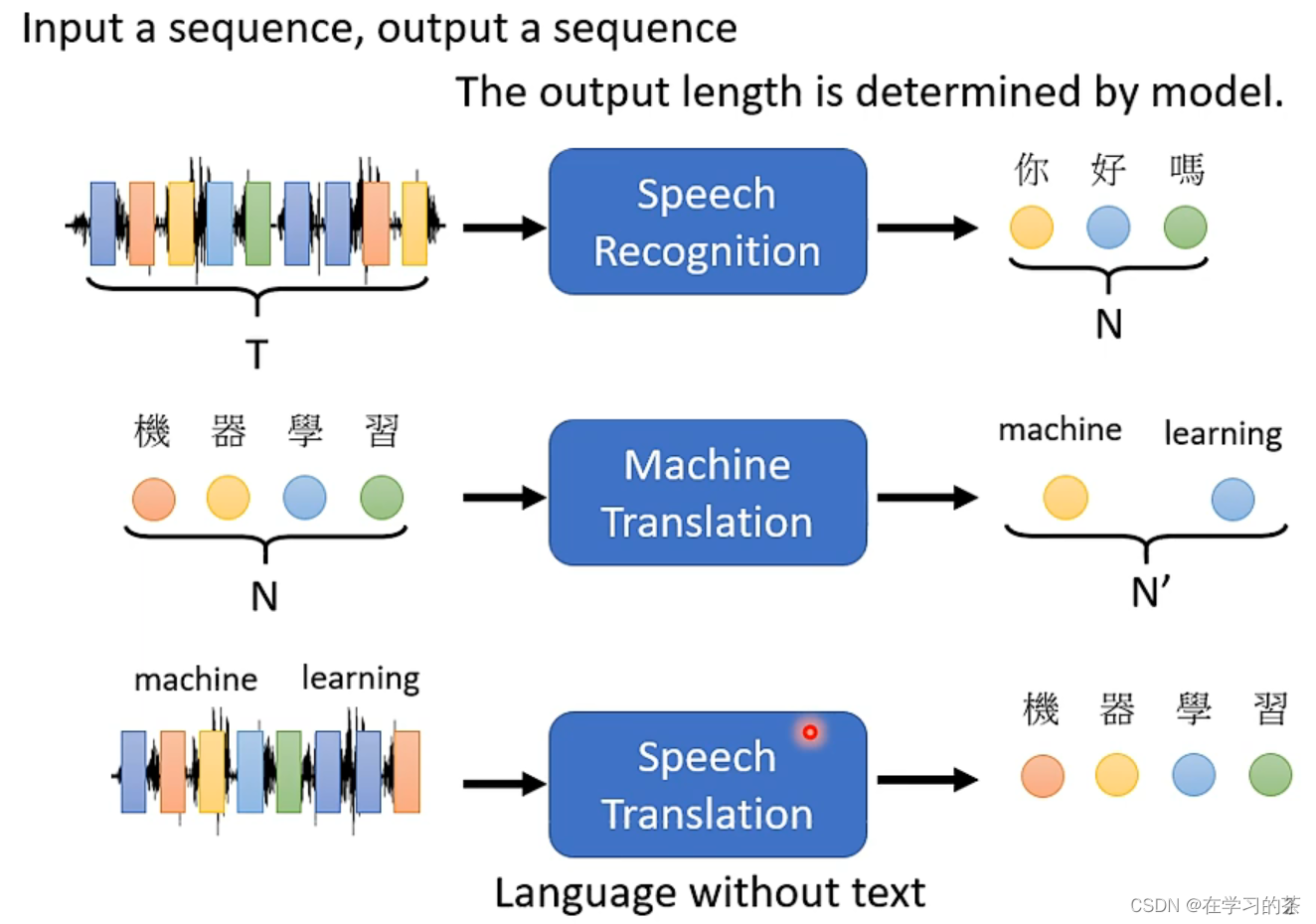
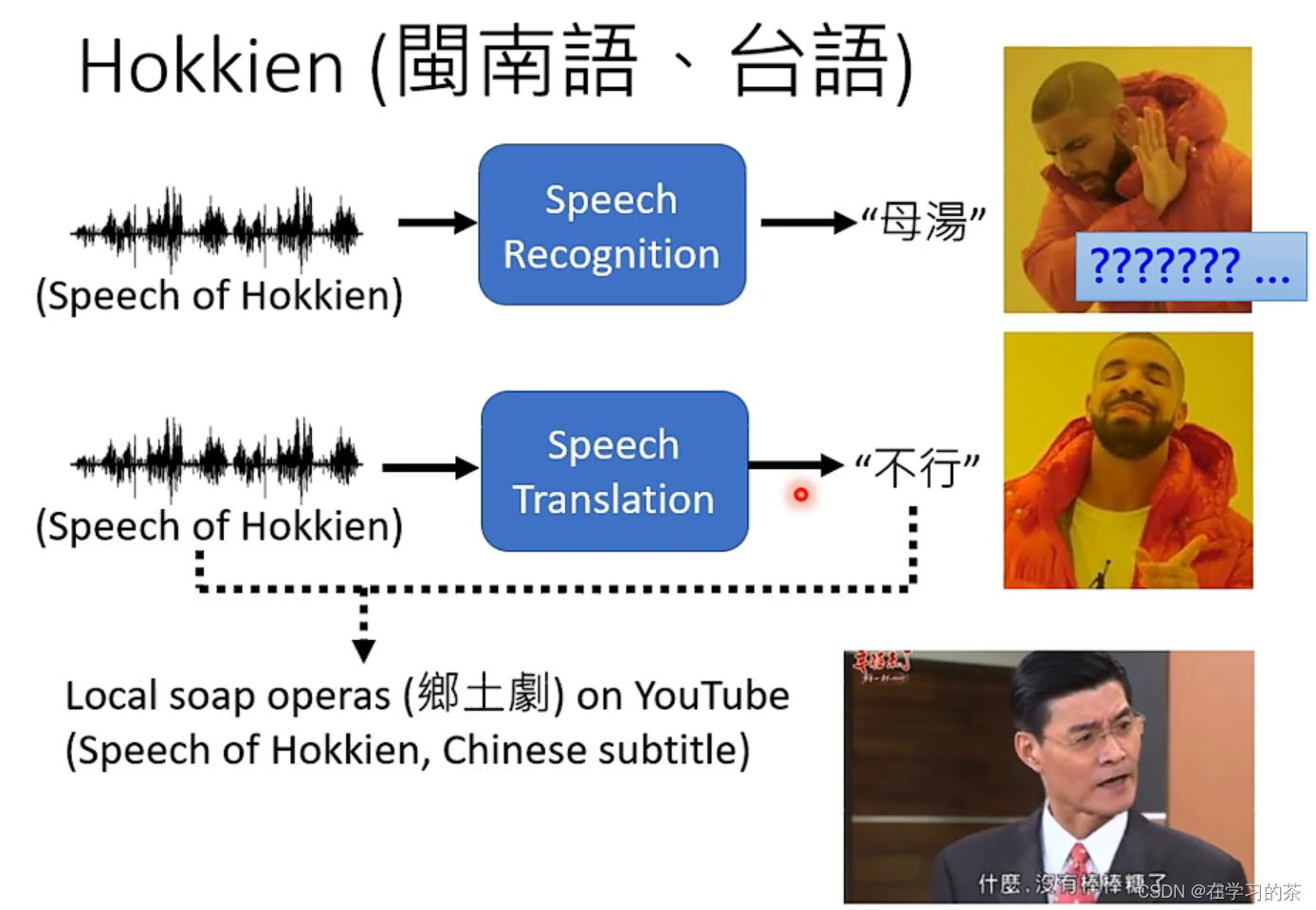
这个是台语到中文的翻译器
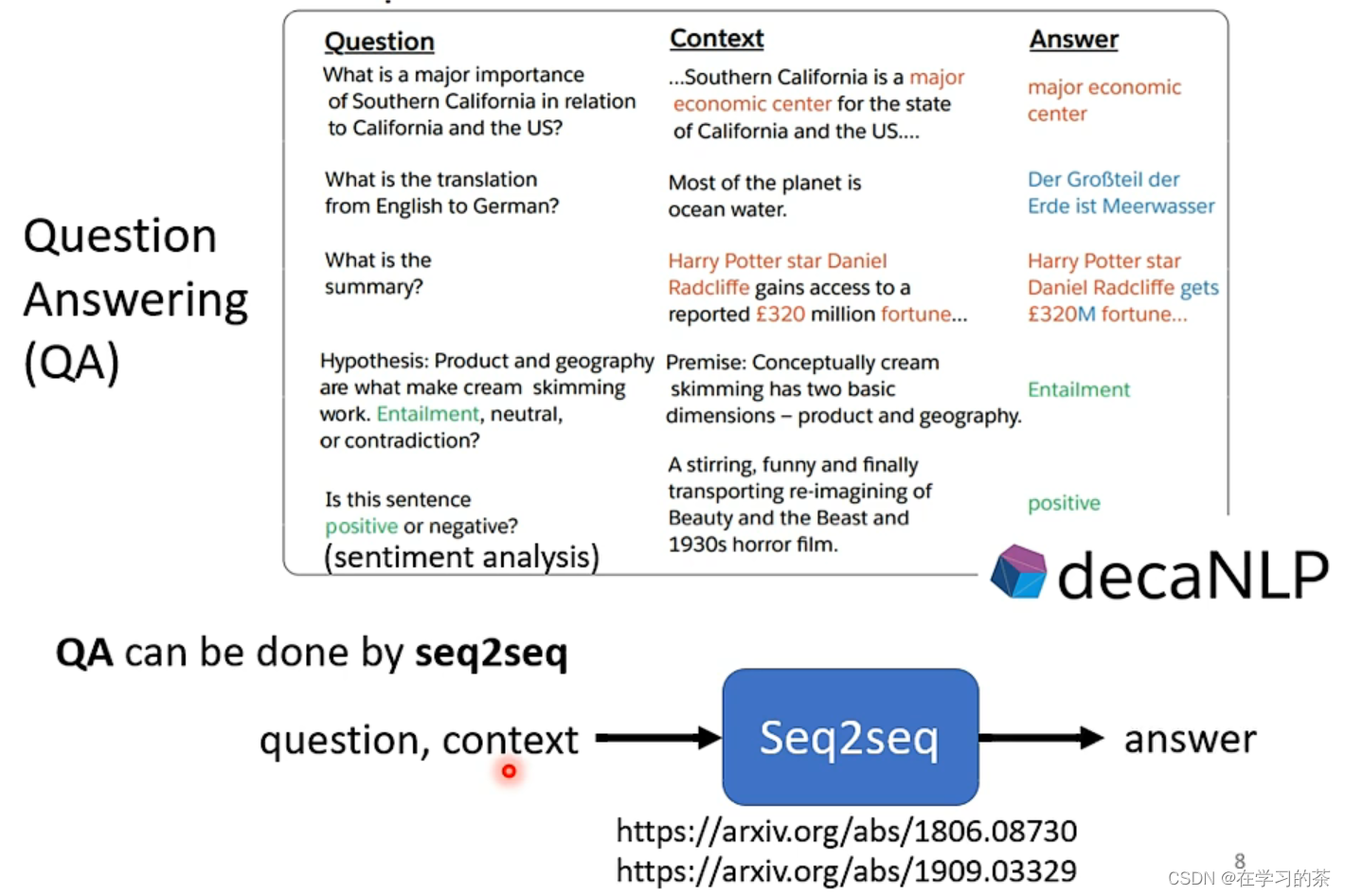
其实各式各样的NLP问题都可以看成QA问题,类似一个机器人,你问他,他会选择模式并且返回结果。如翻译,主成分提取,情感分析等
但是如果你特质化模型(专门定制),效果当然更好。当然最普遍的Seq2Seq也能做
多标签的训练,直接可以看成Seq2Seq模型
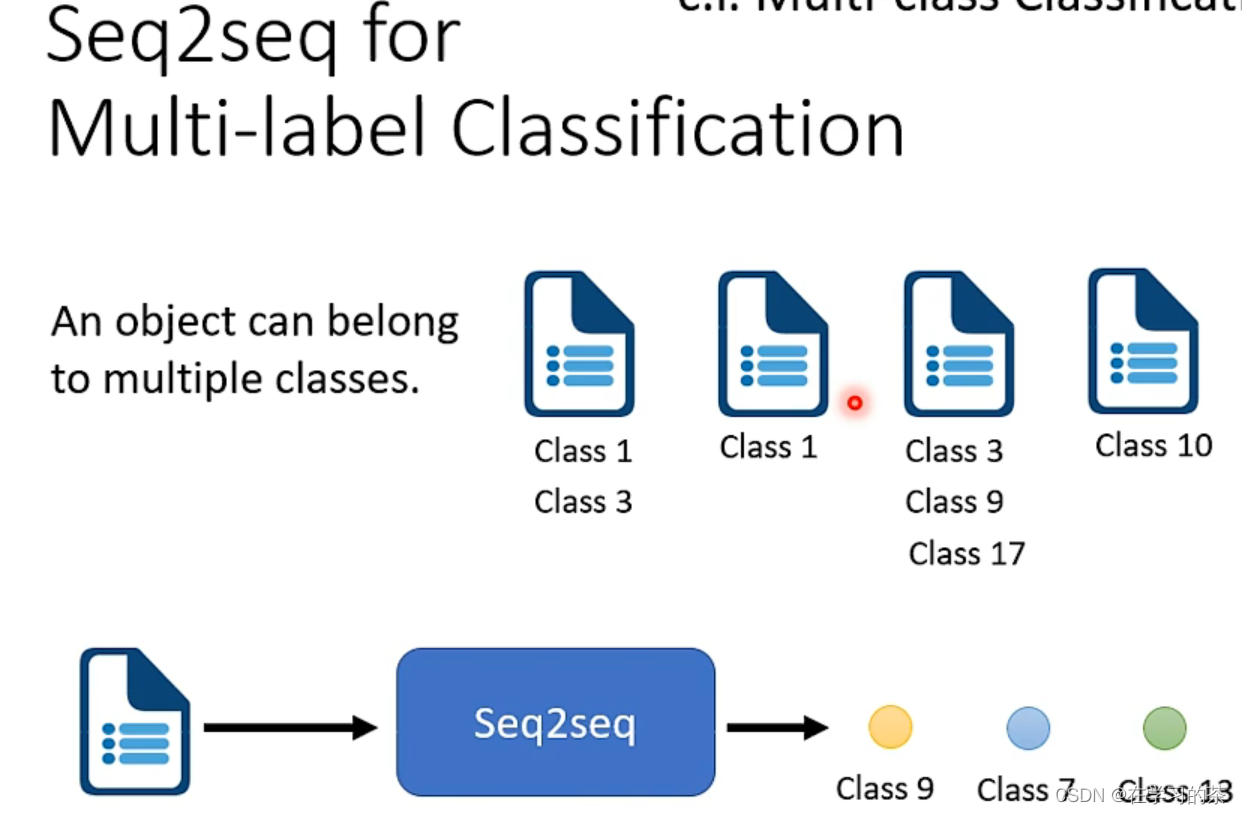
还有如下。
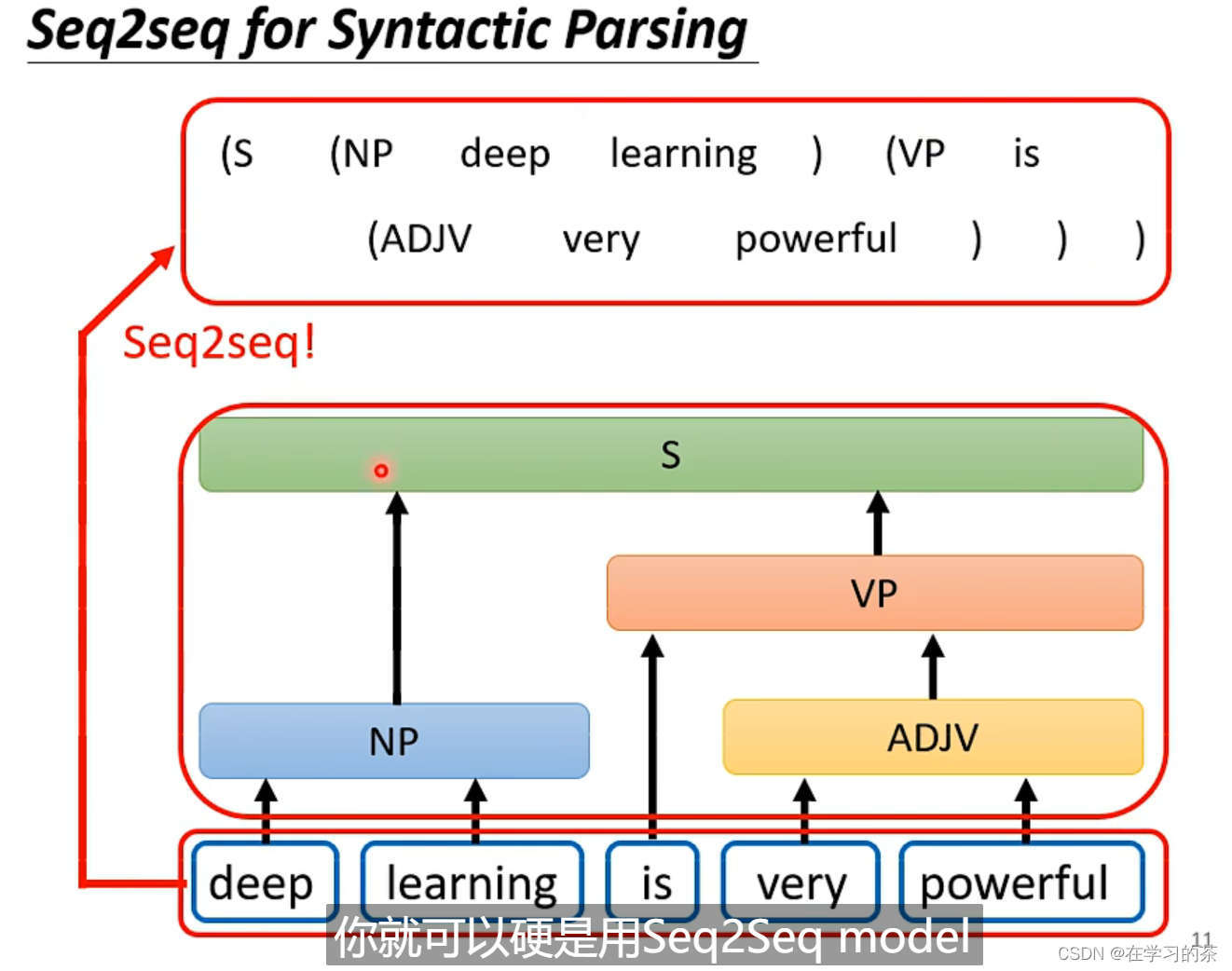
文法剖析
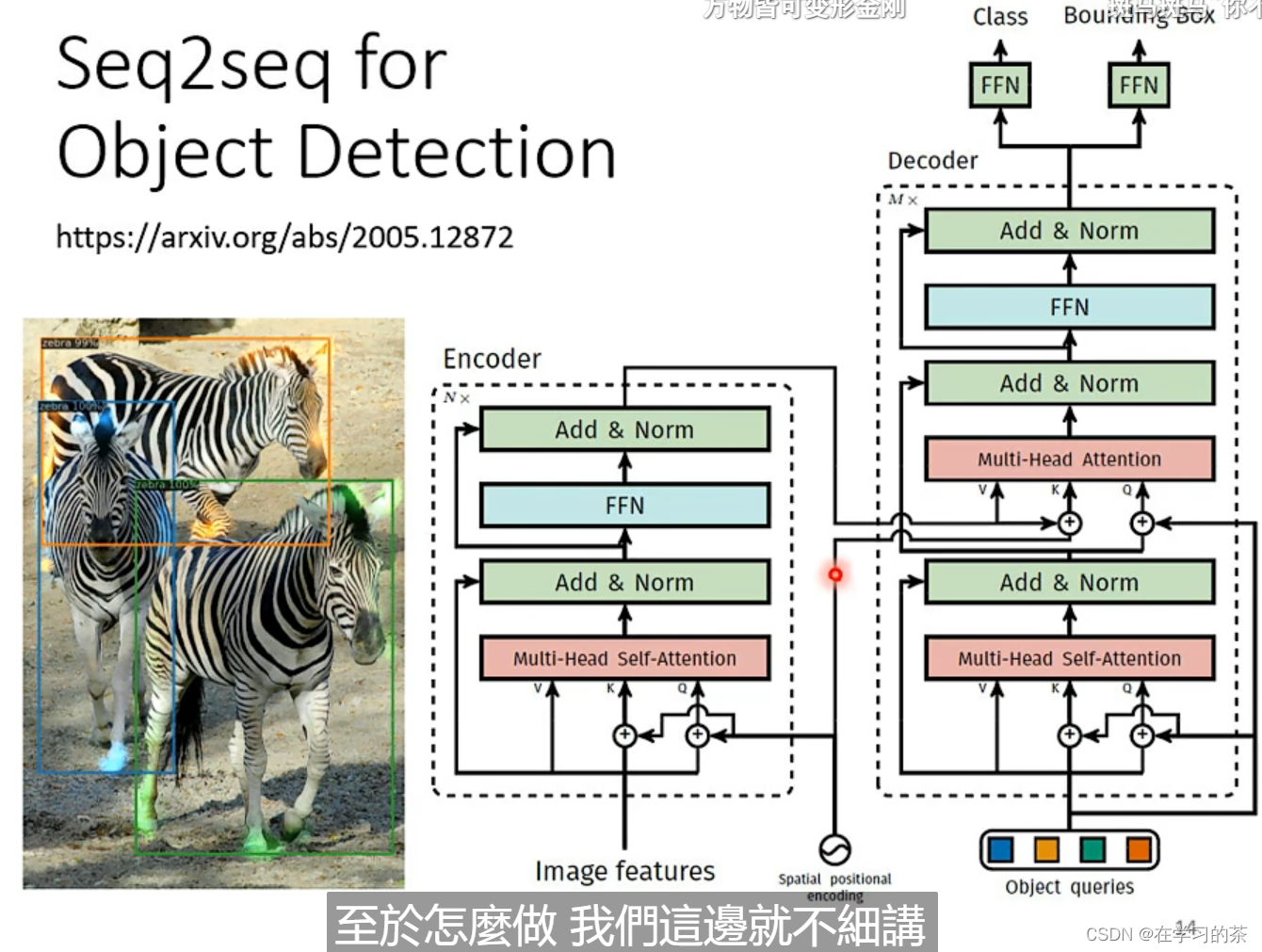
甚至物体检测也可以用Seq2Seq
Transformer原理
Encoder
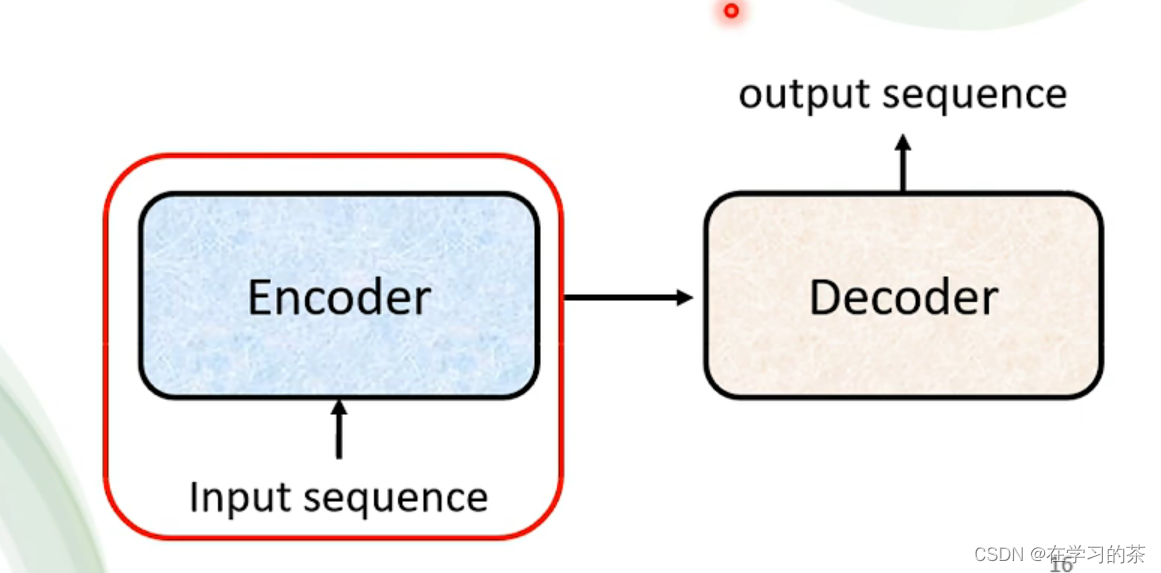
这就是一级框架。下面我们来讲Encoder
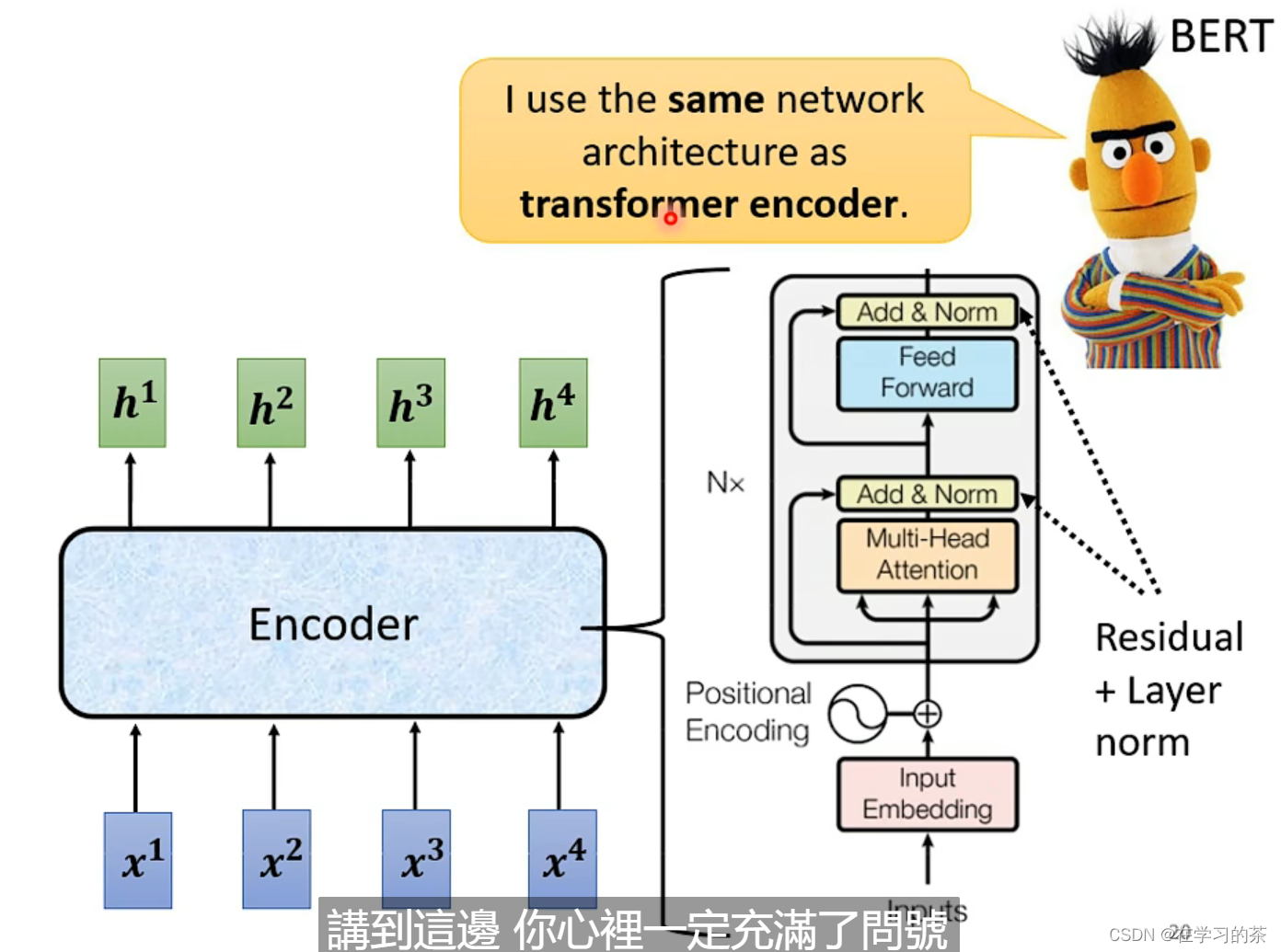
其实Transformer的Encoder就是用了Self-attention。
Positional Encoding是位置信息,Embedding是把文本向量化。使用Word2vec方法编码单词,不用one-hot因为太稀疏了
FeedForward就是全连接层
注意
Muti-attention如下,多个attention进行concat
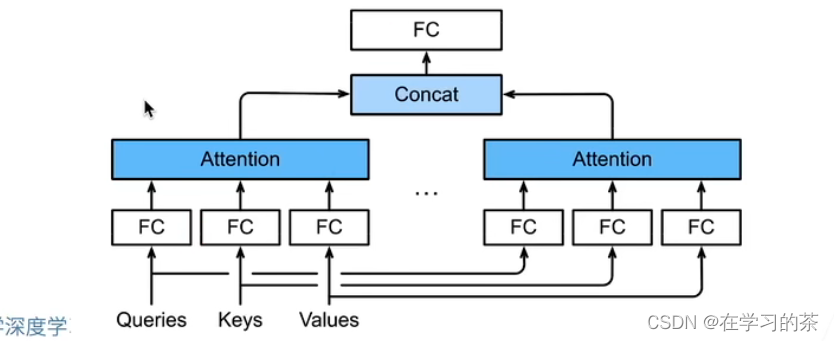


前馈网络解释。
b:batch-size
n:序列长度
d:维度
你知道的,n作为序列长度会变化,不可以一起放进去!!
B:多少个句子,N:句子有多少个字,d:就是这个字是多少维。
bn就是整个输入多少字,这就是为什么要变化维度
详细如下图
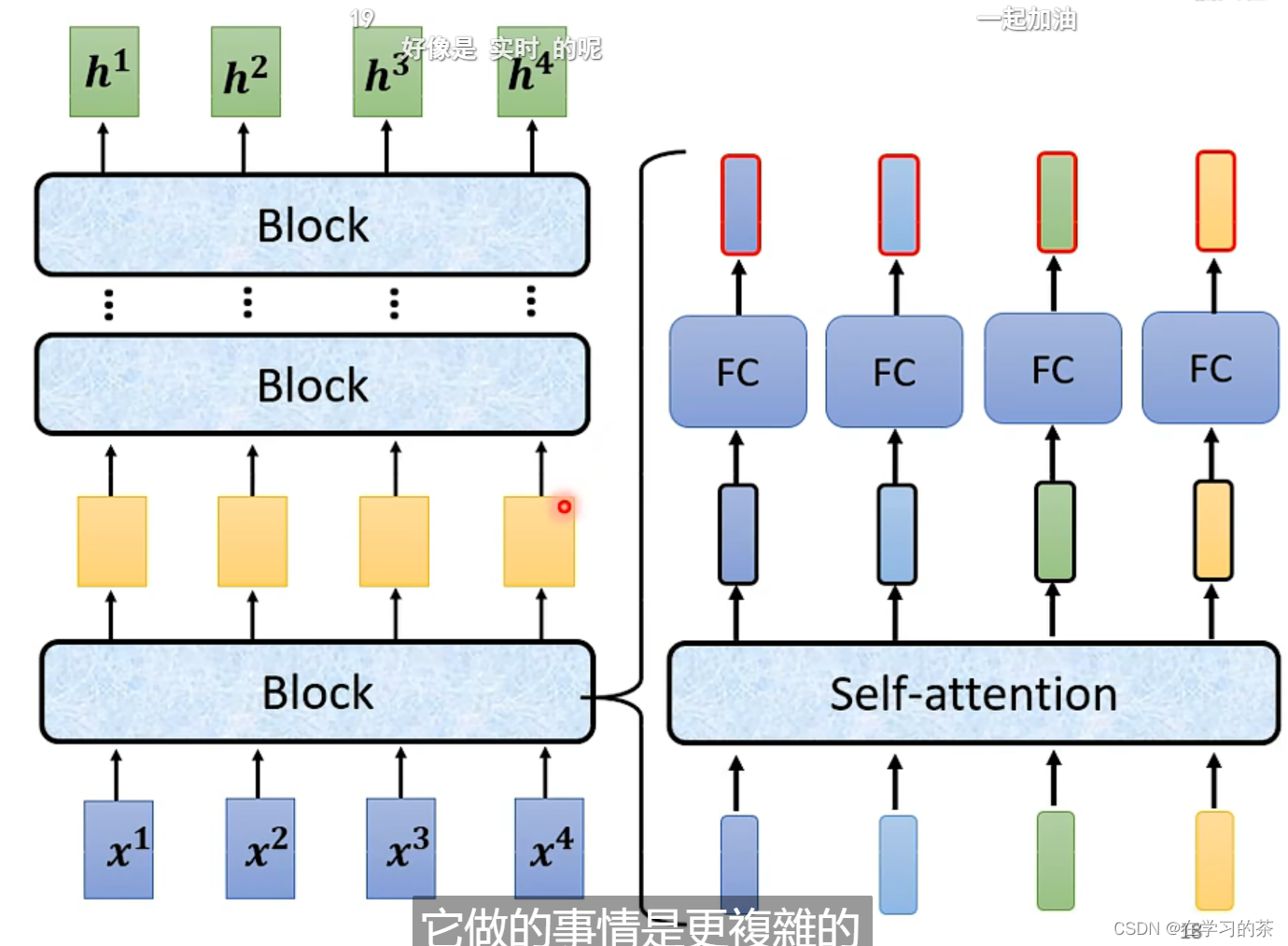
解释一下:每个Block都包括好几个Layer
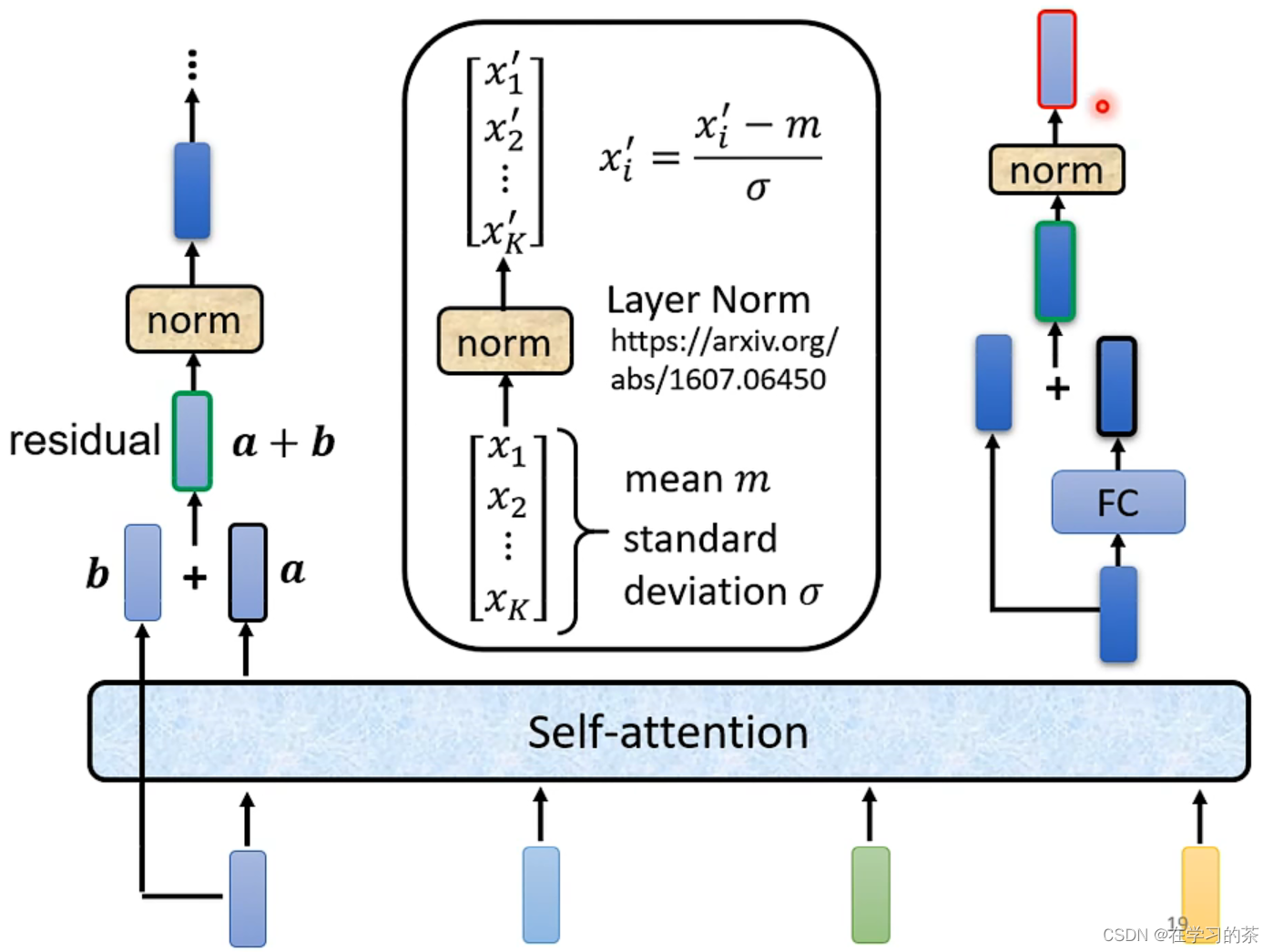
这里的Self-attention用到了一个叫residual的方法,把attention后的结果再加上自身。之后Normalization,不过这里的Normalization是Layer Norm。
不同于batch norm,这里是把同一个batch的不同feature进行求μ,σ。再标准化。而BN是对很多个batch 的同一个feature做标准化
为什么不可以batchNorm?
batchnorm是对同一个feature归一化,在这里就是对第三维d归一化,毫无意义
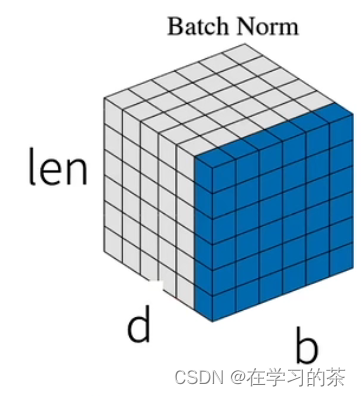
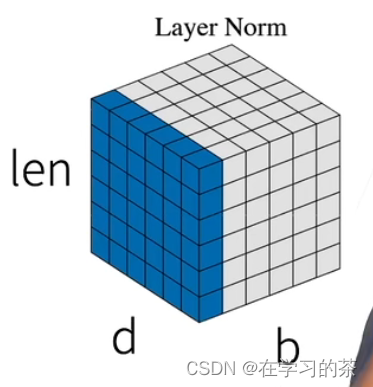
layer是对每个句子的全部字归一,batch是全部句子的第d个维度位子归一
最后的结果在用一次(蓝色)residual+Layer Norm。得到最后的结果 (红框框)
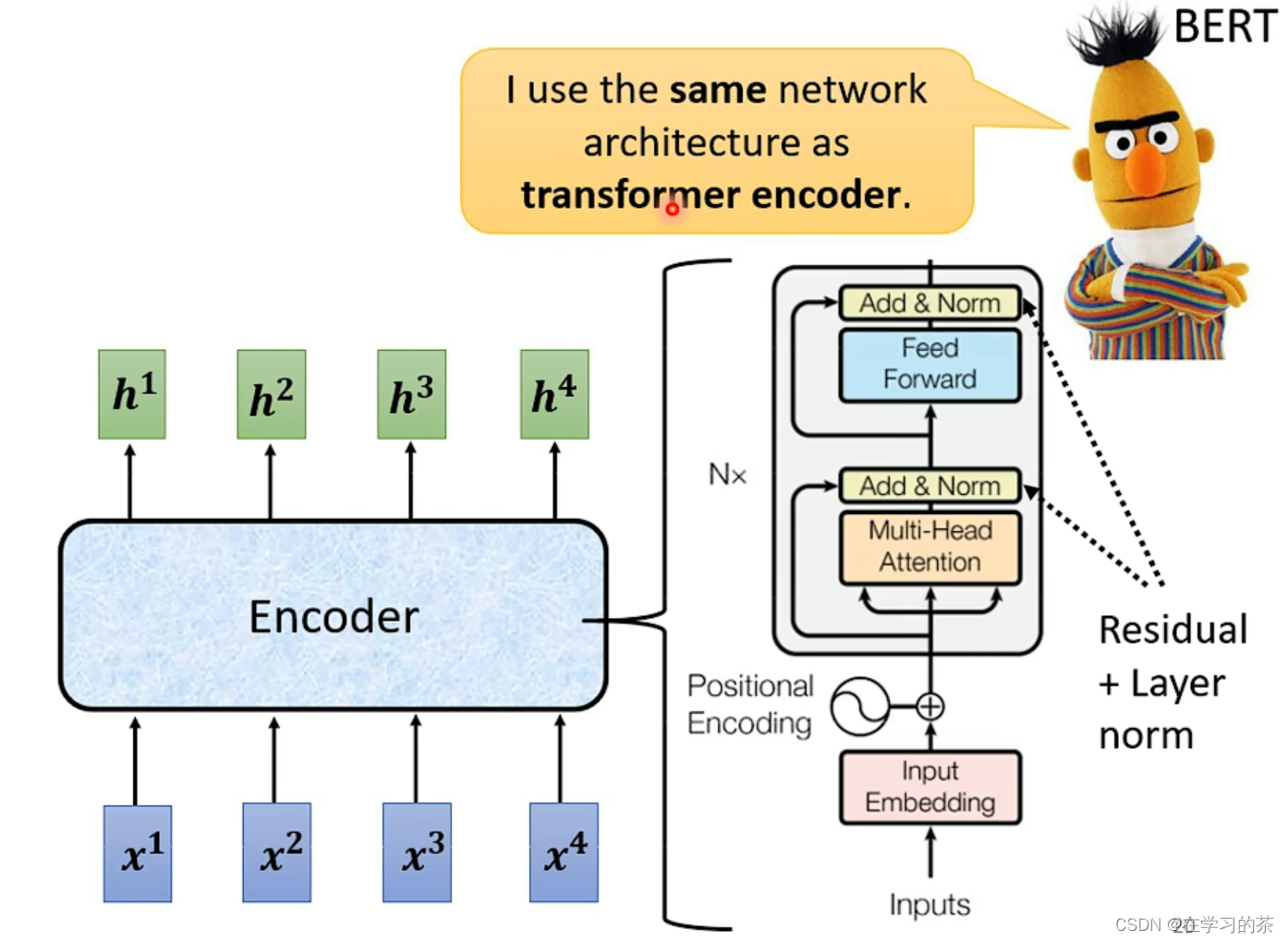
Encoder分解出来就是这个,Position Encoding是加了个顺序,相当于一句话单词的顺序,再Self-attention那章又讲。
Multi-Head Attention 就是多头Self-attention
Add&Norm就是Residual + Layer Norm
整体框框会重复N 次
原模型就是最好的吗??如下两篇论文给出①LayerNorm位置分析②BatchNorm可行性
Decoder
其实有两种,介绍最常见的AT
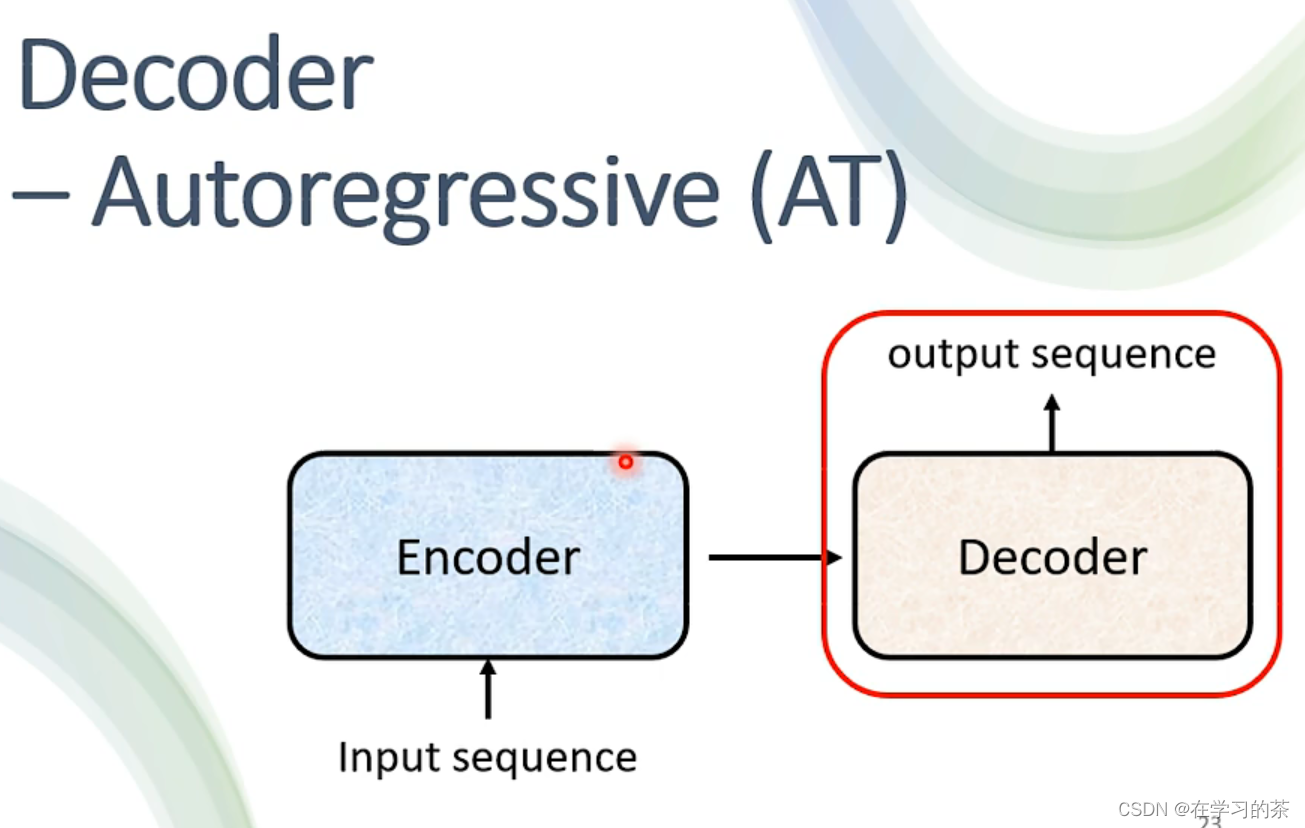
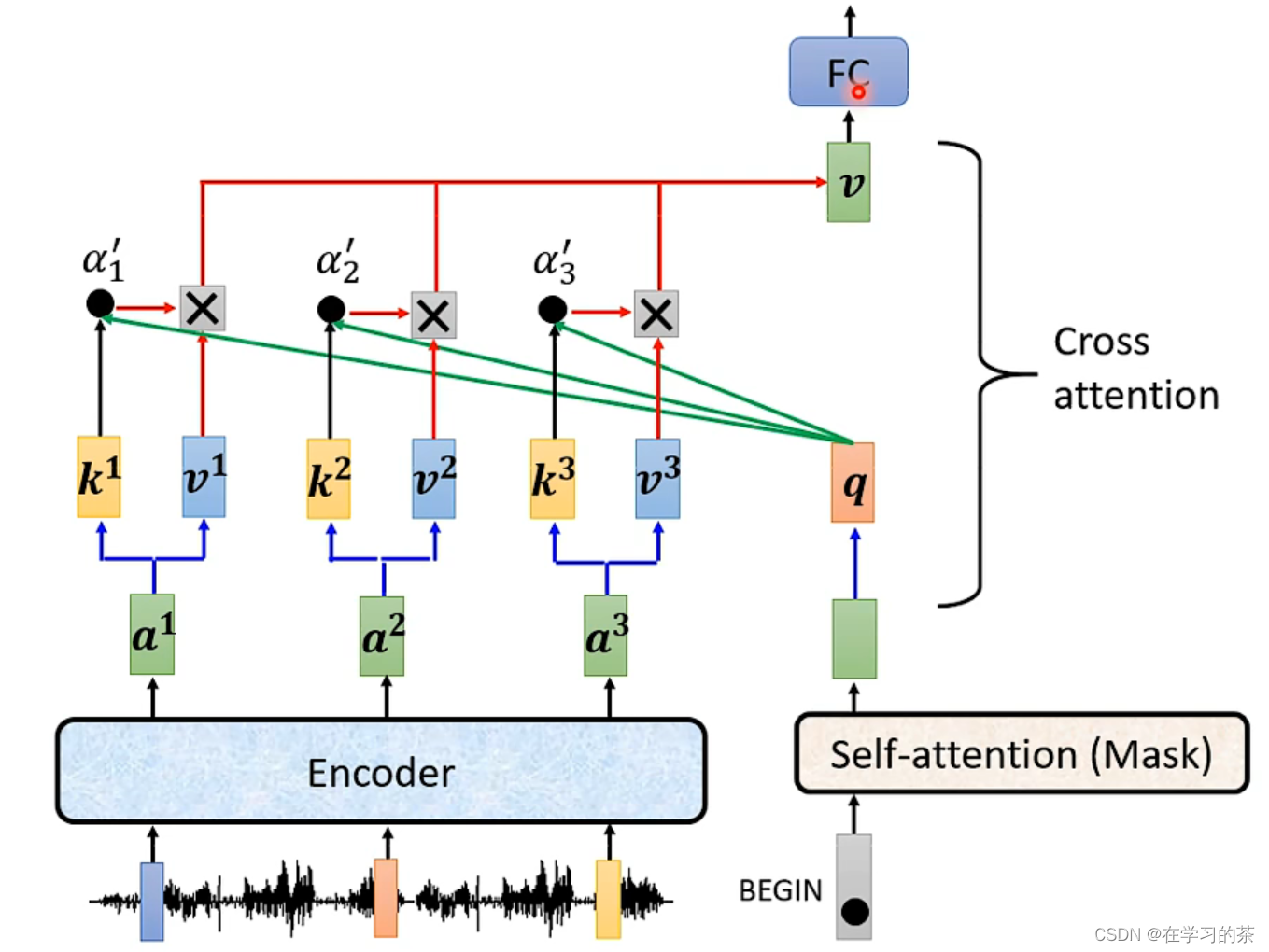
下面用语音辨识作为例子说明
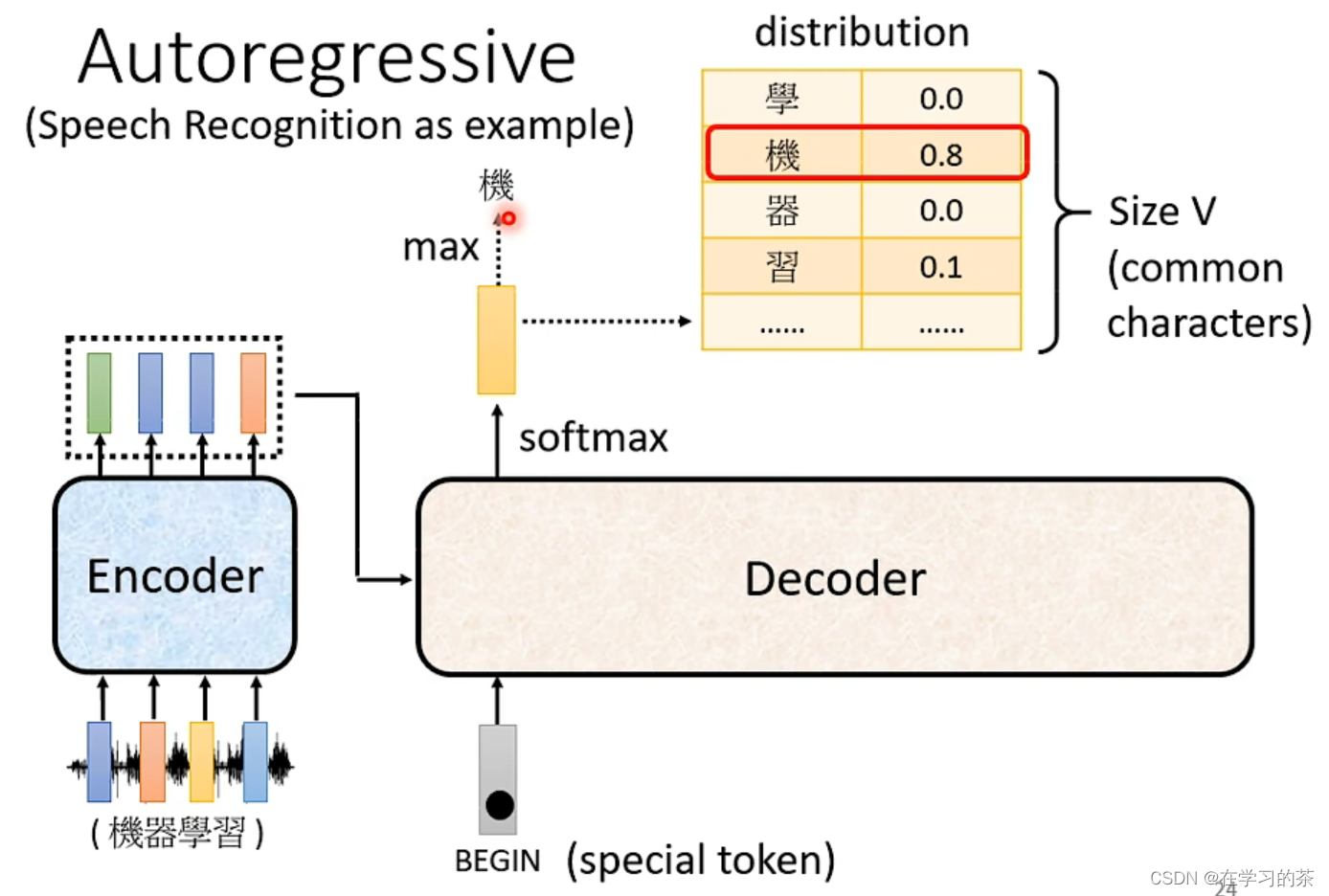
Encoder输出的是一段Vector,作为码传入Decoder
Decoder前需要一段BEGIN来开启Decoder
经过Decoder后再来一个softmax得出汉字出现的概率,选择概率最大的汉字进行输出
这里要注意了,下一个开始的符号是上一个输出的符号!!!
循环往复即可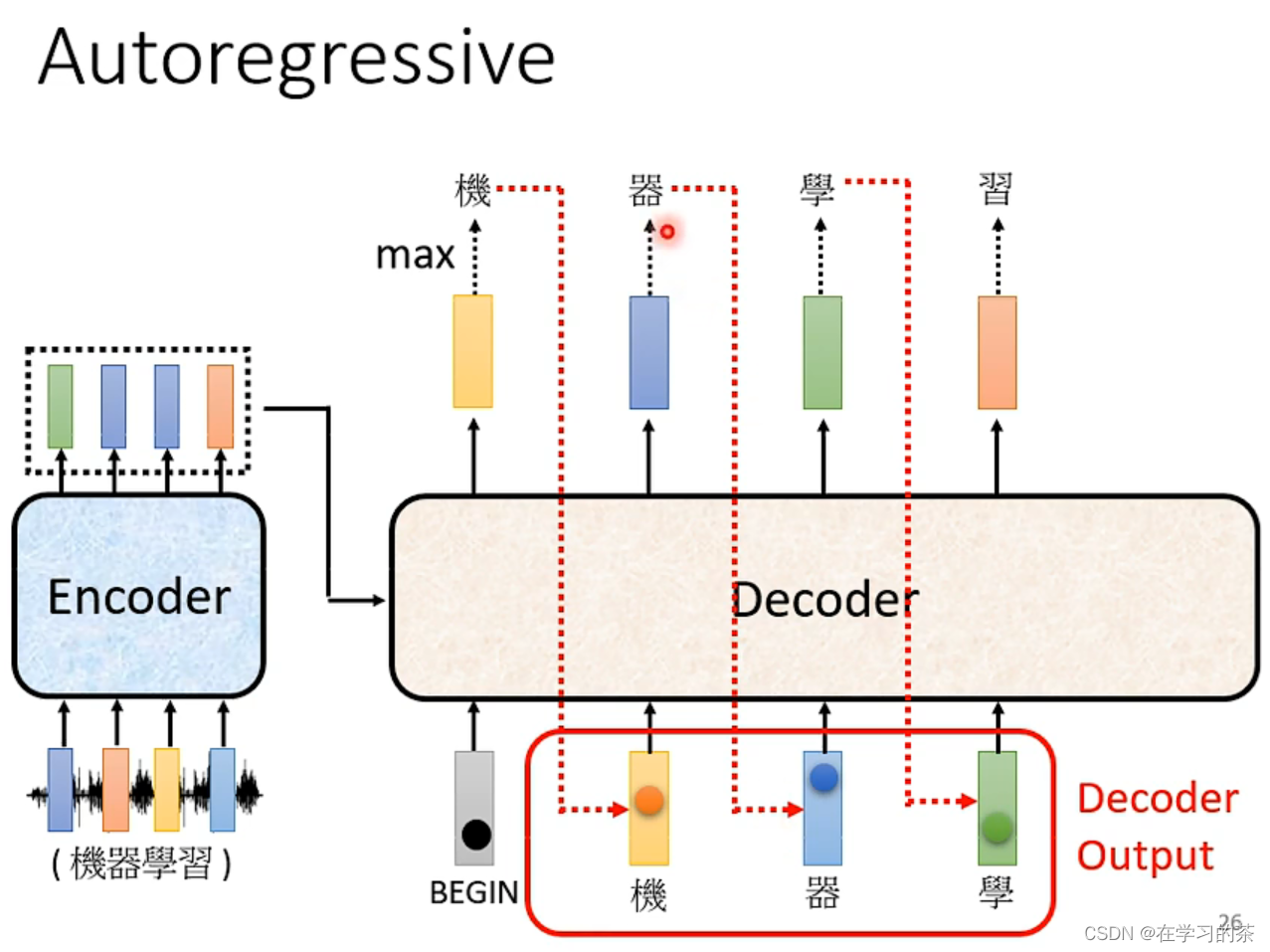
但是Decoder每次都要接受上一步的输出,那这样可能出现一步错、步步错的问题
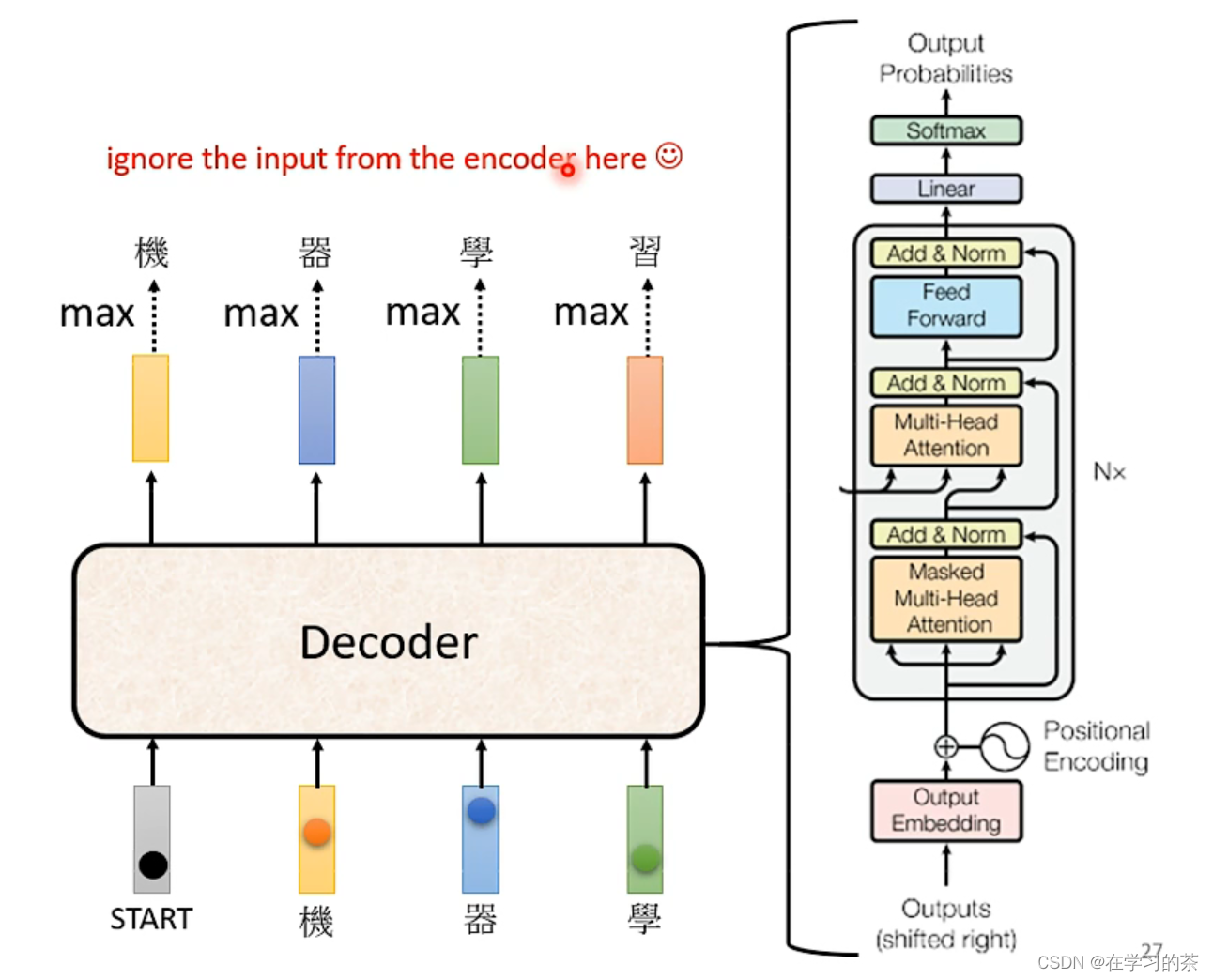
其实可以比一下Encoder
第二个attention的目的是接受输入的序列output,和这一步的输出拼起来,目的是看看之前!
先大概看一下Decoder的内部构造
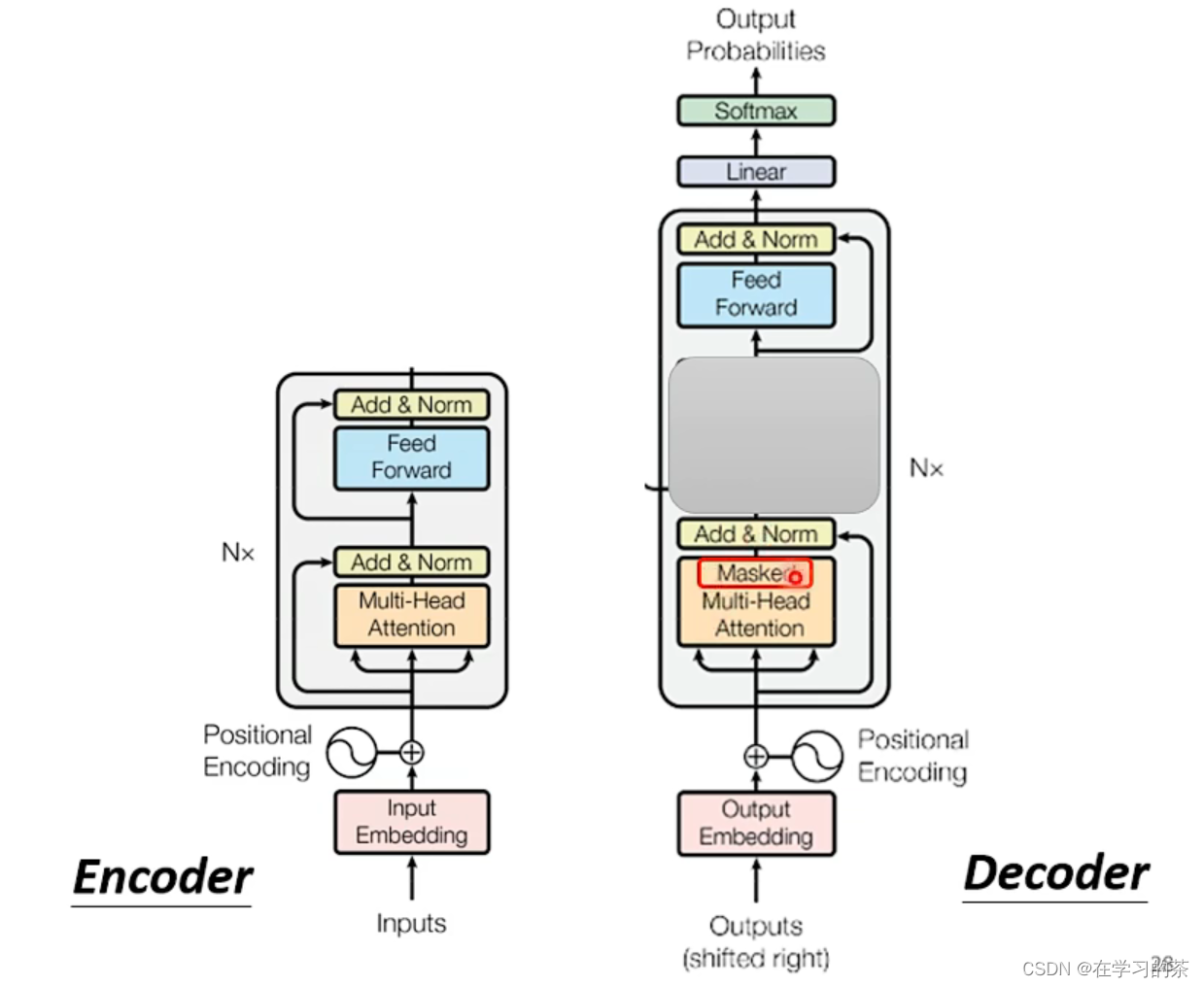
其实和Encoder很像欸有没有
不过这个Masked有点区别
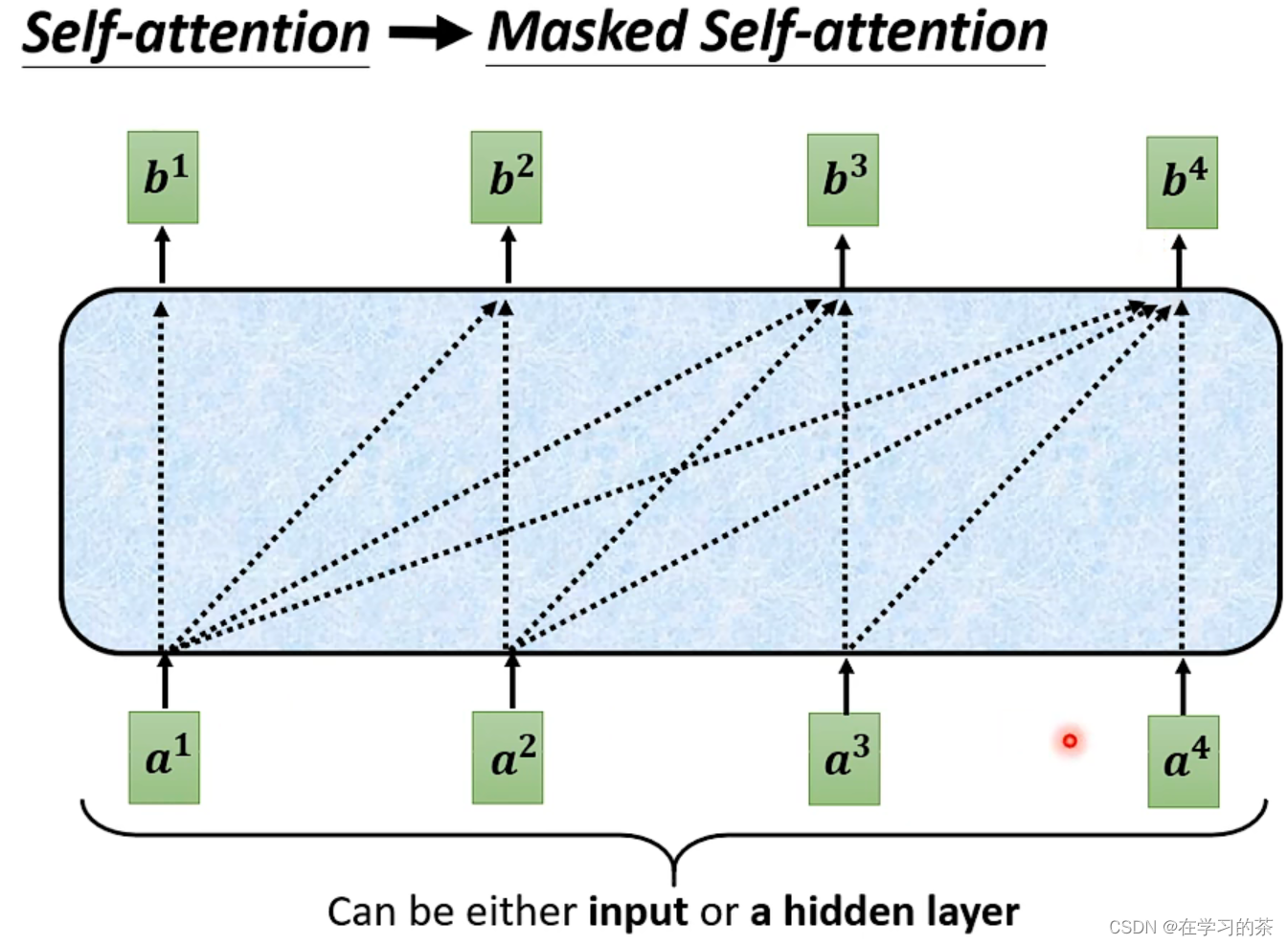
Masked sa是:只考虑以前的东西,如a1只考虑自己,a2只考虑a1,a2等等
这是因为Decoder必须先拿到a1,再来a2,他不能看到全部!!!

注意:最后还要输出一个终止符END,要不然都不会停止
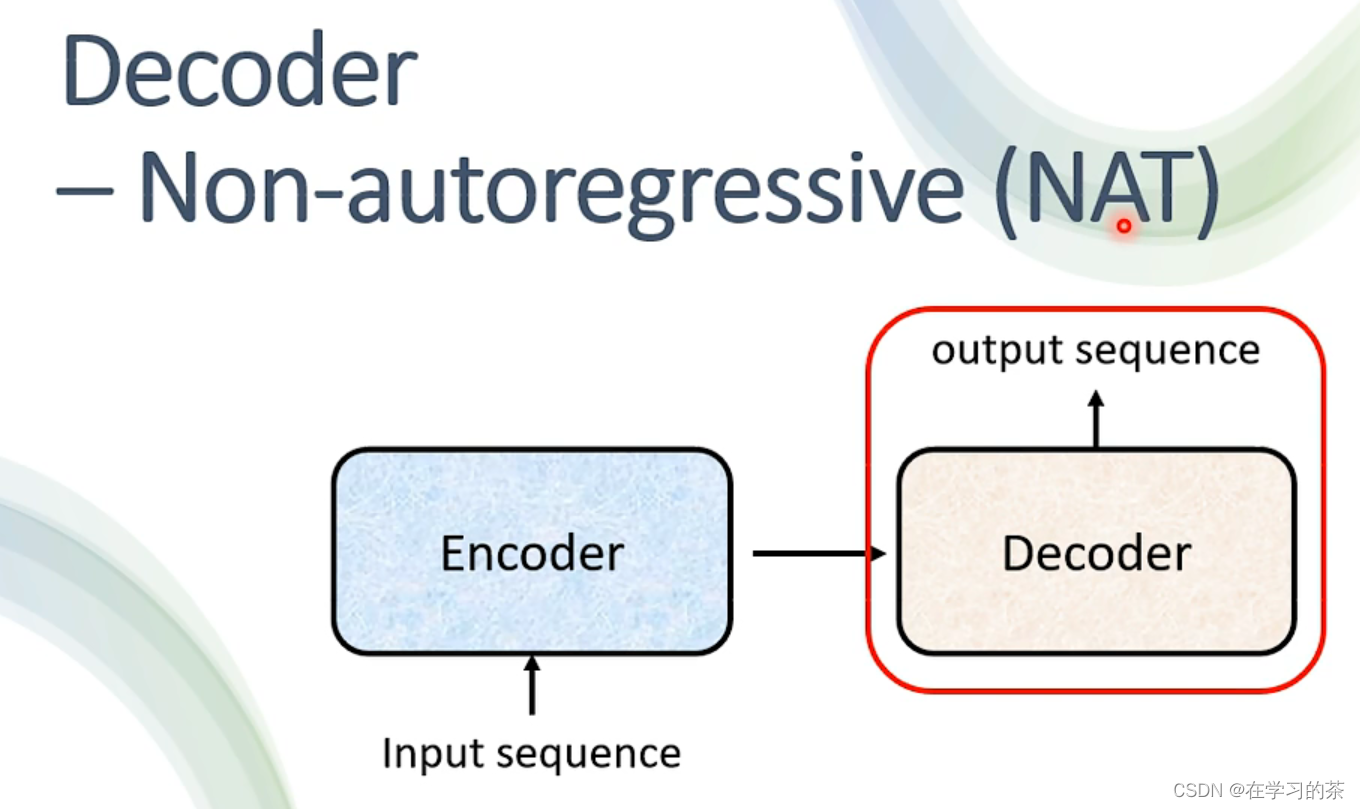
再换一个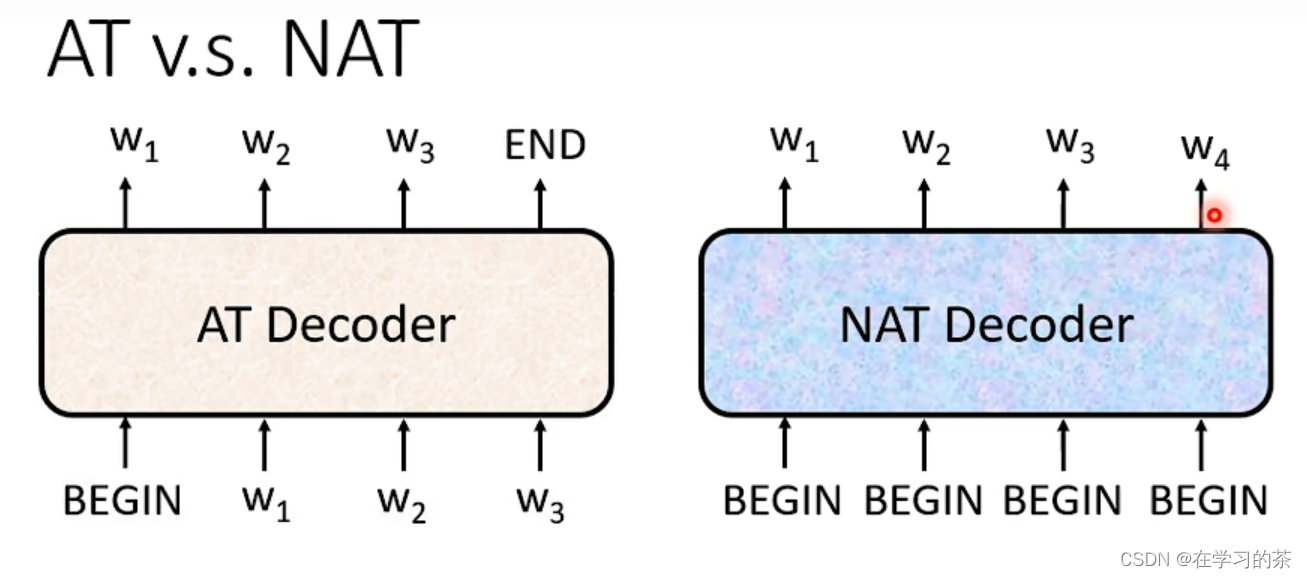
比较一下看看
那NAT要怎么看输出多长呢?也就是说怎么判断BEGIN的个数呢??
①搞一个计数器NetWork,计数器输出BEGIN的长度
②一直给BEGIN,直到输出了END停止
和AT比,NAT平行处理,速度较快
但是NAT效果往往不如AT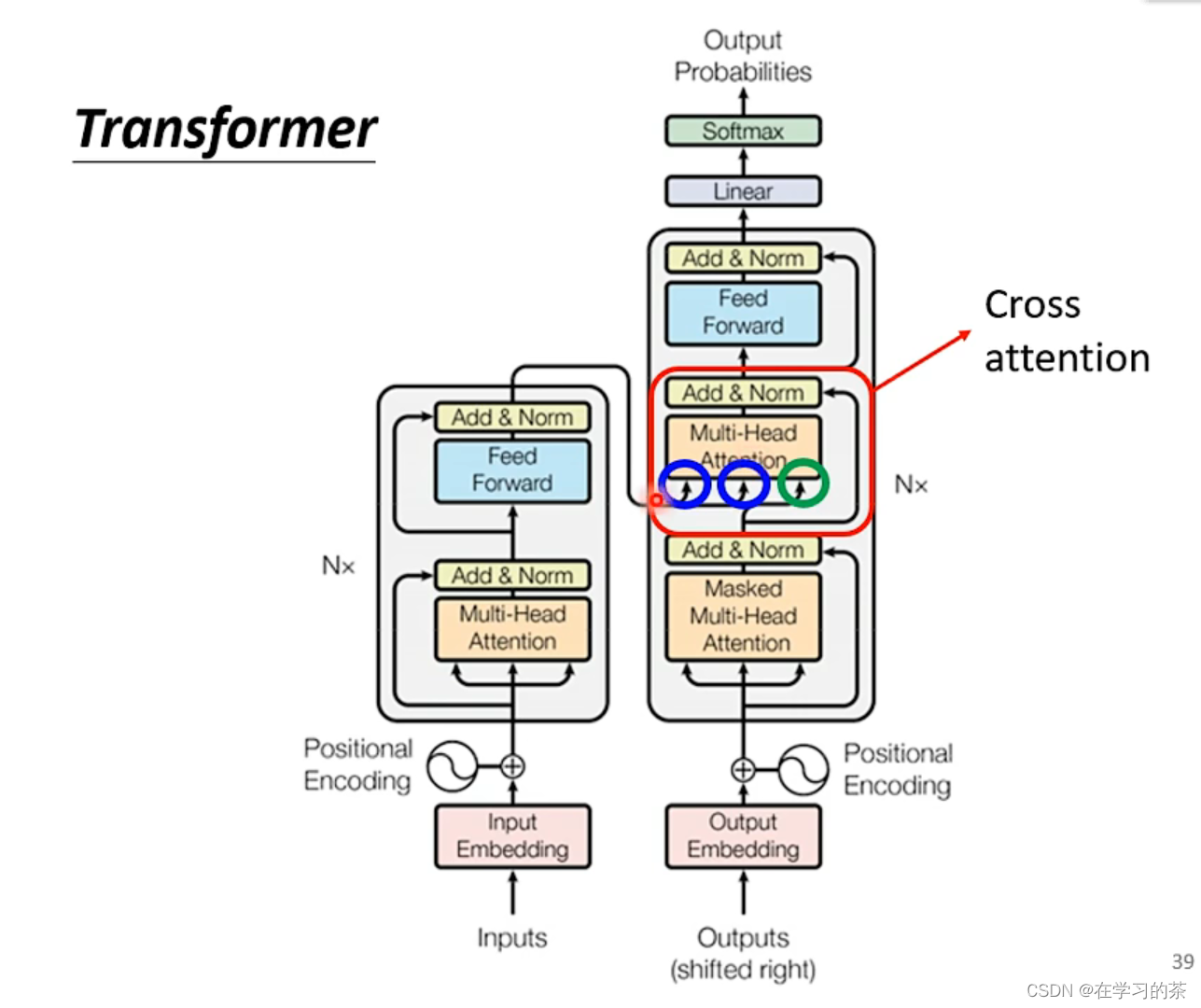
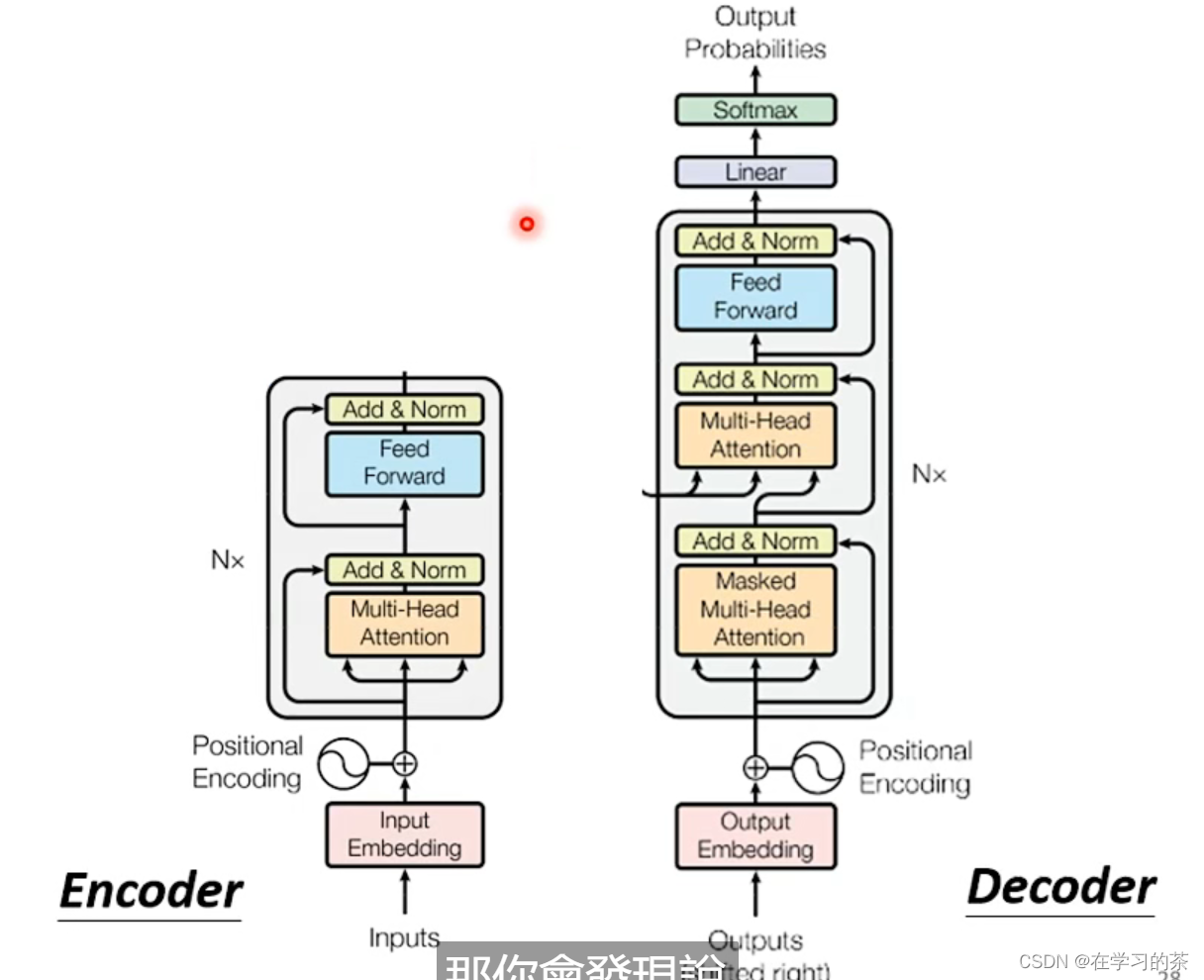
我们再来看看整体的连接部分。
也就是说这个连接了两个部分,
注意:因为是现在看之前,所以和之前Encoder的Vector拼起来之后,目前的一个作为Q,这就叫Cross-Attention,该元素的output含义就是,当前预测结构考虑原句意之后的下一个推断
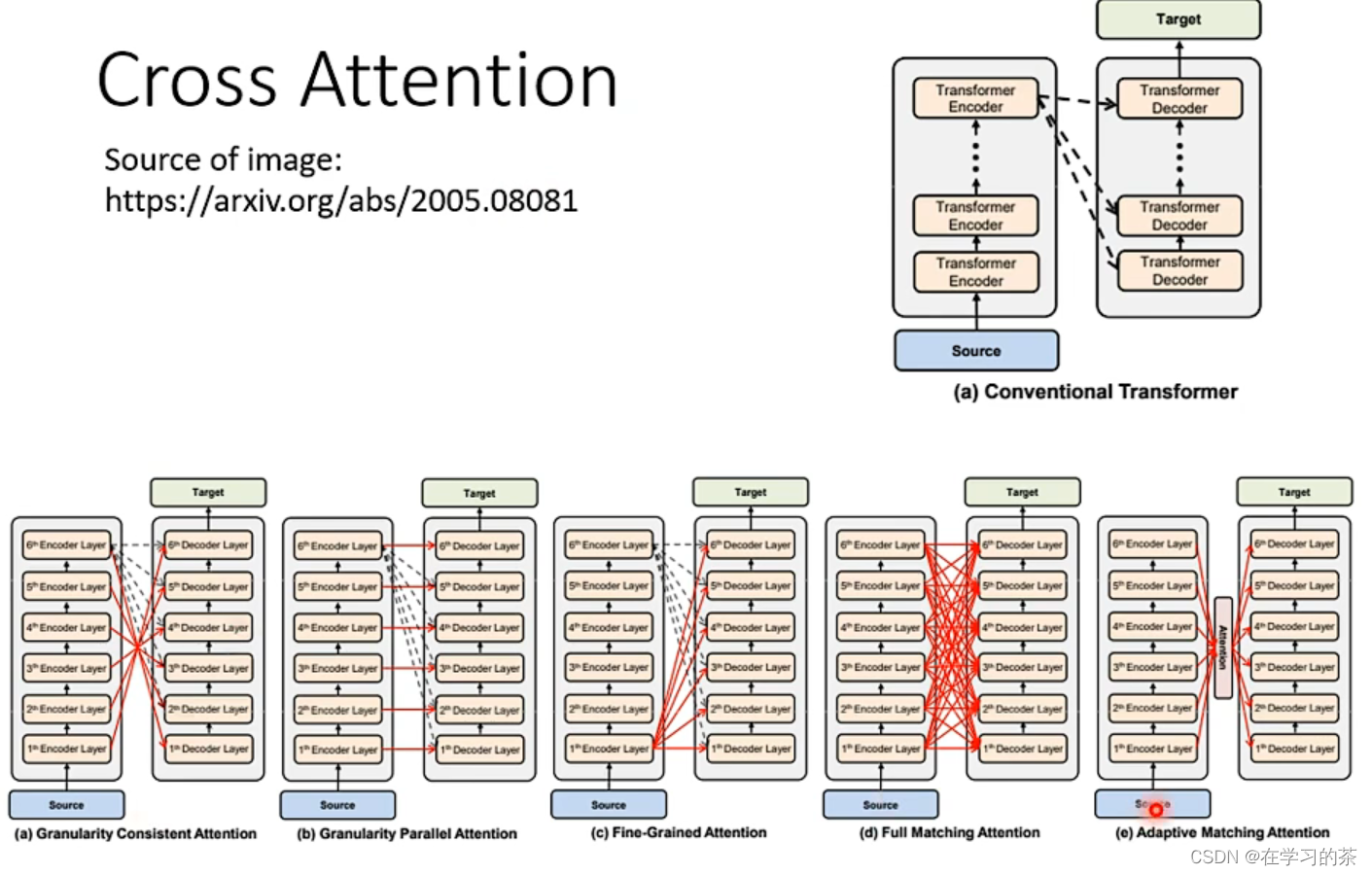
因为我们的Network是多层的,En-De的Cross-Attention也可以有多种
How To Train?
上述讲的都是Encoder&Decoder训练完成后的预测步骤
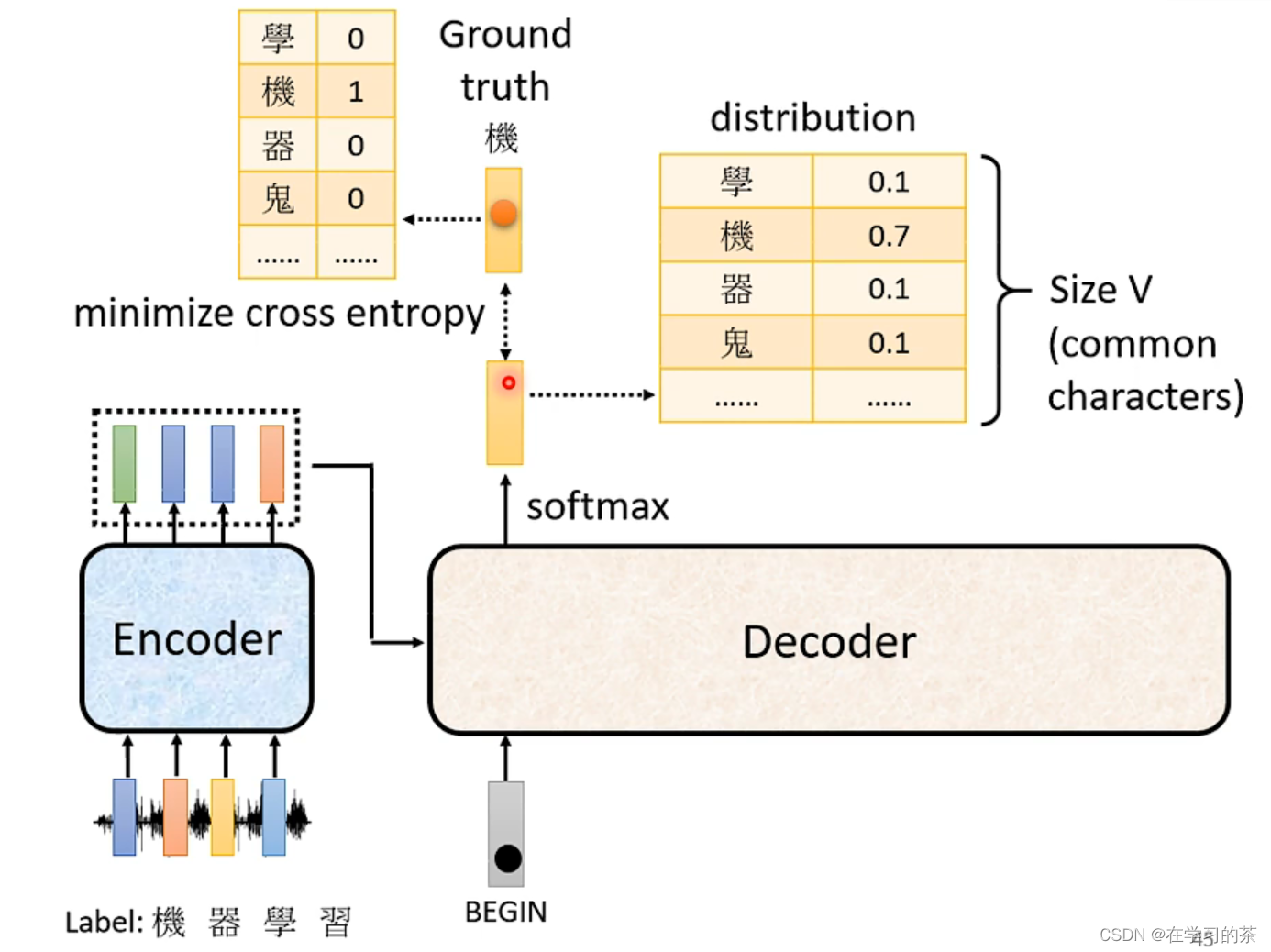
目的就是输出和Ground Truth最接近的向量,其实就和分类问题一样Classification。也用到了Cross entropy 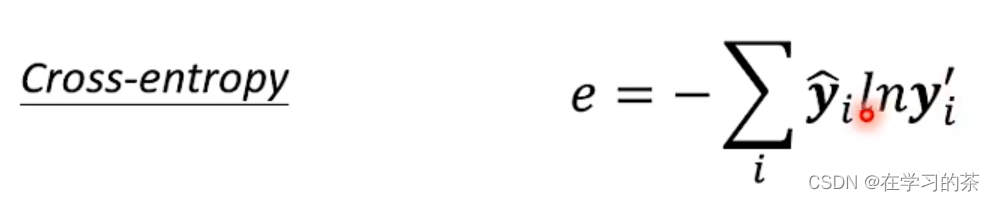
进行Loss的构造
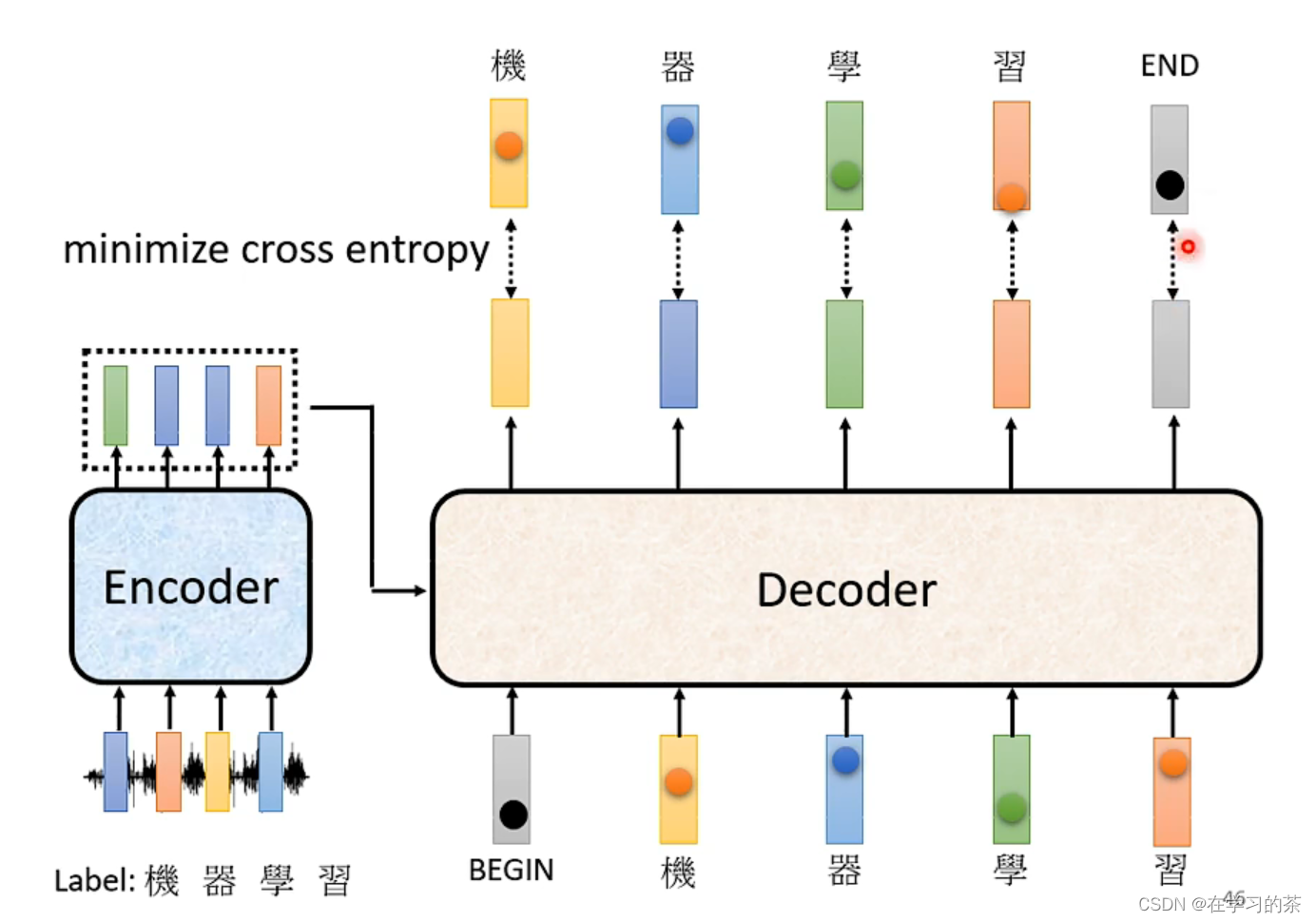
等于说训练的过程就是让Cross-entropy最小,不要忘记了END也要编码进行训练哦
记住,我们在训练的时候会给Decoder看正确答案 ,因为如果不给他看的话,本来就容易错,还要步步错
这个叫做Teacher Forcing:给Ground Truth训练

拷贝技能!!也就是我的输出会用到输入的部分原始内容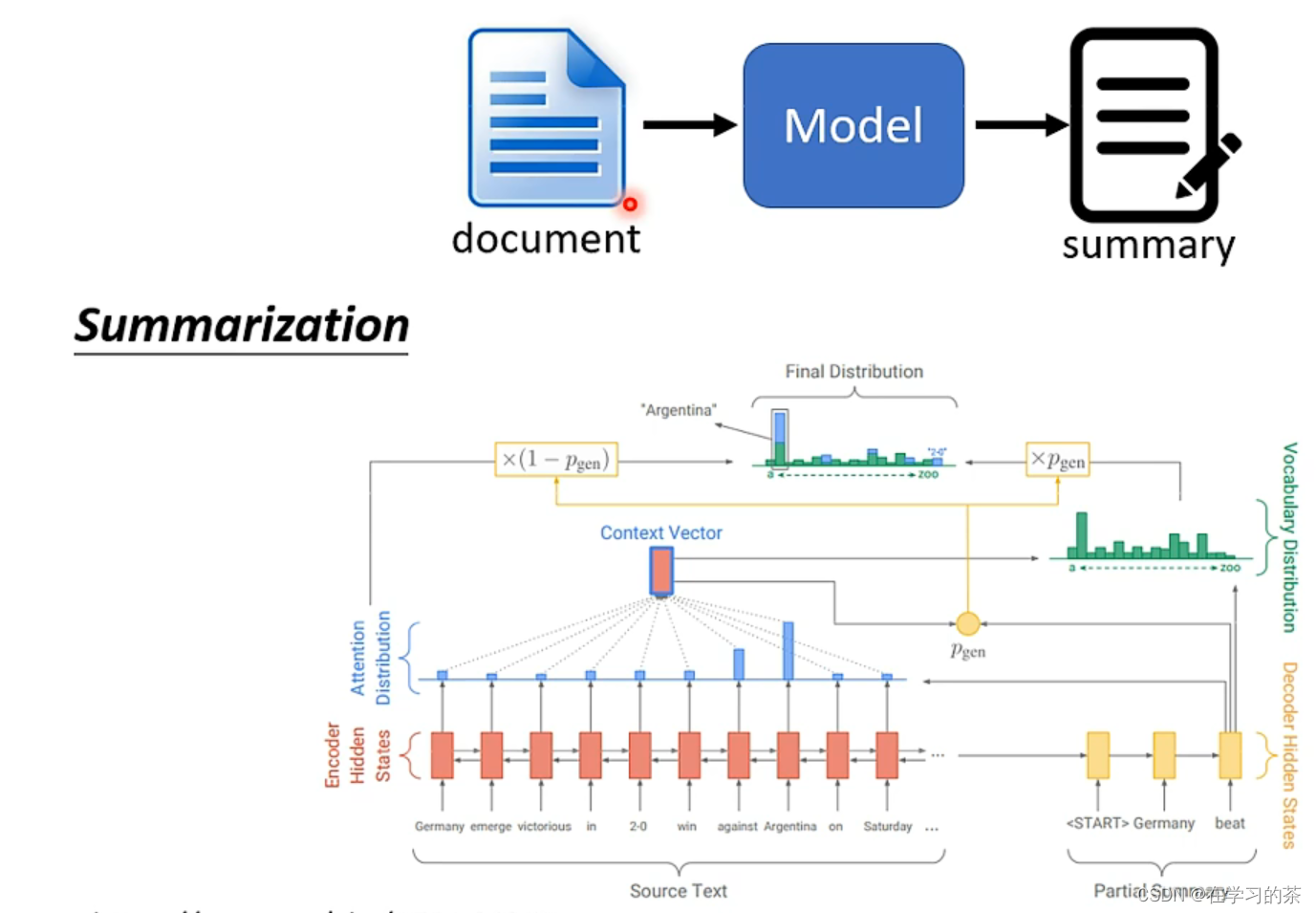
这个技能:Copy Mechanism也可以做论文的总结

想看就看!
Guided Attention
咱就是说,对于短序列的生成不是这么好,因为训练集的超短句,超长句太少了。
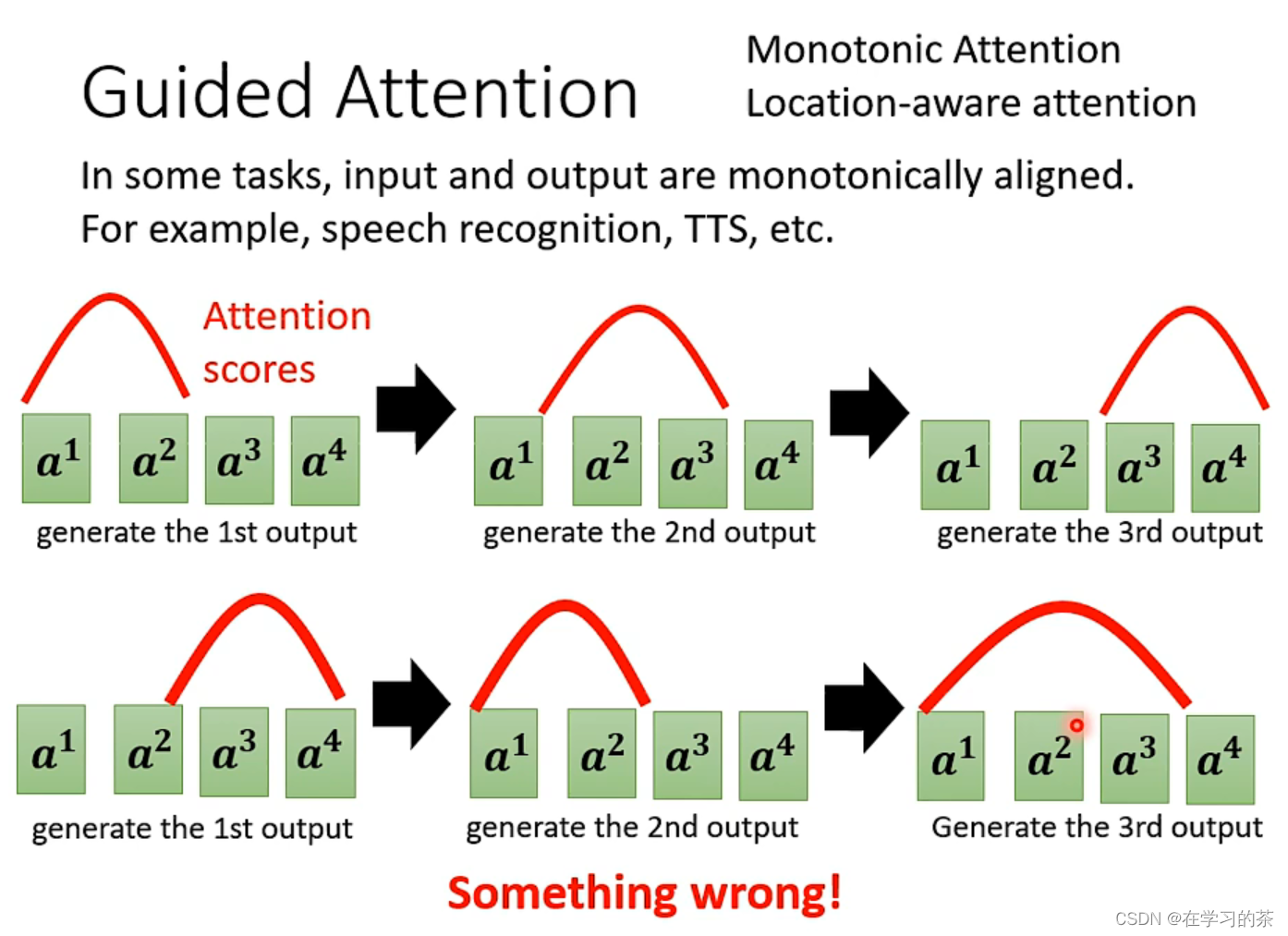
这个功能是:语音合成需要固定的发音顺序
那么我们需要固定Attention的高低曲线

这有个现象表明:虽然Beam Search得到的分数更好,但是很可能发生复读机现象,有时候我们不需要这一trick 。如果说语音辨识,答案唯一的时候,beamSearch往往更好,需要一些随机性的时候,最好不要。
有时候我们期待test数据加一定的随机性,可能会更好
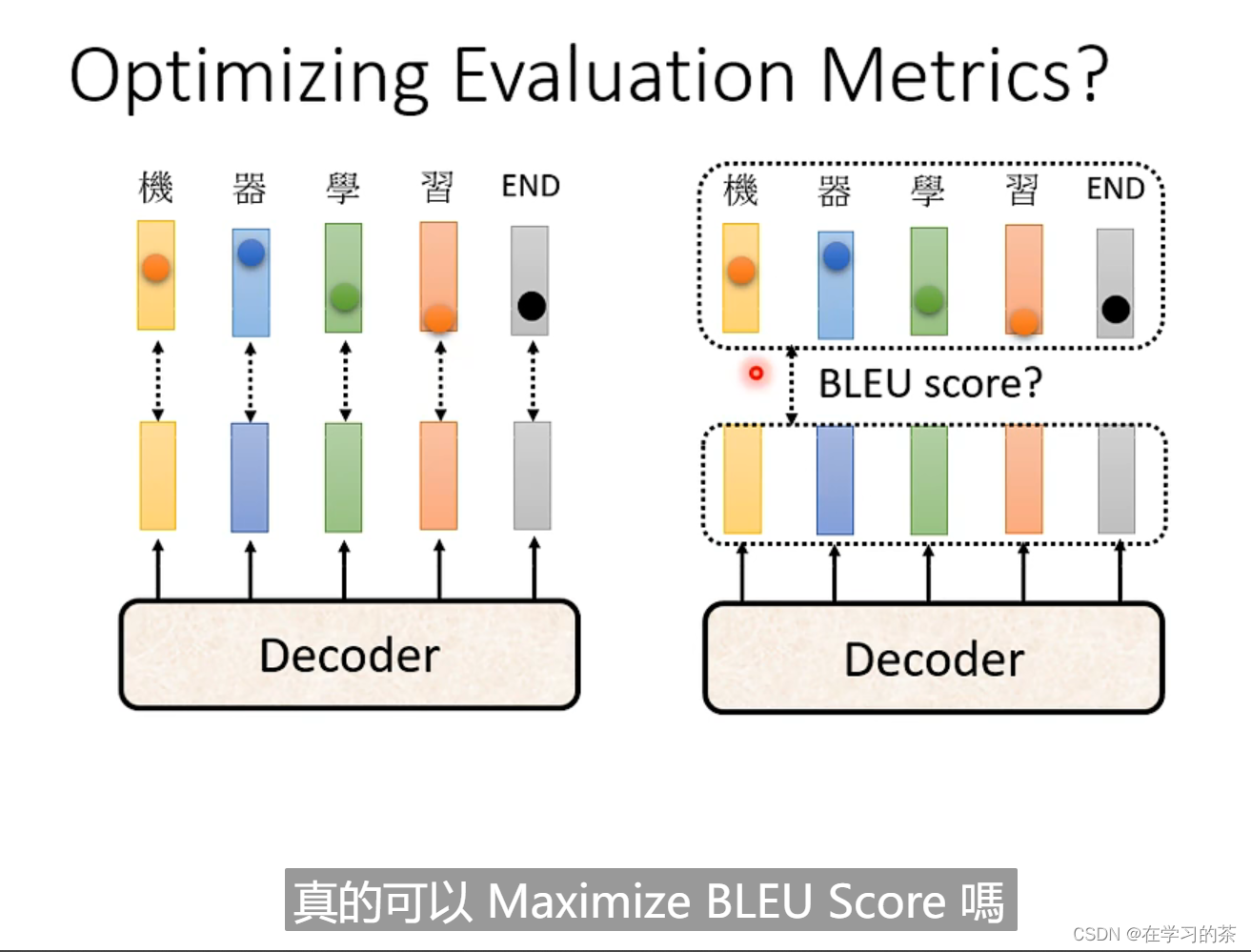

我们知道,在训练的时候,Loss是cross-entropy,但是在评估的时候用的是BLEU score 。根本上两个东西。
但是我们在训练的时候不可以作为Loss,因为BLEU scroe不能做微分!!
所以我们在做Optimization时,无法解决的话,用RL强化学习硬train就行了
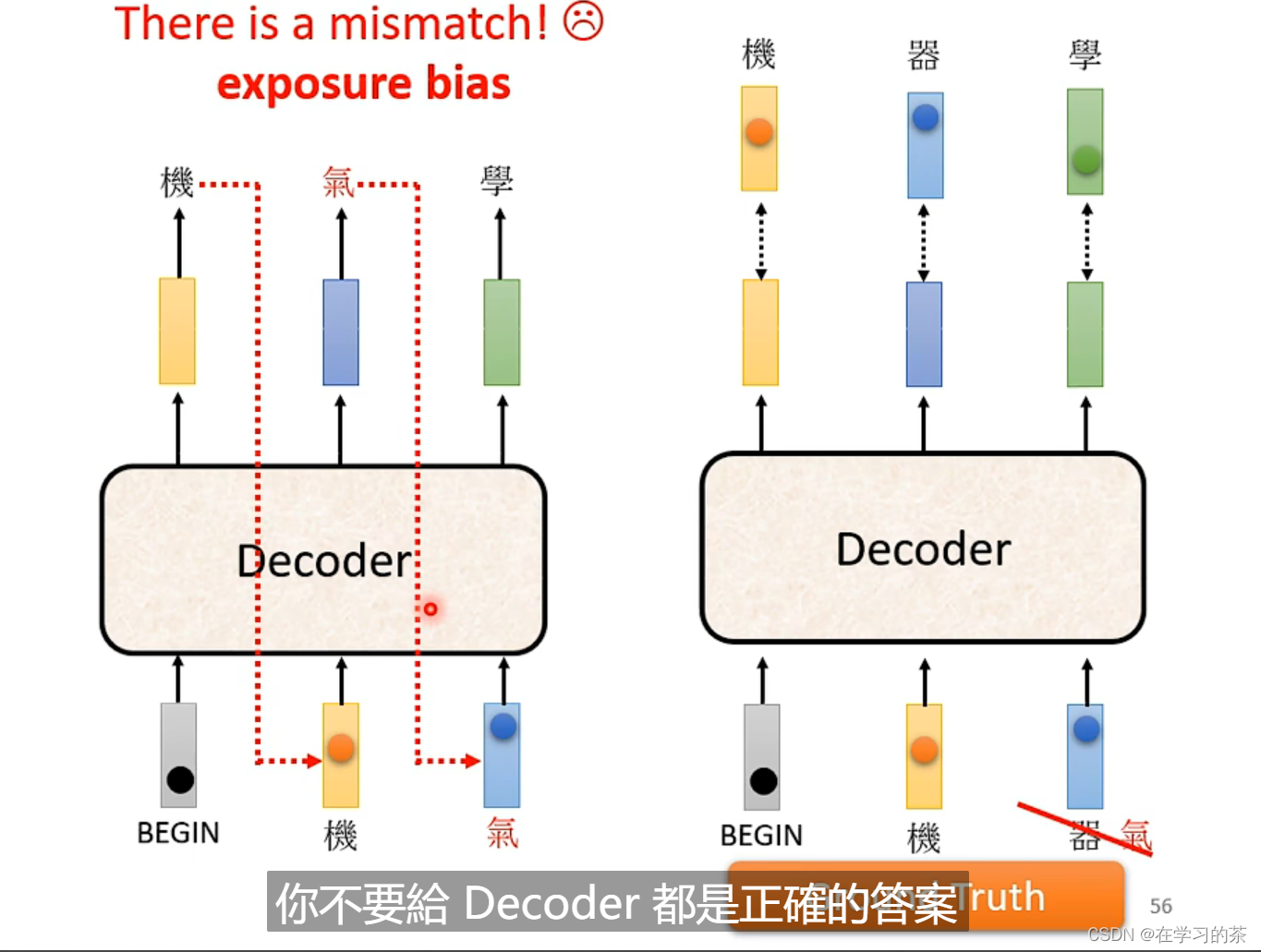
还有一个问题,你在训练的时候使用Ground Truth训练,那么test的时候万一前项错了,那么后面都错了!!
我们的应对方法就是 :不要给他全正确去train——Scheduled Sampling
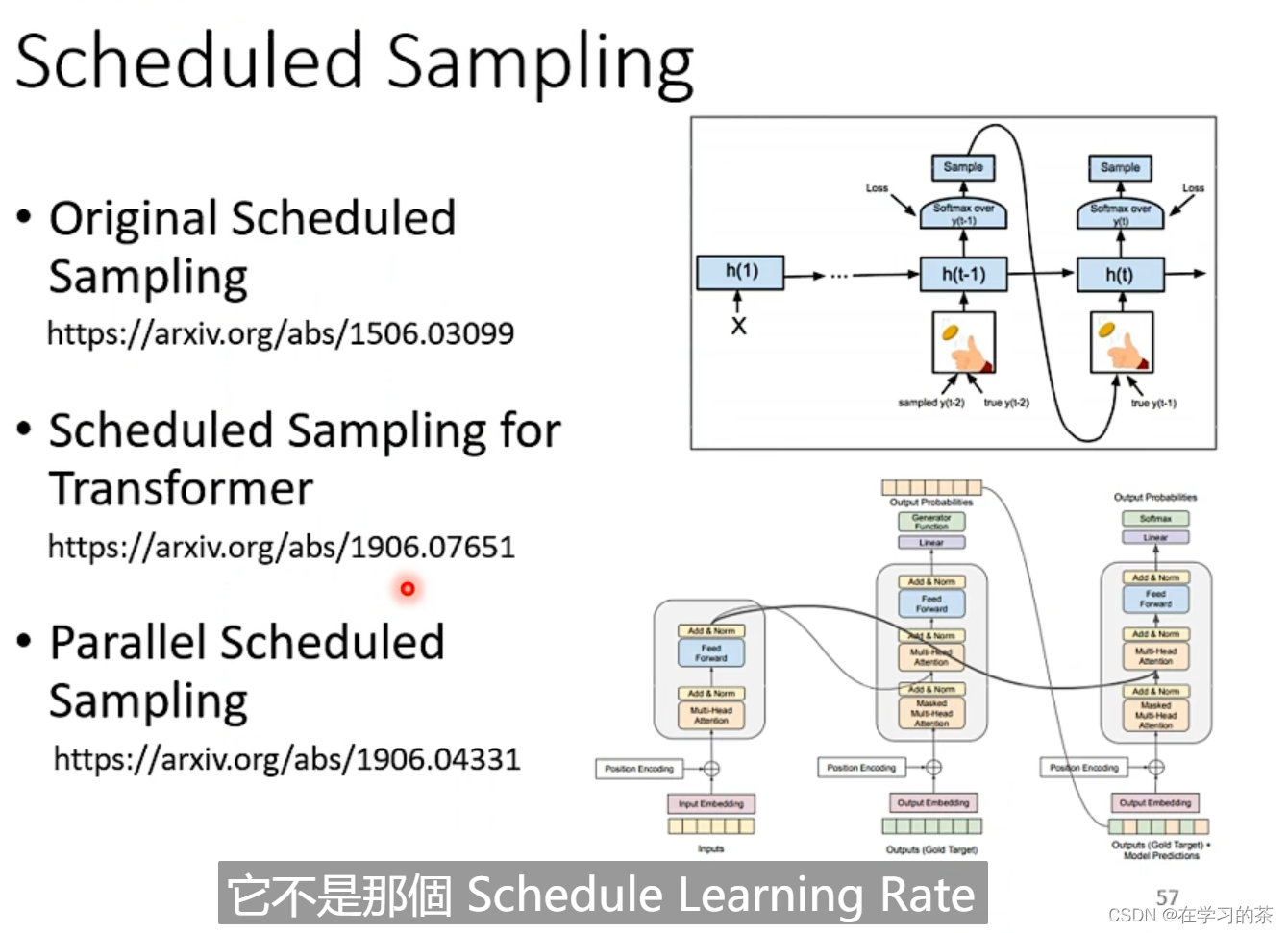
可以看看这些论文,但是对Transformer来说会减少平行运算的能力
怎么预测
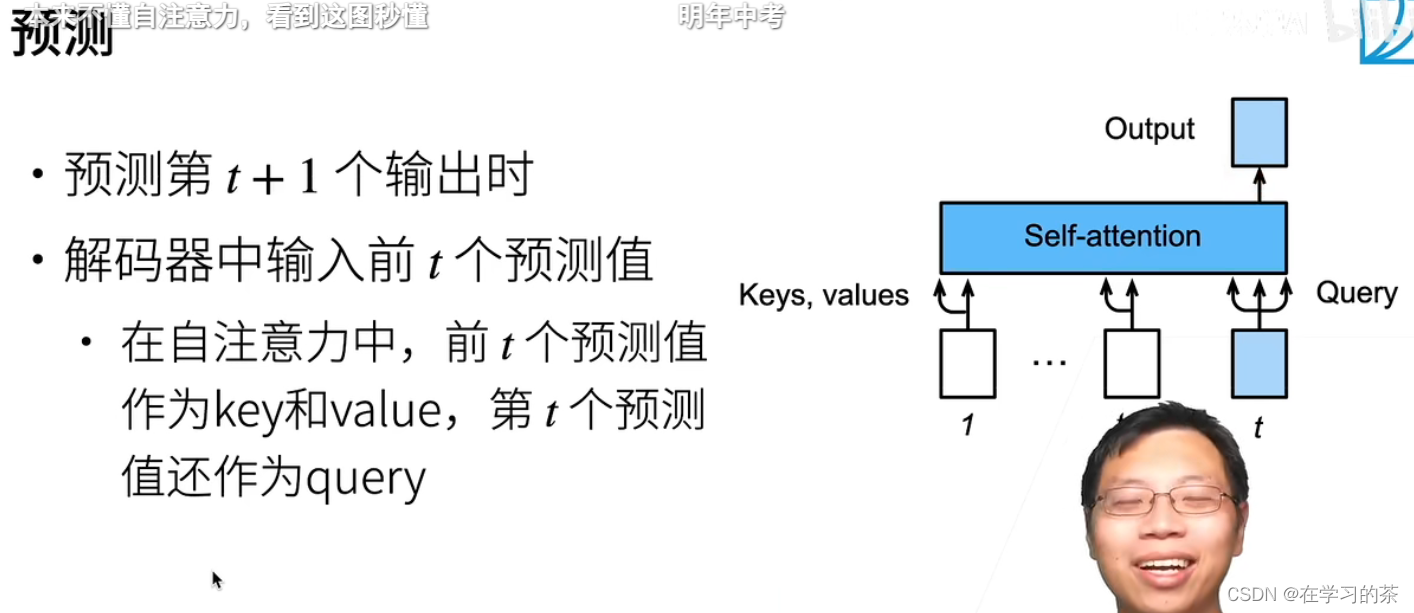
注意,预测的时候直接把序列丢到编码器,,,预测的输出作为KV,当前预测作为Q

















 1915
1915

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









