






 该博客围绕人工智能面试常见问题展开,涉及Python装饰器、生成器、迭代器,神经网络Dropout技术,C++多态、析构函数,梯度提升树等算法,图像比较方法,极大似然估计,ROIPooling和ROIalign区别,多种注意力机制,BN层优缺点,YOLO系列主干网络等内容。
该博客围绕人工智能面试常见问题展开,涉及Python装饰器、生成器、迭代器,神经网络Dropout技术,C++多态、析构函数,梯度提升树等算法,图像比较方法,极大似然估计,ROIPooling和ROIalign区别,多种注意力机制,BN层优缺点,YOLO系列主干网络等内容。
Q1: 什么是装饰器,什么是生成器,什么是迭代器?
装饰器(Decorator)是 Python 中一种特殊的函数,它可以用来修改其他函数的行为。装饰器本质上是一个函数,它接受一个函数作为输入,并返回一个新的函数作为输出。 通过装饰器,我们可以在不修改原函数代码的情况下,给函数添加额外的功能或者修改其行为。
生成器(Generator)是一种特殊的迭代器,它可以在循环的过程中动态生成值,而不需要一次性将所有值存储在内存中。 生成器使用 yield关键字来实现,每次调用生成器的 next() 方法或者使用 for 循环时,生成器会生成下一个值并暂停,直到下一次调用或循环终止。
迭代器(Iterator) 是一种可以逐个访问元素并支持惰性计算的对象。 迭代器必须实现 iter() 和 next()方法,其中 iter() 返回迭代器对象自身,而 next()返回下一个元素。迭代器可以用于循环遍历容器对象(如列表、字典等),并且可以节省内存空间,因为它们在需要时才计算元素值。
定义一个装饰器函数
def my_decorator(func):
def wrapper():
print("Something is happening before the function is called.")
func()
print("Something is happening after the function is called.")
return wrapper
使用装饰器修饰函数
@my_decorator
def say_hello():
print("Hello!")
调用被装饰后的函数
say_hello()
>>>
Something is happening before the function is called.
Hello!
Something is happening after the function is called.
生成器示例:
定义一个生成器函数
def my_generator():
for i in range(5): # 在循环的过程中动态生成值
yield i
使用生成器函数
gen = my_generator()
循环遍历生成器产生的值
for value in gen:
print(value)
生成器表达式:类似于列表推导式,生成器表达式是一种简洁的语法,用于创建生成器。它使用圆括号而不是方括号,并在内部使用 (value for item in iterable) 的形式。
gen = (x for x in range(3))
生成器对象方法:某些Python内置对象具有返回生成器的方法,例如 dict.items(), set.intersection(), enumerate(), 等等。
my_dict = {'a': 1, 'b': 2, 'c': 3}
gen = my_dict.items()
迭代器示例:
定义一个迭代器类
class MyIterator:
def __init__(self, max_count):
self.max_count = max_count
self.current = 0
def __iter__(self):
return self
def __next__(self):
if self.current < self.max_count:
self.current += 1
return self.current
else:
raise StopIteration
使用迭代器
my_iter = MyIterator(5)
循环遍历迭代器产生的值
for value in my_iter:
print(value)
>>>
1
2
3
4
5
惰性求值(Lazy Evaluation)是一种编程语言中的计算策略,其特点是只有在需要值的时候才会进行计算。这种方式与及时求值(Eager Evaluation)相对,后者是在表达式被绑定到变量时立即计算其值。
在惰性求值中,表达式被保存为一个"延迟计算"的形式,直到真正需要获取其值时才被求值。这种方式可以带来一些优势,比如可以节省计算资源,因为只有在需要时才进行计算。另外,它也支持一些无限序列和懒加载数据结构,因为只有在需要时才会进行计算,而不是一次性计算整个序列。
Q1.5:Range和For的区别是什么?
对于 range() 函数,有几个注意点:(1)它表示的是左闭右开区间;(2)它接收的参数必须是整数,可以是负数,但不能是浮点数等其它类型;(3)它是不可变的序列类型,可以进行判断元素、查找元素、切片等操作,但不能修改元素;(4)它是可迭代对象,却不是迭代器。
可以获得迭代器的内置方法很多,例如 zip() 、enumerate()、map()、filter() 和 reversed() 等等。
在 for-循环 遍历时,可迭代对象与迭代器的性能是一样的,即它们都是惰性求值的,在空间复杂度与时间复杂度上并无差异。我曾概括过两者的差别是“一同两不同”:相同的是都可惰性迭代,不同的是可迭代对象不支持自遍历(即next()方法),而迭代器本身不支持切片(即__getitem__() 方法)。
有三种基本的序列类型:列表、元组和范围(range)对象,不可变序列类型:元组 /字符串/range
普通序列都支持的操作有 12 种。range 序列只支持其中的 10 种,不支持进行加法拼接与乘法重复。
>>> range(2) + range(3)
-----------------------------------------
TypeError Traceback (most recent call last)
...
TypeError: unsupported operand type(s) for +: 'range' and 'range'
>>> range(2)*2
-----------------------------------------
TypeError Traceback (most recent call last)
...
TypeError: unsupported operand type(s) for *: 'range' and 'int'
结论:range 是可迭代对象而不是迭代器;range 对象是不可变的等差序列。
Q2: Drop out是什么 在训练和测试时有何区别?如果测试时不用dropout会发生什么现象?
Dropout 是一种用于深度神经网络中的正则化技术,旨在减少过拟合(overfitting)的发生。在训练神经网络时,Dropout 随机地将网络中的一些单元(神经元)的输出设置为零,以一定的概率(通常在 0.2 到 0.5 之间)丢弃它们。这样做的效果是,在每次训练迭代中,网络的结构都会发生变化,这样可以减少神经元之间的依赖关系,从而提高模型的泛化能力。 在训练和测试时,Dropout 的行为有所不同:训练时的 Dropout:在训练时,Dropout 起作用,会随机地将一些神经元的输出设置为零。这样可以迫使网络学习更加鲁棒和健壮的特征,减少过拟合的风险
测试时的 Dropout:在测试时,不再需要使用 Dropout。此时,通常会将所有神经元的输出都保留,并将它们的输出值按照一定的比例进行缩放,以保持训练时的期望输出。这样可以保持网络的输出稳定性,使得模型在测试数据上有更好的性能。
在测试时不使用 Dropout 可能会导致模型性能下降,或者使得模型在新的、未见过的数据上的泛化能力较差。这是因为在训练过程中使用了 Dropout 技术,但在测试时却没有应用相同的 Dropout,导致了训练时和测试时神经元的行为不一致。
具体来说,如果在测试时不使用 Dropout,那么模型在训练过程中学到的特定的神经元的组合和权重可能会相互依赖,以适应训练数据的特定噪声和变化。这样的情况下,模型在测试时可能会过度依赖于这些特定的神经元组合,而不能很好地泛化到新的数据上,从而导致性能下降。另外,由于 Dropout在训练时会随机地丢弃一部分神经元的输出,这种随机性有助于模型学习到更加鲁棒的特征表示,减少过拟合的风险。如果在测试时不使用Dropout,那么模型可能会过度自信,认为所有神经元的输出都是可靠的,从而增加了过拟合的风险。
但由于随机地将一些神经元的输出设置为零,如果在测试时仍然使用Dropout,可能会导致网络的结构发生变化,而且输出值也经过了缩放,这可能会使得模型产生不稳定的预测结果。
因此,为了保持模型在测试时的性能和稳定性,通常会在测试时关闭 Dropout,并按照一定的缩放规则对神经元的输出值进行调整,具体而言,假设在训练时某个神经元的输出被保留的概率为 ( p ),那么在测试时,该神经元的输出值将按照 ( 1-p ) 的比例进行缩放以保持与训练时的期望输出值一致。
在神经网络的结构中,Dropout 操作通常是在激活函数之前应用的。
具体来说,Dropout 操作应用在激活函数之前的原因是为了在每一层的输入上施加噪声,以减少神经网络的过拟合风险。通过在每一层的输入中随机丢弃一部分神经元的输出,Dropout 可以迫使网络学习到更加鲁棒的特征表示,从而提高模型的泛化能力。
在应用激活函数之前使用 Dropout的另一个原因是为了确保激活函数的输入具有一定的随机性,以防止模型对特定的输入模式过度适应。这种随机性有助于提高模型的鲁棒性,减少过拟合的风险。
因此,通常情况下,在神经网络的结构中,Dropout 操作会在激活函数之前应用,以提高模型的泛化能力和鲁棒性。
Q2.5 什么是多态?
C++ 的三大特性通常指的是封装、继承和多态。这三个特性是面向对象编程中的基本概念,这三个特性共同构成了面向对象编程的基础,它们使得代码更加模块化、可扩展和易于维护。
封装(Encapsulation):封装是将数据和操作数据的方法(即函数)捆绑在一起的机制。通过封装,对象的内部细节被隐藏,只暴露出公共的接口供外部使用。这种方式可以保护数据不被直接访问和修改,提高代码的安全性和可维护性。
继承(Inheritance):继承是面向对象编程中的一种重要概念,它允许一个类(称为子类或派生类)继承另一个类(称为父类或基类)的属性和行为。通过继承,子类可以重用父类的成员变量和方法,并且可以添加新的成员变量和方法,从而实现代码的复用和扩展。
多态(Polymorphism):多态是指同一个函数名可以有多种形式,即一个函数可以有多个不同的实现方式。在 C++ 中,多态性通过函数重载(函数名相同,参数列表不同)和虚函数实现。在运行时,根据对象的实际类型来决定调用哪个函数版本,从而实现多态行为,提高代码的灵活性和可扩展性。
函数重载(Function Overloading)是指在同一个作用域内定义多个同名函数,但它们的参数列表(包括参数的类型、顺序或个数)不同。在调用时,编译器会根据实际传入的参数类型和个数来确定调用哪个重载函数。函数重载使得我们可以使用相同的函数名来执行不同的操作,提高了代码的可读性和灵活性。例如:
#include <iostream>
// 函数重载示例
void print(int x) {
std::cout << "Integer: " << x << std::endl;
}
void print(double x) {
std::cout << "Double: " << x << std::endl;
}
int main() {
print(5); // 调用 print(int)
print(3.14); // 调用 print(double)
return 0;
}
虚函数(Virtual Function)是指在基类中使用 virtual 关键字声明的成员函数,它可以被派生类重写(Override)。虚函数允许在运行时根据对象的实际类型来确定调用哪个版本的函数,从而实现多态性。在派生类中重写虚函数时,需要使用 override 关键字进行声明,以确保正确地覆盖基类中的虚函数。使用虚函数可以实现运行时多态性,提高了程序的灵活性和扩展性。例如:
#include <iostream>
// 基类
class Animal {
public:
// 虚函数
virtual void makeSound() {
std::cout << "Animal makes a sound" << std::endl;
}
};
// 派生类
class Dog : public Animal {
public:
// 重写基类的虚函数
void makeSound() override {
std::cout << "Dog barks" << std::endl;
}
};
// 派生类
class Cat : public Animal {
public:
// 重写基类的虚函数
void makeSound() override {
std::cout << "Cat meows" << std::endl;
}
};
int main() {
Animal* animal1 = new Dog();
Animal* animal2 = new Cat();
animal1->makeSound(); // 调用 Dog 的 makeSound()
animal2->makeSound(); // 调用 Cat 的 makeSound()
delete animal1;
delete animal2;
return 0;
}
Q3: 析构函数是什么?析构函数的子类可以从父类继承吗?
子类会继承父类的析构函数,但并不是通过继承其实现。当子类的对象销毁时,会先调用子类的析构函数,然后再调用父类的析构函数。这种顺序确保了对象的析构顺序与构造顺序相反。
如果父类有虚析构函数(通过在析构函数前面加上 virtual关键字),那么子类也会继承这个虚析构函数。这是为了实现多态性,确保在使用基类指针指向派生类对象时正确地释放资源。
构造函数(Constructor)是一种特殊的方法,用于在创建对象时进行初始化操作。在面向对象编程中,通常每个类都可以有一个构造函数。构造函数的作用是初始化对象的状态,为对象的属性赋予初始值,以确保对象在创建后处于一个合适的状态。
在继承关系中,子类可以继承父类的属性和方法,但是构造函数却不能直接继承。这是因为构造函数的特殊性质,它在对象创建时被调用,用于初始化该对象的状态。当子类继承父类时,子类可以使用父类的属性和方法,但是子类的构造函数需要负责初始化子类自己的属性,而不能直接继承父类的构造函数。
通常情况下,如果子类没有定义自己的构造函数,那么会隐式地调用父类的构造函数来初始化子类的实例。但是如果子类定义了自己的构造函数,那么子类的构造函数就会覆盖父类的构造函数,这样父类的构造函数就无法被子类直接继承和使用了。
在一些编程语言中,可以通过在子类的构造函数中显式调用父类的构造函数来实现一定程度的继承。比如在Java中,可以使用super()来调用父类的构造函数。但是这种调用是显式的,而不是继承的方式。
构造函数:子类不能继承父类的构造函数。子类必须自己定义构造函数,并且在其初始化列表中调用父类的构造函数来初始化继承的成员变量。
当子类没有定义自己的构造函数时,它会隐式地继承父类的构造函数。这里有一个简单的Python示例,说明了子类继承父类构造函数的情况:
class Animal:
def __init__(self, species):
self.species = species
def speak(self):
print("I am an", self.species)
class Dog(Animal):
def bark(self):
print("Woof!")
#创建一个Dog的实例
dog = Dog("Canine")
dog.speak() # 输出: I am an Canine
在这个例子中,Animal类有一个构造函数__init__(),用于初始化species属性。Dog类继承了Animal类,但是没有定义自己的构造函数。因此,当创建Dog类的实例时,会隐式地调用Animal类的构造函数来初始化实例。这样,Dog类的实例就可以访问species属性,并调用Animal类的方法。
接下来,我们看一个子类定义了自己构造函数的情况:
class Animal:
def __init__(self, species):
self.species = species
def speak(self):
print("I am an", self.species)
class Dog(Animal):
def __init__(self, breed):
self.breed = breed
def bark(self):
print("Woof!")
#创建一个Dog的实例
dog = Dog("Labrador")
dog.speak() # 这里会出现错误,因为Dog类的构造函数没有初始化species属性
Q4: 什么是梯度提升树(GBDT);与XgBoost的区别是什么;与随机森林的区别是什么?
梯度提升树(Gradient Boosting DecisionTree,简称GBDT)是一种集成学习方法,用于解决回归和分类问题。它通过逐步构建多个决策树,并利用梯度提升的方式来提升模型性能。具体来说,GBDT是通过迭代训练决策树,每一棵树都试图修正前面所有树组合的残差(或梯度),从而逐步改进模型的预测能力。
GBDT的基本原理是,首先训练一个基本的决策树模型,然后根据当前模型的表现,调整样本的权重或者残差,接着训练下一个决策树,如此循环迭代,直到达到预定的迭代次数或者模型性能满足某个条件为止。最终,将所有决策树的预测结果加权求和,得到最终的集成模型。
XGBoost(eXtreme GradientBoosting)是GBDT的一种扩展,它在原始GBDT的基础上进行了一系列改进和优化,以提高模型的性能和效率。XGBoost相比于传统的GBDT有以下几个区别:
- 正则化: XGBoost引入了正则化项,包括L1正则化(Lasso)和L2正则化(Ridge),用于控制模型的复杂度,防止过拟合。
- 损失函数: XGBoost支持多种损失函数,如回归问题可以选择平方损失或者绝对损失,分类问题可以选择对数损失或者指数损失等,灵活性更强。
- 特征列采样: XGBoost支持对特征列进行采样,防止模型过拟合,提高模型的泛化能力。 并行计算: XGBoost使用了一种称为Block
- Structure的数据存储结构和相应的多线程算法,以便在训练过程中进行高效的并行计算,提高了训练速度。 缺失值处理:
- XGBoost能够自动处理输入数据中的缺失值,无需对缺失值进行额外处理。
总的来说,XGBoost相对于传统的GBDT在模型性能、效率和功能方面都有所提升,因此在实际应用中更为常用。
在梯度提升(Gradient Boosting)算法中,我们通常使用决策树作为基本的弱学习器。该算法的核心思想是迭代地训练一系列的决策树,每个新的决策树都尝试修正前面所有树的预测结果与真实观测值之间的差异(残差)。
具体来说,在梯度提升的每一轮迭代中,我们计算当前模型的预测值与真实观测值之间的残差,然后训练一个新的决策树模型来拟合这些残差。新的决策树模型被设计为尽可能减小这些残差,以此逐步改进整体模型的预测性能。这个过程重复进行多轮,直到达到预设的停止条件。
调整样本的权重是另一种优化算法,通常在一些集成方法中被使用,例如AdaBoost。在AdaBoost算法中,每个样本都有一个权重,初始时都被赋予相等的权重。在每一轮训练中,
算法会根据上一轮的结果调整样本的权重,使得上一轮被错误分类的样本在下一轮得到更多的关注。 这样,后续的模型就会更专注于那些之前分类错误的样本,从而逐步提高整体模型的性能。总的来说,残差是评估模型拟合程度的一种度量,而调整样本权重是一种优化算法,用于在迭代训练中重点关注之前分类错误的样本,以提高模型的性能。在梯度提升算法中,通常使用残差来训练新的基本模型,而在AdaBoost等算法中则使用样本权重的调整来优化模型。
随机森林(Random Forest)和梯度提升树(Gradient BoostingTrees)都是常用的集成学习算法,它们有一些显著的区别:
- 算法原理:
随机森林是一种基于决策树的集成学习算法,它通过构建多棵决策树,并将它们的结果进行投票或平均来进行最终预测。每棵树的构建过程中会使用随机抽样的训练数据和随机选择的特征。
梯度提升树是一种通过迭代地训练决策树来提高模型性能的算法。它通过逐步减小残差(预测值与真实值之间的差异)来训练新的决策树,并将多棵树的结果进行加权求和来进行最终预测。- 集成方式:
随机森林是一种被称为“装袋法”(Bagging)的集成学习方法,它通过对训练数据进行随机抽样来生成多个子数据集,然后基于每个子数据集构建一棵决策树,最后将所有决策树的结果进行组合。
梯度提升树是一种被称为“提升法”(Boosting)的集成学习方法,它通过串行地训练决策树来改进模型的性能,每个新的决策树都是在前一棵决策树的残差基础上进行训练。- 模型性能: 随机森林通常具有良好的泛化能力,对于高维度数据和大规模数据集表现较好,且相对不易过拟合。
梯度提升树在一般情况下能够获得更高的预测性能,尤其适用于处理结构化数据和表征学习任务。- 调参复杂度:
随机森林相对来说参数较少,调参相对简单,一般来说,只需调整树的数量和每棵树的最大深度等参数。
梯度提升树需要调整的参数相对较多,比如学习率、树的数量、树的深度、子采样率等,调参相对复杂。
总的来说,随机森林适用于处理大规模数据集和高维度特征,而梯度提升树则在一般情况下能够提供更好的预测性能,但对参数调整和计算资源的要求较高。选择哪种算法取决于数据集的特征、任务的需求以及可用的计算资源。
Q4.5 了解python中的多线程机制吗?
在Python中,多线程机制通过内置的threading模块实现。threading模块允许你创建和管理线程,以便在同一进程内执行多个任务。下面是使用threading模块实现多线程的基本步骤:
import threading
#定义线程执行的函数: 创建一个函数,作为线程执行的任务。
def task():
print("Executing task...")
#创建线程对象: 使用Thread类创建线程对象,传入要执行的函数作为参数。
thread = threading.Thread(target=task)
#启动线程: 调用线程对象的start()方法启动线程,开始执行任务。
thread.start()
#等待线程结束: 可以使用join()方法等待线程执行完毕。
thread.join()
需要注意的是,Python中的多线程实际上是基于操作系统的原生线程实现的,而Python解释器中的全局解释锁(GIL)限制了同一时刻只能有一个线程执行Python字节码 (源代码也会被编译成字节码,然后由Python解释器执行)。因此,Python的多线程通常适用于I/O密集型任务,而对于CPU密集型任务,多线程可能无法充分利用多核处理器的优势。如果需要执行CPU密集型任务,可以考虑使用multiprocessing模块来实现多进程。
当谈到使用多进程代替多线程时,我们通常是指使用Python的multiprocessing模块来创建和管理进程,而不是使用threading模块来创建和管理线程。这种方式可以绕过GIL的限制,充分利用多核处理器的优势。
下面是一个简单的示例,演示了如何使用multiprocessing模块创建多个进程:
import multiprocessing
def task():
print("Executing task...")
if __name__ == "__main__":
# 创建多个进程
processes = [multiprocessing.Process(target=task) for _ in range(4)]
# 启动进程
for process in processes:
process.start()
# 等待进程结束
for process in processes:
process.join()
print("Processes execution completed.")
在这个示例中,multiprocessing.Process类用于创建进程对象,每个进程都执行task函数。通过这种方式,我们可以同时在多个进程中执行任务,而不受GIL的限制。
关于"执行字节码"的意思,可以理解为Python代码在被Python解释器执行时的中间步骤。Python代码在被解释器执行之前会先被编译成字节码,然后解释器会逐行执行字节码指令,完成代码的执行过程。
而 "CPU密集型任务"指的是那些需要大量计算资源(CPU资源)的任务,比如复杂的数学运算、图像处理、加密解密等。这些任务通常会占用大量的CPU时间,因此在执行这些任务时,CPU的计算能力是非常关键的。与之相对的是 “I/O密集型任务”,指的是那些主要消耗时间在等待输入/输出操作完成的任务,比如文件读写、网络通信等。在执行I/O密集型任务时,CPU通常处于空闲状态,大部分时间都是在等待IO操作完成,因此多线程在这种情况下可以有效提升程序的性能。
Q4.75 进程与线程的区别
进程(Process)和线程(Thread)是操作系统中用于实现并发执行的两种基本方式,它们有以下主要区别:
资源分配: 进程是操作系统中的一个独立执行单元,拥有独立的内存空间、文件描述符、堆栈等资源。
线程是进程中的执行单元,同一进程中的多个线程共享相同的内存空间和其他资源,包括代码段、数据段、打开的文件等。
并发性: 多个进程之间可以并发执行,每个进程都有自己的地址空间,互相之间不会影响。
同一进程中的多个线程可以并发执行,它们共享进程的地址空间和其他资源,因此需要通过同步机制来保证数据的一致性和安全性。
切换开销: 由于进程拥有独立的内存空间,进程间的切换开销较大,涉及到上下文切换、内存空间切换等。 线程共享同一进程的地址空间,线程间的切换开销较小,通常只需要保存和恢复寄存器状态即可。
通信方式: 进程间通信(Inter-Process Communication,IPC)的方式包括管道、消息队列、信号量、共享内存等。线程间通信(Inter-Thread Communication,ITC)的方式包括锁、条件变量、信号量等,也可以通过共享内存来进行通信。
稳定性: 由于进程之间相互独立,一个进程崩溃不会影响其他进程。 线程共享相同的地址空间,一个线程的错误可能会影响到其他线程和整个进程的稳定性。
总的来说,进程适合用于需要高度隔离、稳定性要求高的场景,而线程适合用于需要共享数据和共享资源、并发性要求高的场景。在实际应用中,需要根据具体的需求和场景来选择使用进程还是线程。
Q5: 平衡的二叉树增加了一个节点会怎么样?怎样使它重新保持平衡?
平衡的二叉树(AVL树)在每个节点上都有一个平衡因子(Balance Factor),它表示了该节点的左子树高度和右子树高度之差。当插入一个新节点后,如果破坏了树的平衡性,就需要进行旋转操作来重新平衡树。
插入新节点可能导致以下四种情况之一:
左子树的左子树(LL情况):新节点插入了某个节点的左子树的左子树中,导致失衡。
左子树的右子树(LR情况):新节点插入了某个节点的左子树的右子树中,导致失衡。
右子树的右子树(RR情况):新节点插入了某个节点的右子树的右子树中,导致失衡。
右子树的左子树(RL情况):新节点插入了某个节点的右子树的左子树中,导致失衡。
对于LL和RR情况,可以进行单旋转操作来恢复平衡;对于LR和RL情况,需要进行双旋转操作。
具体来说,假设有一个树如下所示(其中数字表示节点的值):
A
/
B
/
C
当在节点 C 的左子树中插入一个新节点时,导致了 LL 情况。进行左旋转后,树将会变为:
B
/ \
C A
现在,节点 C 成为了整个子树的根节点,节点 A 则成为节点 C 的右子节点,而原先的节点 B 仍然是节点 C 的左子节点。
当插入的节点引发了左子树的右子树(LR)或右子树的左子树(RL)情况时,需要先进行一次旋转,然后再进行另一次旋转。
-
LR情况(左子树的右子树):
假设有如下树:A
\
C
/
B
当在节点 B 的右子树中插入一个新节点时,导致了LR情况。此时,可以进行一次右旋转,然后再进行一次左旋转。右旋转之后,树将会变为:A
\
B
\
C
然后再进行一次左旋转,将树调整为平衡状态:B
/ \
A C
在这个例子中,原先在 LR 情况下插入的节点 B 最终成为了整个子树的根节点。 -
RL情况(右子树的左子树):
假设有如下树:C
/
A
\
B
当在节点 B 的左子树中插入一个新节点时,导致了RL情况。此时,可以进行一次左旋转,然后再进行一次右旋转。左旋转之后,树将会变为:C
/
B
\
A
然后再进行一次右旋转,将树调整为平衡状态:B
/ \
A C
在这个例子中,原先在 RL 情况下插入的节点 B 最终成为了整个子树的根节点。
Q6: CTC的原理是什么?
Q7: 你知道几种颜色空间?HSV中的H/S/V分别是什么,明度和亮度是一个东西吗?
常见的颜色空间包括RGB(红绿蓝)、HSV(色调、饱和度、明度)、HSL(色调、饱和度、亮度)、Lab(明亮度、色度a、色度b)等。
在HSV颜色空间中,H代表色调(Hue),S代表饱和度(Saturation),V代表明度(Value)。
色调(Hue):表示颜色的种类或者类型,以角度(0°-360°)表示,其中0°和360°代表红色,120°代表绿色,240°代表蓝色,依此类推。色调的变化对应于颜色的变化,而不是亮度或者饱和度的变化。
饱和度(Saturation):表示颜色的纯度或者浓度,以百分比(0%-100%)表示。0%的饱和度代表灰色,100%的饱和度表示完全饱和的颜色。
明度(Value):表示颜色的明亮程度,以百分比(0%-100%)表示。0%的明度表示黑色,100%的明度表示白色。
HSV颜色空间将颜色的描述从RGB的三维空间中转换到了一个圆锥体中,使得颜色的调节更加直观。
YUV
是一种颜色编码系统,通常用于视频压缩和传输中。它将图像的亮度(Y)和色度(U、V)分离开来,以便更有效地对图像进行压缩和处理。主要的组成部分包括:
Y(亮度):Y 表示图像的亮度信息,即灰度信息。它代表了图像的明暗程度,决定了图像的亮度和对比度。Y 分量通常占据了整个图像数据的大部分。
U(色度):U 表示图像的色度信息,即色彩的蓝色成分。它测量了图像中的蓝色与亮度的相对强度。U
分量描述了图像中蓝色与亮度的变化,但不包含红色和绿色信息。 V(色度):V
表示图像的色度信息,即色彩的红色成分。它测量了图像中的红色与亮度的相对强度。V 分量描述了图像中红色与亮度的变化,但不包含绿色和蓝色信息。YUV 格式的优势在于它能够更好地适应于人眼对亮度和色度的感知特性,从而实现对图像数据的有效压缩。常见的 YUV 格式包括
YUV420、YUV422、YUV444 等,它们的差别在于色度分量的取样率不同,影响了图像的色彩精度和压缩效率。 YUV
被广泛应用于视频编码和数字电视等领域。
"明度"和"亮度"在一些上下文中可能会被混用,但它们在某些情况下确实有区别。在颜色学和图像处理中,它们通常有以下不同的含义:亮度(Brightness): 亮度通常用来描述光的强度或物体发出的光的强度。
在图像处理中,亮度是指像素的灰度级别,表示像素的明亮程度。在黑白图像中,亮度值表示像素的灰度值,范围通常在 0(黑色)到
255(白色)之间。 在彩色图像中,亮度可能是 RGB 值的加权平均值,也可能是从彩色空间中分离出的亮度分量,比如 YUV
中的亮度分量(Y)。 明度(Luminance):
明度是指物体表面对光的反射或发射的光的强度。它是由光源的强度、物体的表面特性和观察者的位置共同决定的。
在色彩空间中,明度通常指的是色彩的亮度,即颜色的明暗程度。在 HSV(色调、饱和度、明度)颜色空间中,明度表示颜色的明亮程度,取值范围通常在
0 到 100 之间。
总的来说,亮度通常用于描述光的强度和图像的灰度级别,而明度通常用于描述颜色的亮度或明暗程度。它们的具体含义可能会根据上下文和使用的领域而有所不同。
在RGB颜色空间中,明度和亮度虽然通常都可以通过红色(R)、绿色(G)和蓝色(B)三个分量的加权平均值来衡量,但在一些情况下,它们的计算方式可能略有不同。
在某些文献或应用中,"亮度"一词可能更倾向于描述灰度级别或整体的明暗程度,因此在RGB颜色空间中,亮度通常指的是RGB分量的简单平均值,即
(R + G + B) / 3。这种情况下,亮度与明度的概念相似。
而在其他情况下,尤其是在色彩理论和图像处理中,"明度"可能更倾向于描述颜色的亮度或明暗程度,这时候可能会使用一些不同的权重来计算RGB分量的加权平均值,以更好地反映人眼对颜色的感知。这种情况下,明度与亮度的概念更加接近。
因此,虽然在一些情况下明度和亮度可以被认为是相同的概念,但在另一些情况下,它们的具体含义可能会有所不同,取决于上下文和使用领域。
Q8: 怎样区别两幅图像?
当涉及到图像比较时,特征提取和匹配以及结构化方法是两种常见且有效的技术。以下是它们的详细说明:
特征提取和匹配方法:
特征提取:特征提取是指从图像中提取出具有代表性的信息点或结构,这些信息点可以用来描述图像的内容。常见的特征包括角点、边缘、斑点等。特征提取的目标是保留图像中最重要和最具区分性的信息,同时减少对噪声和无关信息的敏感度。
常见的特征提取算法包括Harris角点检测、SIFT(尺度不变特征变换)、SURF(加速稳健特征)等。
特征匹配:特征匹配是将两幅图像中的特征进行对应,找到它们之间的相似性或匹配关系。匹配可以基于特征之间的距离、相似性度量或几何约束进行。 在特征匹配过程中,通常会使用一些算法来计算特征之间的相似性,例如最近邻算法、RANSAC(随机抽样一致)算法等。
特征匹配的评估: 特征匹配的质量可以通过匹配的准确性和稳定性来评估。准确性表示匹配的正确率,稳定性表示匹配的一致性和可靠性。
结构化方法: 图像分割:图像分割是将图像分解成若干个不同的区域或对象的过程。这些区域可以是图像中具有相似特征的部分,例如颜色、纹理或亮度等。图像分割可以帮助理解图像的结构和内容,从而更好地比较图像之间的差异。
特征提取和表示:结构化方法通常涉及从图像中提取出具有代表性的结构化特征,例如边缘、纹理、颜色直方图等。这些特征可以用来描述图像的内容和结构。
相似性度量:一旦提取了图像的结构化特征,就可以使用各种相似性度量方法来比较这些特征,以量化图像之间的相似性或差异。常见的相似性度量方法包括欧氏距离、余弦相似度、相关系数等。这两种方法可以单独使用,也可以结合使用,以便更准确地比较和区分图像。它们的选择取决于应用场景、图像特点以及可用的资源和技术水平。
Q9: 什么是极大似然?
极大似然估计是统计学中常用的一种参数估计方法,用于估计一个概率模型的参数,使得观察到的样本数据在该参数下的出现概率最大。
假设我们有一组独立同分布的样本数据,每个样本都是根据一个未知参数的概率分布生成的。我们的目标是通过观察到的样本数据,估计出这个未知参数的值。极大似然估计的核心思想是找到使得观察到的样本数据出现的概率最大的参数值。
具体来说,假设我们有一个参数为θ的概率分布模型,记为P(x|θ),其中x是样本数据。那么给定观察到的样本数据X,极大似然估计的目标是找到使得P(X|θ)最大的θ值。这个θ值即为我们的估计值。
通常情况下,我们并不直接最大化P(X|θ),而是最大化其对数,即对数似然函数(log-likelihood function)。这是因为对数函数的性质更易处理,而且对数函数的极值点与原函数相同。因此,极大似然估计的目标可以表述为:
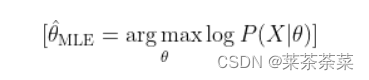
Q9.5 你了解哪些激活函数?
可参考这篇
Q10 ROIPooling和ROIalign的区别
ROIPooling和ROIAlign都是用于处理区域感兴趣(Region of Interest,ROI)的池化操作,通常用于目标检测和语义分割等任务中。
ROIPooling:
ROIPooling是一种粗略的ROI池化方法,它将不规则的ROI区域划分为固定大小的子区域,并对每个子区域进行池化操作。
ROIPooling将ROI区域划分为固定大小的网格,然后通过最大池化(Max Pooling)或平均池化(Average Pooling)等方式,将每个网格内的特征值池化为固定大小的输出特征。
ROIAlign:
ROIAlign是一种更精确的ROI池化方法,它考虑了ROI区域内像素的精确位置,而不是简单地划分为固定大小的网格。
ROIAlign首先将ROI区域内的坐标映射到特征图上,并使用双线性插值等方法计算每个采样点的特征值,然后对这些特征值进行池化操作,以生成输出特征。
主要区别在于精度和对位置的处理方式:
ROIPooling会导致信息丢失,因为它将不规则的ROI划分为固定大小的网格,而且不考虑像素的精确位置。
ROIAlign更准确,因为它考虑了ROI区域内像素的精确位置,利用插值等方法计算每个位置的特征值,从而减少了信息损失。但是由于计算复杂度较高,ROIAlign的计算成本也更高。
Q10 请阐述双向LSTM的原理
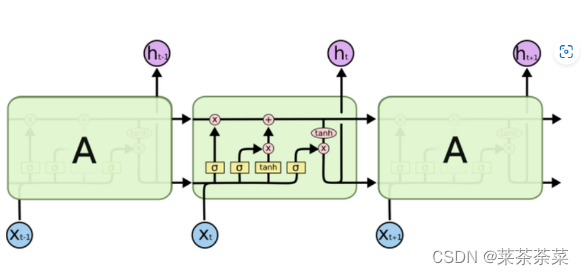
单向LSTM图解
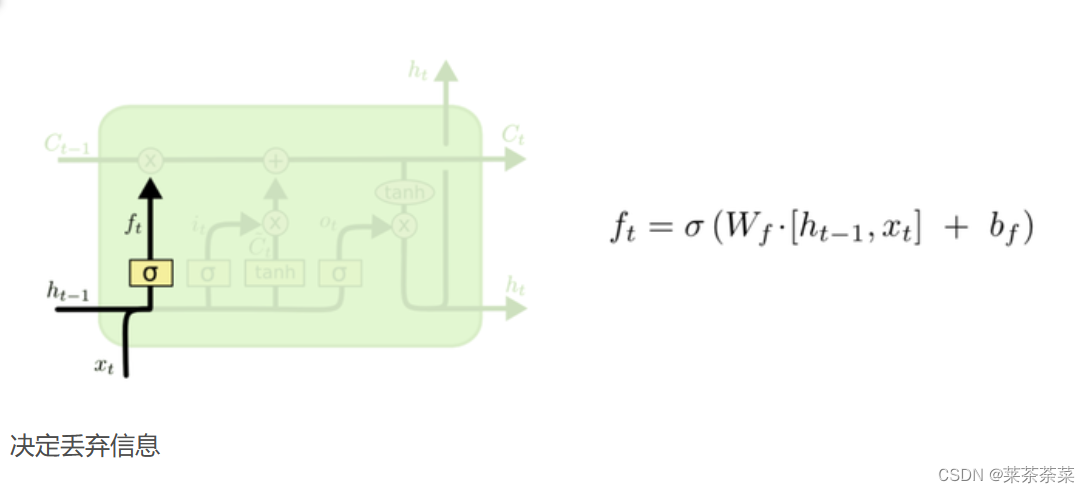
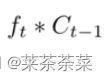
我们把旧状态与f_t相乘,丢弃掉我们确定要丢弃的信息
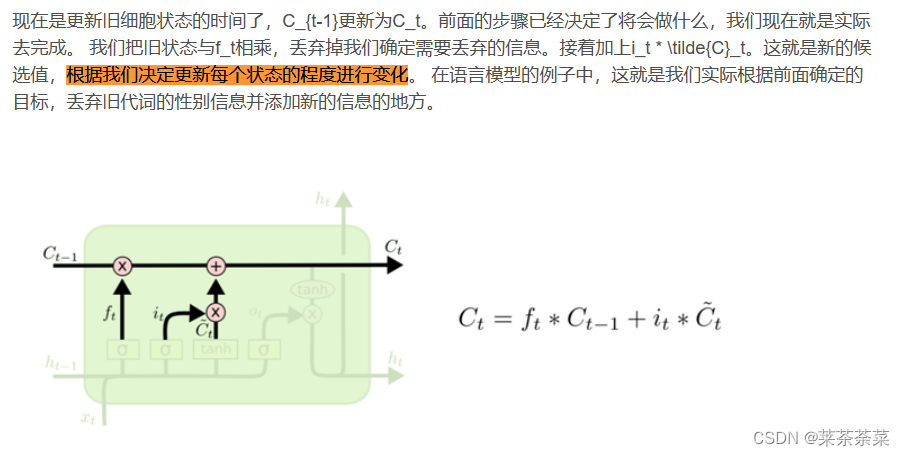
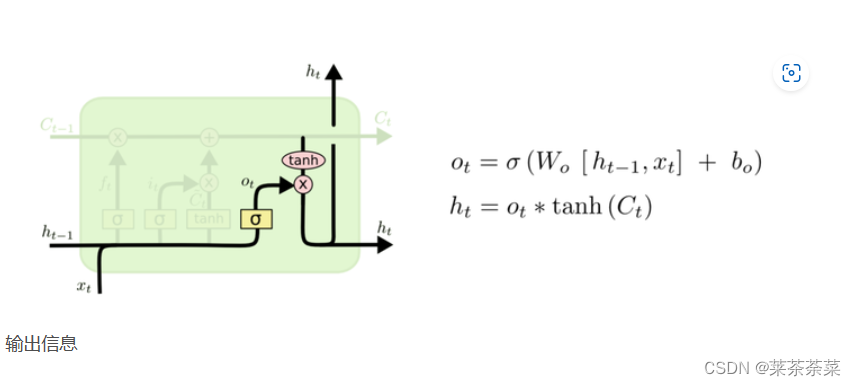
在有些问题中,当前时刻的输出不仅和之前的状态有关,还可能和未来的状态有关系。比如预测一句话中缺失的单词不仅需要根据前文来判断,还需要考虑它后面的内容,真正做到基于上下文判断
Bi-LSTM 可以看成是两层神经网络,第一层从左边作为系列的起始输入,在文本处理上可以理解成从句子的开头开始输入,而第二层则是从右边作为系列的起始输入,在文本处理上可以理解成从句子的最后一个词语作为输入,反向做与第一层一样的处理处理。最后对得到的两个结果进行处理。
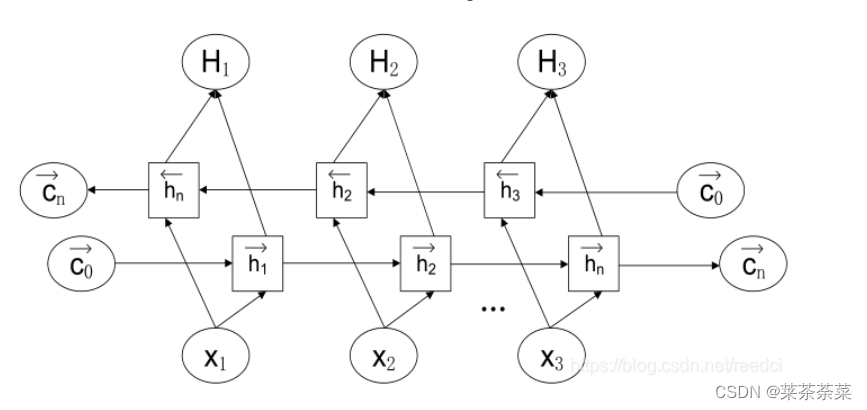
Q11 你知道哪些注意力机制?
点积注意力(Dot-Product Attention): 这是最简单的注意力机制之一,通常用于序列到序列(Sequence-to-Sequence)模型中。在点积注意力中,通过计算查询向量和键向量的点积来计算注意力权重,然后将这些权重与值向量相乘以获取加权和。
加权平均注意力(Weighted Average Attention): 这种注意力机制根据查询向量和键向量之间的相似度来计算注意力权重,然后将这些权重与值向量相乘以获取加权和。常见的相似度度量包括余弦相似度、欧氏距离等。
自注意力(Self-Attention): 自注意力机制允许模型在一个序列中的不同位置之间进行关联。在自注意力中,查询、键和值都来自于同一个序列,并且通过计算序列中每个位置的查询向量与所有位置的键向量之间的相似度来计算注意力权重。
多头注意力(Multi-Head Attention): 多头注意力机制通过将输入进行线性变换并分成多个头来并行计算多组注意力权重,然后将这些注意力权重进行拼接并经过另一个线性变换来生成最终的输出。这有助于模型更好地捕捉不同方面的信息。
位置注意力(Positional Attention): 这种注意力机制通常用于处理空间结构化的数据,例如图像。它考虑到了输入的位置信息,并根据位置来计算注意力权重,以便模型能够关注输入中的特定区域。
跨模态注意力(Cross-Modal Attention): 跨模态注意力用于处理多模态数据,例如同时包含图像和文本的数据。它允许模型在不同模态之间进行交互,并基于一个模态的表示来计算另一个模态的注意力权重。
空间注意力和通道注意力是两种不同类型的注意力机制,它们分别关注于数据的空间维度和通道维度,以提取和利用数据中的重要信息。
空间注意力(Spatial Attention): 空间注意力机制关注于数据在空间维度上的分布和结构,它允许模型在处理图像或其他空间结构数据时聚焦于特定区域或特征。在图像处理中,空间注意力可以使模型关注于图像中的重要区域,从而提高模型的性能和泛化能力。例如,在处理对象检测或图像分类任务时,模型可以通过空间注意力机制自动地关注于包含重要目标信息的图像区域,而不是简单地对整个图像进行处理。
通道注意力(Channel Attention): 通道注意力机制则关注于数据在通道维度上的特征表示,它允许模型自动地学习到不同通道之间的相关性,并根据其重要性调整特征表示。在处理具有多个通道的数据(例如图像、音频等)时,通道注意力可以帮助模型选择和集成最具信息量的通道,从而提高模型的性能。通道注意力机制通常通过计算每个通道的重要性权重来实现,然后将这些权重应用到每个通道的特征表示上,以调整特征的重要程度。
Q11.5 Transformer中自注意机制怎么理解 ,有什么优势?
自注意力机制:
自注意力机制允许模型在输入序列中的每个位置都能够关注其他所有位置的信息,并据此调整每个位置的表示。具体来说,给定一个输入序列,自注意力机制通过计算每个位置与其他所有位置的相关性得分,然后将这些得分用于加权求和以生成每个位置的新表示。这使得模型能够在不同位置之间建立并利用长距离的依赖关系。
优势:
全局信息交互: 自注意力机制允许模型在输入序列中的每个位置捕获全局信息,而不仅仅是局部信息。这有助于模型更好地理解整个序列的语义结构,而不会受到局部上下文的限制。
位置不变性: 自注意力机制不受输入序列长度的限制,因此可以轻松处理长序列。与循环神经网络(RNN)或卷积神经网络(CNN)不同,它不会受到梯度消失或梯度爆炸的问题。
并行计算: 自注意力机制的计算可以并行进行,因为每个位置的注意力权重都是独立计算的。这使得 Transformer 模型在训练和推理时能够高效地利用计算资源。
灵活性: 自注意力机制可以适用于不同类型的序列数据,包括文本、语音和图像等,因此 Transformer 模型可以应用于各种任务,如自然语言处理、语音识别和图像处理等。
Q12 BN层有什么优点与缺点
批量归一化(Batch Normalization,简称 BN)是一种用于神经网络中的层,其主要作用是加速神经网络的训练并提高模型的泛化能力。下面是批量归一化层的优点和缺点:
优点:
加速收敛: BN 层通过将每个批次的输入数据进行归一化,有助于缓解梯度消失或爆炸的问题,从而加速神经网络的收敛速度。这使得可以使用更高的学习率,加快模型训练过程。
减少梯度消失: BN 层可以将每一层的输入都归一化到一个稳定的分布范围内,有助于避免梯度消失问题,特别是在深层网络中。
降低对初始化的敏感性: BN 层减少了对初始参数的依赖,使得网络对初始参数的选择不太敏感,从而简化了网络的设计和调整过程。
正则化作用: BN 层在训练过程中对每个批次的数据进行归一化,类似于 Dropout 的效果,有一定的正则化作用,可以降低过拟合的风险。
增强模型的泛化能力: BN 层使得网络在训练过程中学习到的特征更加稳定,有利于提高模型的泛化能力,从而在测试集上取得更好的性能。
缺点:
计算代价: BN 层在每个批次中都需要对输入数据进行归一化,这会增加额外的计算代价,尤其是在推理阶段。
限制了 batch size: BN 层对每个批次的数据进行归一化,因此在 batch size 较小时,由于统计量不足可能会导致归一化效果不佳,影响模型的性能。
不适用于 RNN: 在循环神经网络(RNN)中,由于序列长度的不确定性,BN 层的统计量难以稳定,因此不太适合直接应用于 RNN 模型中。
综上所述,批量归一化层通过加速收敛、减少梯度消失、降低对初始化的敏感性等优点,提高了神经网络的训练效率和泛化能力,但也存在一定的计算代价和适用范围限制。在实际应用中,需要根据具体情况权衡其利弊。
Q13 YOLO系列主干网络是什么?描述yolov5的架构。
YOLOv1/YOLOv2使用的骨干架构被称为Darknet-19, YOLOv3在主干网络上采用了Darknet53。而后版本的主干都是CSPDarknet53。
yolov5架构我的一篇写yolov5的文章中涵盖了,并且会继续完善

















 619
619

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









