







 本文详细介绍Scrapy框架的使用,包括项目与爬虫创建、数据抓取与解析、多级页面处理等核心流程。通过实例讲解如何定义目标字段、解析响应数据及配置数据保存管道。
本文详细介绍Scrapy框架的使用,包括项目与爬虫创建、数据抓取与解析、多级页面处理等核心流程。通过实例讲解如何定义目标字段、解析响应数据及配置数据保存管道。
scrapy框架
scrapy-项目和爬虫的创建
1.项目的创建scrapy startproject 项目名
2.爬虫的创建scrapy genspider 爬虫名 目标的主域名(进入项目文件夹后执行)
创建好的scrapy项目文件夹如下:
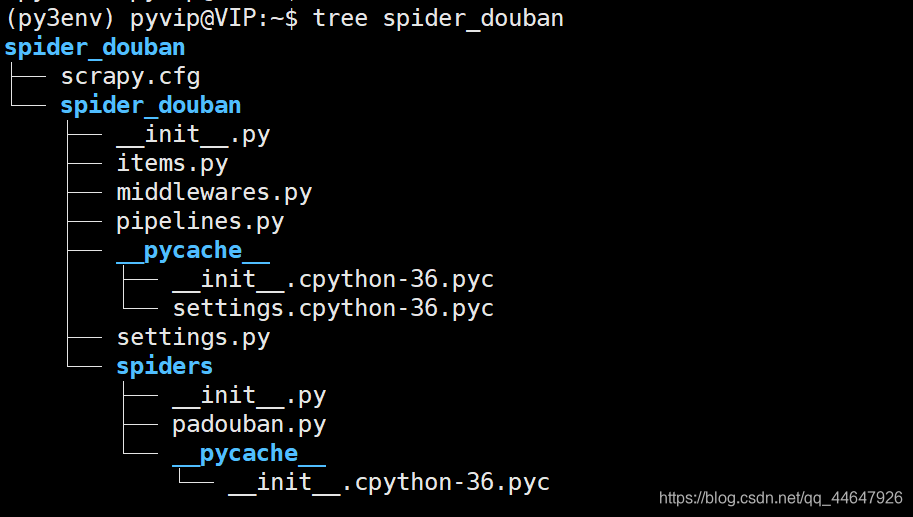
3.项目文件夹的介绍

scrapy-爬虫的编写
scrapy的运行过程
爬虫文件(请求的数据) → 引擎 → 调度器(对请求的数据入队) → 引擎 →下载器(开始依次下载请求的数据) → 引擎 → 爬虫文件(解析下载的数据) → pipelines(保存解析的数据)
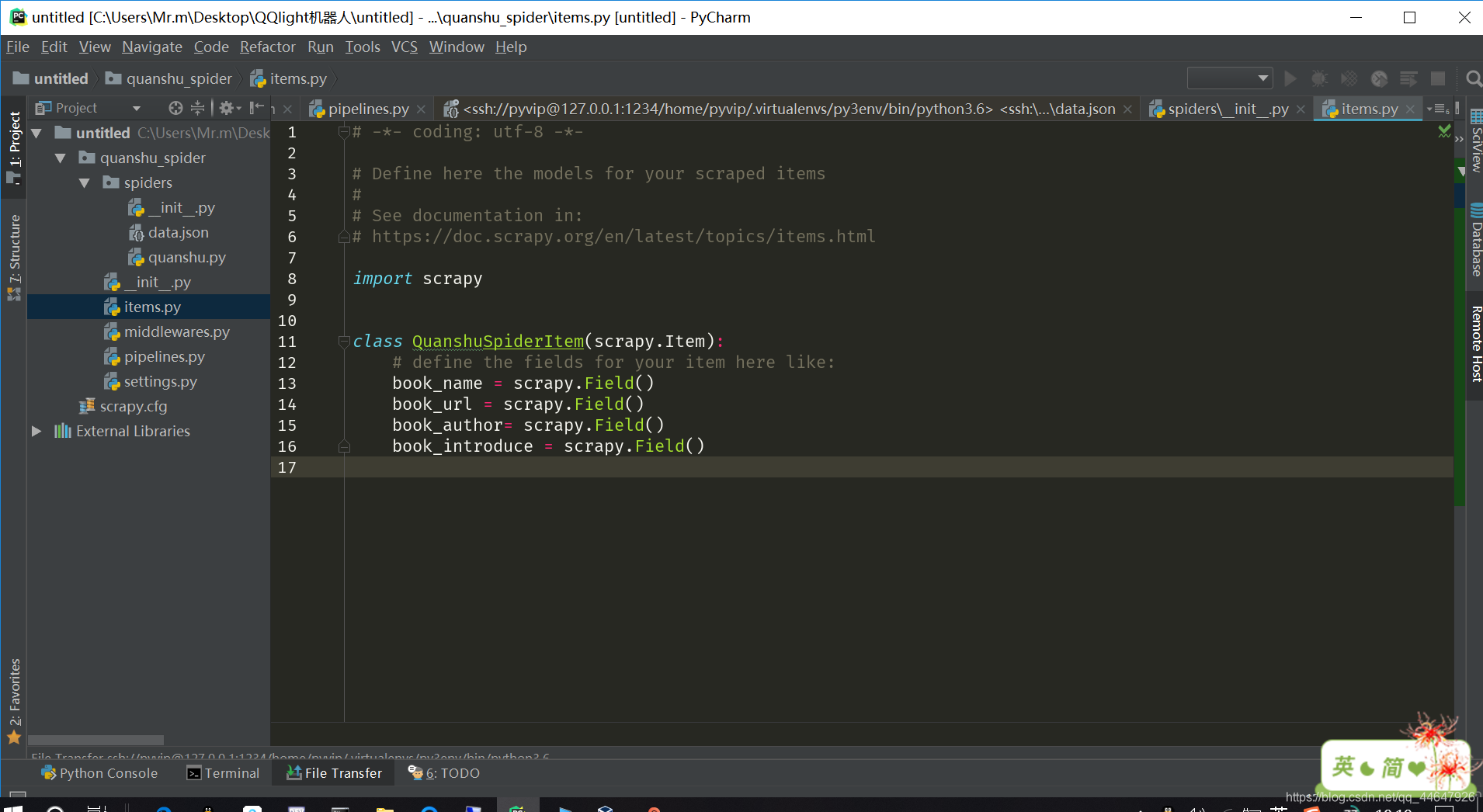
1.在item中定义准备抓取的目标字段
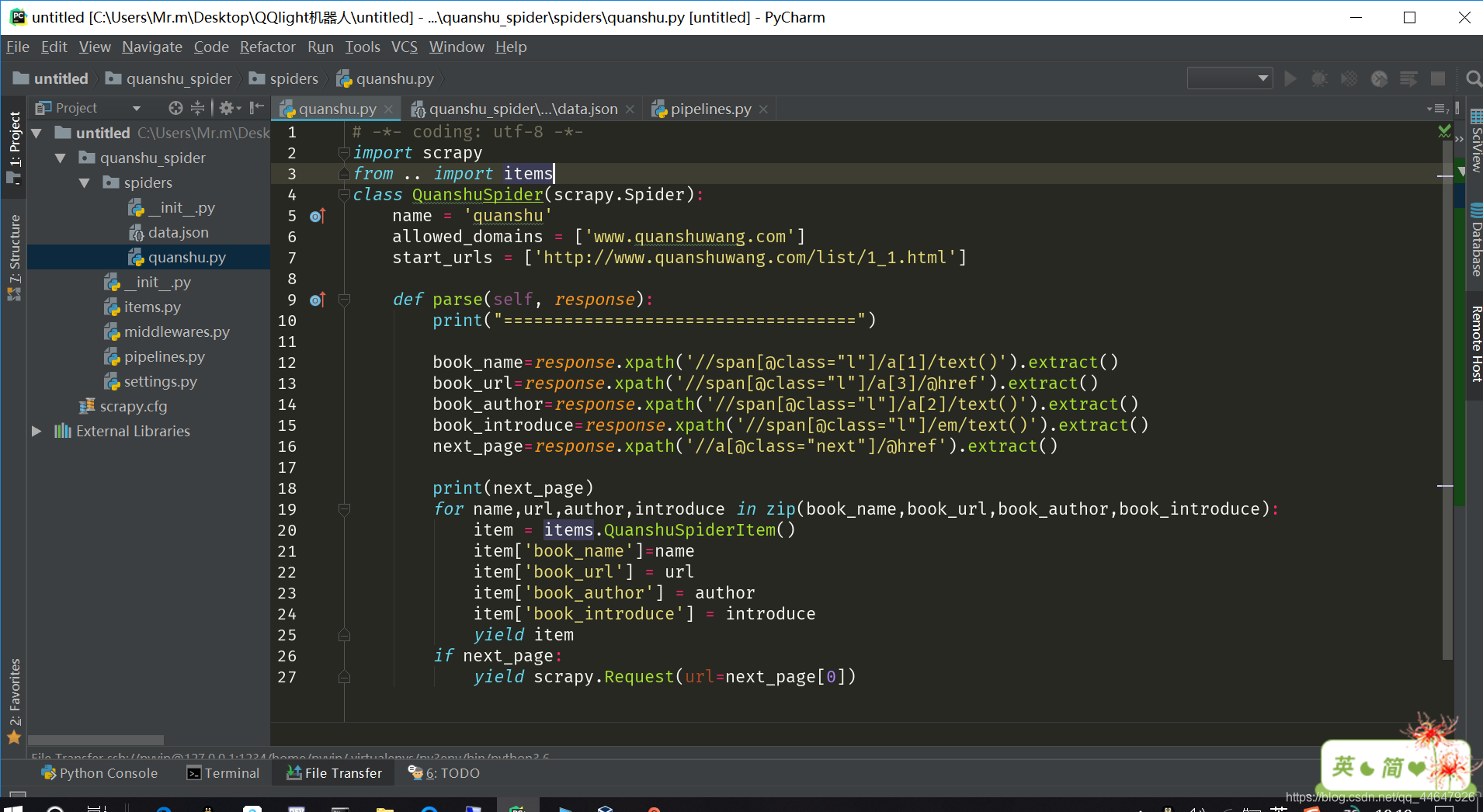
2.在爬虫文件中对响应数据进行解析
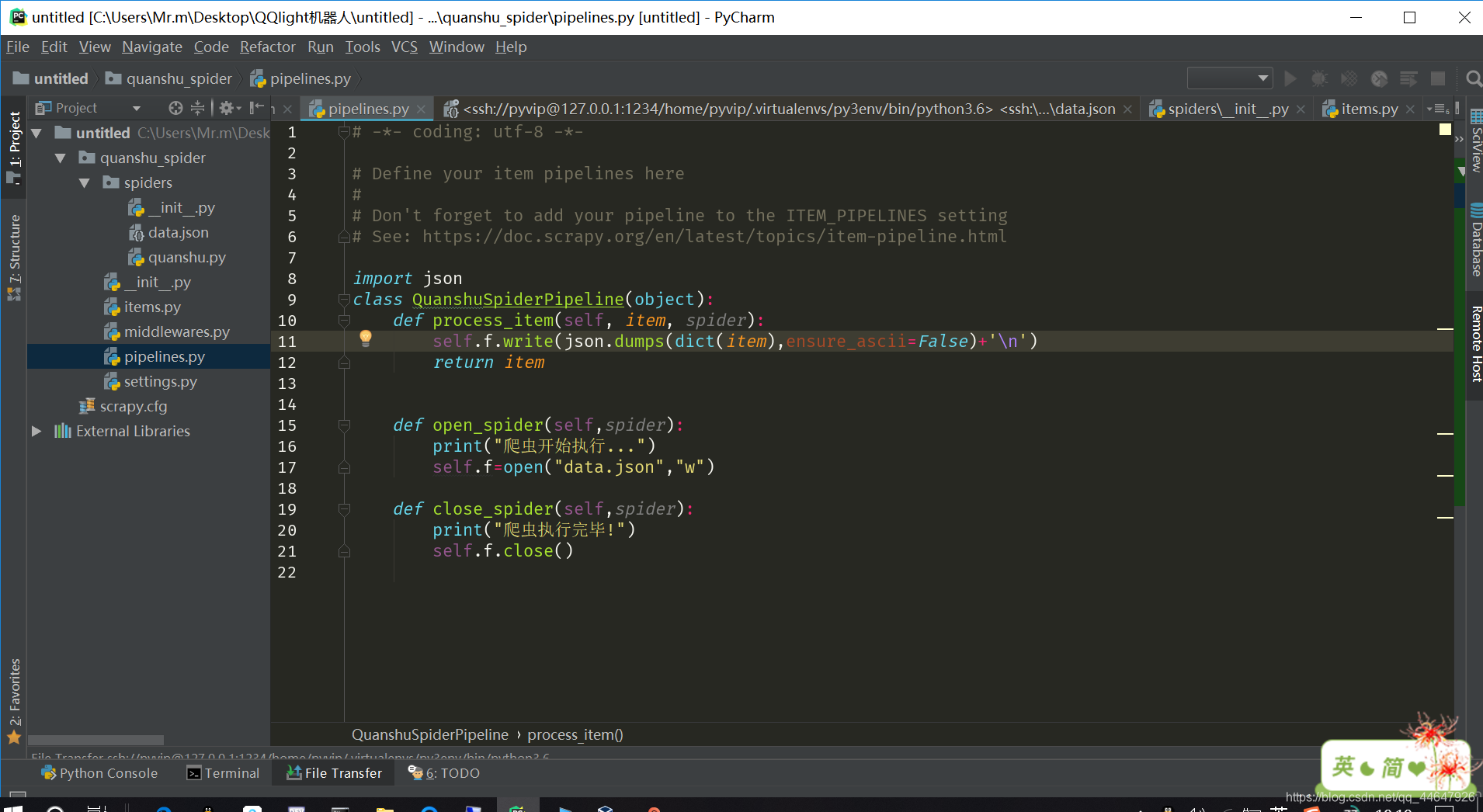
3.配置pipelines管道文件 对爬虫文件传过来的数据进行保存
4.执行爬虫文件
查看可执行爬虫文件scrapy list
执行爬虫文件 scrapy crawl 爬虫文件名
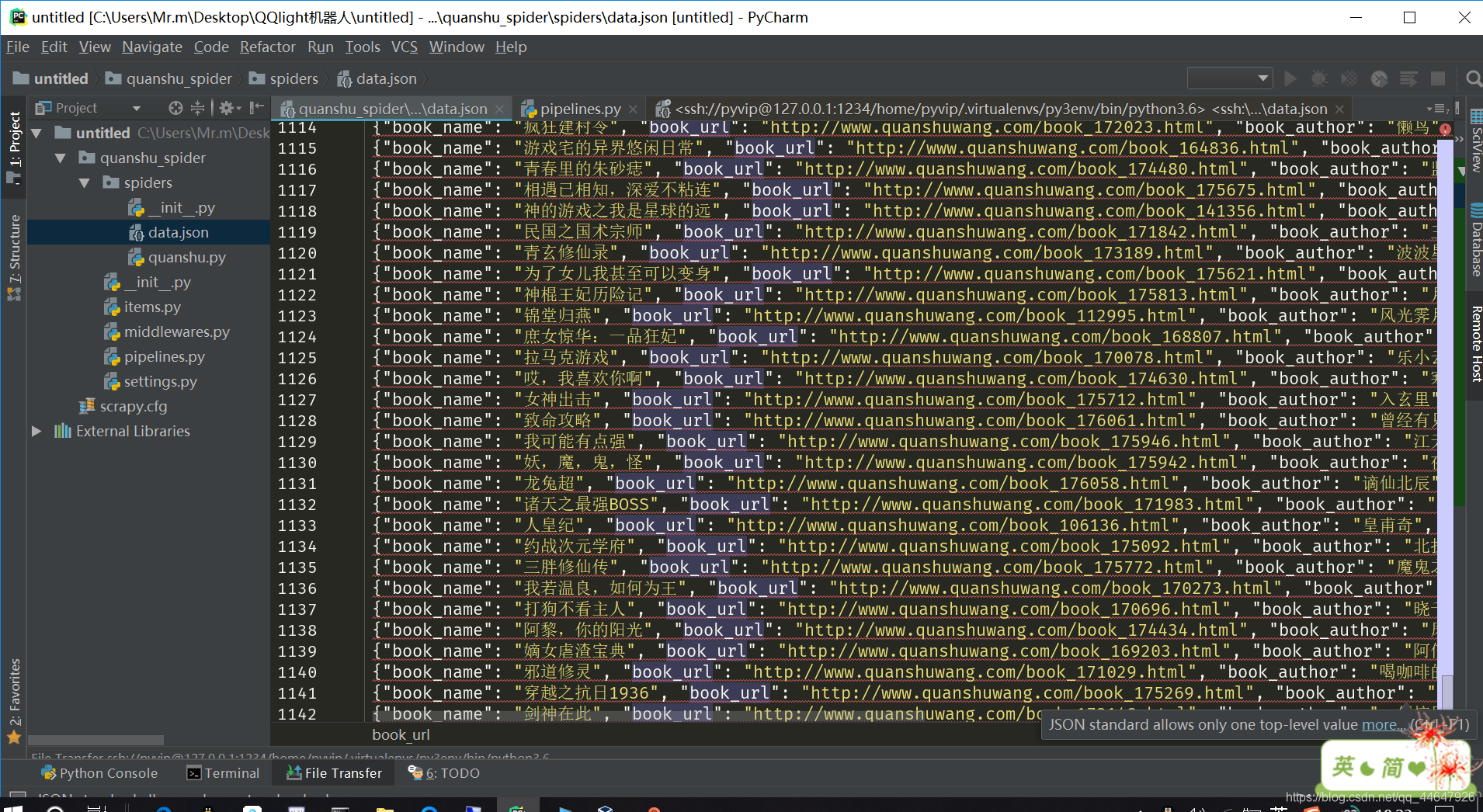
5.数据展示
几个注意点:
-
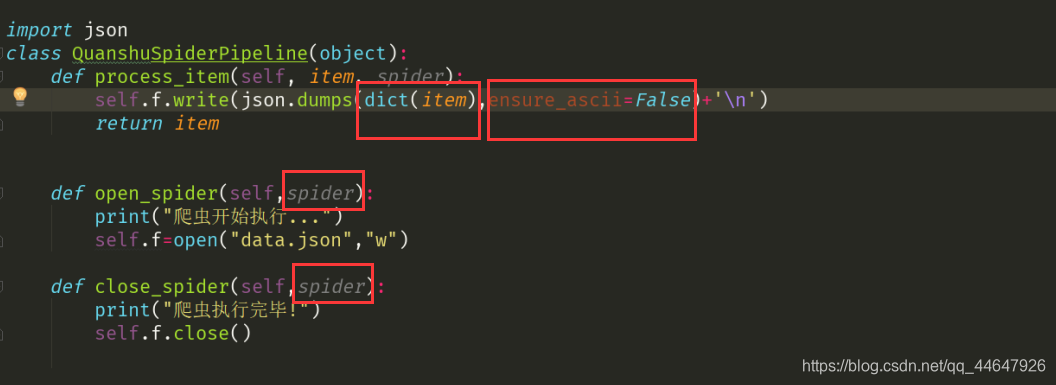
item的实例化被后来的数据覆盖 ?解决办法 将实例化item的过程放在yield item的循环中,一边实例一边返回item

-
在pipelines文件中将数据保存到文件时要先将item类型的数据转化字典类型,再将字典类型的数据转化为json数据。
-
pen_spider() 和close_spider()两个方法要传入spider后才能被调用。
-
其次是爬虫文件里的item每次yield返回到pipelines里时都会执行一次process_item方法。
scrapy-多级页面解析的实现
位置:爬虫文件
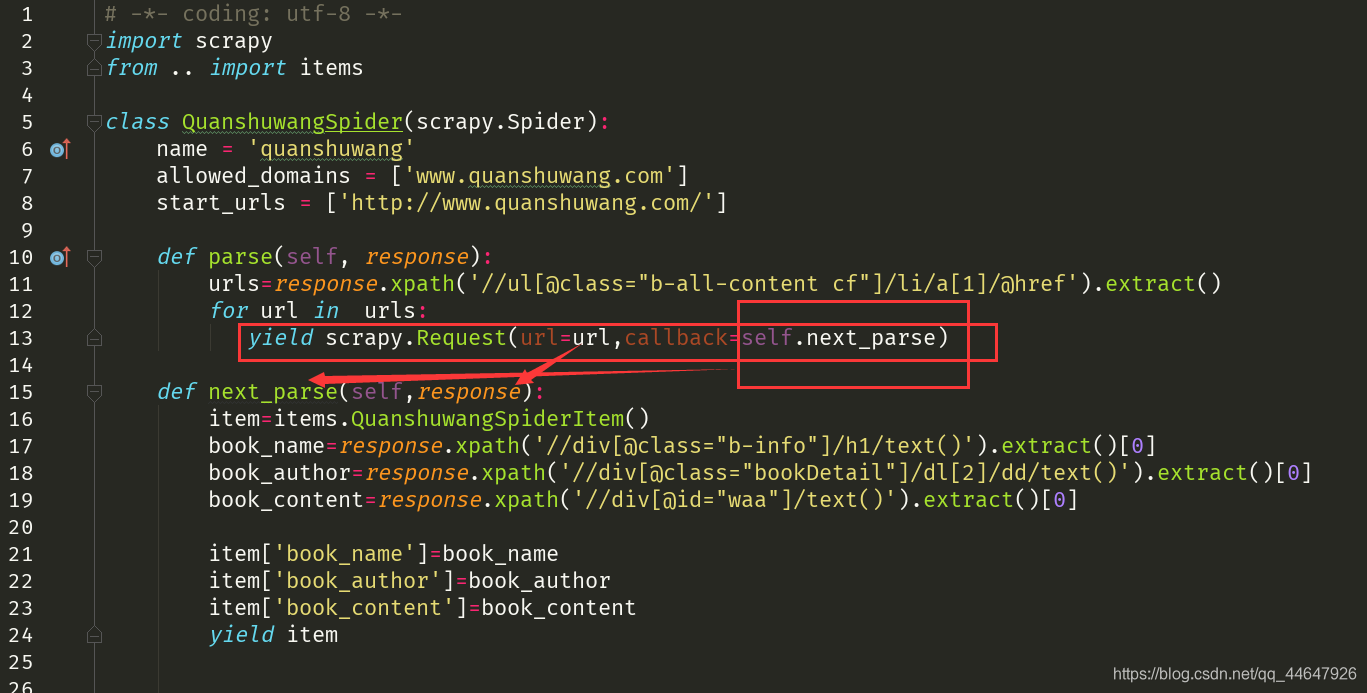
实现的方法:在第一次解析中使用scrapy.Request方法
yield scrapy.Request(url=next_url,callback=next_parse)
- next_url:要请求的下一个页面的url
- next_parse:解析由next_url请求完成后获得的页面数据

















 4504
4504

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









